BentoML
Introduction
-
만약 30~50개의 모델을 만들어야 한다면?
-
반복되는 작업(Config, FastAPI 설정 등)이 존재
-
여전히 Serving은 어려움
-
⇒ 더 쉬운 개발을 위해 본질적인 Serving에 특화된 라이브러리를 원하게 됨
BentoML이 해결하는 문제
-
Model Serving Infra의 어려움
-
Serving을 위해 다양한 라이브러리, Artifact, Asset 등 사이즈가 큰 파일 패키징
-
Cloud Service에 지속적인 배포를 위한 많은 작업 필요
⇒ BentoML은 CLI로 위 문제들의 복잡도를 낮춤 (CLI 명령어로 진행 가능하도록)
-
-
Online Serving의 Monitoring 및 Error Handling
- Error 처리, Logging 추가 구현이 필요함
⇒ BentoML은 Python Logging Module을 사용해 Access Log, Prediction Log를 기본 제공
⇒ Config를 수정해 Logging 커스텀 가능하고, Prometheus 같은 Metric 수집 서버에 전송 가능
-
Online Serving 퍼포먼스 튜닝의 어려움
-
트래픽이 많이 올 때 어떻게 처리할 것인가
- 동기? 비동기?
⇒ BentoML은 Adaptive Micro Batch 방식을 채택해 동시에 많은 요청이 들어와도 높은 처리량
-
BentoML 소개
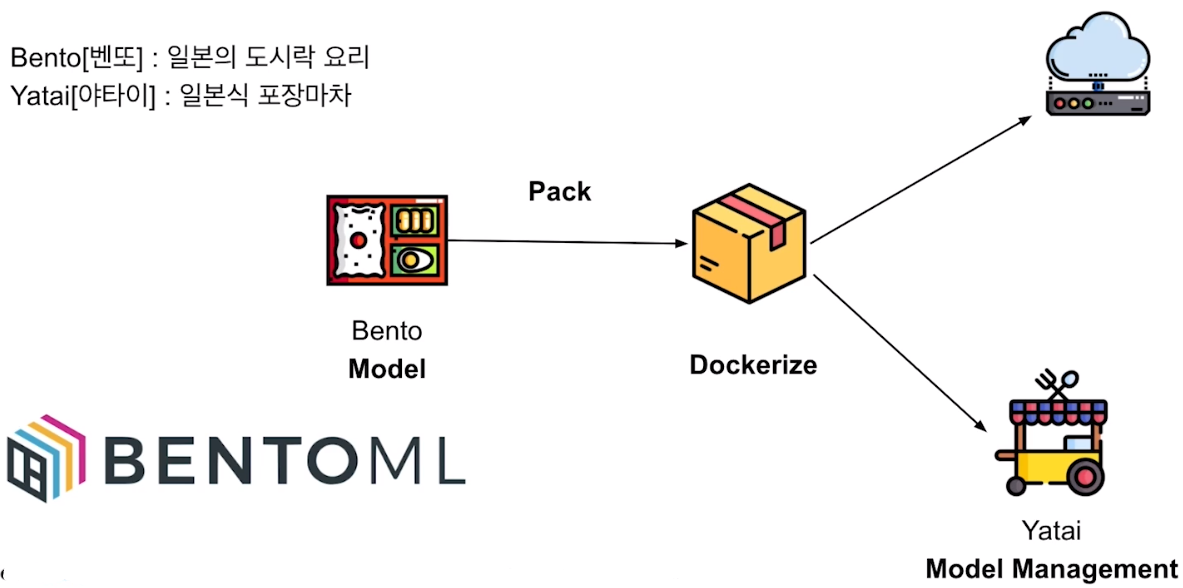
- 포장마차에서 벤또 리스트 중 하나를 선택하는 느낌
BentoML 특징
-
쉬운 사용성
-
Online / Offline Serving 지원
-
Tensorflow, Pytorch, Keras, XGBoost 등 메이저 프레임워크 지원
-
도커, 쿠버네티스, AWS, Azure 등 배포 환경 지원 및 가이드 제공
-
Flask 대비 100배 처리량
-
모델 저장소 (Yatai) 웹 대시보드 제공
-
데이터 사이언스와 DevOps 사이 간격을 이어주며 높은 성능의 Serving을 가능하게 함
BentoML 시작하기
예시 BentoML 사용 Flow
-
모델 학습 코드 생성
-
Prediction Service Class 생성
-
Prediction Service에 모델 저장 (Pack)
-
(Local) Serving
- 로컬에서 작동이 잘 되면, 다음 스텝으로 이동
-
Docker Image Build (컨테이너화)
-
Serving 배포
1) 모델 학습 코드 생성
- 기존에 Serving 하기 위해 해야 하는 작업
2) Prediction Service Class 생성
import pandas as pd
from bentoml import env, artifacts, api, BentoService
from bentoml.adapters import DataframeInput
from bentoml.frameworks.sklearn import SklearnModelArtifact
@env(infer_pip_packages=True)
@artifacts([SklearnModelArtifact('model')])
class IrisClassifier(BentoService):
"""
A minimum prediction service exposing a Scikit-learn model
"""
@api(input=DataframeInput(), batch=True)
def predict(self, df: pd.DataFrame):
"""
An inference API named `predict` with Dataframe input adapter, which codifies
how HTTP requests or CSV files are converted to a pandas Dataframe object as the
inference API function input
"""
return self.artifacts.model.predict(df)-
@env-
파이썬 패키지, install script 등 서비스에 필요한 의존성 정의
-
infer_pip_packages=True- 설치된 패키지를 import문 기반으로 직접 추론해서 requirements를 생성해서 저장
-
-
@artifacts([SklearnModelArtifact('model')])- 서비스에서 사용할 Artifact를 SklearnModel 형태로 쓰겠다고 정의
-
class IrisClassifier(BentoService):- BentoService를 상속하면, 해당 서비스를 Yatai(모델 이미지 registry)에 저장
-
@api-
API 생성
-
input, output을 원하는 형태 (df, Tensor, JSON 등)로 선택할 수 있음
-
Doc String으로 Swagger에 들어갈 내용 추가 가능
-
-
return self.artifacts.model.predict(df)-
self.artifacts.model
-
위에서 선언한
@artifacts([SklearnModelArtifact('model')])이름을 그대로 사용 -
API에 접근할 때 해당 Method 호출
-
-
3) Prediction Service 저장 (Pack)
from sklearn import svm
from sklearn import datasets
clf = svm.SVC(gamma='scale')
iris = datasets.load_iris()
X, y = iris.data, iris.target
clf.fit(X, y)
# bento_service.py에서 정의한 IrisClassifier
from bento_service import IrisClassifier
# IrisClassifier 인스턴스 생성
iris_classifier_service = IrisClassifier()
# Model Artifact를 Pack
iris_classifier_service.pack('model', clf)
# Model Serving을 위한 서비스를 Disk에 저장
saved_path = iris_classifier_service.save()-
from bento_service import IrisClassifier-
2에서 생성한 class
-
클래스 받아와서 인스턴스 생성
-
-
iris_classifier_service.pack('model', clf)- clf 모델을 넣어서 model이라는 이름을 쓰겠다고 명시
-
코드를 실행하면 경로가 나타나며 해당 경로에 모델이 저장
-
CLI에서
bentoml list입력하면 저장된 Prediction Service 확인 가능

-
BentoML에 저장된 Prediction Service 폴더로 이동 후, 파일 확인
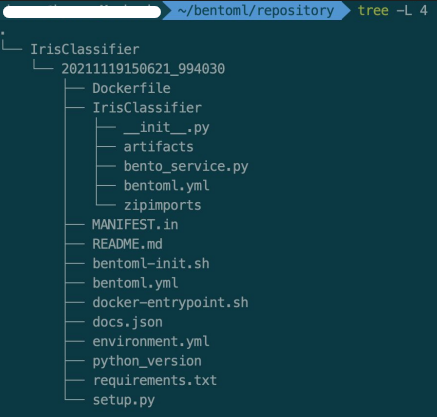
-
여러 파일들이 생성
-
bento_service.py는 우리가 만든 것과 동일
-
bentoml.yml
-
모델 메타정보 저장
-
API input, output, docs 등
-
-
Dockerfile도 자동 생성
-
-
이 때, 다른 이름의 모델이 Pack 되면 어떻게 되는지 확인을 위해 IrisClassifier을 IrisClassifier1로 수정 (bento_packer의 import 부분도 같이 수정)

-
IrisClassifier1 생성
-
bentoml list로 확인해도 생성되어 있는 것 확인 가능
-
4) Serving
-
bentoml serve IrisClassifier:latest-
Serving 명령어
-
웹 서버 실행
-
localhost:5000로 접근하면 Swagger UI 나타남
-
우리가 생성한 predict 함수도 확인
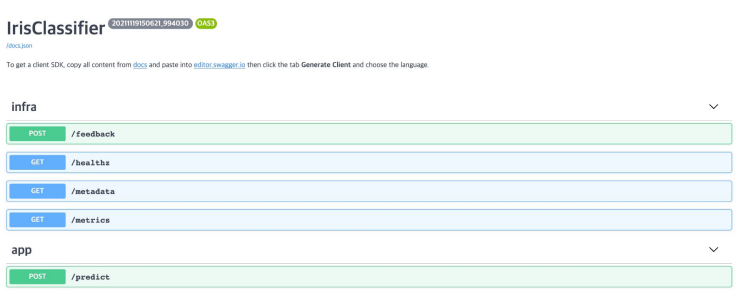
-
Try it Out에서 정의한 입력 format에 맞춰 입력하면 예측 값 반환
-
-
~/bentoml/logs에 로그 저장됨
-
터미널에서 curl로 Request해도 정상적으로 실행
- 앞서 client 코드를 만들어서 실험했는데, CLI에서 curl 명령어 넘겨도 post 값 받아올 수 있음
Yatai Service 실행
-
bentoml yatai-service-start실행 -
localhost:3000 접속
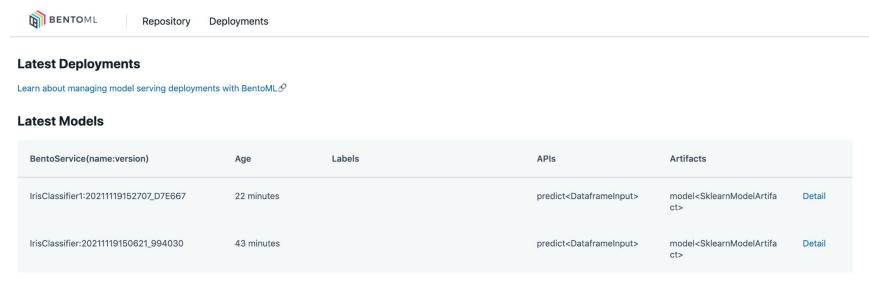
5) Docker Image Build
-
bentoml containerize IrisClassifier:latest -t iris-classifier- Docker 명령어나 FastAPI 사용하지 않고 웹 서버 띄우고, 이미지 빌드 가능
BentoML Component
BentoService
-
예측 서비스를 만들기 위한 베이스 클래스
-
bentoml.BentoService -
@bentoml.artifacts- 여러 머신러닝 모델 포함할 수 있음
-
@bentoml.api-
input, output 정의
-
API 함수 코드에서 self.artifacts.{ARTIFACT_NAME}으로 접근
-
Service Environment
-
파이썬 관련 환경, Docker 등을 설정 가능
-
@bento.env(infer_pip_packages=True)-
import 기반 필요 라이브러리 추론
-
requirements_txt_file을 명시할 수도 있음
-
pip_packages=[]를 사용해 버전 명시 가능
-
docker_base_image를 사용해 base image 지정 가능
-
setup_sh를 지정해 docker build 과정 custom
-
Model Artifact
-
@bentoml.artifacts-
사용자가 만든 모델을 저장해 pretrained model을 읽어 Serialization, Deserialization
-
여러 모델 같이 저장 가능
-
A 모델의 예측 결과를 B 모델의 Input으로 사용하는 경우
-
Model Artifact Metadata
-
해당 모델의 Metadata (Metric, 사용 데이터셋, 생성한 사람, Static 정보 등)
-
Pack에서 metadata 인자에 넘겨주면 메타 데이터 저장
-
메타 데이터는 Immutable
Model Management & Yatai
-
BentoService save 함수는 BentoML Bundle을 ~/bentoml/repository/{서비스 이름}/{서비스 버전}에 저장
-
bentoml get IrisClassifier- 특정 모델 (IrisClassifier)의 정보를 가져옴
-
bentoml yatai-service-start- 모델 저장 및 배포
API Function, Adapters
-
Adapter
-
input/output 추상화해서 중간 부분 연결하는 layer
-
e.g., csv 파일 형식으로 예측 요청할 경우 → DataframeInput을 사용하고 있으면 내부적으로 pandas.DataFrame 객체로 변환하고 API 함수에 전달
-
Model Serving
-
Online Serving
- 클라이언트가 REST API Endpoint로 근 실시간 예측 요청
-
Offlline Batch Serving
- 예측을 계산한 후, Stroage에 저장
-
Edge Serving
- 모바일, IoT device에 배포
BentoML으로 Serving 코드 Refactoring
BentoService 정의
@env(infer_pip_packages=True)
@artifacts([PytorchModelArtifact("model")])
class MaskAPIService(BentoService):
@api(input=ImageInput(), output=JsonOutput())
def predict(self, image_array: Array):
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
transformed_image = self.transform(image_array).to(device)
outputs = self.artifacts.model.forward(transformed_image)
_, y_hats = outputs.max(1)
return self.get_label_from_class(class_=y_hats.item())-
@artifacts([PytorchModelArtifact("model")])- 마스크 분류 모델이 PytorchModel이므로
-
@api(input=ImageInput(), output=JsonOutput())-
image input을 사용해 업로드 된 이미지로부터 imageio.Array를 함수 인자로 주입
-
output은 json으로 client에 제공
-
Model Pack
if __name__ == "__main__":
import torch
bento_svc = MaskAPIService()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = MyEfficientNet().to(device)
state_dict = torch.load(
"../../../assets/mask_task/model.pth", map_location=device
)
model.load_state_dict(state_dict=state_dict)
bento_svc.pack("model", model)
saved_path = bento_svc.save()
print(saved_path)-
bento_svc.pack("model", model)- load한 model을 packing하고 service save
※ 모든 이미지 및 코드 출처는 네이버 커넥트재단 부스트캠프 AI Tech 5기입니다. ※
