키워드 추출 모델
키워드 추출 모델은 주어진 문서에서 키워드를 추출하는 모델입니다.
전체적인 로직은 다음과 같습니다.
문서에서 명사를 추출한 후 SBERT를 이용해 임베딩을 진행합니다. 그리고 Extract Keyword 프로그램을 통해 키워드를 추출합니다.
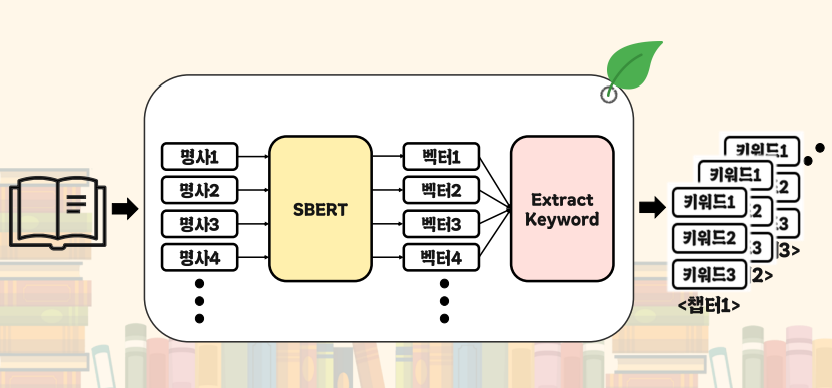
명사 추출
주어진 문서에서 명사를 추출하는 방식은 Mecab() 한국어 형태소 분석기를 이용하였습니다. Mecab()에서 제공하는 품사 태깅 기능을 이용하여 명사에 해당하는 단어를 추출하고 불용어 또한 제거하였습니다.

단어 임베딩
추출된 명사는 그대로 사용할 수가 없기 때문에 벡터로 임베딩을 진행하였습니다. 이 과정에서 임베딩에 특화된 SBERT를 이용하였고 결과적으로 각 단어는 768차원의 벡터로 임베딩하였습니다.

키워드 추출
키워드 추출에 사용한 알고리즘은 두 가지 방식을 사용하였습니다. 첫 번째는 문서 벡터와 각 단어 벡터 사이에 코사인 유사도를 구하여 유사도가 가장 높은 N개를 추출하는 방식입니다. 그렇지만 첫 번째 방식으로만 키워드를 추출하게 되면 유사한 의미를 가진 키워드들이 추출됩니다. 예시로 셜록홈즈 시리즈 중 주홍색 연구에서 chapter 1을 키워드 추출하면 다음과 같이 키워드가 추출됩니다.
['군의관', '진군', '군','합류', '사관', '발발', '부대', '장병', '주둔', '육군', '의무병', '병사', '승진', '후송', '상륙', '전쟁', '전투’, ...]
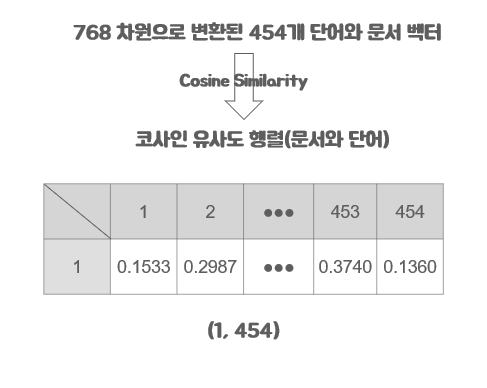

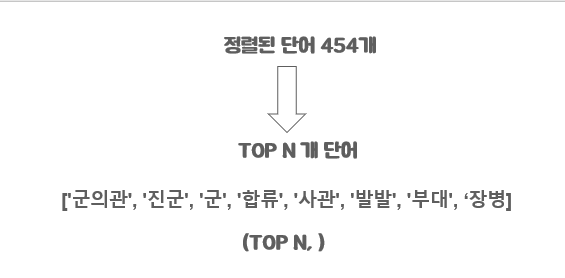
물론 이렇게 추출 되어도 잘 되었다고 볼 수 있지만 키워드간 유사한 의미를 가진 단어가 많이 존재하게 됩니다. 그래서 사용한 방식이 Max Sum Similarity 입니다. 이 방식은 N개의 키워드를 뽑을 때 먼저 문서와 유사도가 높은 명사 30~40개 정도를 후보 집합으로 뽑습니다. 이 후보 집합에서 N개로 이루어진 조합을 만듭니다. 여기서 각 조합들 마다 포함된 N개의 단어들 사이에 유사성을 구하고 이 유사성이 가장 낮은 조합이 결과적으로 키워드로 뽑히게 됩니다. 이 방식으로 키워드를 뽑으면 훨씬 더 다양한 키워드를 뽑을 수 있게 됩니다.
