Serving
Production 환경에 모델을 사용할 수 있도록 배포
Input이 제공되면 모델이 예측 값 (Output)을 반환
Online Serving, Batch Serving으로 나뉨
Serving과 Inference 용어가 혼재되어 사용
Online Serving
Web Server
-
Client의 다양한 요청을 처리해주는 역할
- 데이터 전처리, 모델 기반 예측 등
-
HTTP를 통해 웹 브라우저에서 요청하는 HTMP 문서나 오브젝트를 전송해주는 서비스 프로그램
-
요청(Request)을 받으면 요청한 내용을 보내주는(Response) 프로그램

API (Application Programming Interface)
-
운영체제나 프로그래밍 언어가 제공하는 기능을 제어할 수 있게 만든 인터페이스
- e.g., 사람과 TV 사이를 연결해 주는 리모컨
-
특정 서비스에서 해당 기능을 사용할 수 있도록 외부에 노출
- e.g., 기상청 API, 지도 API
-
라이브러리의 함수
- e.g., Pandas, Tensorflow, PyTorch, …
Online Serving Basic
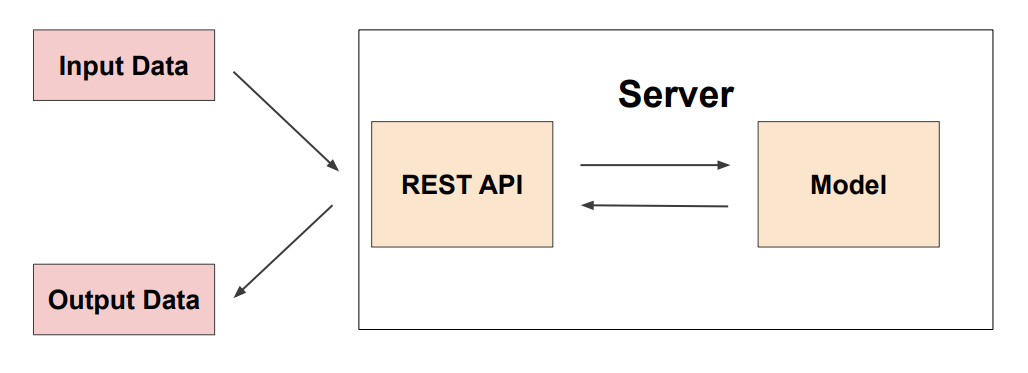
-
필요 시 ML모델 서버와 전처리 서버를 나눌 수 있음
-
Online Serving 구현 방식
-
직접 API 웹 서버 개발
- Flask, FastAPI
-
클라우드 서비스 활용
-
AWS의 SageMaker, GCP의 VertexAI
-
학습 코드만 제공하면 API 서버가 만들어짐
-
-
Serving 라이브러리 활용
- Tensorflow Serving, Torch Serve, MLFlow, BentoML
-
Online Serving에서 고려할 부분
- Python 버전, 패키지 버전 등 Dependency가 중요
- 실시간 예측을 하기 때문에 지연 시간(Latency)을 최소화해야 함
- 모델 경량화, 간단한 모델 사용하는 경우도 존재
- 결과 값에 대한 보정이 필요한 경우
- e.g., 집값 예측인데 음수가 나오면 0으로 표시
Batch Serving
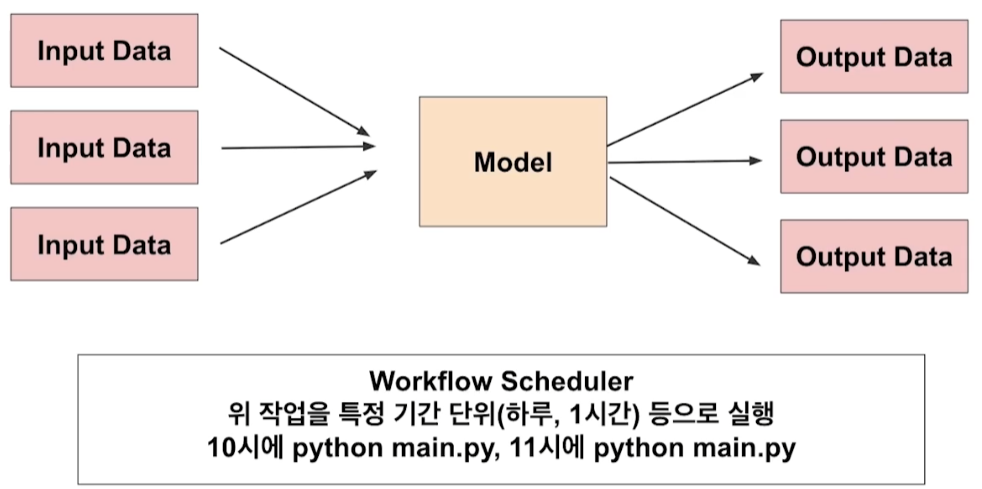
-
주기적으로 학습을 하거나 예측
- e.g., 30분에 1번씩 최근 데이터를 가지고 예측
-
특정 시간에 반복해서 실행
-
Online Serving보다 구현이 수월하고 간단함
-
Spotify의 예측 알고리즘
- Discover Weekly는 일주일 단위로 학습을 하고 추천
Serving \ 관점 | Input | Output |
|---|---|---|
| Online Serving | 데이터 하나씩 요청하는 경우 | API 형태로 바로 결과를 반환해야 하는 경우, 서버와 통신이 필요한 경우 |
| Batch Serving | 여러 데이터가 한 번에 처리되는 경우 | 1시간에 한 번씩 예측해도 괜찮은 경우 |
※ 모든 이미지 및 코드 출처는 네이버 커넥트재단 부스트캠프 AI Tech 5기입니다. ※

AI-Kid