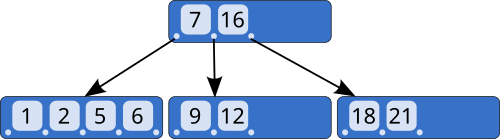
B-Tree
일반적인 이진 탐색 트리는 데이터가 한쪽으로 쏠리면 탐색 성능이 급격히 떨어지며, 노드 하나당 하나의 데이터만 가질 수 있어 데이터가 많아질수록 트리가 매우 깊어집니다.
B-Tree는:
-
디스크 I/O 최적화: 하드디스크나 SSD 같은 보조기억장치는 데이터를 블록 단위로 읽습니다. B-Tree는 노드 하나에 여러 데이터를 담아 한 번의 I/O로 많은 데이터를 읽어올 수 있습니다.
-
빠른 탐색속도: 트리의 높이가 낮게 유지되므로, 수억 개의 데이터 중에서도 단 몇 번의 이동만으로 원하는 값을 찾을 수 있습니다.
구조
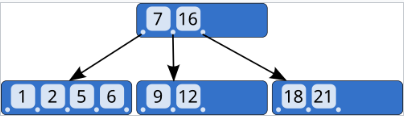
하나의 노드는 크게 세 가지 요소로 이루어져 있습니다.
-
Key (데이터): 실제 찾고자 하는 값입니다. 노드 내에서 항상 오름차순으로 정렬되어 있습니다.
-
Pointer (포인터): 자식 노드로 연결되는 통로입니다.
-
Data Record: Key와 연결된 실제 데이터(또는 데이터의 위치 주소)입니다.
만약 한 노드에 개의 Key가 있다면, 자식 노드를 가리키는 포인터는 항상 개가 존재합니다.
- 예: [ 10 | 20 ] 이라는 Key가 있는 노드는, 10보다 작은 값, 10~20 사이의 값, 20보다 큰 값을 가리키는 3개의 포인터를 가집니다.
구조적 규칙 (Invariant)
B-Tree가 균형을 유지하기 위해 반드시 지키는 엄격한 구조적 규칙입니다. (차 B-Tree 기준)
-
자식의 수: 루트와 리프를 제외한 모든 노드는 최소 개, 최대 개의 자식을 가집니다.
-
Key의 수: 각 노드는 최소 개, 최대 개의 Key를 가집니다.
-
수평적 균형: 모든 리프 노드는 반드시 같은 깊이(Level)에 있어야 합니다. 트리가 한쪽으로 쏠리는 것을 원천 봉쇄하는 구조입니다.
실무적 관점의 노드와 차수
이론에서는 차수 을 강조하지만, 실무에서 여러분이 이 숫자를 직접 설정할 일은 거의 없습니다. 대신 "페이지 크기 내에 몇 개의 키를 담을 수 있는가"가 중요합니다.
-
페이지 크기: 보통 8KB.
-
인덱스 키 선택: 인덱스 키가 UUID나 긴 문자열이면 한 페이지에 담을 수 있는 요소가 줄어듭니다. 이는 트리의 높이를 높이고, 결국 더 많은 디스크 I/O를 유발합니다. 인덱스 키는 가급적 작고 고정된 크기(Integer 등)를 권장하는 이유입니다.
DB 엔진별 데이터 포인터의 차이
B-Tree의 각 요소는 키(Key)와 값(Value, 데이터 포인터)으로 구성됩니다. 이 '값'이 무엇을 가리키느냐가 엔진의 성격을 결정합니다.
-
PostgreSQL: 모든 인덱스가 실제 행(Tuple)의 물리적 위치를 직접 가리킵니다. 관리가 직관적이지만, 테이블 업데이트 시 인덱스 전체를 손봐야 할 때가 많습니다.
-
MySQL (InnoDB): 보조 인덱스가 실제 데이터가 아닌 기본 키(Primary Key)를 가리킵니다. 기본 키가 바뀌지 않는 한 보조 인덱스를 수정할 필요가 적어 효율적입니다. (Uber가 Postgres에서 MySQL로 넘어간 주요 아키텍처적 이유 중 하나이기도 합니다.)
B-Tree의 한계와 B+Tree의 등장 배경
B-Tree는 단일 값 검색에는 강하지만 실무의 복잡한 쿼리에는 한계가 있습니다.
-
메모리 낭비: 검색 경로에 있는 내부 노드들이 굳이 갖고 있을 필요가 없는 '데이터 포인터'까지 메모리에 올리게 되어 효율이 떨어집니다.
-
범위 검색(Range Query)의 쥐약: 예를 들어 BETWEEN 1 AND 10 쿼리를 날릴 때, B-Tree는 1 찾고 다시 위로 올라갔다 내려와서 2 찾고... 하는 식으로 랜덤 액세스를 유발합니다.
B+Tree
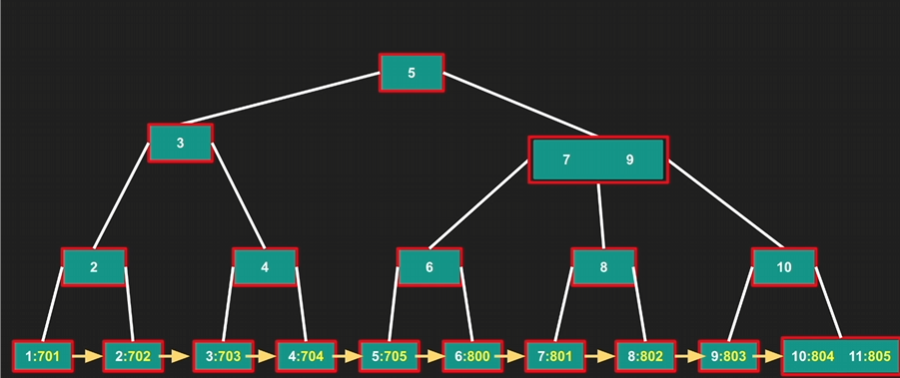
데이터를 오직 리프 노드(Leaf Node)에만 저장하고, 내부 노드(Internal Node)는 길잡이 역할인 '키(Key)'만 가집니다. 리프 노드끼리 서로 연결(Linked List)되어 있어 범위 쿼리(Range Scan)에 압도적으로 유리하며, 한 페이지에 더 많은 키를 담을 수 있어 디스크 IO를 획기적으로 줄인 구조입니다.
왜 데이터는 리프 노드에만 저장하는가?
- 데이터 포인터가 빠진 자리에 더 많은 키를 넣을 수 있습니다.
- 결과: 트리의 높이(Height)가 낮아집니다. DB에서 트리의 높이는 곧 디스크 접근 횟수(IO)입니다. 높이가 낮을수록 사용자는 더 빠른 응답을 받게 됩니다.
범위 쿼리
실무에서 WHERE age BETWEEN 20 AND 30 같은 쿼리는 아주 흔합니다.
-
B-Tree의 한계: 매번 루트부터 다시 탐색하거나 트리를 위아래로 왔다 갔다 해야 합니다.
-
B+Tree의 강점: 리프 노드가 연결 리스트(Linked List) 형태입니다. 시작점(20)을 찾으면, 그때부터는 트리 탐색 없이 옆 노드로 이동하며 끝점(30)까지 쭉 읽으면 끝입니다. 이것이 인덱스 스캔의 핵심 원리입니다.
