데이터베이스에 100만 개의 테스트 데이터를 순식간에 때려 넣는 방법
docker run --rm -e POSTGRES_PASSWORD=postgres --name pg postgres
docker exec -it pg psql -U postgres
create table temp (t int);
# 테이블 확인
\dt
insert into temp(t) select random()*100 from generate_series(0,100000)
select count(*) from temp;
-
generate_series()와 random()을 조합하면 단 한 줄의 SQL 쿼리로 100만 개의 랜덤 데이터를 생성할 수 있습니다.
-
응용: 문자열이 필요하다면 CHR() 함수와 ASCII 코드를 활용하여 랜덤한 이름이나 주소 등도 충분히 만들어낼 수 있습니다.
실습 준비
docker run --rm --name pg -e POSTGRES_PASSWORD=postgres -d postgres
docker exec -it pg psql -U postgres
create table employees( id serial primary key, name text);
\d employees;
create or replace function random_string(length integer) returns text
as $$
declare
chars text[] := '{0,1,2,3,4,5,6,7,8,9,A,B,C,D,E,F,G,H,I,J,K,L,M,N,O,P,Q,R,S,T,U,V,W,X,Y,Z,a,b,c,d,e,f,g,h,i,j,k,l,m,n,o,p,q,r,s,t,u,v,w,x,y,z}';
result text := '';
i integer := 0;
length2 integer := (select trunc(random() * length + 1));
begin
if length2 < 0 then
raise exception 'Given length cannot be less than 0';
end if;
for i in 1..length2 loop
result := result || chars[1+random()*(array_length(chars, 1)-1)];
end loop;
return result;
end;
$$ language plpgsql;
insert into employees(name)(select random_string(10) from generate_series(0, 11000000));인덱스
인덱스 작동 원리
- 인덱스는 보통 B-Tree 구조로 관리됩니다. 시간복잡도는
- 데이터가 많아져도 탐색 속도가 매우 안정적입니다.
실험해보기
explain analyze 명령어는 쿼리를 실제로 실행한 뒤, 예상치와 실제 수행 시간을 비교해서 보여주는 가장 강력한 분석 도구입니다.
(주의: INSERT나 DELETE 쿼리에 사용하면 실제로 데이터가 변합니다!)
실행하기 싫다면?!
BEGIN;
EXPLAIN ANALYZE DELETE FROM orders WHERE ...;
ROLLBACK; -- 분석만 하고 실제 반영은 취소!Index Only Scan(인라인 쿼리)
인덱스에 포함된 데이터만으로 쿼리 결과를 즉시 반환하는 최적화된 스캔 방식
-
핵심 원리: 필요한 모든 컬럼이 인덱스에 이미 존재하기 때문에, 비용이 많이 드는 테이블 블록 방문(Heap Fetch) 과정을 생략합니다.
-
장점: 디스크 I/O가 획기적으로 줄어들어 실행 속도가 매우 빠릅니다.
-
조건: SELECT 절과 WHERE 절에 사용된 모든 컬럼이 해당 인덱스에 포함되어 있어야 합니다.
explain analyze select id from employees where id = 1000;
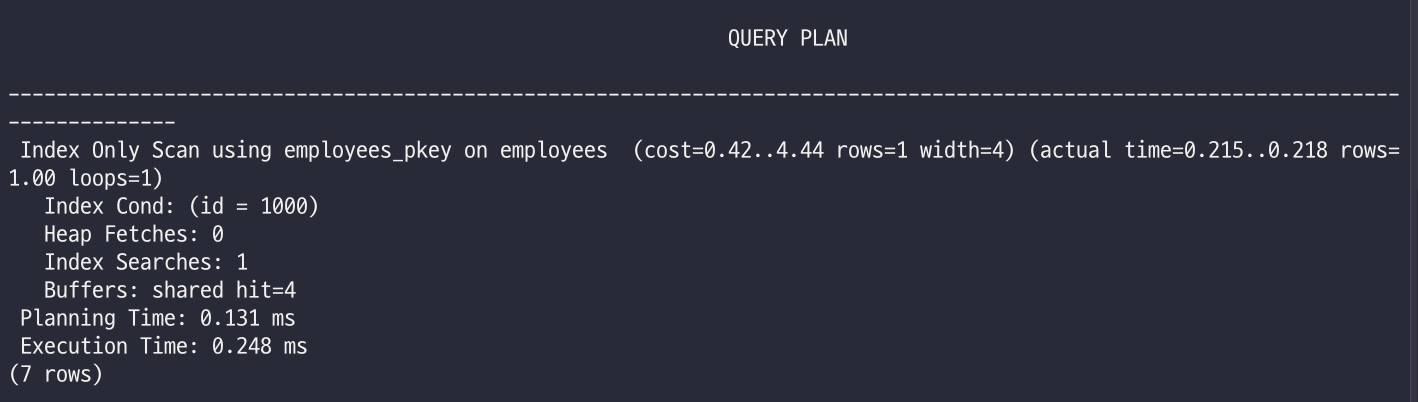
heap fetches: 0 입니다.
- 개념: 쿼리가 필요로 하는 모든 컬럼이 이미 인덱스 안에 포함되어 있어서, 실제 데이터 블록(Heap)을 단 한 번도 열어보지 않고 결과를 반환하는 방식입니다.
- 왜 최고인가?:
- 디스크 I/O 절감: 인덱스는 실제 테이블보다 훨씬 가볍습니다. 힙(Heap)으로 점프하는 과정 자체가 생략되니 물리적인 이동 거리가 0이 됩니다.
Index Scan
인덱스에서 주소를 찾고 → 테이블에 가서 나머지 정보를 가져옵니다. (필요한 컬럼이 인덱스에 다 없을 때 발생)
explain analyze select name from employees where id = 10000;
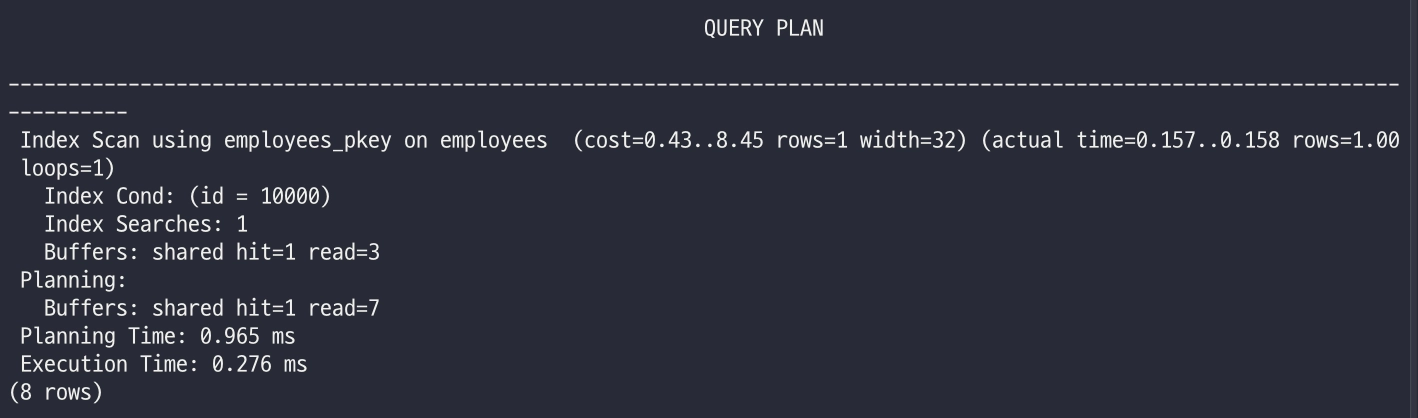
-
insert 과정에서 버퍼에 저장되어서 빠르게 찾아지는 거 같네요.
-
인덱스로 찾았지만 이름이 인덱스에 없다면 실제 테이블(Heap)이 저장된 디스크 페이지를 한 번 더 읽어야 하므로 추가 비용이 발생합니다.
Seq Scan
인덱스를 전혀 사용하지 않고 테이블의 처음부터 끝까지 모든 행을 하나하나 순차적으로 읽어 조건에 맞는 데이터를 찾는 방식입니다.
explain analyze select id from employees where name = 'GaBpJ';
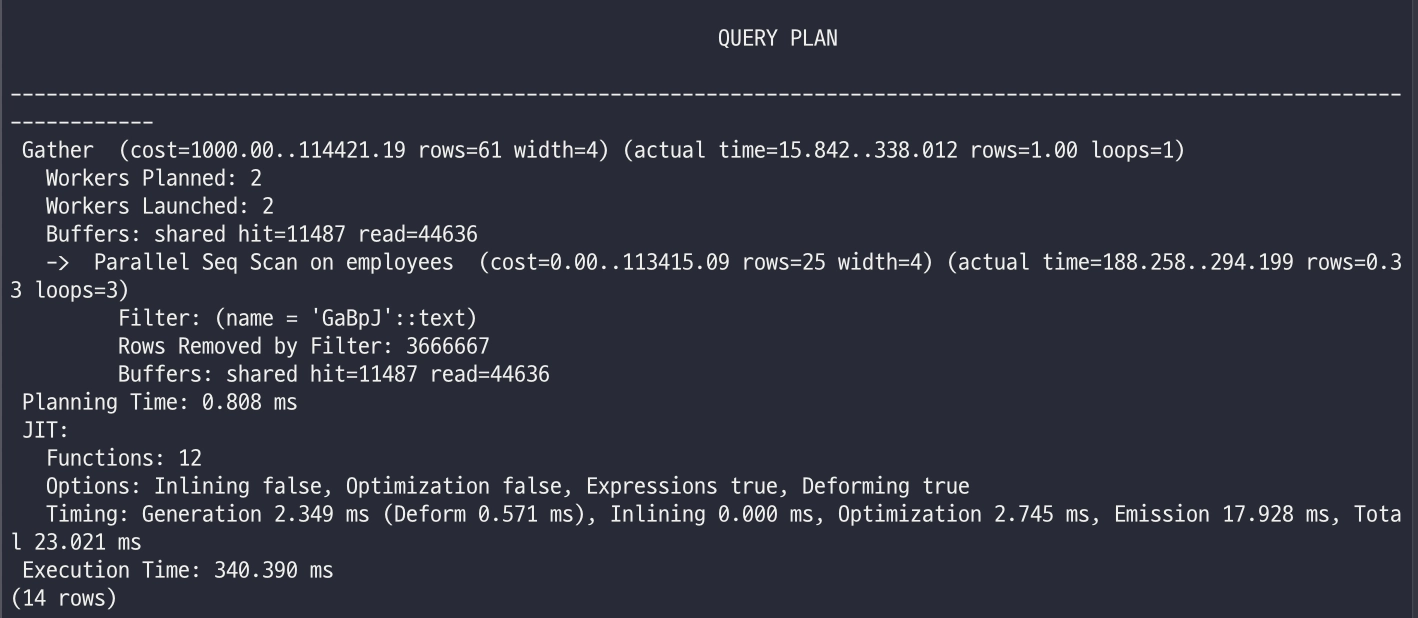
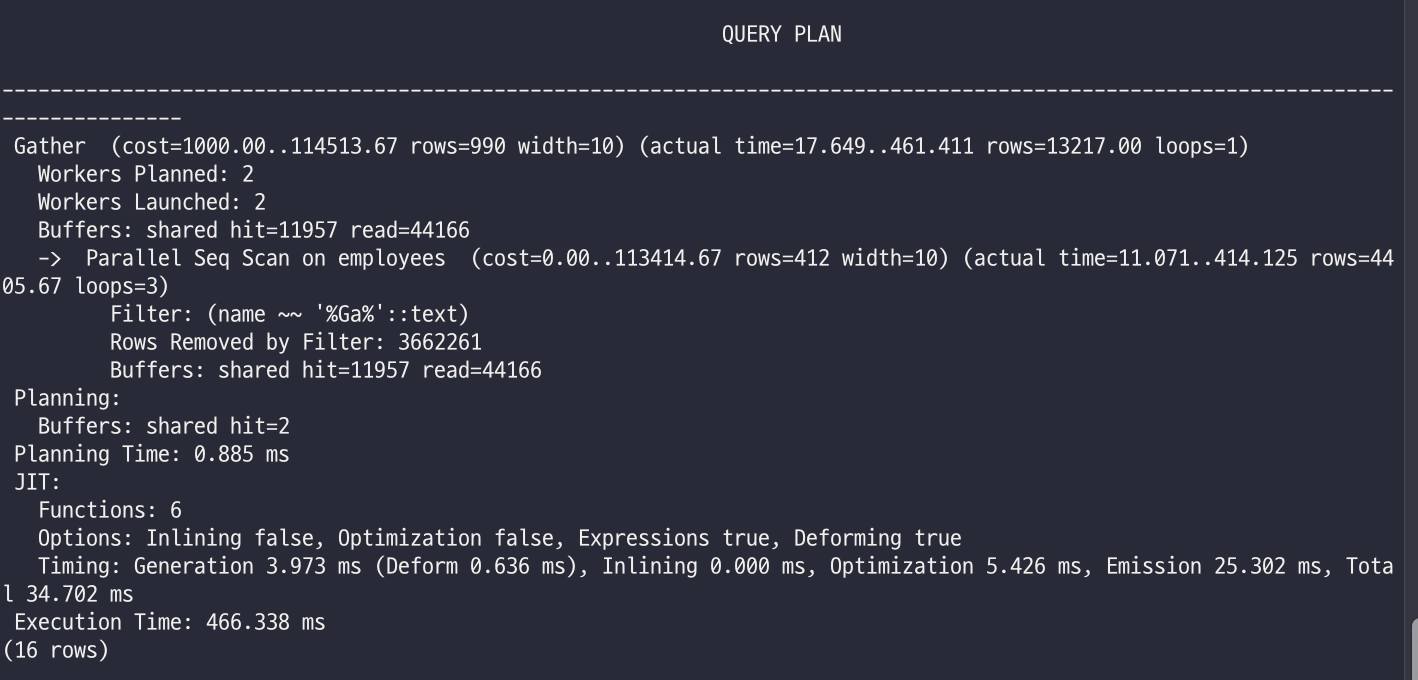
- 확실히 인덱스에 없는 걸로 찾으니 느려졌습니다.
인덱스 만들어 보기
create index employees_name on employees(name);
다시 실행
explain analyze select id from employees where name = 'GaBpJ';
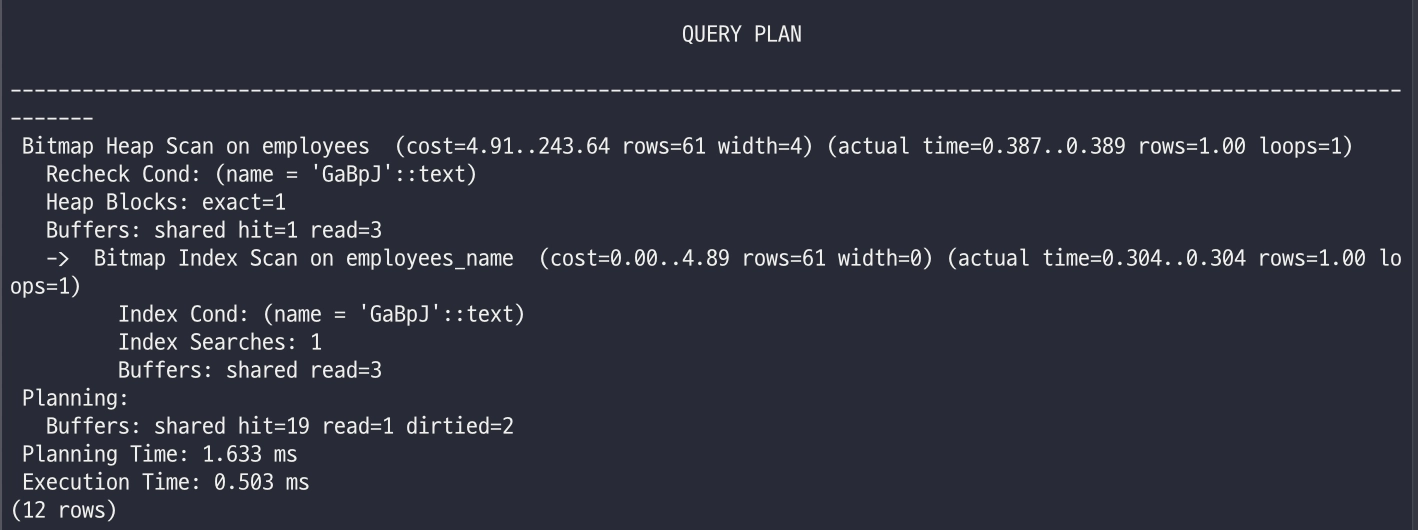
- 빨라졌네요.
실무에서 자주하는 실수: 인덱스 죽이기
인덱스를 만들어 뒀어도 다음과 같은 쿼리는 인덱스를 타지 못하고 전체 스캔을 수행합니다.
- 와일드카드 앞 배치:
WHERE name LIKE '%name'(어디서 시작하는지 모르니 인덱스 활용 불가) - 컬럼 가공:
WHERE UPPER(name) = 'HUSSEIN'(인덱스에 저장된 원본값과 달라짐) - 복합적인 표현식: 인덱스가 단일 값에 최적화되어 있을 때 복잡한 수식을 걸면 플래너(Planner)는 인덱스를 포기합니다.
와일드카드 예시
explain analyze select id, name from employees where name like '%Ga%';
EXPLAIN
쿼리를 실제로 실행하지 않고, 데이터베이스 옵티마이저가 "나는 이 쿼리를 이렇게 처리할 계획이야"라고 말해주는 기능입니다.
EXPLAIN 결과의 4대 요소
EXPLAIN을 실행하면 다음과 같은 구조의 정보를 얻게 됩니다.
explain select * from employees where id = 10000;

| 요소 | 의미 | 실무 가이드 |
|---|---|---|
| Cost | 작업에 소요되는 상대적 시간 단위 | 시작 비용이 0이 아니면 정렬/집계 등 사전 작업이 있음을 의미 |
| Rows | 예상되는 결과 행 수 | SELECT COUNT(*) 대신 추정치를 얻을 때 활용 가능 |
| Width | 각 행의 평균 바이트 크기 | SELECT *를 쓰면 이 숫자가 커져 네트워크 부하 발생 |
| Scan Type | 데이터를 찾는 방식 | Index Only Scan > Index Scan > Seq Scan 순으로 선호 |

순차 스캔(Sequential Scan)과 비용 분석
쿼리에 적절한 WHERE 절이나 인덱스가 없으면 Postgres는 테이블 전체를 뒤집니다.
- 시작 비용 0: "바로 읽기 시작함"을 뜻하지만, 끝까지 읽어야 하므로 총 비용은 매우 높습니다.
- 병렬 스캔: 데이터가 너무 많으면 Postgres가 여러 스레드를 띄워 동시에 읽기도 하지만, 여전히 비싼 작업입니다.
인덱스 정렬: 인덱스는 이미 정렬되어 있어 Order By 시 비용이 거의 추가되지 않습니다.
비트맵 인덱스 스캔
인덱스가 있다고 무조건 쓰는 게 아닙니다. Postgres는 통계 정보를 바탕으로 전체 행의 몇 퍼센트를 가져올지 계산하여 스캔 방식을 결정합니다.
랜덤 액세스의 비용: 인덱스에서 테이블(힙)로 왔다 갔다 하는 작업은 매우 비싼 작업입니다.
비트맵 인덱스 스캔 (Bitmap Index Scan)
랜덤 액세스의 단점을 극복하기 위한 Postgres의 똑똑한 전략입니다.
- 비트맵 생성: 인덱스를 먼저 훑어서 조건에 맞는 데이터가 들어있는 페이지 번호를 비트로 표시한 '비트맵'을 메모리에 만듭니다 (예: 0번 비트 = 0번 페이지).
- 순차적 접근: 비트맵이 완성되면 1로 표시된 페이지들만 골라서 순서대로 방문합니다.
- 효과: 테이블로 점프하는 횟수를 줄이고, 디스크를 순차적으로 읽게 유도하여 랜덤 I/O 비용을 획기적으로 낮춥니다.
비트맵 방식의 진짜 강점은 여러 조건을 결합할 때 나타납니다.
- 예시:
WHERE 성적 > 95 AND ID < 10000 - 처리: '성적' 인덱스로 비트맵 하나, 'ID' 인덱스로 비트맵 하나를 만든 뒤 두 비트맵을 AND 연산 합니다. 결과적으로 두 조건을 모두 만족하는 데이터가 있는 페이지들만 정확히 짚어서 방문하게 됩니다.
비트맵으로 페이지를 다 가져온 뒤에는 Recheck 과정이 뒤따릅니다.
Covering Index
인덱스로 검색을 해도 인덱스에 없는 값을 가져오려면 heap 영역으로 점프해야합니다.
그래서 이 행위가 디스크 I/O 비용이며, 행이 많을수록 성능 저하가 일어납니다.
즉, 인덱스는 번호순으로 줄 서 있지만 실제 데이터는 여기저기 흩어져 있어서, 데이터를 찾으러 디스크 이곳저곳을 왔다 갔다 하느라 느려집니다.
해결책 Covering Index
PostgreSQL의 INCLUDE 기능을 사용하면 힙으로 가는 발걸음을 멈출 수 있습니다.
- SQL 예시:
CREATE INDEX employees_name on employees(id) INCLUDE (name); - 구조: id는 B-Tree 키가 되고, name은 그 옆에 붙어있는 부가 정보
이걸 적용하면 이제 Index Only Scan이 됩니다.
만약 Index Only Scan 인데 만약에 heap fetches가 0이 아니라면?
VACUUM을 실행해주어야 합니다.
- VACUUM은 한마디로 "데이터베이스의 쓰레기 데이터를 정리하고 지도를 최신화하는 청소 작업"입니다.
왜 VACUUM이 필요한가? (MVCC 때문)
PostgreSQL 같은 DB는 데이터를 수정하거나 삭제할 때 원본을 바로 지우지 않고 "이 데이터는 이제 죽은 것(Dead Tuple)"이라고 표시만 해둡니다.
-
문제점: 인덱스에는 데이터가 있는데, 이게 '방금 삭제된 데이터'인지 '아직 살아있는 데이터'인지 인덱스만 봐서는 100% 확신할 수 없습니다.
-
해결책: 이때 Visibility Map(가시성 지도)이라는 것을 확인하는데, 이 지도가 "이 구역은 깨끗해서 안심하고 인덱스만 봐도 돼!"라고 보증해줘야 heap fetches가 0이 됩니다.
보통
AUTOVACUUM이 알아서 해주지만, 대량의 데이터를 넣거나 지운 직후에는 수동으로VACUUM ANALYZE table_name;을 실행해 주는 것이 성능에 큰 도움이 됩니다.
인덱스 운영
단일 인덱스 2개 (A, B) 운영
각 컬럼에 개별적으로 인덱스를 생성한 경우입니다.
- 작동 방식:
WHERE A=70 AND B=100쿼리 시, A 인덱스와 B 인덱스를 각각 스캔하여 결과 후보지 지도(Bitmap)를 만듭니다. - 비트맵 결합: 두 지도를 겹쳐서 공통된 부분만 골라낸 뒤 실제 데이터(Heap)에 접근합니다.
- 특징: 유연하지만, 복합 인덱스 하나를 타는 것보다는 오버헤드가 발생합니다.
복합 인덱스 (A, B)와 좌측 우선 규칙
create index on test (a,b);
두 컬럼을 묶어서 하나의 인덱스로 만드는 방식입니다.
- A만 검색할 때: 인덱스가 잘 작동합니다. (A가 인덱스의 왼쪽, 즉 선두에 있기 때문)
- B만 검색할 때: 전체 테이블 스캔(Sequential Scan)이 발생합니다. 인덱스는 왼쪽부터 정렬되어 있어, 왼쪽 컬럼(A) 없이 오른쪽(B)만으로는 길을 찾을 수 없습니다.
AND 연산에서 비트맵 결합 과정 없이 한 번에 정확한 위치를 찾아냅니다.
최적의 조합: 복합 인덱스(A, B) + 단일 인덱스(B)
A쿼리, A and B 쿼리, B 쿼리, A or B 쿼리 다 해결 가능
OR 연산은 복합 인덱스 하나만으로는 처리가 어렵다.
옵티마이저
쿼리 조건에 a=1 AND b=4가 있고 각각 인덱스가 있을 때, DB는 보통 다음 세 가지 중 하나를 선택합니다.
-
인덱스 병합 (Index Merge): 두 인덱스를 각각 검색해 조건에 맞는 행 ID를 뽑아낸 뒤, 교집합(AND)이나 합집합(OR) 연산을 수행, 결과 집합이 작을 때 효과적
-
단일 인덱스 활용 + 필터링: 가장 좁은 범위를 걸러낼 수 있는 인덱스 하나만 사용합니다. 예를 들어 a=1인 데이터가 10건뿐이라면, a_IDX로 10건을 먼저 찾고 테이블로 가서 b=4인지 확인하는 게 더 빠릅니다.
-
Full Table Scan: 인덱스를 타는 게 오히려 손해일 때 선택합니다. 인덱스를 거쳐 테이블을 한 건씩 읽는(Random I/O) 것보다 테이블 전체를 한 번에 읽는(Sequential I/O) 것이 저렴하다고 판단될 때 발생
-
예시: 미국 고객 테이블의
'State'컬럼-
State = 'California'(데이터의 90%가 캘리포니아 거주): 인덱스 타는 게 오히려 느립니다. 테이블 전체 스캔이 낫습니다. -
State = 'Texas'(데이터의 0.1%만 텍사스 거주): 인덱스 효율이 극대화됩니다.
-
-
데이터 신선도
옵티마이저는 DB가 내부적으로 저장하고 있는 통계 데이터를 보고 판단합니다.
-
대량의 데이터를 삽입한 직후 쿼리를 날리면, DB는 아직 테이블이 비어있다고 착가하고 잘못된 실행 계획을 세울 수 있습니다.
-
해결책: 주요 작업 후 반드시 통계 정보를 수동으로 업데이트하세요.
- PostgreSQL:
ANALYZE또는VACUUM ANALYZEANALYZE는 테이블의 데이터 분포를 조사해서 통계 정보(Statistics)를 만드는 작업
- PostgreSQL:
[참고] 옵티마이저 힌트라는 것도 있는 데 내가 인덱스 강제로 쓰라고 지정할 수 있습니다.
CONCURRENTLY
일반적인 방식으로 인덱스를 생성하면 테이블에 쓰기 잠금(Lock)이 걸려 서비스 장애로 이어질 수 있습니다.
이를 방지하기 위해 PostgreSQL은 CONCURRENTLY 옵션을 제공합니다.
create index concurrently g on employees(name);
-
작동 원리: 먼저 인덱스 정의를 등록하고, 현재 실행 중인 모든 쓰기 트랜잭션이 끝나기를 기다린 후, 테이블을 스캔하며 인덱스를 구축합니다.
-
시간: 테이블을 최소 두 번 이상 풀 스캔하고 트랜잭션을 기다려야 하므로 일반 방식보다 2~3배 이상 오래 걸립니다.
생성에 실패한다면?
-
상태 확인: 실패하면 데이터베이스에 인덱스 이름은 남지만 사용할 수 없는 INVALID 상태가 됩니다.
-
조치: 그대로 두면 공간만 차지하므로 DROP INDEX로 삭제한 뒤 다시 CREATE INDEX CONCURRENTLY를 실행해야 합니다.
블룸 필터
왜 필요한가?
사용자 이름 중복 확인 기능을 만든다고 가정해 봅시다.
-
기본 방식: 매번 DB에 SELECT 쿼리를 날립니다. 사용자가 많아지면 디스크 I/O 때문에 매우 느려집니다.
-
캐시 방식: 모든 이름을 메모리에 올립니다. 속도는 빠르지만, 데이터가 많아질수록 메모리 비용이 감당 안 될 정도로 커집니다.
-
블룸 필터: 메모리는 아주 적게 쓰면서, 존재하지 않는 데이터에 대한 DB 요청을 사전에 차단(Filtering)합니다.
작동 원리: 비트 배열과 해시 함수
-
데이터 저장 시: 닉네임(예: Jack)을 해시 함수에 통과시켜 나온 숫자(예: 63)에 해당하는 비트를 1로 세팅합니다.
-
데이터 조회 시: "Paul"이 있는지 묻습니다. Paul을 해싱했더니 3이 나왔는데, 3번 비트가 0이라면? DB에 갈 필요도 없이 "없음"으로 즉시 응답합니다.
-
충돌(Collision)의 이해: "Tim"을 해싱했는데 하필 Jack과 같은 63이 나올 수 있습니다. 이때 블룸 필터는 "있다"고 말하겠죠(가짜 양성). 하지만 괜찮습니다. 이때만 DB에 가서 확인하면 되니까요.
주의사항
-
데이터 삭제가 불가능함: 일반적인 블룸 필터는 한 번 1로 만든 비트를 다시 0으로 되돌릴 수 없습니다. (다른 데이터가 해당 비트를 공유할 수 있기 때문)
-
비트 배열의 크기 설정: 배열이 너무 작으면 모든 비트가 1이 되어 버립니다. 그럼 모든 요청이 DB로 흘러가 필터의 의미가 없어집니다.
Postgres
PostgreSQL은 두 테이블을 조인할 때 Hash Join 방식을 자주 사용합니다. 이때 엔진은 내부적으로 블룸 필터를 자동으로 생성합니다.
- 개발자가 건드릴 필요 없음. Optimizer가 알아서 판단합니다.
수동 설정
- 여러 컬럼을 동시에 필터링해야 하는데, 모든 조합에 대해 인덱스를 만들자니 용량이 부담될 때 사용하는 특수 인덱스입니다.
-- 1. 블룸 필터 확장 모듈 활성화 (최초 1회)
CREATE EXTENSION IF NOT EXISTS bloom;
-- 2. 블룸 인덱스 생성
-- 여러 컬럼(col1, col2, col3)을 하나의 블룸 인덱스로 묶습니다.
CREATE INDEX idx_user_profile_bloom ON user_profiles
USING bloom (age, city, job_type)
WITH (length = 80, col1 = 2, col2 = 2, col3 = 4);-
불완전성: 블룸 인덱스는 "가짜 양성(False Positive)"이 발생합니다. 인덱스에서 찾았다고 해도 실제 데이터가 있는지 확인하러 테이블을 다시 읽어야 합니다.
-
용도 제한: = 연산자(일치 여부)에만 사용 가능합니다. 범위 검색(보다 크다/작다)은 불가능합니다. (B-Tree와의 가장 큰 차이점)
-
성능: 테이블 전체를 읽는 것보다는 빠르지만, 딱 맞는 B-Tree 인덱스보다는 느릴 수 있습니다. "공간 효율성"과 "조회 속도" 사이의 트레이드오프입니다.
