
데이터베이스는 파일의 집합으로 저장됩니다. 각 파일은 레코드의 시퀀스입니다. 레코드는 필드의 시퀀스입니다.
- 데이터베이스 : 파일 + ... + 파일
- 파일(테이블) = 레코드 + ... + 레코드
- 레코드 = 필드 + ... + 필드
- 레코드 << 블록
고정 길이 레코드
고정 길이 레코드 경우에는 크기를 쉽게 예측이 가능하다. 다음 instructor 테이블의 한 레코드의 길이는 5 + 20 + 20 + 8 = 53bytes로 쉽게 구할 수 있다.

i 번째 레코드에 접근하려면 n*(i-1) byte 를 찾으면 됨. 예를 들어 아인슈타인 record를 찾고 싶으면 한 record의 크기는 53bytes 이고 4번 째 레코드이기 때문에 53 * (4-1) = 159 bytes부터 읽으면 된다.
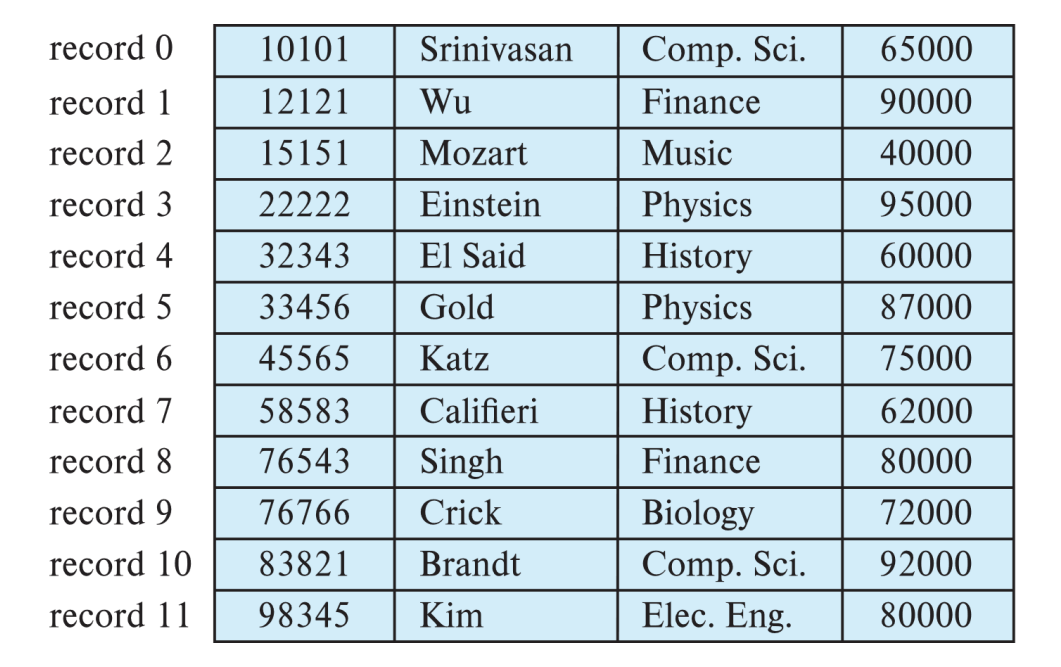
이렇게 고정 길이 레코드 방식은 간단한 방식으로 특정 테이블의 레코드 크기가 모두 동일하다고 가정한 경우입니다.
예를 들어 한 블록의 크기를 4KB라고 가정했을 때 레코드의 크기가 100bytes인 경우 한 블록에는 최대 40개의 레코드를 저장할 수 있습니다.
나머지 96bytes는 비어있는 공간이 됩니다.
- 고정 길이 레코드에서 각 레코드의 접근은 간단하지만 한 레코드의 크기가 크다면 한 레코드는 여러 block에 저장될 수 있습니다. 이렇게 되면 여러 블록에 저장된 레코드를 읽을 때는 IO가 여러 번 이루어져 비효율적일 수 있습니다. 그렇기 때문에 애초부터 한 레코드가 여러 블록에 저장되는 것을 허용하지 않는 것이, 메모리 측면에서는 조금 효율이 떨어 질 수 있지만 구현의 복잡성과 IO 측면에서 더 좋습니다.
이 때 한 블록에 저장할 수 있는 레코드의 수를 blocking factor라고 합니다.
고정 길이 레코드에서의 삭제
위에 그림에서 record i th 를 삭제했을 때 고정 길이 레코드에서는 3가지 방식으로 삭제 연산을 처리할 수 있다.

1. move records i+1,..., n to i,...,n-1
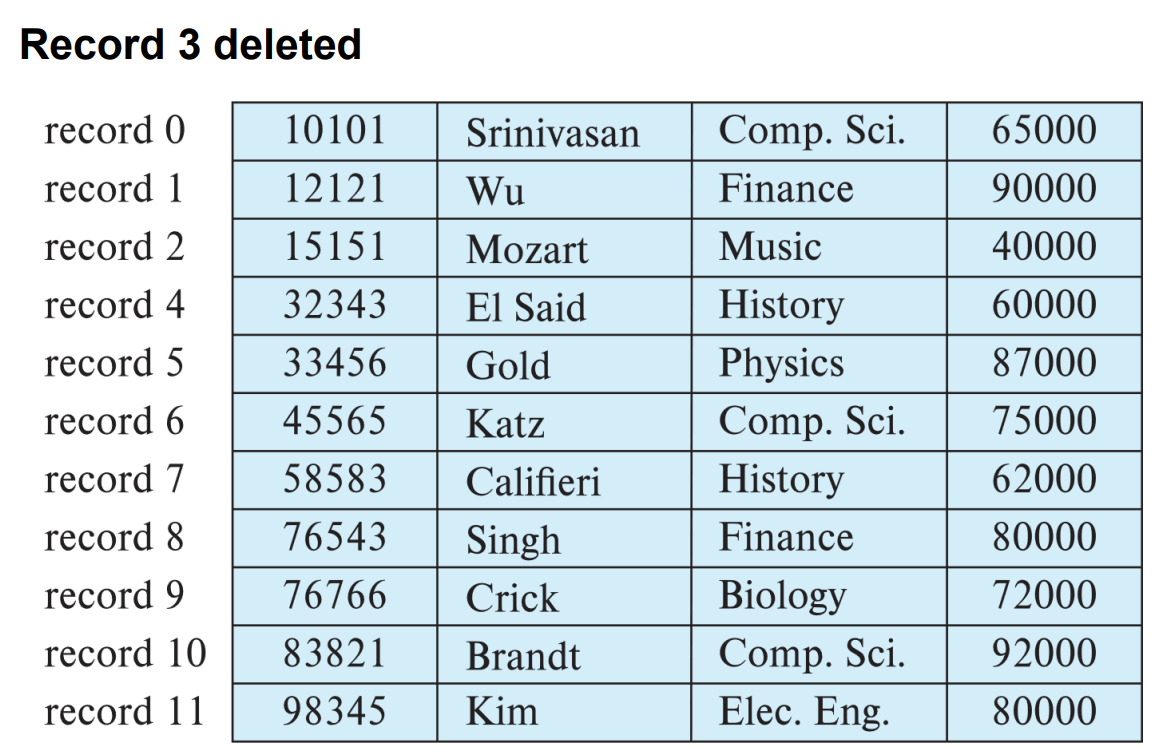
가장 간단한 방법으로 단순히 i+1 번째부터 한 칸씩 미뤄주는 것이다.
예를 들어 위 그림에서 blocking factor가 4일 때 3개의 block이 존재한다.
그렇다면 record3을 삭제하면 그 아래있는 모든 레코드가 한 칸씩을 땡겨줘야 하기 때문에 모든 블록들을 메모리로 가지고 와서 연산 한 다음에 다시 디비에 저장해줘야 한다. 그렇게 되면 3개의 block을 모두 read/write해줘야 하기 때문에 6번의 IO가 발생한다.
이를 일반화 해서 총 Block이 K 개 라면 이 때 O(k)만큼의 IO가 발생한다.
2. move record n to i
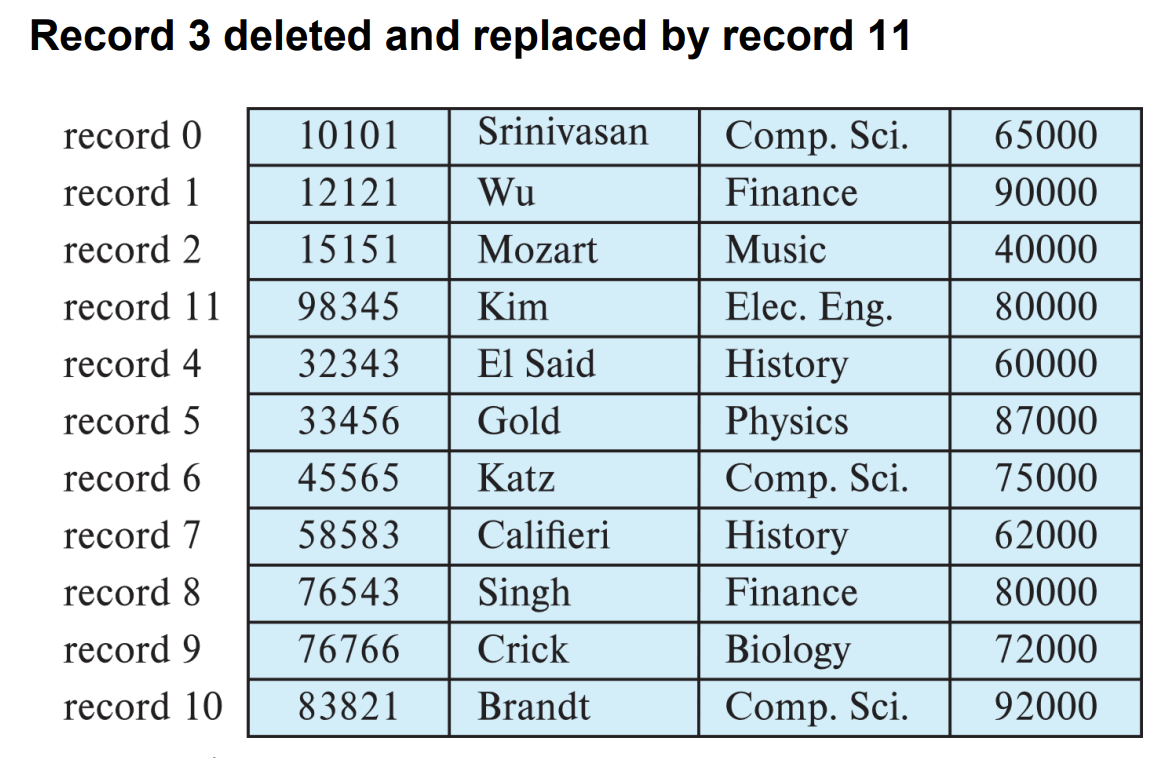
이 방식은 마지막에 있는 레코드를 삭제된 레코드 위치로 옮겨주는 것이다.
이 경우에는 삭제할 record가 포함된 block과 맨 마지막 레코드가 포함된 block 2개만 메모리에 올려서 연산 한 다음 다시 디비에 저장해주면 된다.
위 그림에서는 아인슈타인이 포함된 블록과 KIM이 포함된 블록 2개만 read/write해주면 되기 때문에 4번의 IO가 발생한다.
이를 일반화 해서 i번 째 record를 삭제할 때 언제나 최대 4번의 IO가 발생하게 된다. 따라서 O(1) 만큼의 IO가 발생한다.
3. do not move records , but link.
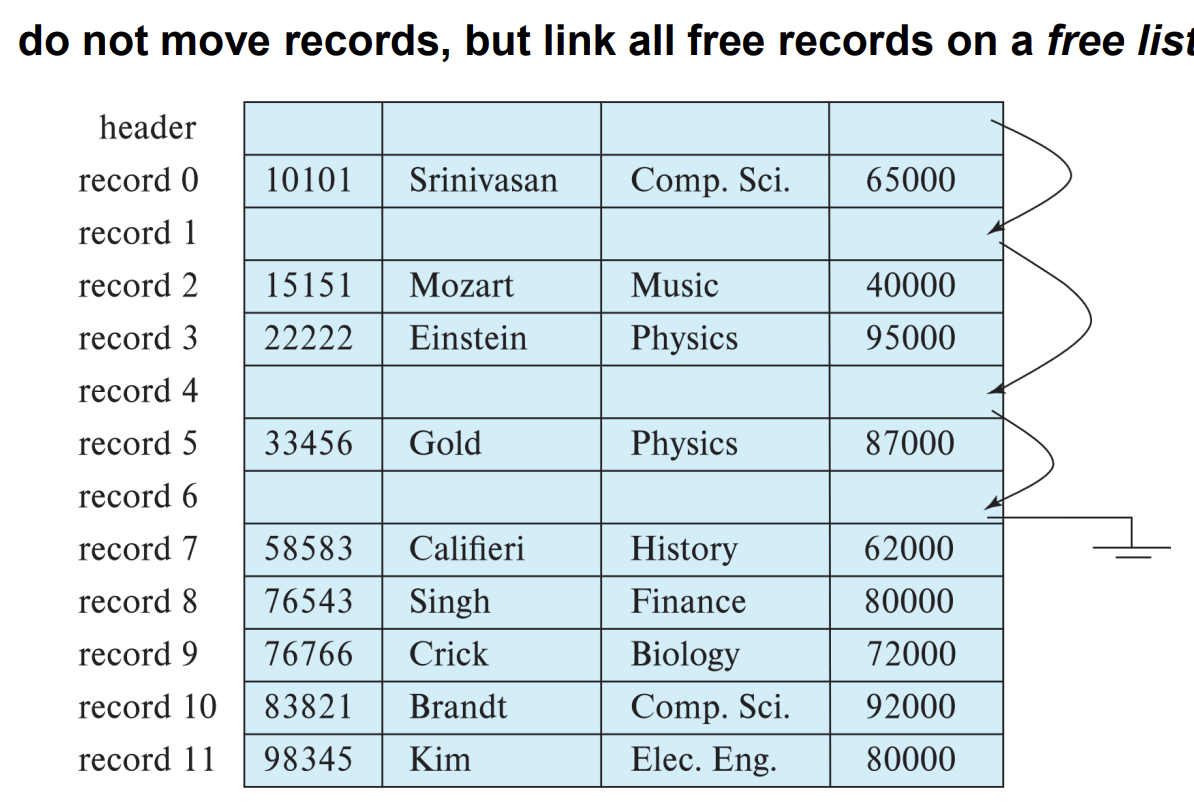
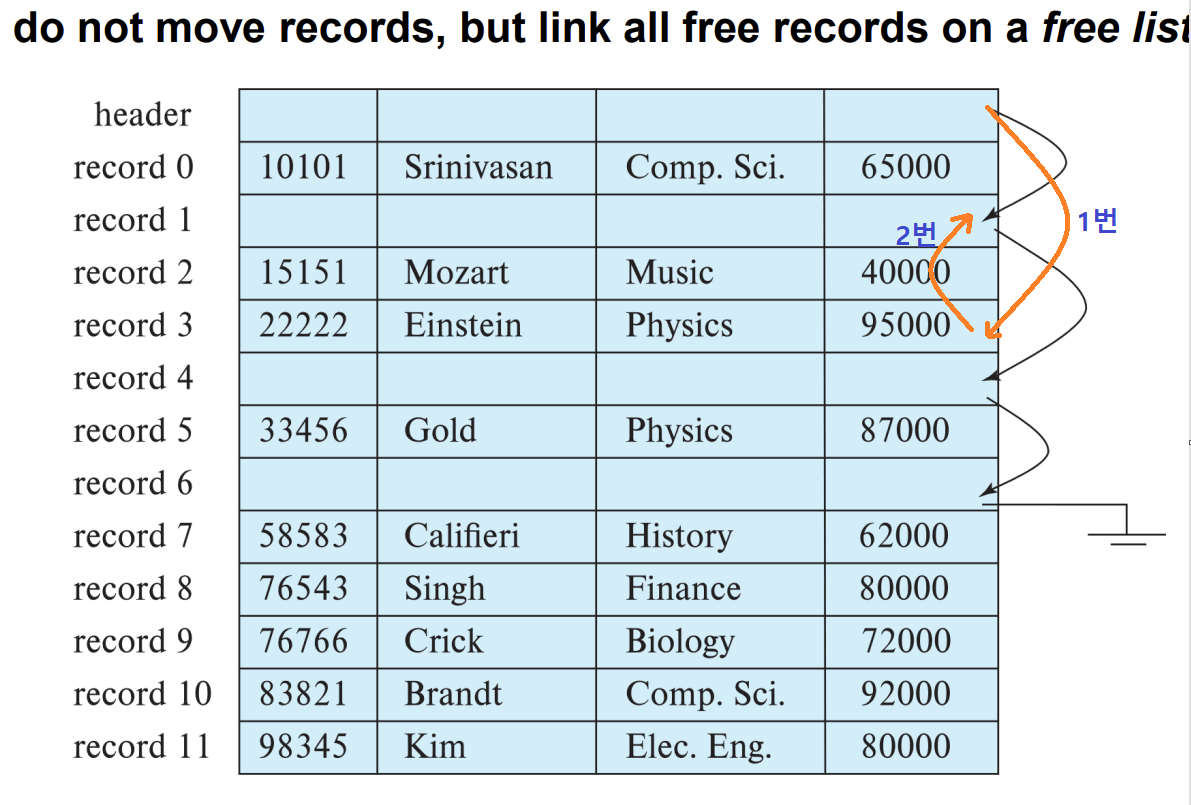
이 방식은 말 그대로 레코드를 옮기는 것이 아니라 link를 옮겨주는 방식이다.
여기서 free list는 빈 공간을 가리키는 포인터(link)들의 연결리스트이다.
※free list : 레코드를 제거했을 때, 제거된 레코드의 주소를 연결리스트로 구현 (처음 시작은 header, 다음은 레코드)
그림에서 아인슈타인 레코드가 삭제가 되면 header가 아인슈타인이 삭제된 공간을 가리키게 되고(1번) 아인슈타인 링크 필드는 record1의 링크 필드를 가리키게 된다.(2번) 이렇게 되면 headr가 포함된 블록과 아인슈타인이 포함된 블록만 메모리에 가져오면 되기 때문에 이 방식도 2번 방식과 마찬가지로 O(1)만큼의 IO가 발생한다.
가변 길이 레코드
저장되는 레코드의 길이가 서로 다른(가변적) 레코드를 할당하는 방법.
디비 시스템에서 가변길이 레코드가 발생하는 경우
- Storage of multiple record types in a file
- Record types that allow variable lengths for one or more fields such as strings (varchar)
- Record types that allow repeating fields (used in some older data
models)
Variable length attributes represented by fixed size (offset, length), with actual data stored after all fixed length attributes.
-> 가변 길이 속성은 offset과 length로 표시한다. 이 때 offset과 length는 고정된 길이임. 가변 길이에 해당하는 실제 데이터는 모든 고정 길이 속성이 저장된 후 저장된다.
예를 들어 record 0이 가변길이 저장되면 다음과 같이 저장될 수 있다.
저장된 상황을 보면 다음과 같다.
0~3 bytes : 21,5 -> id값이 저장된 offset과 length를 의미
4~7 bytes : 26,10 -> 이름이 저장된 offset과 length를 의미
8~11 bytes : 36,10 ->학과가 저장된 offset과 length를 의미
하나만 보면 21,5는 21 bytes부터 5바이트가 의미하는 것이 record0의 id인 10101이다. 이름과 학과도 마찬가지이다. 즉 이 db 시스템에서 해당 테이블은 id, 이름, 학과 이름이 가변 길이로 저장된 상황이다.
그리고 보면
12~19 bytes는 고정 길이 속성인 salary 65000이 저장되어 있는 것을 볼 수 있다.
Null values represented by null-value bitmap
널 값을 할당하는 방법은 null-value bitmap을 사용한다. 여기서는 1byet에 해당함.
그림에서 보면 20bytes에 0x0000이 저장되어 있는데 record0 같은 경우는 모든 속성이 null이 아니기 때문이다. 만약 name이 null값이었다면 0x0100으로 저장되었을 것이다.


