스케줄링
CPU 스케줄러는 프로세스가 생성된 후 종료될 때까지 모든 상태 변화를 조정하는 일을 한다. 즉, 스케줄러는 하나의 관리자로 프로세스들의 여러 상황을 고려하여 cpu와 시스템 자원을 어떻게 배정할 지 결정하는 역할을 한다.
1. 스케줄링 단계
1.1 고수준 스케줄링
가장 큰 틀에서 이루어지는 CPU 스케줄링으로 고수준 스케줄링, 장기 스케줄링, 작업 스케줄링(job scheduling)이라고도 한다.
가게가 너무 잘된다고 바쁠 때 계속 손님을 받으면 안된다. 이처럼 고수준 스케줄링은 시스템 내의 전체 작업 수를 조절하는 것을 말한다. 여기서 말하는 작업은 운영체제에서 다루는 일의 가장 큰 단위로 1 개 또는 여러 개의 프로세스로 이루어진다.
작업이 시작되면 시스템 자원을 사용하기 때문에 기존 작업에 영향을 미친다. 작업 요청이 오면 스케줄러가 시스템의 상황을 고려하여 작업을 승인할지, 거부할 지 결정하므로 고수준 스케줄링을 승인 스케줄링이라고도 한다. 고수준 스케줄링에 따라 시스템 내에서 동시에 실행 가능한 프로세스의 총 개수가 정해진다.
1.2 저수준 스케줄링
가장 작은 단위의 스케줄링을 저수준 스케줄링, 단기 스케줄링이라고 한다. CPU 스케줄러 입장에서 저수준 스케줄링은 어떤 프로세스에 CPU를 할당할지, 어떤 프로세스를 대시 상태로 보낼지 등을 결정하는 일이다. 준비 상태인 프로세스를 실행 상태로, 실행 상태를 대기 상태로, 대기 상태를 준비 상태로 보내는 것들이 있다.
1.3 중간 수준 스케줄링
고수준 스케줄링과 저수준 스케줄링 사이에 일어나는 일로, 중간 수준 스케줄링은 suspend와 active로 전체 시스템의 활성화된 프로세스 수를 조절하여 과부하를 막는다. 즉, 고수준 스케줄링은 스케줄링 대상에 참여하는 job을 조절하는 것이라면 중간수준 스케줄링은 이미 들어온 프로세스들에 대해서 전체적으로 조절하는 것이다. 이는 프로세스의 상태 중 보류 상태(suspend state)에 해당하며 저수준 스케줄링이 원만하게 이루어지도록 완충하는 역할을 한다.
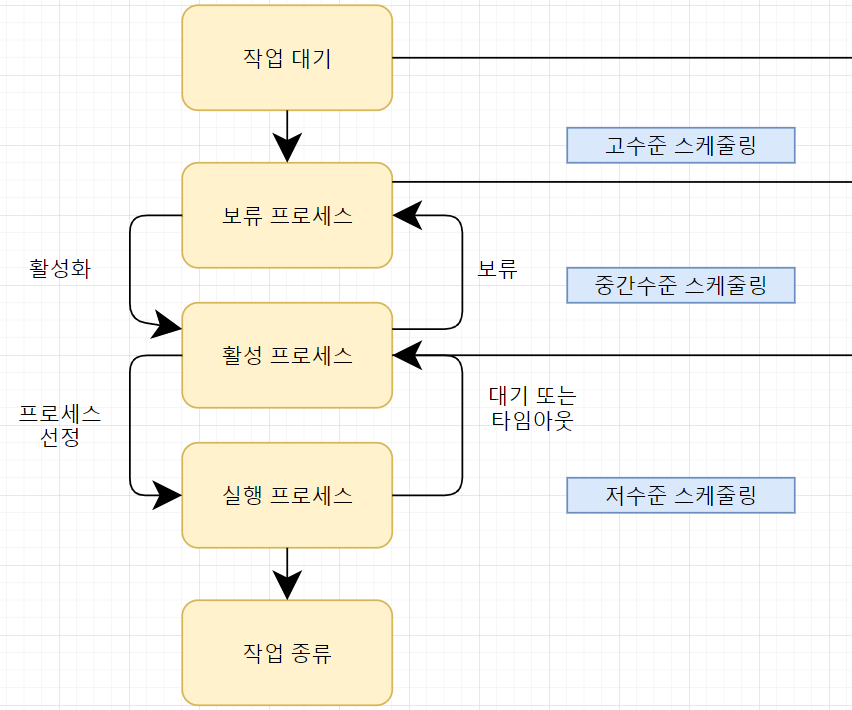
그림으로 표현하면 다음과 같다.
고수준 스케줄링에서 전체 시스템의 부하를 고려하여 작업을 시작할지 말지 결정한다. 이 결정에 따라 전체 프로세스 수가 결정되는 것이다.
중간수준 스케줄링은 시스템이 과부하가 걸려서 전체 프로세스 수를 조절해야할 때, 이미 활성화된 프로세스 중 일부를 보류 상태로 보낸다. 보류된 프로세스는 처리 능력에 여유가 생기면 다시 활성화된다.
저수준 스케줄링에서 실제로 작업이 이루어진다. CPU 스케줄러는 필요에 따라 준비 상태에 있는 프로세스를 실행 상태로 옮기기고, 대기 상태로 보내기도 하며, 타임아웃으로 준비 상태로 보내기도 한다. 보통 특별한 명시가 없다면 CPU 스케줄러는 저수준 CPU 스케줄러를 말한다.
2. 스케줄링 목적
음식적에서 손님들과 직원들을 관리한다고 하자, 손님들에게 형평성있게 음식을 주어야하고, 직원들은 효율적으로 일을 시켜야하며 새로운 손님이 와도 여유있게 받을 수 있어야한다.
비슷하게 손님은 프로세스고, 직원은 자원이 된다. 관리자는 스케줄러가 된다. 스케줄러는 프로세스를 공평하게 자원을 효율적으로 배분하며, 안정적으로 운영해야 한다. 또한, 새로운 프로세스에 대해서도 유연하게 처리하기위해 확정성을 갖추어야한다.
이를 정리하면 다음과 같다.
- 공평성 : 모든 프로세스가 자원을 공평하게 배정받아야 하며 자원 배정 과정에서 프로세스가 배제되어서는 안된다.
- 효율성 : 시스템 자원이 유휴 시간 없이 사용되도록 스케줄링을 하고, 유휴 자원을 사용하려는 프로세스에는 우선권을 주어야 한다.
- 안정성 : 우선순위를 사용하여 중요 프로세스가 먼저 작동하도록 배정함으로써 시스템 자원을 점유하거나 파괴하려는 프로세스로부터 자원을 보호해야 한다.
- 확장성 : 프로세스가 증가해도 시스템이 안정적으로 작동하도록 조치해야 한다. 또한 시스템 자원이 늘어나는 경우 이 혜택이 시스템에 반영되게 해야한다.
- 반응 시간 보장 : 응답이 없는 경우 사용자는 시스템이 멈춘 것으로 가정하기 때문에 시스템은 적절한 시간 안에 프로세스의 요구에 반응해야 한다.
- 무한 연기 방지 : 특정 프로세스의 작업 무한히 연기되어서는 안된다.
2.1 선점형(preemptive)과 비선점형(non-preemptive) 스케줄링
선점은 '빼앗을 수 있음' 을 의미한다.
- 선점형 스케줄링(preemptive) : 어떤 프로세스가 CPU를 할당받아 실행 중이더라도 운영체제가 CPU를 강제로 빼앗을 수 있는 스케줄링 방식이다.
- 비선점형 스케줄링(non-preemptive) : 어떤 프로세스가 CPU를 점유하면 다른 프로세스가 이를 빼앗을 수 없는 스케줄링 방식이다.
가령, CPU를 할당받은 프로세스가 일을 하고 있는데 인터럽트가 걸린다면 프로세스는 CPU 자원을 해제시킨다. 이처럼 선점형 스케줄링은 context switching 같은 부가적인 작업으로 인한 자원의 낭비가 있지만, 하나의 프로세스가 CPU를 독점할 수 없어 더 효율이 좋고 공평하다.
3. CPU 집중 프로세스, IO 집중 프로세스 ( CPU bound process, io bound process)
프로세스가 실제 작업을 수행하는 상태는 실행(running)과 대기(Blocked) 상태이다. 실행상태에서는 CPU를 할당받아 연산 처리를 하므로 CPU 버스트 작업이라고 한다. 대기(blocked)상태에서는 입출력 작업을 처리하므로 입출력 버스트, IO 버스트 작업이라고 부른다.
이에 따라, 프로세스는 cpu가 더 많은 처리를 해야하는지, 또는 입출력 처리가 더 많이 처리되어야 하는지에 따라 CPU 집중 프로세스(CPU bound process), IO 집중 프로세스(IO bound process)로 나뉜다.
생각해보면 스케줄러는 IO 집중 프로세스를 먼저 실행 상태로 옮기는 것이 좋다. 왜냐하면 IO 집중 프로세스는 어차피 들어오고나서 IO처리를 위해 대기상태에 빠질 것이고, 이 때를 틈타 CPU 집중 프로세스가 실행 상태로 옮겨질 수 있기 때문이다. 따라서, IO 집중 프로세스가 실행 상태에 먼저 들어가는 경우를 사이클 훔치기(cycle stealing)라고 한다. 이는 IO 집중 프로세스에 우선순위를 CPU 집중 프로세스보다 더 높게 함으로서 구현할 수 있다.
4. 전면 프로세스, 후면 프로세스
- 전면 프로세스 : GUI 를 사용하는 운영체제에서 화면의 맨 앞에 놓인 프로세스로 현재 입력과 출력을 사용하는 프로세스이다.(상호작용, 대화형 프로세스)
- 후면 프로세스 : 사용자와 상호작용 없이 백그라운드에서 동작하는 프로세스를 말한다.(일괄, 배치 프로세스)
이는 전면 프로세스가 후면 프로세스보다 IO 집중 프로세스이라는 것이므로 전면 프로세스가 우선순위가 더 높다는 것을 의미한다. 반면 후면 프로세스는 전면 프로세스보다 CPU 집중 프로세스에 더 가까우므로 우선순위가 더 낮다는 것이다.
5. 다중큐
5.1 Ready 상태의 다중큐
스케줄러가 준비(ready) 상태의 프로세스를 실행(running) 상태로 바꿀 때, 어떤 프로세스를 선택하냐는 우선순위에 따라 다르다. 우선순위는 PCB에 적혀있는데, 매번 PCB를 모두 순회하여 프로세스를 찾아내면 부하가 정말 클 것이다. 그래서 스케줄러는 다중 큐(multi queue)를 우선순위 별로 두어 필요할 때마다 우선 순위가 높은 순서로 pop해나간다.
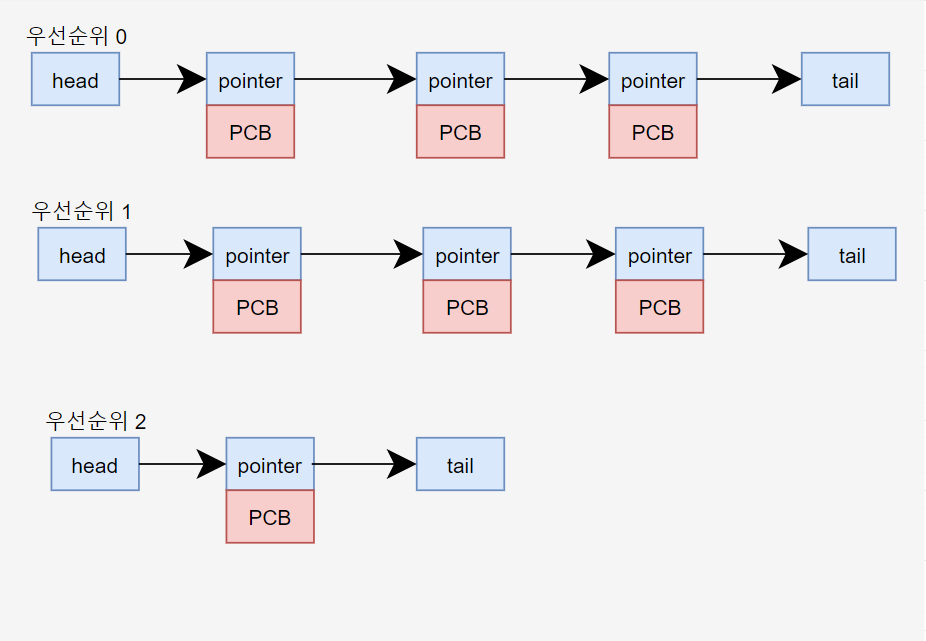
참고로 우선순위는 번호가 낮을수록 높은 순서이다. (가령 음식점에서 받은 대기표는 순서가 낮을수록 우선순위가 높은 것처럼 말이다.)
다음의 사진은 ready 상태인 process들을 다중큐로 묶어낸 것이다. 다중이라는 말은 우선순위 level을 multi로 구현했다는 것이고, 그 내부는 queue로 이루어져 있다는 것이다.
우선순위 별로 정리하였기 때문에, 우선순위가 높을수록 하나씩 pop을 해나가는 것이다. 참고로 queue이기 때문에 head의 앞에 있는 것부터 나간다. 그리고 data가 들어오면 tail 앞에 넣어준다.
ready queue를 몇개로 나눌지 여러 개의 ready queue에 있는 프로세스 중 어떤 프로세스에 CPU를 할당할 지 결정하는 일은 스케줄링 알고리즘에 따라 달라진다. 이는 뒤에서 하나하나씩 알아가보자
참고로, 프로세스의 우선순위를 배정하는 방식은 두 가지가 있다.
1. 고정우선순위 방식 : 운영체제가 우선순위를 부여하면 끝날 때까지 바뀌지 않는 방식이다. 단, 이는 구현은 쉽지만 변동에 대응하기 어렵다는 단점이 있다.
2. 변동 우선순위 방식 : 프로세스 생성 시 부여받은 우선순위가 프로세스 작업 중간에 변하는 방식이다. 구현하기는 어렵지만 시스템의 효율성이 좋다.
5.2 block상태의 다중큐
block상태는 입출력이 완료되기를 기다리는 프로세스들이 모여있는 곳이다. 시스템 내의 다양한 입출력 장치들이 각자의 queue를 가지고 있어 이들이 block된 process에게 IO작업이 완료되었다는 것을 알려준다. 만약 이렇게 queue를 입출력 장치별로 만들어놓지 않았으면 USB입출력 장치가 완료되면 모든 PCB을 뒤져서 block상태에서 ready상태로 천이시켜주어야 할 것이다. 이는 시스템 효율이 좋지 않다.
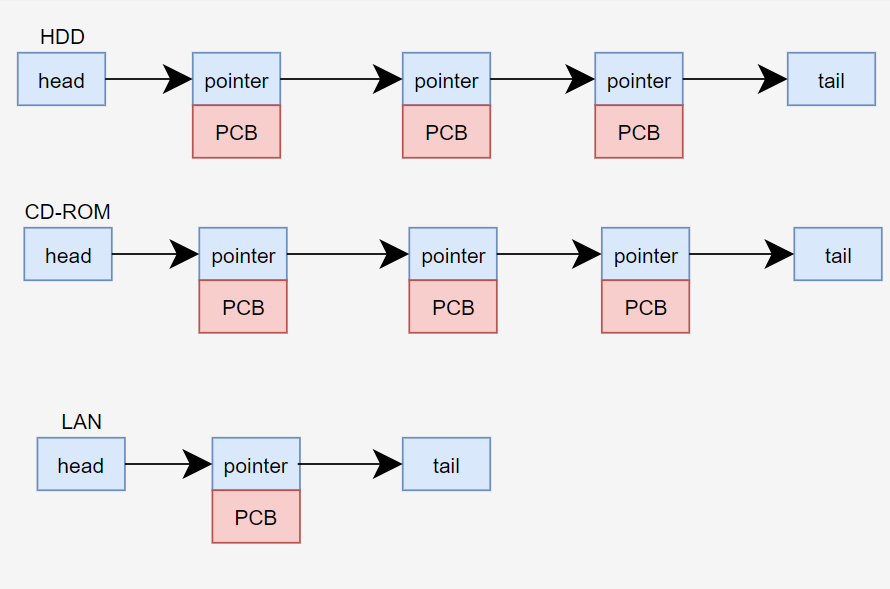
같은 장치의 입출력을 기다리는 프로세스의 PCB는 동일한 입출력 큐에 모여있게 된다. 한 가지 대기상태의 다중큐와 다른점은, 대기 상태의 다중큐는 전체 우선순위 큐에서 하나의 process를 선택해서 실행하는 것이다.
그런데, block 상태의 다중큐는 각 입출력 마다 한 개씩의 process를 선택해서 실행하는 것이다. 따라서, 동시에 다른 주변기기들로 부터 IO 작업이 완료되었다는 인터럽트가 발생할 수 있다. 이를 처리하기위한 로직이 담긴 인터럽트 벡터가 있는데, 이 안에 동시에 완료된 입출력 정보와 처리 방법이 담겨져 있다.
이렇게 다중큐를 사용하여 각 상태별로 process들을 효율적으로 관리하게 된다. 그러나, queue라고해서 무조건 앞에 있는 것만 pop하는 것은 아니다. 앞서 말했듯이 변동우선순위 방식에서는 ready queue이든, block queue이든 CPU 스케줄링 방식에 따라 우선순위가 바뀌어 뒤에 있던 것이 앞으로와 실행될 수 있다.
