
![]()
1. 기본 정렬 알고리즘
고등학생 때, 나는 행렬을 굉장히 잘했다. (요즘 세대는 행렬을 고등학생 때 안배운다 카더라)
왜 난 행렬을 잘했고, 그 뒤에 있던 다른 수학 내용은 못했을까??
아주 단순하다.
행렬은 수학책 첫장에 있었기 때문이다.

행렬은 해치웠지만, 그 뒤의 수학들은 해치우지 못했다.
이와 비슷하게, 알고리즘을 배우신다면 가장 먼저 만나게 될 내용은 바로 정렬이다.
그 중에서도 O(n^2) 정렬이다.
혹시나 하는 마음에 O(n^2) 에 대해서 잘 모르신다면, 간단하게 설명하겠다.
O 는 빅오라고 읽고
(n^2)은 그냥 n 제곱이라고 읽는다.
따라서 O(n^2)은 빅오 n 제곱이다.
"이 의미는 아주아주 최악을 잡아도 n^2 시간이 걸립니다!"
를 의미한다.
컴퓨터의 수행시간은 1초에 1억(10^8) 정도이기 때문에, 만약 n = 10^5이면, 1초안에 수행이 불가능하여 컴퓨터에 부하가 걸리게 된다. 우리가 풀려고 하는 문제 대부분은 1초안에 해결해야하므로 이 사실만을 기억하고 공부해보자.
더 자세한 내용은 아래의 링크를 남기겠다. (종만북 만세!)
https://book.algospot.com/estimation.html
자 그럼, O(n^2)의 정렬 알고리즘을 알아보자
2. 버블 정렬
_thumb.jpg)
원 투 쓰리 풔~ 버블버블~
유명한 세탁기 CF인데, 여기서 나오는 버블과 버블 정렬의 버블은 같은 의미이다.
정렬되는 모습이 마치 거품이 일어나는 것과 같다고 여겨 버블 정렬이라고 하는데, 전혀 그렇게 안보이니 그냥 그러려니 하자
만약 내가 어떤 수들을 오름차순으로 정렬한다고 하자
그럼 어떻게 해야할까??
버블 정렬의 원리(로직)은 아주 간단하다.
오름 차순으로 정렬한다는 것은, 내 왼쪽은 나보다 작고, 오른쪽은 나보다 크다는 것이다.
그럼 가장 첫번째 수를 기준으로 오른쪽은 나보다 큰 수여야 한다.
그런데 나보다 작다? 그럼 바꿔!
만약 나보다 크다? 그럼 가만히 두자
그 다음 두번째 수를 기준으로 이를 반복하는 것이다.
그림으로 보자

다음과 같이 정렬이 안된 배열이 있다고 하자, 이 수를 오름차순으로 정렬하고 싶은데 어떻게 해야할까?? 앞서 소개한 버블 정렬의 로직을 생각해보자,
내 왼쪽은 나보다 작고, 내 오른쪽은 나보다 크다는 것이다.
그렇다면 오른쪽이 나보다 작다면, 나와 바꾸어야 하고, 이 말은 반대로 오른쪽 입장에서는 왼쪽이 나보다 크다면 나와 자리를 바꾸어야 한다는 것이다.
이 과정을 첫번째, 두번째, 세번째 ... 마지막 값까지 이웃과 비교하면 된다.

그래서 우리는 두 개의 포인터(화살표)를 준비하였다.
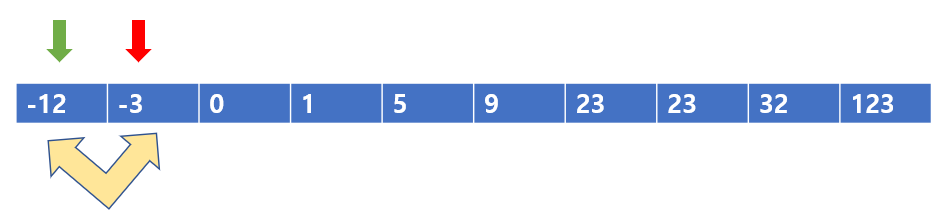
빨간색를 기준으로 생각해보자
버블 정렬은 뭐다? 내 오른쪽은 나보다 크고, 내 왼쪽은 나보다 작다는 것이다.
그렇다면 우리는 초록색 포인터와 빨간색 포인터를 비교해보자
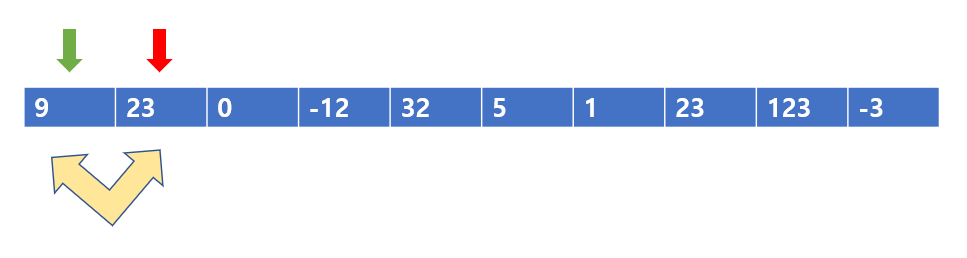
빨간색 포인터 기준으로 왼쪽은 자신보다 작아야한다.
초록색 포인터가 가리키는 값은 9이고, 빨간색 포인터가 가리키는 값은 23이므로 9 < 23 이다.
따라서, 빨간색 포인터 기준으로 왼쪽은 자신보다 작은 값이 오므로 그냥 넘어가도록 하자
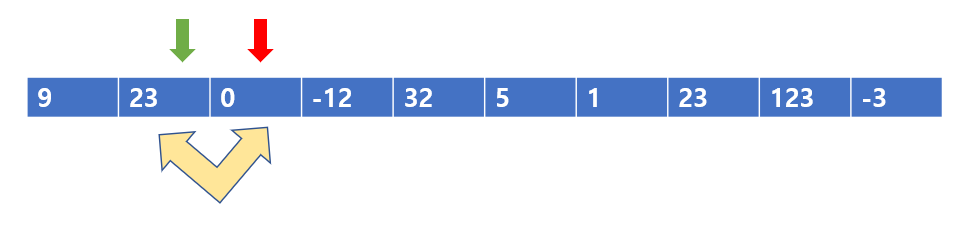
빨간색 포인터와 초록색 포인터를 한 칸 씩 옮겨보자,
다시 빨간색 포인터 기준으로 왼쪽인 초록색 포인터 값을 비교하면 23 < 0 이 된다.
이는 빨간색 포인터 기준으로 왼쪽이 자신보다 더 작아야 한다는 버블 정렬의 규칙에서 벗어났다. 따라서 이들을 바꾸어 준다.

다음은 23과 0을 바꾸어주고, 빨간색 포인터와 초록색 포인터를 한 칸 씩 옮겨간 모습이다. 이 역시 비교를 한다면 23 < -12 가 되므로, 이 두 값을 서로 바꾸어 주자
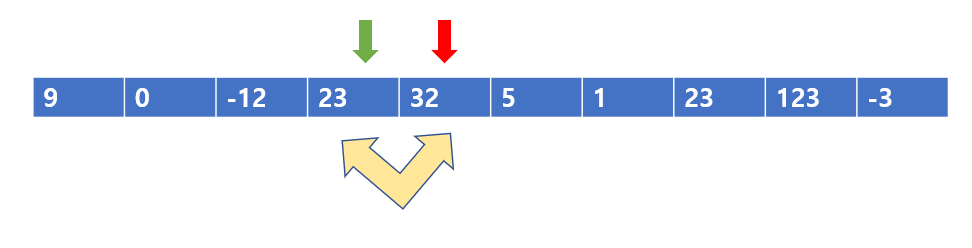
-12 와 23을 바꾸어주고, 다음 칸으로 넘어간 모습이다.
23 < 32니까 바꾸지 않는다.
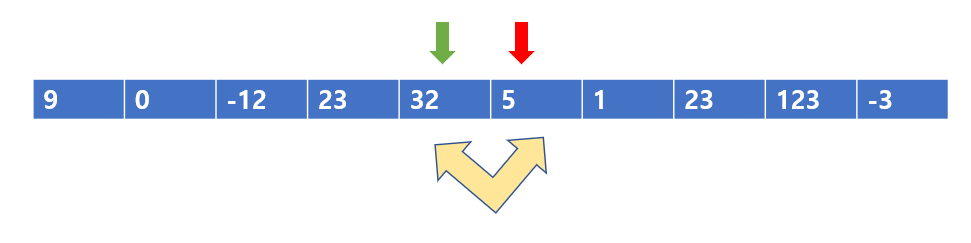
다음 칸으로 가고, 32 < 5이므로 서로를 바꾸어 준다.
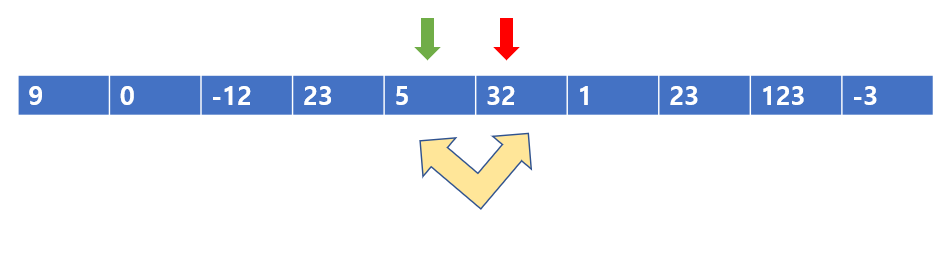
이렇게 바꾸어 주면 된다.
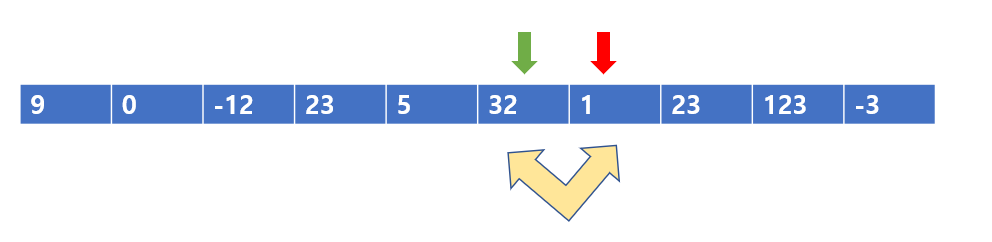
다음 칸으로 넘어가고, 32 < 1을 비교한다.
당연히 빨간색 포인터와 왼쪽 초록색 포인터 값을 바꾸어준다.
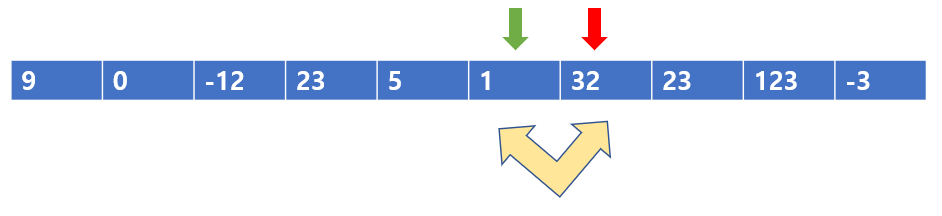
이렇게 말이다.

이제 귀찮으니까 쭉쭉 나가자 23 < 32 이므로 바꾸어주지 않고 넘어간다.
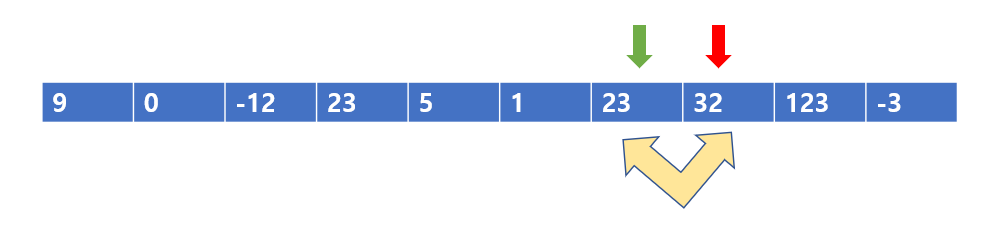

32 < 123 이므로 바꾸어주지 않고 넘어가자

123 < -3 이므로 바꾸어준다.
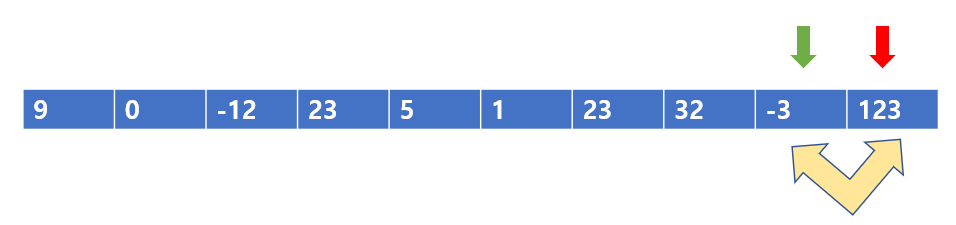
짜잔, 드디어 빨간색 포인터 기준으로 왼쪽은 자신보다 작은 값 밖에 없게 되었다.
이제 더 이상, 123이라는 값은 건드리지 않아도 된다. 왜냐하면 이 자리가 최종 자리이기
때문이다.
이제 나머지를 가지고 비교를 진행하면 된다.
이 다음부터를 라운드 2라고 하자
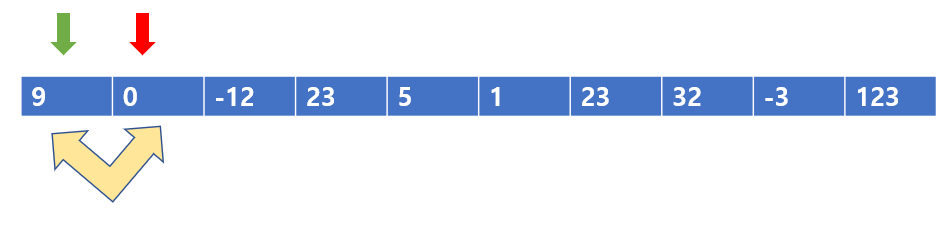
2라운드 부터도 역시 빨간색 포인터 기준으로 왼쪽은 자신보다 작은 값을 가지도록 만든다. 9 < 0 이므로, 이들을 바꾸어 주도록 하자
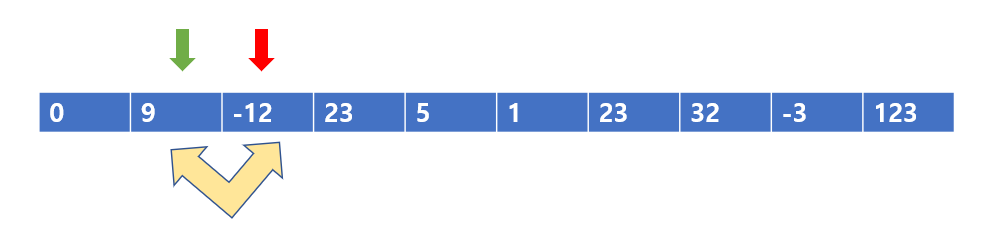
다음칸으로 넘어가서 비교하면, 9 < -12이므로 교환해준다.
귀찮으므로 쭉쭉 넘어가보자
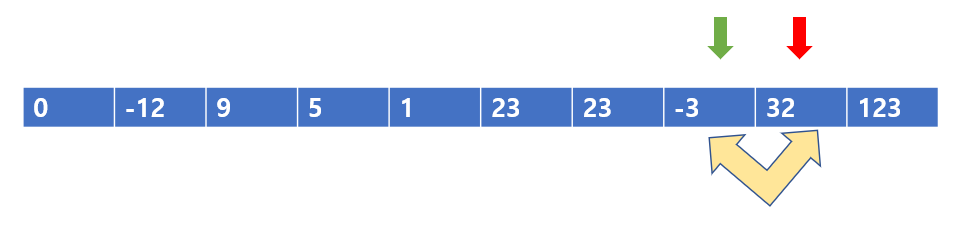
결국 2라운드의 최종은 -3 <32를 비교로 끝난다. 123은과 32는 비교해도 되고, 안해도 되는데 된다. 왜냐하면 123은 1라운드 때 이미 정렬을 마쳤다. 자신의 왼쪽에는 자신보다 작은 값 밖에 없기 때문에 32와 비교해도 자리가 바뀌지 않는다. 이는 반대로 비교를 안해도 상관없다는 말과 같다.
그럼 우리는 몇 라운드를 해야할까?? 두 개의 포인터를 기준으로 비교하는 작업은 배열 한 줄을 싹 도는 것을 한 번으로 하나의 값이 맨 뒤부터 정렬된다. 그 말은 배열 한 줄에 N개의 원소가 있다면 1개의 값(빨간색 포인터)을 정렬시키는데 N번 비교 작업을 해야한다는 것이다. 따라서 N개의 수를 각각이 N번씩 비교작업을 하므로 O(n^2)이 된다.
즉, 라운드를 N번이나 해야하는 것이다.
최종 정렬된 모습은 이렇게 나올 것이다.
그렇다면 코드로 만들어보자
코드
#include <iostream>
using namespace std;
int n = 10;
int data[] = {9,23,0,-12,32,5,1,23,123,-3};
void bubbleSort(){
for(int i = 0; i < n; i++){
for(int j = 1; j < n-i; j++){
if(data[j-1] > data[j]){
int temp = data[j-1];
data[j-1] = data[j];
data[j] = temp;
}
}
}
for(int i = 0; i < n; i++){
cout << data[i] << ' ';
}
}
int main(){
bubbleSort();
}설명을 하자면 int i 로 순회하는 for문은 라운드 수이다.
그 안에 있는 for문의 j가 빨간색 포인터이고, j-1이 초록색 포인터이다.
for문 순회가 n-i번 반복하는 이유는 맨 뒤에 정렬된 숫자를 차곡차곡 쌓아놓기 때문에 비교할 필요가 없어 적어둔 것이다. n-i 를 안써주고 n으로 써줘도 상관은 없다.
3. 선택 정렬(Selection Sort)
선택 정렬은 버블 정렬처럼 길게 하지 않을 것이다. (버블 정렬에 너무 많은 열정을 투자했다...)
선택 정렬은 굉장히 단순하다. 아마 정렬 알고리즘을 배우지 않았어도 이 알고리즘을 사용했을 것이다.
선택 정렬의 원리
선택 정렬의 핵심은, 배열에서 가장 큰 값을 찾았다면, 그 값은 배열의 맨 마지막에 위치해야한다. 그럼, 두 번째로 배열에서 가장 큰 값을 찾았다면, 그 값은 배열의 맨 마지막에서 두 번째 칸에 위치해야한다.
이게 끝이다. 반대로 가장 작은 값을 찾았다면, 배열의 가장 첫번째 위치에 넣으면 된다.
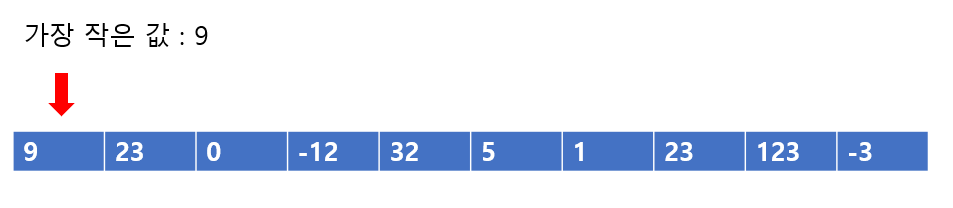
자 다음과 같은 배열이 있다고 하자, 우리가 이번에 해야할 것은, 배열에서 가장 작은 값을 찾아서 맨 처음 자리에 해당 값을 넣는 것이다. 그렇다면 배열에서 가장 작은 값을 찾아보자
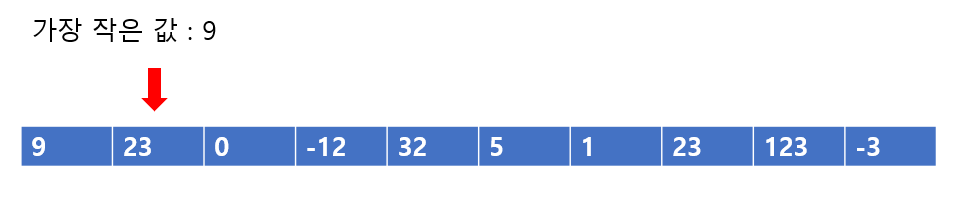
23은 9보다 크므로 pass
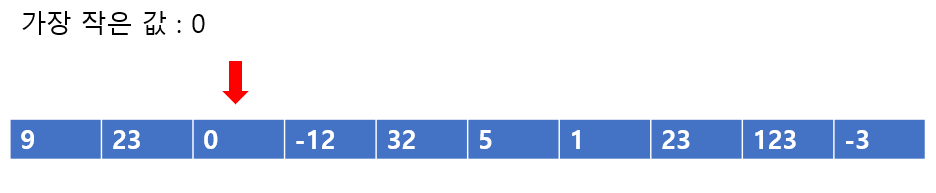
0은 9보다 작으므로 현재까지 가장 작은 값은 0이다. 이렇게 하나하나 비교를 쭉 해나가면
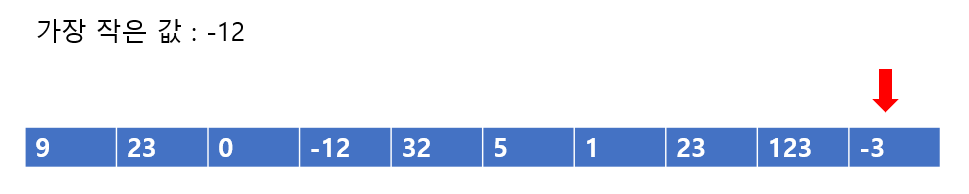
배열의 가장 마지막 자리에 이르면 가장 작은 값이 -12이라는 것을 알 수 있다.
이제 이 값을 배열의 맨 첫번째 자리에 넣어주도록 하자

-12를 맨 앞에 넣기 위해서는 -12와 배열 맨 처음에 있는 값을 서로 교환해주어야 한다. 색으로 표시해두었다. 이제 -12를 제외한, 바로 다음으로 가장 작은 값을 배열에서 찾아주도록 하자,
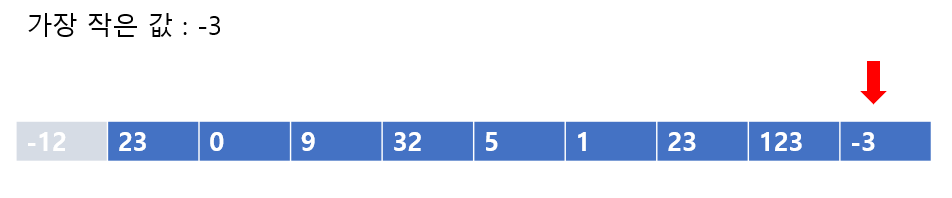
두 번째로 배열에서 가장 작은 값은 -3이었다. -3과 23의 자리를 바꾸어주도록 하자

다음은 -12와 -3을 제외한 나머지 중 가장 작은 값을 찾는다. 그리고 이 값은 -12와 -3 다음으로 작은 값이므로 3번째 자리에 위치해야한다. 따라서 3번째 자리인 0부터 시작한다.

이렇게 가장 작은 값을 선택하고, 선택한 값을 배열의 맨 처음부터 차근차근 넣어주는 것이 바로 선택 정렬이다. 반대로 배열에서 가장 큰 값을 선택하고, 선택한 값을 배열의 맨 끝부터 차근차근 넣어주는 것도 가능하다.
시간 복잡도는 어떻게 될까??
우리는 총 N개의 숫자로 이루어진 배열에서 가장 작은 수를 선택하였고, 이를 배열의 맨 첫 자리에 넣어주었다. 그렇다면, 가장 작은 수를 찾는 과정은 배열의 모든 수와 비교해야하므로 N번 해야하고, 하나씩 자리가 채워지므로 N개의 자리(라운드)를 반복해서 채워야 한다.
따라서 N*N = N^2, O(N^2)이 걸린다.
코드
#include <iostream>
using namespace std;
int n = 10;
int data[] = {9,23,0,-12,32,5,1,23,123,-3};
void selectionSort(){
for(int i = 0; i < n; i++){
int index = i;
for(int j = i; j < n; j++){
if( data[index] > data[j]) index = j;
}
int temp = data[index];
data[index] = data[i];
data[i] = temp;
}
}
int main(){
selectionSort();
for(int i = 0; i < n ; i++){
cout << data[i] << ' ';
}
}변수 index는 매 라운드마다 가장 작은 값의 위치를 기록한다.
가장 안 쪽에 있는 for문의 j는 정렬된 자리를 제외한 나머지 중에서 가장 작은 값을 찾기 위해 반복된다.
밖에 있는 for문의 i는 i번째로 작은 값이 위치할 자리를 의미한다. i = 0이면 가장 작은 값이 위치할 자리이므로 배열 맨 앞에 오게 된다.

멈춰! 수업은 여기까지다!
안된다! 우리에겐 아직 삽입정렬이 남았다.
아쉽게도 기본 정렬 알고리즘 중에선 삽입 정렬이 제일 어렵다.
4. 삽입 정렬(Insertion Sort)
삽입 정렬의 핵심 아이디어는 다음과 같다.
- 정렬이 된 그룹과 정렬이 안된 그룹이 있다.
- 정렬이 안된 그룹의 원소를 정렬이 된 그룹으로 보낸다.
- 정렬이 된 그룹은 정렬이 되었다는 것을 지켜야하므로, 새로운 원소를 기준으로 정렬을 시작한다.
- 이렇게 반복하면 정렬이 된 그룹만 남게된다.
여기서 삽입(insertion)이라는 것은 정렬이 안된 그룹의 원소를 정렬이 된 그룹의 원소로 삽입(보내기)하는 것을 의미한다.

다음과 같은 배열이 있다고 하자, 이를 삽입 정렬로 정렬을 해보자

위에서 언급했듯이 삽입 정렬의 핵심은 '정렬이 된 그룹'과 '정렬이 안된 그룹'이다. 여기서는 '정렬이 안된 그룹'을 파란색으로 표현하였고, 정렬이 된 그룹을 초록색으로 표시하였다.
가장 처음, 원소를 기준으로 정렬이 된 그룹을 만든다. 정렬이 안된 그룹 내에 원소가 하나 밖에 없다면 이는 정렬이 된 것이다.

다음은 '정렬이 안된 그룹'에서 '정렬이 된 그룹'으로 원소를 가져와보자, 23을 '정렬이 된 그룹'에 넣어주는 것이다. 그러면 '정렬이 된 그룹'은 9와 23으로 이루어지게 된다. 이는 정렬이 된 상태이므로 넘어가자
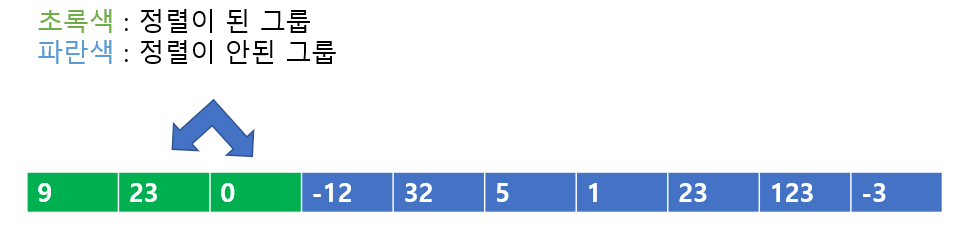
다음은 '정렬이 된 그룹'에 0을 넣어보자, 이러면 정렬이 무너진다. 그러므로 23과 0을 비교하여 바꾸어준다.
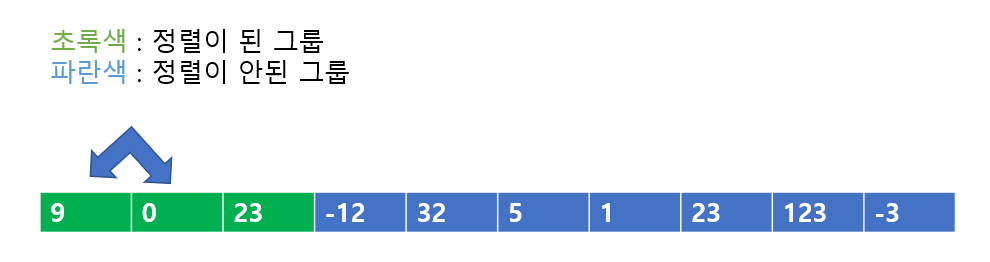
다음 역시도 정렬이 무너진 상태이다. 9와 0을 바꾸어주자
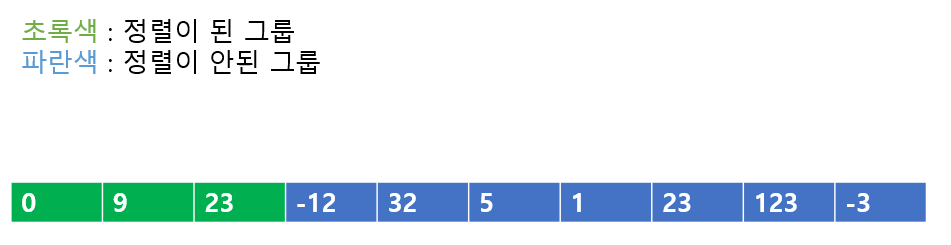
이렇게 정렬해주면 '정렬이 된 그룹'이 성립하게 된다.
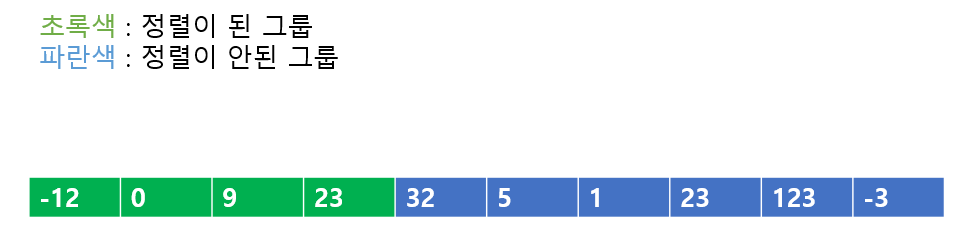
다음은 23을 넣어준다. 9와 비교하니 23이 더 크다. 따라서 정렬이 되었음을 알 수 있다.
이게 굉장히 큰 핵심인데, '정렬이 된 그룹'에 정렬이 안된 그룹의 원소를 추가할 때, '정렬이 된 그룹'의 바로 앞 값과 서로를 비교하여 문제가 없다면 더 이상 그 앞으로 정렬을 진행하지 않아도 된다.
즉 9 <23 이므로 더이 상 0과 23, -12와 23을 비교할 필요가 없다는 것이다.
왜?? '정렬이 된 그룹' 이기 때문에 '정렬이 된 그룹'의 맨 마지막 값은 '정렬이 된 그룹'에서 사장 큰 값이기 때문이다. 해당 값 새로들어 온 값을 비교 했을 때, 새로 들어온 값이 크다면 이는 '정렬이 된 그룹'의 맨 마지막 값 앞의 값들은 새로 들어온 값보다 작기 때문에 비교를 더 이상 진행하지 않아도 된다는 것이다. 이게 삽입 정렬에 있어서 정말 큰 장점이기 때문에 기억해두자
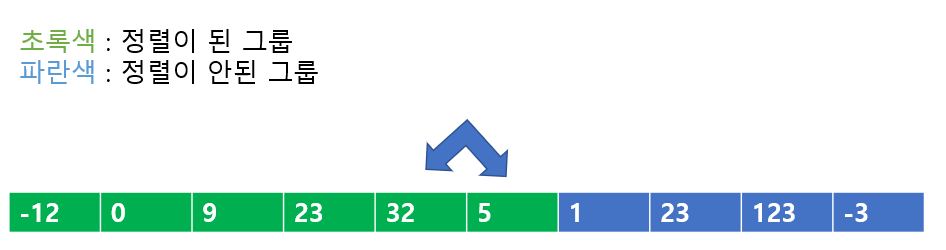
다음으로 5가 새로운 값으로 들어온다. 32 < 5 이므로 서로 바꾸어준다. 바꾸어주고 나서도 23 < 5이므로 서로 바꾸어주고, 9 < 5이므로 서로 바꾸어 준다.

이번에는 32가 추가되었다. 23 < 32 이므로 비교를 종료하고 다음 칸으로 간다.
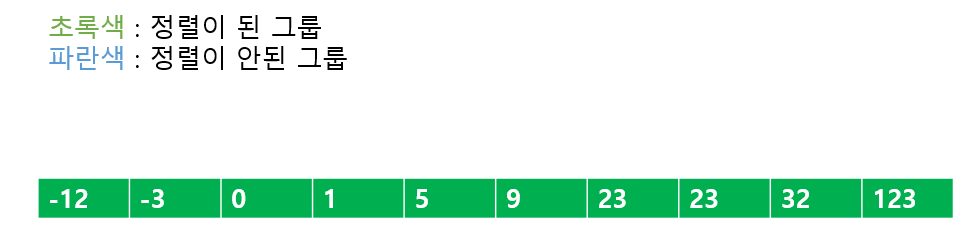
'정렬이 된 그룹'이 모든 배열 값을 품고 있다면 이는 정렬이 끝난 것이다.
우리는 '정렬이 된 그룹'에 '정렬이 안 된 그룹'의 원소를 하나하나 씩 추가하고, '정렬이 된 그룹'의 기존 값과 하나하나 비교를 수행하였다. '정렬이 된 그룹'의 최대 원소는 N개 이고, 새로운 원소의 최대 값은 N개 이므로 O(N^2) 시간 복잡도를 갖게 된다.
그런데, 이는 최악, 평균 시간 복잡도이고 최선의 시간 복잡도는 O(n)이다
맙소사! 어떻게 그런 일이 가능한가??
한다면 다음과 같다.

자 다음의 배열을 삽입 정렬해보자
어떻게 되는가??
우리는 이전에 '정렬이 된 그룹'에 새로운 원소를 추가할 때, '정렬이 된 그룹'에의 맨 마지막 값이 새로운 원소보다 작다면 비교를 중지하고 새로운 원소를 또 추가하는 페이즈로 간다고 했다.
그렇다, 위의 원소는 이미 정렬이 끝난 배열이다. 이 배열은 이미 정렬이 되었으므로, '정렬이 된 그룹'을 만들고 새로운 원소를 추가해도 한 번 밖에 비교 연산이 이루어지지 않는다. 따라서 O(n)만에 해결된다.
코드
#include <iostream>
using namespace std;
int n = 10;
int data[] = {9,23,0,-12,32,5,1,23,123,-3};
int main(){
for(int i = 1; i < n; i++){
for(int j = i; j > 0 ; j--){
if(data[j-1] > data[j]){
int temp = data[j-1];
data[j-1] = data[j];
data[j] = temp;
}else{
break;
}
}
}
for(int i = 0; i < n; i++){
cout << data[i] << ' ';
}
}첫 번째 for문에서 i 는 정렬이 된 그룹에 추가할 새로운 원소의 위치를 의미한다.
그 안에 있는 두번째 for문의 j는 정렬이 된 그룹과 새로 추가된 원소의 비교 연산 과정을 나타낸다.
만약 새로 추가된 원소가 더 작다면 정렬이 된 원소의 값과 바꾸어 앞으로 나아 간다.
그런데, 만약 새로 추가된 원소가 더 크다면, 정렬을 멈추어도 되므로 break를 걸고, 다음 새로운 추가 원소를 가져온다.
5. 그래서 이걸 왜 배워야하나?
뭐 어차피 코딩 테스트에서는 sort() 쓰고 끝낼 마당에 이걸 배워야하는 이유가 무엇인지 궁금할 것이다.
나름대로 생각해본 바로는 이렇다.
- 막상 면접 때 이거 못짜는 사람이 생각보다 많다.
- 재밌어서
끄트!
