문자열 관련
문자열 합치기
-- MySQL
SELECT CONCAT('Hello', ' ', 'World'); -- 여러 개 인자 가능
SELECT CONCAT_WS('-', '2026', '05', '07'); -- 구분자(With Separator) 포함: 2026-05-07
-- PostgreSQL
SELECT 'Hello' || ' ' || 'World'; -- 파이프(||) 연산자 사용
SELECT CONCAT('Hello', ' ', 'World'); -- 함수도 지원함문자열 자르기
-- MySQL & PostgreSQL 공통
SELECT SUBSTRING('Database', 1, 4); -- 결과: Data (1번째부터 4글자)
SELECT LEFT('Database', 4); -- 결과: Data (왼쪽에서 4글자)
SELECT RIGHT('Database', 4); -- 결과: base (오른쪽에서 4글자)
-- MySQL
SELECT SUBSTR('Database', 1, 4); -- SUBSTRING의 줄임말문자열 길이 구하기
-- MySQL
SELECT LENGTH('abc'); -- 바이트(Byte) 수
SELECT CHAR_LENGTH('한글'); -- 실제 글자 수 (추천)
-- PostgreSQL
SELECT LENGTH('한글'); -- 실제 글자 수대소문자 변환 및 공백 제거
-- 공통
SELECT UPPER('mysql'); -- 대문자로: MYSQL
SELECT LOWER('MYSQL'); -- 소문자로: mysql
SELECT TRIM(' space '); -- 양쪽 공백 제거
SELECT LTRIM(' left'); -- 왼쪽 공백 제거
SELECT RTRIM('right '); -- 오른쪽 공백 제거문자열 치환 및 위치 찾기
-- 공통
SELECT REPLACE('Apple Pie', 'Apple', 'Banana'); -- 결과: Banana Pie
-- MySQL
SELECT INSTR('Hello World', 'o'); -- 'o'가 처음 나타나는 위치 (5)
SELECT LOCATE('o', 'Hello World'); -- 위와 동일 (5)
-- PostgreSQL
SELECT POSITION('o' IN 'Hello World'); -- 'o'의 위치 (5)문자열 채우기
-- 공통 (자릿수 맞출 때 유용, 예: 1 -> 001)
SELECT LPAD('1', 3, '0'); -- 결과: 001 (왼쪽에 0을 채워 3자리로)
SELECT RPAD('1', 3, '0'); -- 결과: 100 (오른쪽에 0을 채워 3자리로)Date 관련
현재 날짜/시간 구하기
SELECT NOW(); -- 현재 시간
SELECT CURDATE(); -- 현재 날짜 (YYYY-MM-DD)
SELECT CURTIME(); -- 현재 시간 (타임존 세팅된 거로 나옵니다.) 참고: SET time_zone = 'Asia/Seoul';
-- [참고] postgresql
SELECT NOW(); -- 동일
SELECT CURRENT_DATE;
SELECT CURRENT_TIME;날짜 포맷 변환
SELECT DATE_FORMAT(date, '%Y-%m-%d'); -- 연-월-일
SELECT DATE_FORMAT(date, '%Y-%M'); -- 연-월
SELECT DATE_FORMAT(date, '%W'); -- 요일
-- 예시
SELECT DATE_FORMAT('2026-05-06', '%Y년 %m월')
-- 문자열 -> 날짜 변환
STR_TO_DATE('20240315', '%Y%m%d')
-- [참고] PostgreSQL
SELECT TO_CHAR(date, 'YYYY-MM-DD');
SELECT TO_CHAR(date, 'YYYY-MM');
SELECT TO_CHAR(date, 'Day');
-- 예시
SELECT TO_CHAR(DATE '2026-05-06', 'YYYY"년" MM"월"');
-- 문자열 -> 날짜
SELECT TO_DATE('20240315', 'YYYYMMDD');
날짜 추출 함수
SELECT YEAR(date);
SELECT MONTH(date);
SELECT DAY(date);
SELECT HOUR(datetime);
SELECT MINUTE(datetime);
SELECT SECOND(datetime);
-- [참고] PostgreSQL
SELECT EXTRACT(YEAR FROM date);
SELECT EXTRACT(MONTH FROM date);
SELECT EXTRACT(DAY FROM date);
SELECT EXTRACT(HOUR FROM timestamp);
SELECT EXTRACT(MINUTE FROM timestamp);
SELECT EXTRACT(SECOND FROM timestamp);
-- 또는
SELECT DATE_PART('year', date);날짜 더하기 / 뺴기
DATE_ADD(date, INTERVAL 1 DAY)
DATE_SUB(date, INTERVAL 1 DAY)
INTERVAL 7 DAY
INTERVAL 1 MONTH
INTERVAL 1 YEAR
INTERVAL 1 HOUR
-- [참고] PostgreSQL
SELECT date + INTERVAL '1 day';
SELECT date - INTERVAL '1 day';
SELECT date + INTERVAL '7 day';
SELECT date + INTERVAL '1 month';
SELECT date + INTERVAL '1 year';
SELECT date + INTERVAL '1 hour';날짜 차이 구하기
DATEDIFF(date1, date2) -- 일(day) 단위
DATEDIFF('2024-03-10', '2024-03-01') -- 9
TIMESTAMPDIFF(unit, d1, d2)
TIMESTAMPDIFF(DAY, d1, d2)
TIMESTAMPDIFF(MONTH, d1, d2)
TIMESTAMPDIFF(YEAR, d1, d2)
-- [참고] PostgreSQL
SELECT date1 - date2; -- 일 단위 (integer)
SELECT AGE(date1, date2); -- interval 반환조건 필터링
WHERE date BETWEEN '2024-01-01' AND '2024-01-31'
-- 최근 n일
WHERE date >= DATE_SUB(CURDATE(), INTERVAL 7 DAY)
-- [참고] PostgreSQL
WHERE date BETWEEN '2024-01-01' AND '2024-01-31';
-- 최근 n일
WHERE date >= CURRENT_DATE - INTERVAL '7 day';요일 관련
DAYOFWEEK(date) -- 1:일요일 ~ 7:토요일
WEEKDAY(date) -- 0:월요일 ~ 6:일요일
-- [참고] PostgreSQL
SELECT EXTRACT(DOW FROM date); -- 0:일요일 ~ 6:토요일
SELECT TO_CHAR(date, 'Day'); -- 요일 문자열NULL
WHERE col IS NULL
WHERE col IS NOT NULLNULL 대체
IFNULL(col, 0) -- col이 null이 아니면 col출력 null이면 0(default값)으로 출력함, mysql전용
COALESCE(col1, col2, 0) -- 왼쪽부터 순서대로 검사해서 “NULL이 아닌 첫 번째 값”을 반환, 얘는 공통으로 사용 가능
비트 연산자
& -- Bitwise AND: 대응하는 두 비트가 모두 1이면 1 (가장 많이 사용)
| -- Bitwise OR: 대응하는 두 비트 중 하나라도 1이면 1
^ -- Bitwise XOR: 대응하는 두 비트가 서로 다르면 1
~ -- Bitwise NOT: 비트 반전 (0 -> 1, 1 -> 0)
<< -- Left Shift: 비트를 왼쪽으로 이동 (2의 거듭제곱 곱하기)
>> -- Right Shift: 비트를 오른쪽으로 이동 (2의 거듭제곱 나누기)비트마스크 필터링 (WHERE절)
-- 특정 비트(8, 2진수 1000)가 포함되어 있는지 확인
WHERE (SKILL_CODE & 8) = 8
WHERE (SKILL_CODE & 8) > 0 -- 위와 동일한 효과
-- 여러 비트 중 하나라도 포함되어 있는지 확인 (예: 1 또는 4)
WHERE (SKILL_CODE & (1 | 4)) > 0
-- 여러 비트가 모두 포함되어 있는지 확인 (예: 1과 4 둘 다 있음)
WHERE (SKILL_CODE & (1 | 4)) = (1 | 4)Pivot 테이블
- 행(row)에 있던 값을 열(column)로 펼쳐서 요약하는 것
-> 특정 컬럼 값을 기준으로 열을 만들어 집계하는 것
Before
| user_id | category | amount |
|---|---|---|
| 1 | food | 100 |
| 1 | book | 50 |
| 1 | tech | 200 |
After (피벗 결과)
| user_id | food | book | tech |
|---|---|---|---|
| 1 | 100 | 50 | 200 |
SELECT
user_id,
SUM(CASE WHEN category = 'food' THEN amount ELSE 0 END) AS food,
SUM(CASE WHEN category = 'book' THEN amount ELSE 0 END) AS book,
SUM(CASE WHEN category = 'tech' THEN amount ELSE 0 END) AS tech
FROM table
GROUP BY user_id;IN / EXISTS
IN
WHERE col IN (value1, value2, ...)- 특정 값이 목록 안에 포함되는지 확인
EXISTS
WHERE EXISTS (subquery)- 서브쿼리 결과가 한 건이라도 존재하면 TRUE
NULL 처리
NOT IN + NULL
SELECT *
FROM A
WHERE A.id NOT IN (SELECT B.id FROM B);- B.id에 NULL이 하나라도 있으면 -> 결과: 0 rows
이유: A.id != NULL → UNKNOWN
-
SQL에서 UNKNOWN → FALSE 취급
- NULL과의 모든 비교(=, !=, >, < ...) → UNKNOWN
-
전체 조건이 성립하지 않음
EXISTS, NOT EXISTS (NULL 안전)
- NULL이 있어도 정상 동작
Join
- JOIN(INNER JOIN), LEFT JOIN, RIGHT JOIN, CROSS JOIN, SELF JOIN, FULL OUTER JOIN(MYSQL은 없음 -> UNION으로 LEFT, RIGHT 해야함)
USING
SELECT *
FROM A
JOIN B USING (id);- ON A.id = B.id 생략 버전
서브쿼리
WHERE
SELECT *
FROM A
WHERE col = (
SELECT col
FROM B
WHERE 조건
);
SELECT *
FROM A
WHERE col IN (
SELECT col
FROM B
);
SELECT *
FROM A
WHERE EXISTS (
SELECT 1
FROM B
WHERE A.id = B.id
);
-- ANY
SELECT *
FROM A
WHERE col > ANY (
SELECT col FROM B
);
-- ALL
SELECT *
FROM A
WHERE col > ALL (
SELECT col FROM B
);FROM
SELECT *
FROM (
SELECT col, COUNT(*) AS cnt
FROM A
GROUP BY col
) t; - 반드시 별칭 필요
SELECT
SELECT
A.id,
(SELECT COUNT(*) FROM B WHERE B.id = A.id) AS cnt
FROM A;
집계 함수
예제 테이블 - Sales
| Region (지역) | Product (상품) | SalesAmount (매출) |
|---|---|---|
| Seoul | TV | 1000 |
| Seoul | Radio | 500 |
| Busan | TV | 800 |
| Busan | Radio | 300 |
ROLLUP
- 나열된 컬럼의 순서에 따라 계층적인 소계를 생성합니다. (오른쪽에서 왼쪽 방향으로 그룹을 하나씩 줄여나갑니다.) 예제의 그룹은 (Region, Product), (Region)
SELECT Regin, Proudct, SUM(SalesAmount) AS Total
FROM Sales
GROUP BY ROLLUP(Region, Product);| Region | Product | Total | 설명 |
|---|---|---|---|
| Seoul | TV | 1000 | 지역별/상품별 합계 |
| Seoul | Radio | 500 | 지역별/상품별 합계 |
| Seoul | NULL | 1500 | Seoul 지역 소계 |
| Busan | TV | 800 | 지역별/상품별 합계 |
| Busan | Radio | 300 | 지역별/상품별 합계 |
| Busan | NULL | 1100 | Busan 지역 소계 |
| NULL | NULL | 2600 | 전체 총계 (Grand Total) |
CUBE
- 모든 조합에 대해 집계를 생성합니다.
SELECT Region, Product, SUM(SalesAmount) AS Total
FROM Sales
GROUP BY CUBE(Region, Product);| Region | Product | Total | 설명 |
|---|---|---|---|
| Seoul | TV | 1000 | 지역별/상품별 |
| Seoul | Radio | 500 | 지역별/상품별 |
| Busan | TV | 800 | 지역별/상품별 |
| Busan | Radio | 300 | 지역별/상품별 |
| Seoul | NULL | 1500 | Seoul 소계 |
| Busan | NULL | 1100 | Busan 소계 |
| NULL | TV | 1800 | TV 전체 합계 (Region 무관) |
| NULL | Radio | 800 | Radio 전체 합계 (Region 무관) |
| NULL | NULL | 2600 | 전체 총계 |
GROUPING SETS
- 사용자가 원하는 조합만 골라서 집계할 수 있게 해줍니다.
SELECT Region, Product, SUM(SalesAmount) AS Total
FROM Sales
GROUP BY GROUPING SETS (Region, Product);| Region | Product | Total | 설명 |
|---|---|---|---|
| Seoul | NULL | 1500 | 지역별 합계 |
| Busan | NULL | 1100 | 지역별 합계 |
| NULL | TV | 1800 | 상품별 합계 |
| NULL | Radio | 800 | 상품별 합계 |
참고: 전체 총계나 상세 내역은 사용자가 명시하지 않았으므로 나오지 않습니다.
나오게 하고 싶다면?
GROUP BY GROUPING SETS (
(Region, Product), -- 1. 상세 내역
(Region), -- 2. 지역별 소계
(Product), -- 3. 상품별 소계
() -- 4. 전체 총계 (이 부분이 핵심!)
);윈도우 함수
- 보통 over()절이 붙는 함수들
- 윈도우 함수(Window Function)는 행과 행 사이의 관계를 정의하지만,
GROUP BY와 달리 행을 하나로 합치지 않고 개별 행의 상세 정보를 그대로 유지하면서 계산을 수행하는 아주 강력한 도구입니다.
함수이름() OVER (
[PARTITION BY 컬럼] -- 그룹 분할 (선택)
[ORDER BY 컬럼] -- 정렬 기준 (선택)
[ROWS/RANGE BETWEEN ...] -- 프레임 범위 (선택)
)PARTITION BY: 데이터를 어떤 단위로 묶어서 계산할지 결정합니다 (엑셀의 '그룹화').ORDER BY: 그 그룹 안에서 어떤 순서로 계산을 진행할지 결정합니다.ROWS/RANGE(Window Frame): 현재 행을 기준으로 계산에 포함할 앞뒤 행의 범위를 세밀하게 정합니다.
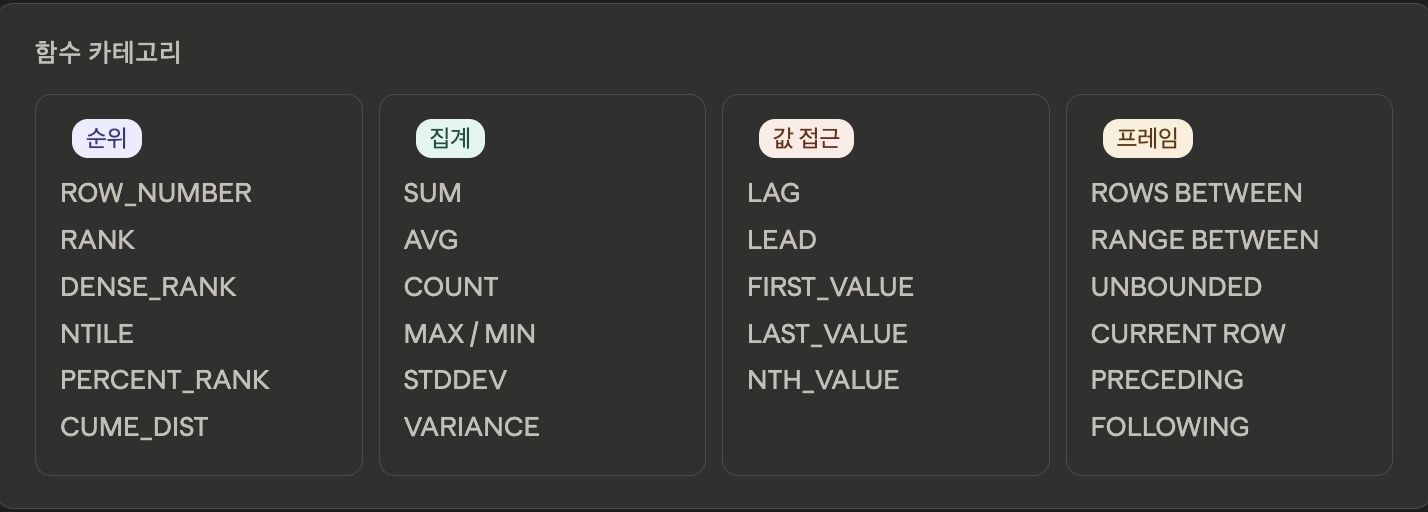
주요 함수
| 분류 | 함수 | 설명 |
|---|---|---|
| 순위 (Ranking) | ROW_NUMBER() | 중복 없이 무조건 1, 2, 3... 순번 부여 |
RANK() | 공동 순위만큼 건너뜀 (1, 2, 2, 4...) | |
DENSE_RANK() | 공동 순위가 있어도 연속 번호 부여 (1, 2, 2, 3...) | |
| 집계 (Aggregate) | SUM(), AVG() | 누적 합계나 이동 평균 계산 |
COUNT(), MIN() | 그룹 내 개수나 최솟값 계산 | |
| 탐색 (Value) | LAG() | 현재 행보다 이전 행의 값을 가져옴 |
LEAD() | 현재 행보다 다음 행의 값을 가져옴 | |
FIRST_VALUE() | 윈도우 내 첫 번째 값을 가져옴 | |
| 분포 (Distribution) | NTILE(n) | 데이터를 n개의 등급으로 균등하게 분할 |
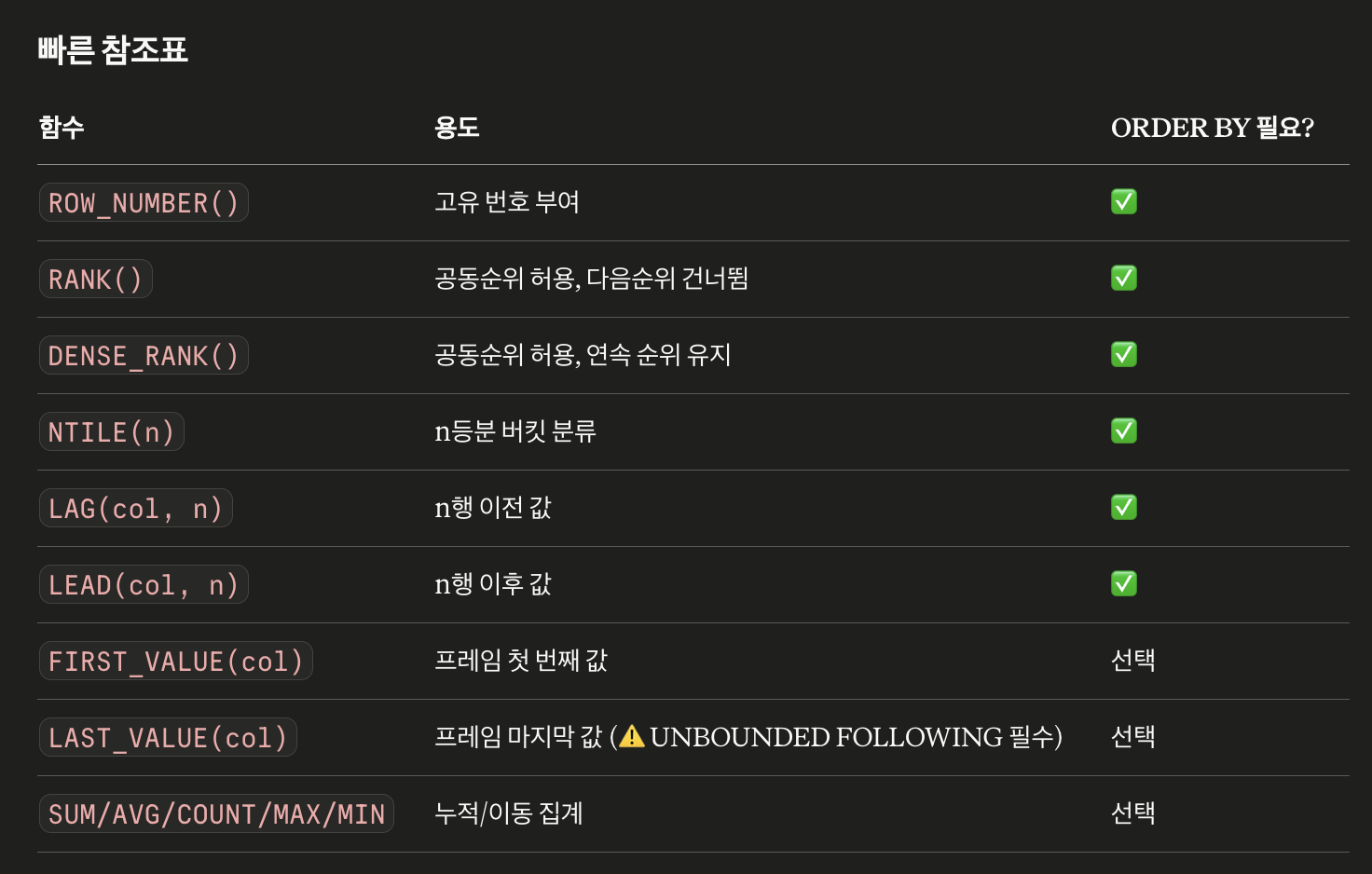
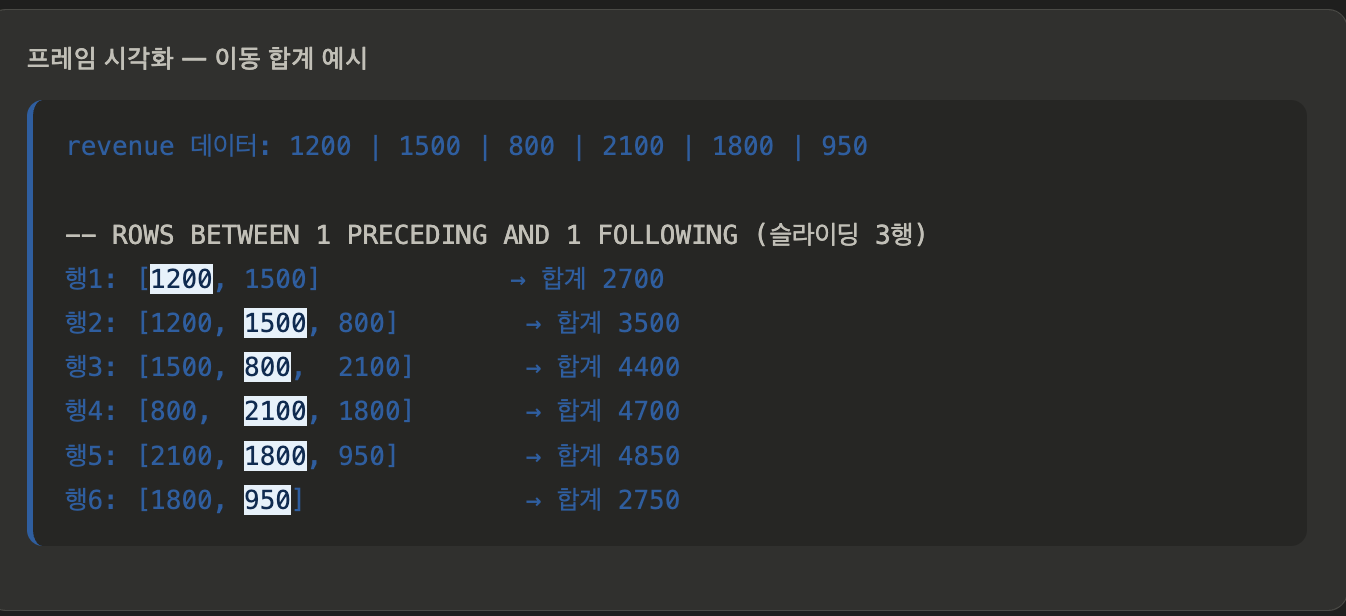
프레임 설정 (Window Frame)
계산 범위를 "현재 행 기준 앞뒤 몇 칸"으로 제한할 때 씁니다. 누적 합계나 이동 평균을 구할 때 필수입니다.
UNBOUNDED PRECEDING: 맨 첫 행부터UNBOUNDED FOLLOWING: 맨 끝 행까지n PRECEDING: 현재 행 기준 앞 n번째 행부터CURRENT ROW: 현재 행
예시:
ROWS BETWEEN 2 PRECEDING AND CURRENT ROW→ "나와 내 앞의 2행, 즉 총 3행의 평균을 구해라" (3일 이동 평균)
ORDER BY가 있을 때 기본 프레임은 RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW입니다. 명시적으로 지정하면 원하는 범위를 정확히 제어할 수 있습니다.
ROWS | RANGE BETWEEN
{ UNBOUNDED PRECEDING -- 파티션 첫 행부터
| N PRECEDING -- N행 이전부터
| CURRENT ROW -- 현재 행
}
AND
{ CURRENT ROW -- 현재 행까지
| N FOLLOWING -- N행 이후까지
| UNBOUNDED FOLLOWING -- 파티션 끝까지
}
윈도우 함수 사용 시 주의사항
WHERE절에서 바로 못 씀: 윈도우 함수는SELECT절이나ORDER BY절에서만 사용할 수 있습니다. 만약 윈도우 함수의 결과로 필터링하고 싶다면, 반드시 CTE(WITH)나 서브쿼리로 먼저 감싸야 합니다.
- 잘못된 예:SELECT * FROM table WHERE RANK() OVER(...) = 1(에러!)
- 올바른 예:WITH tmp AS (SELECT ..., RANK() OVER(...) as rnk FROM table) SELECT * FROM tmp WHERE rnk = 1
GROUP BY와 혼용 불가- 리소스 소모: 대량의 데이터에서
ORDER BY가 포함된 윈도우 함수를 남용하면 쿼리 속도가 느려질 수 있습니다. 하지만 빅쿼리 같은 분산 DB는 이를 매우 효율적으로 처리하는 편입니다.
윈도우 예시
순위 함수
ROW_NUMBER
SELECT name, dept, salary,
ROW_NUMBER() OVER (
PARTITION BY dept
ORDER BY salary DESC
) AS row_num
FROM employees;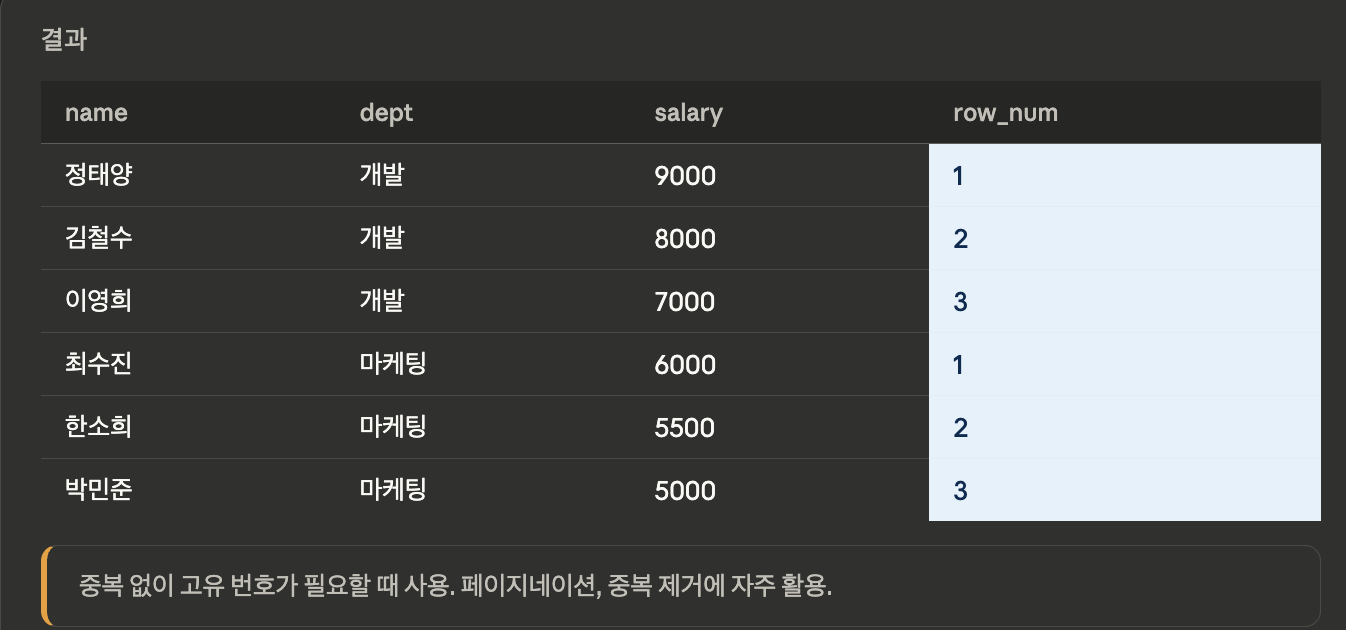
RANK
SELECT name, dept, salary,
RANK() OVER (
ORDER BY salary DESC
) AS rnk
FROM employees;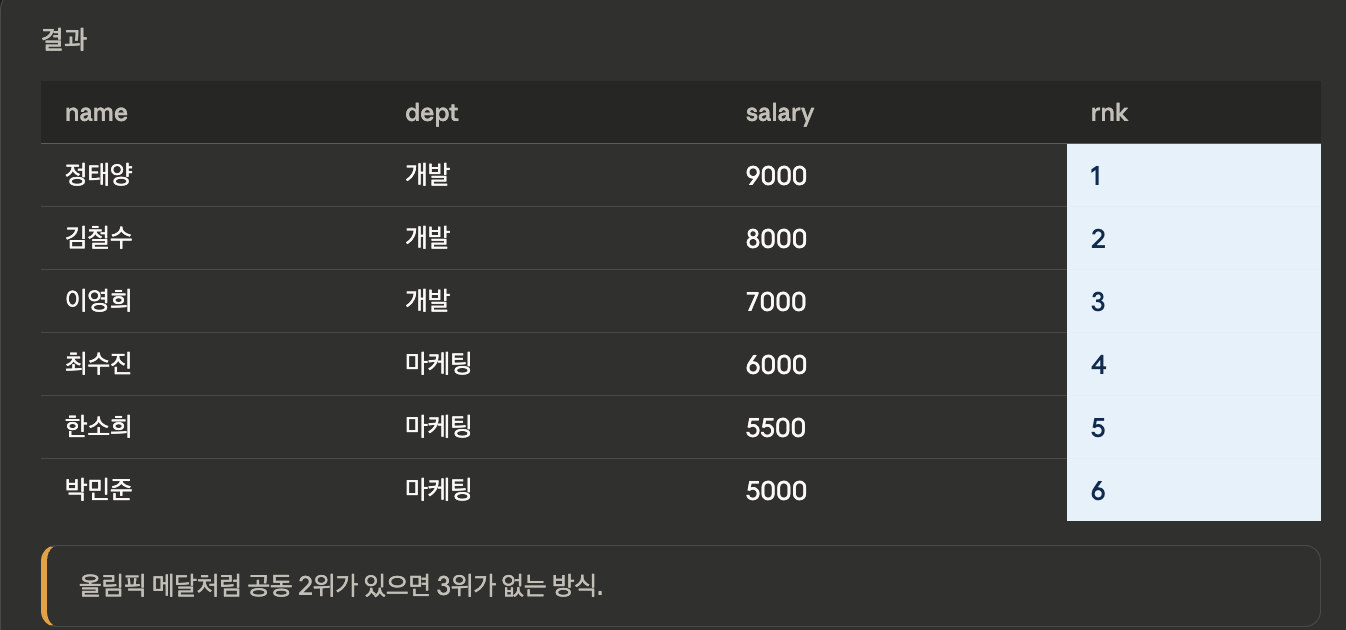
DENSE_RANK
SELECT name, dept, salary,
DENSE_RANK() OVER (
ORDER BY salary DESC
) AS d_rnk
FROM employees;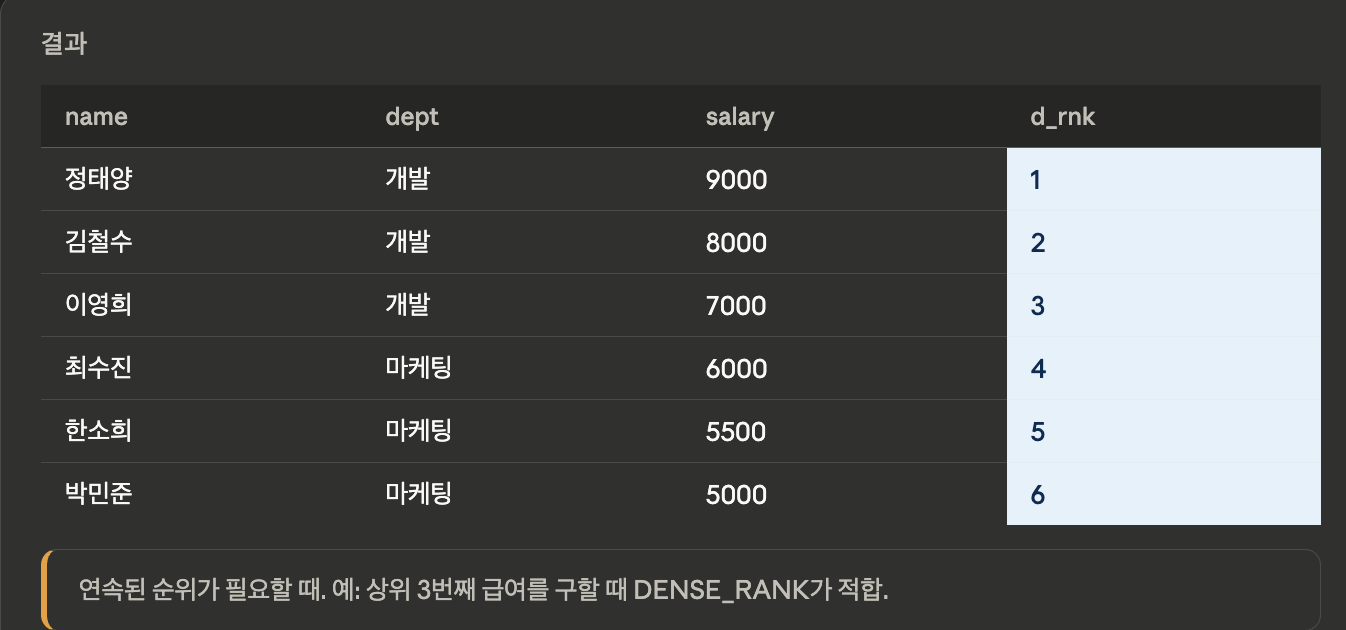
NTILE
- 행들을 N개의 그룹으로 균등하게 나눕니다. 4분위수, 10분위수 계산에 활용
SELECT name, salary,
NTILE(3) OVER (
ORDER BY salary DESC
) AS bucket
FROM employees;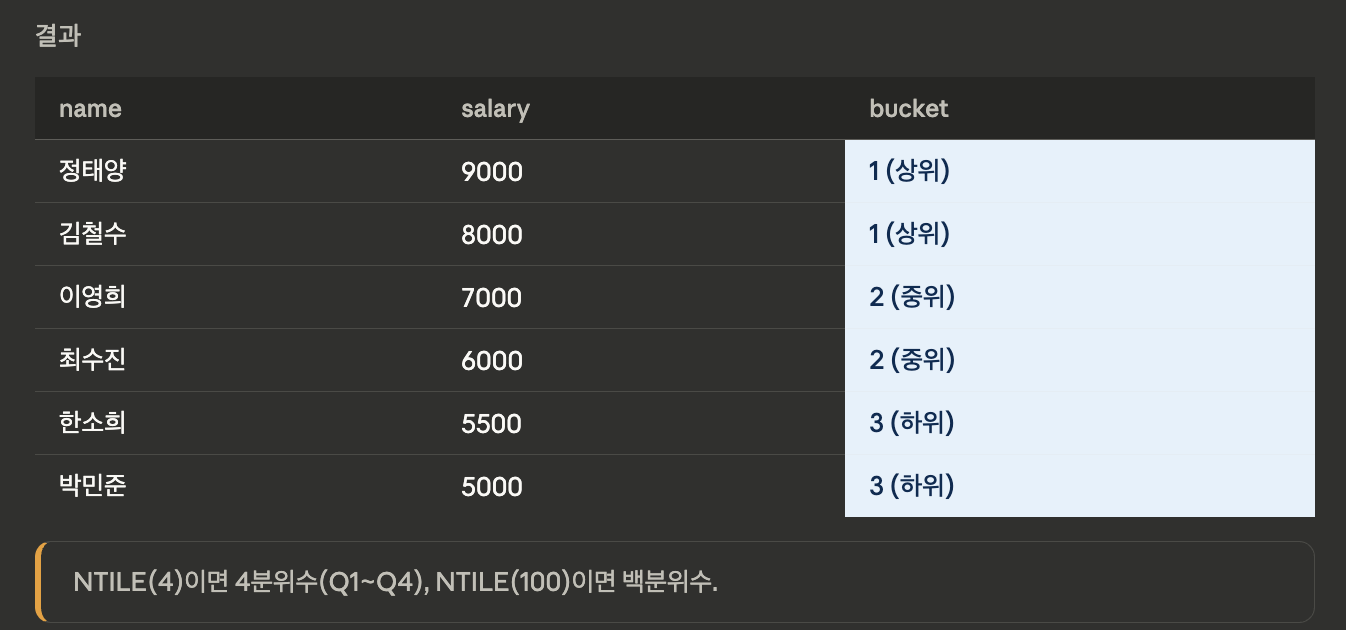
PERCENT_RANK
- 행의 상대적 순위를 0~1 사이 퍼센트로 반환. 공식: (rank-1) / (total_rows-1)
SELECT name, salary,
RANK() OVER (ORDER BY salary) AS rnk,
ROUND(PERCENT_RANK() OVER (
ORDER BY salary
), 2) AS pct_rank
FROM employees;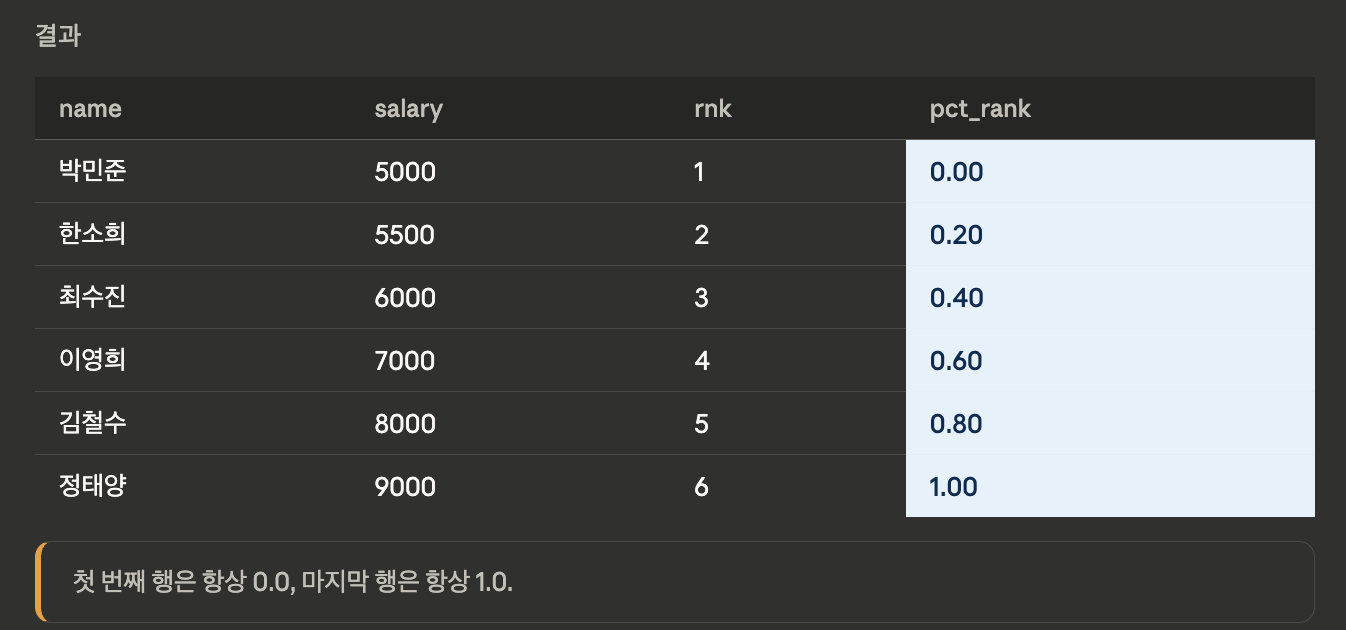
CUME_DIST
- 누적 분포값. 현재 행 이하인 행의 비율을 반환. 공식: rank / total_rows
SELECT name, salary,
ROUND(CUME_DIST() OVER (
ORDER BY salary
), 2) AS cum_dist
FROM employees;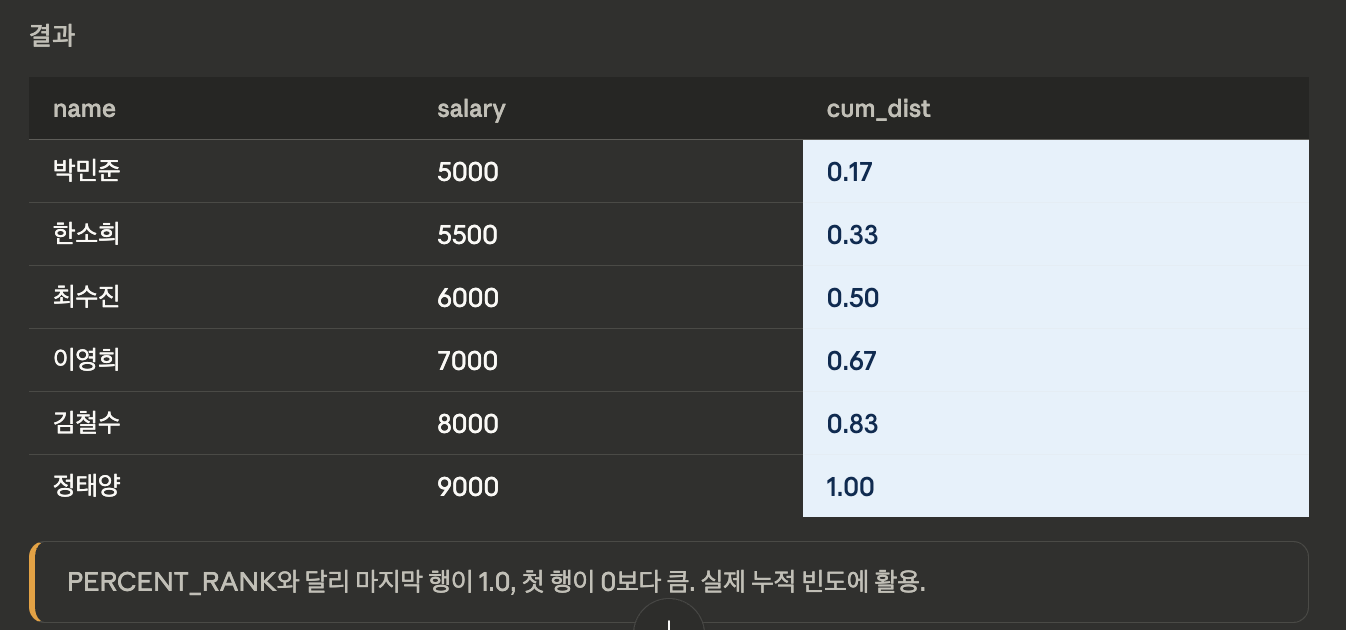
집계 함수
sum
- 파티션 내 누적 합계(Cumulative SUM) 또는 전체 합계를 구합니다.
SELECT name, dept, revenue,
-- 전체 합계 비율
ROUND(revenue * 100.0 / SUM(revenue) OVER (), 1) AS pct_total,
-- 부서별 누적 합계
SUM(revenue) OVER (
PARTITION BY dept
ORDER BY month
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
) AS cum_sum
FROM sales;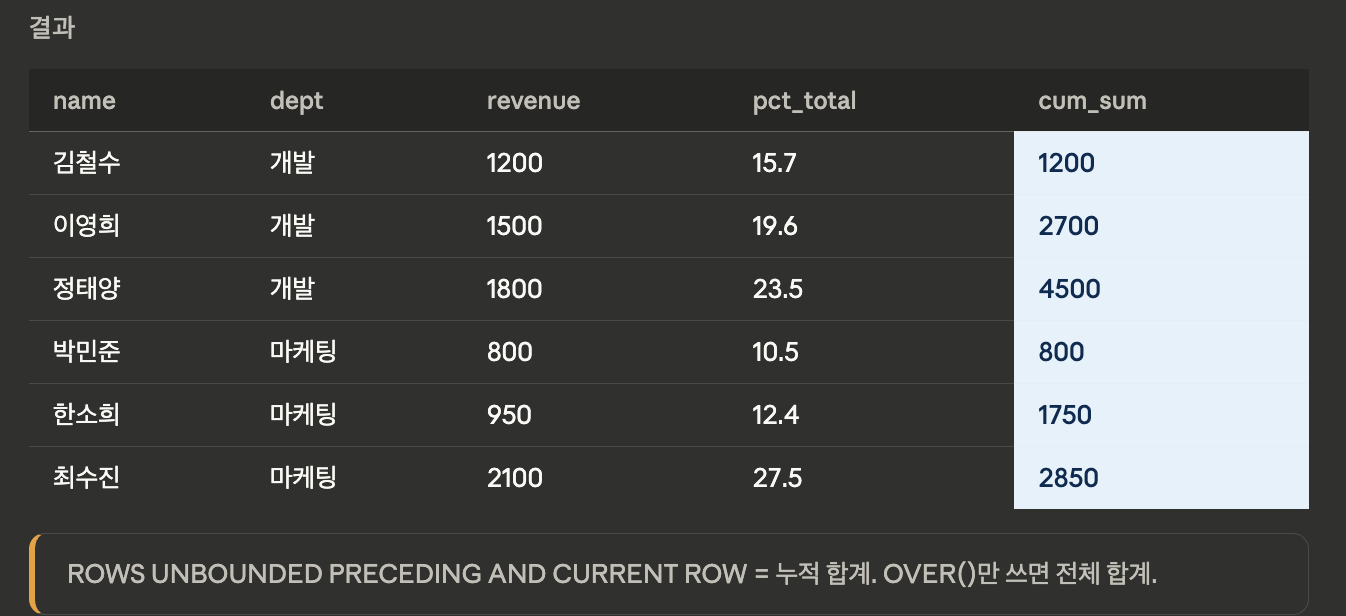
AVG
- 이동 평균(Moving Average)을 구하거나 파티션 내 평균과 비교합니다.
SELECT name, month, revenue,
-- 부서 평균 대비 차이
revenue - AVG(revenue) OVER (
PARTITION BY dept
) AS diff_from_avg,
-- 3개월 이동 평균
ROUND(AVG(revenue) OVER (
ORDER BY month
ROWS BETWEEN 2 PRECEDING AND CURRENT ROW
), 0) AS moving_avg_3m
FROM sales;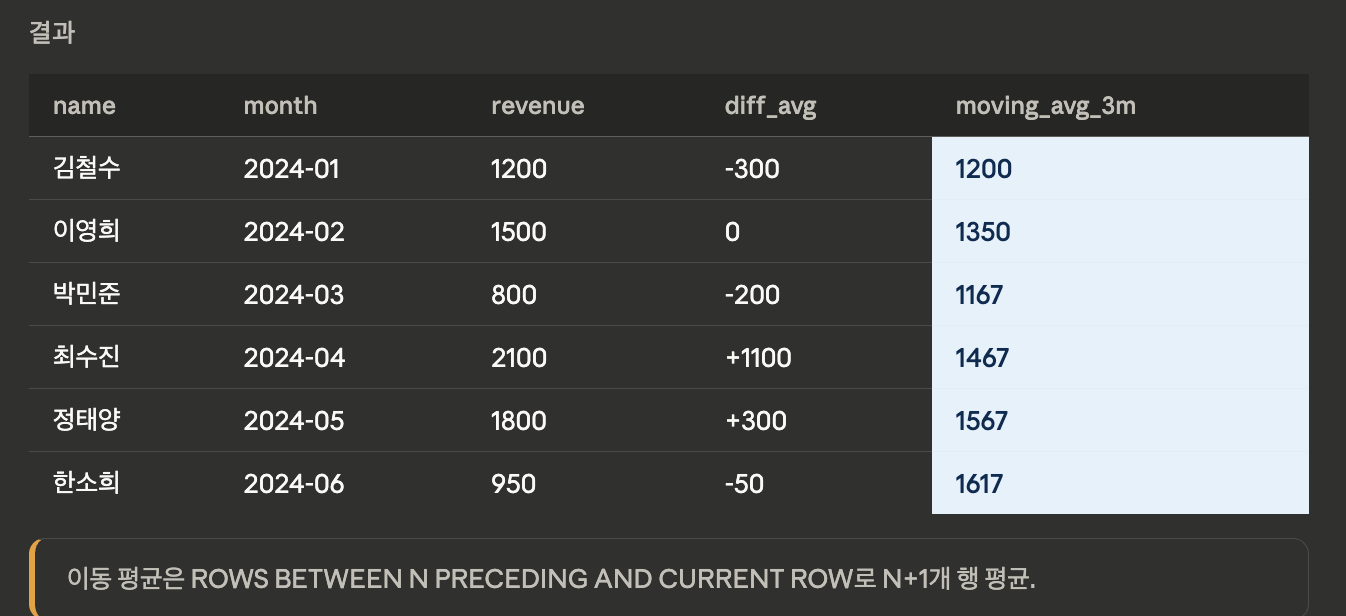
COUNT
- 파티션 내 행 수를 계산합니다. 부서별 인원 수, 누적 건수 등에 활용.
SELECT name, dept,
-- 부서별 인원 수
COUNT(*) OVER (
PARTITION BY dept
) AS dept_count,
-- 전체 대비 부서 비율
ROUND(COUNT(*) OVER (PARTITION BY dept) * 100.0
/ COUNT(*) OVER (), 1) AS dept_pct
FROM employees;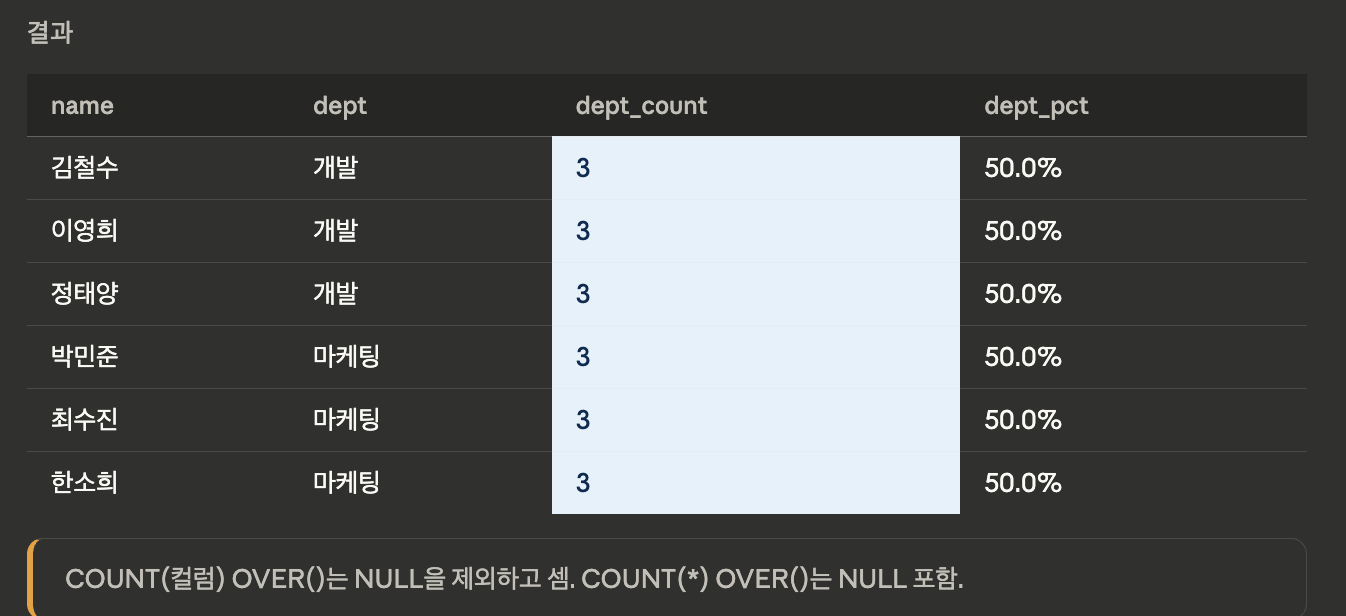
MAX/MIN
SELECT name, dept, salary,
MAX(salary) OVER (PARTITION BY dept) AS dept_max,
MIN(salary) OVER (PARTITION BY dept) AS dept_min,
salary - MIN(salary) OVER (PARTITION BY dept)
AS above_min
FROM employees;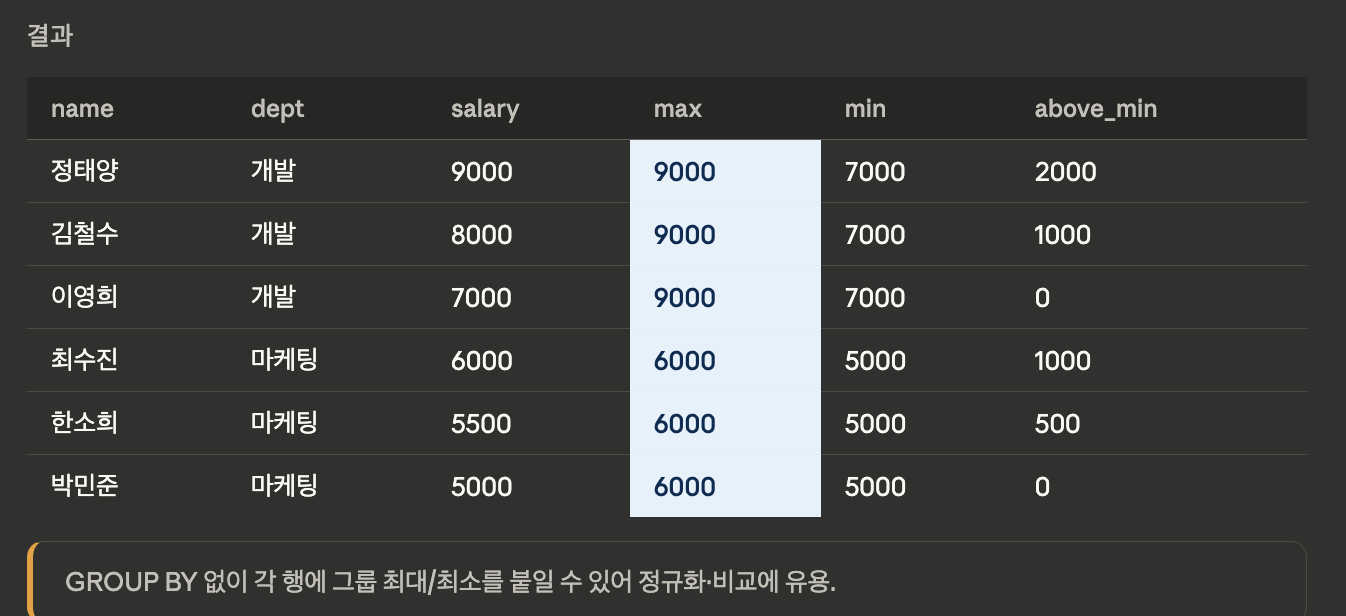
값 함수
LAG
- 현재 행으로부터 N행 이전 값을 가져옵니다. 이전 달 비교, 전일 대비 변화 분석에 활용.
SELECT month, revenue,
LAG(revenue, 1, 0) OVER (
ORDER BY month
) AS prev_month,
revenue - LAG(revenue, 1, 0) OVER (
ORDER BY month
) AS mom_change -- Month over Month
FROM sales;
-- LAG(값, 오프셋, 기본값)
-- 기본값: 이전 행 없을 때 반환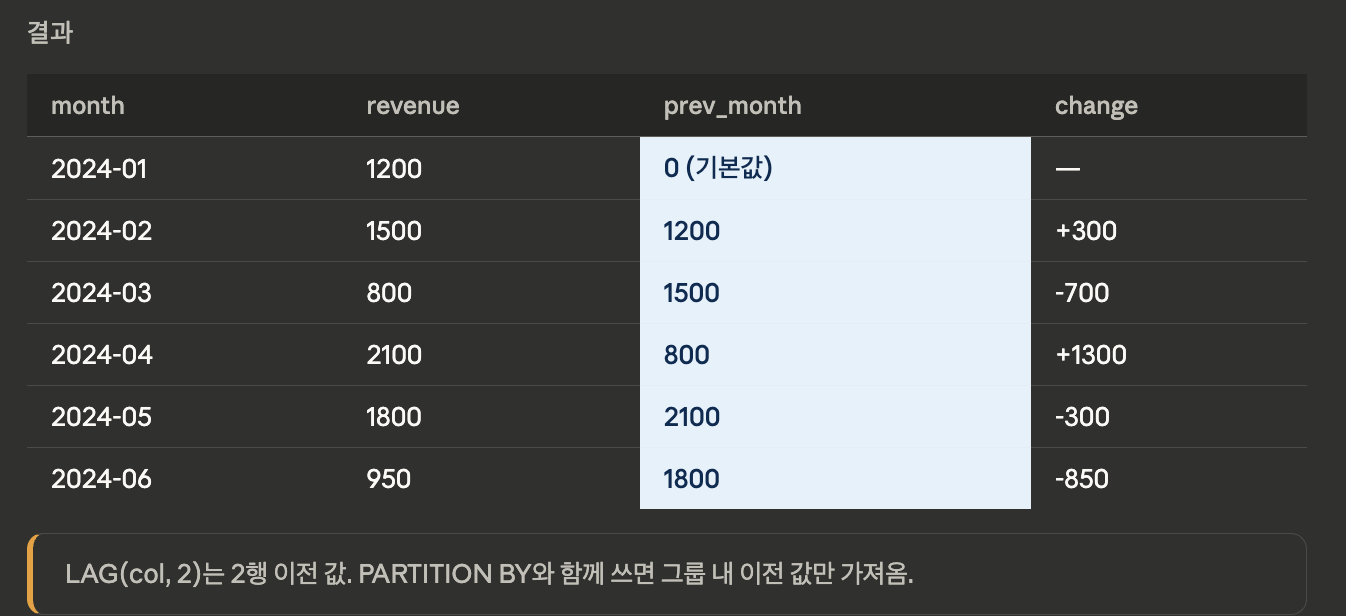
LEAD
- 현재 행으로부터 N행 이후 값을 가져옵니다. 다음 달 예측 비교, 세션 종료 시간 계산에 활용.
SELECT month, revenue,
LEAD(revenue, 1) OVER (
ORDER BY month
) AS next_month,
ROUND((LEAD(revenue,1) OVER (ORDER BY month)
- revenue) * 100.0 / revenue, 1) AS growth_pct
FROM sales;
FIRST_VALUE
- 파티션(또는 프레임) 내 첫 번째 값을 반환합니다.
SELECT name, dept, salary,
FIRST_VALUE(name) OVER (
PARTITION BY dept
ORDER BY salary DESC
) AS top_earner,
FIRST_VALUE(salary) OVER (
PARTITION BY dept
ORDER BY salary DESC
) AS max_salary
FROM employees;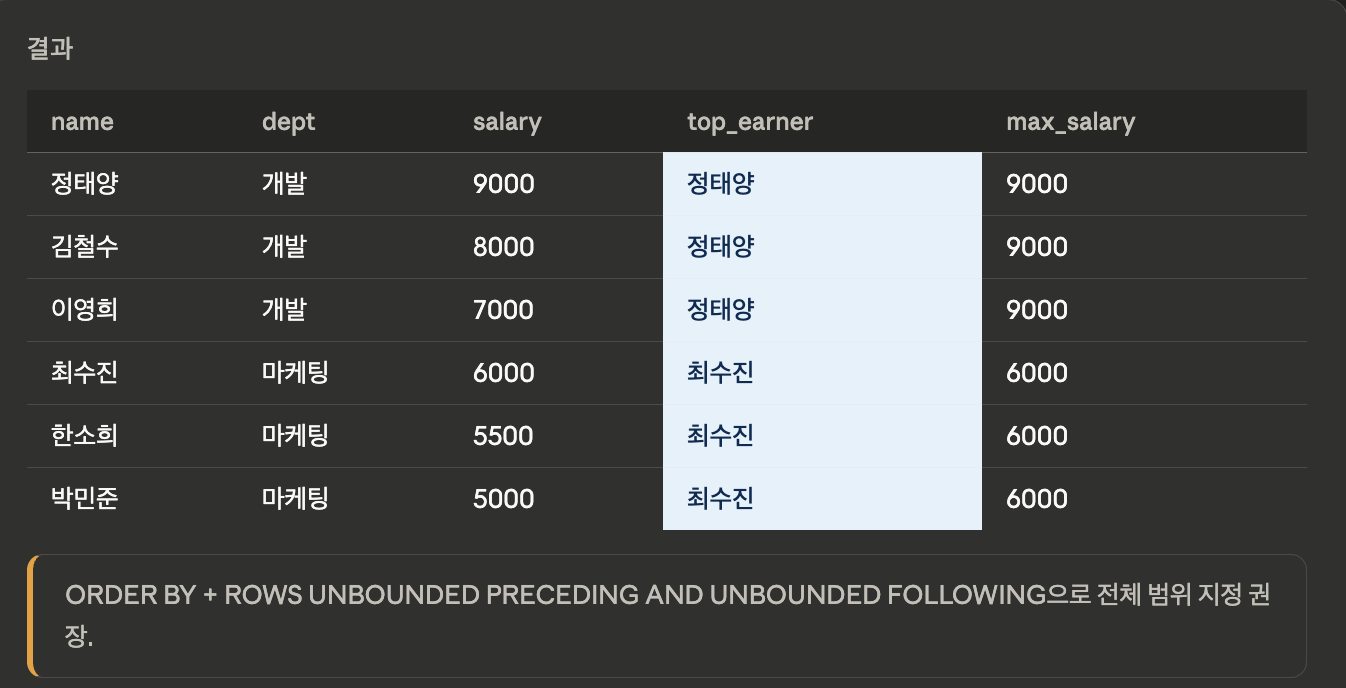
LAST_VALUE
- 파티션 내 마지막 값을 반환합니다. 기본 프레임이 CURRENT ROW이므로 UNBOUNDED FOLLOWING 명시 필요.
SELECT name, dept, salary,
LAST_VALUE(name) OVER (
PARTITION BY dept
ORDER BY salary DESC
ROWS BETWEEN UNBOUNDED PRECEDING
AND UNBOUNDED FOLLOWING
) AS lowest_earner
FROM employees;
-- ⚠️ 주의: ROWS UNBOUNDED FOLLOWING
-- 없으면 항상 현재 행이 마지막이 됨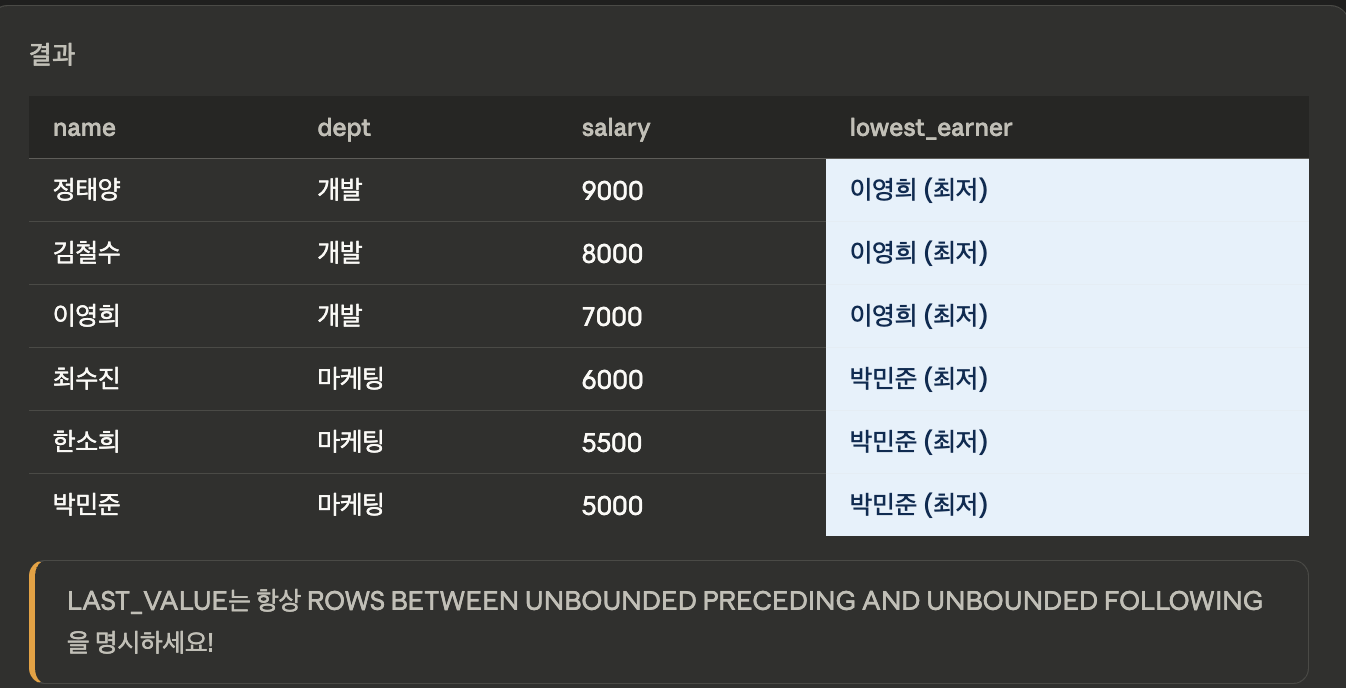
NTH_VALUE
- 파티션 내 N번째 행의 값을 반환합니다. (1-based index)
SELECT name, dept, salary,
NTH_VALUE(name, 1) OVER (
PARTITION BY dept
ORDER BY salary DESC
ROWS BETWEEN UNBOUNDED PRECEDING
AND UNBOUNDED FOLLOWING
) AS rank1_name,
NTH_VALUE(salary, 2) OVER (
PARTITION BY dept
ORDER BY salary DESC
ROWS UNBOUNDED PRECEDING
AND UNBOUNDED FOLLOWING
) AS rank2_salary
FROM employees;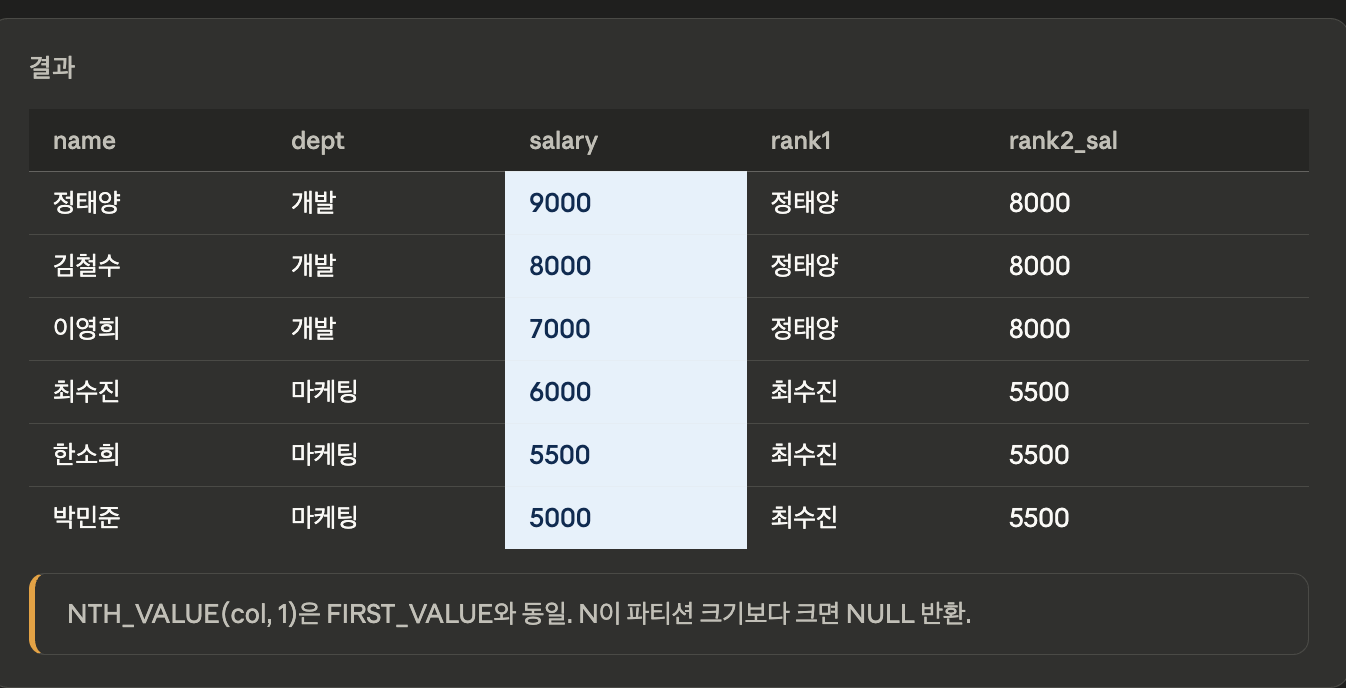
실전 패턴
① 중복 제거 — 최신 레코드만 남기기
WITH ranked AS (
SELECT *,
ROW_NUMBER() OVER (
PARTITION BY user_id
ORDER BY created_at DESC
) AS rn
FROM orders
)
SELECT * FROM ranked WHERE rn = 1;
-- 사용자별 가장 최근 주문만 추출② TOP-N per Group — 부서별 상위 2명
WITH ranked AS (
SELECT name, dept, salary,
DENSE_RANK() OVER (
PARTITION BY dept
ORDER BY salary DESC
) AS dr
FROM employees
)
SELECT * FROM ranked WHERE dr <= 2;
-- GROUP BY로는 불가능한 패턴!③ 세션 분석 — 페이지뷰 세션 구분
WITH gaps AS (
SELECT user_id, page, ts,
LAG(ts) OVER (
PARTITION BY user_id ORDER BY ts
) AS prev_ts
FROM pageviews
),
sessions AS (
SELECT *,
SUM(CASE WHEN ts - prev_ts > 1800 -- 30분 간격
THEN 1 ELSE 0 END)
OVER (PARTITION BY user_id ORDER BY ts) AS session_id
FROM gaps
)
SELECT user_id, session_id, COUNT(*) AS pageviews
FROM sessions GROUP BY 1,2;④ 전월 대비 성장률 + 이동 평균
SELECT
month,
revenue,
LAG(revenue) OVER (ORDER BY month) AS prev,
ROUND((revenue - LAG(revenue) OVER (ORDER BY month))
* 100.0 / LAG(revenue) OVER (ORDER BY month), 1) AS mom_pct,
ROUND(AVG(revenue) OVER (
ORDER BY month
ROWS BETWEEN 2 PRECEDING AND CURRENT ROW
), 0) AS ma3
FROM monthly_revenue;⑤ 누적 점유율 (Running %) + 파레토
WITH ranked AS (
SELECT product, revenue,
SUM(revenue) OVER (
ORDER BY revenue DESC
ROWS UNBOUNDED PRECEDING AND CURRENT ROW
) AS cum_rev,
SUM(revenue) OVER () AS total_rev
FROM sales
)
SELECT product, revenue,
ROUND(cum_rev * 100.0 / total_rev, 1) AS cum_pct,
CASE WHEN cum_rev * 1.0 / total_rev <= 0.8
THEN '상위 80%' ELSE '나머지 20%'
END AS pareto
FROM ranked;⑥ NAMED WINDOW — 재사용 윈도우 정의
SELECT
name, dept, salary,
ROW_NUMBER() OVER w AS rn,
RANK() OVER w AS rnk,
DENSE_RANK() OVER w AS d_rnk,
AVG(salary) OVER w AS avg_sal
FROM employees
WINDOW w AS (
PARTITION BY dept
ORDER BY salary DESC
);
-- PostgreSQL, MySQL 8+, BigQuery 지원
취준생의 개발블로그