Redis Architecture
Stand-Alone(Replication)

Stand-alone은 Redis를 단일서버로 구성하여 운영하는 방식으로 장애발생시 Data의 유실, 가용성 확보에 취약하다
Data유실을 최소화 하기 위해 Data백업을 위한 Replication을제공하고 있다.
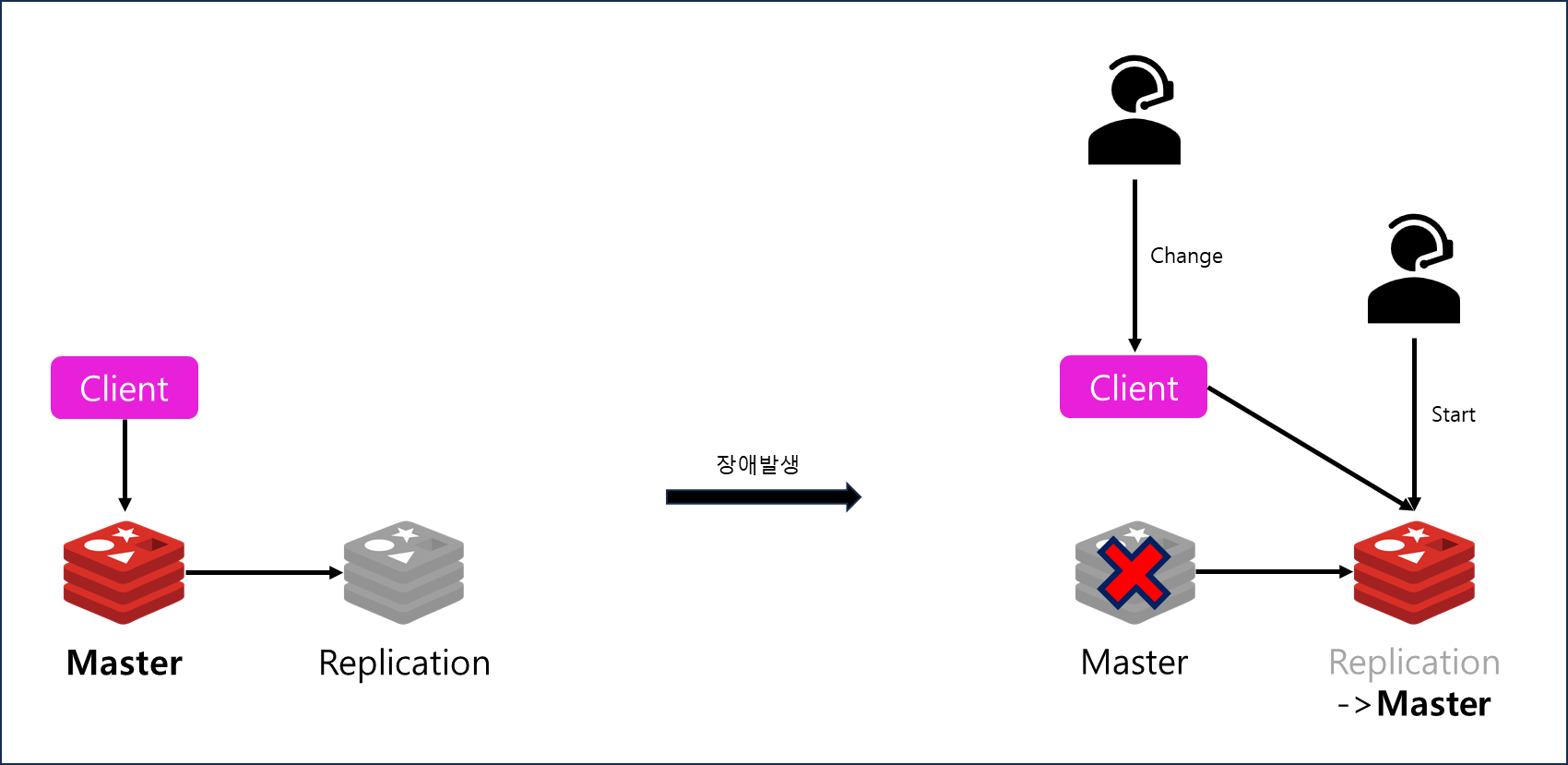
Master서버에 장애 발생시 Replication서버를 Master서버로 활용이 가능하다
단, 이때 Replication서버는 운용자가 직접 기동시켜야하며 별도의 장비가 없다면 Client에서 타깃(Redis Master)서버 주소를 변경해주어야 한다
Sentinel
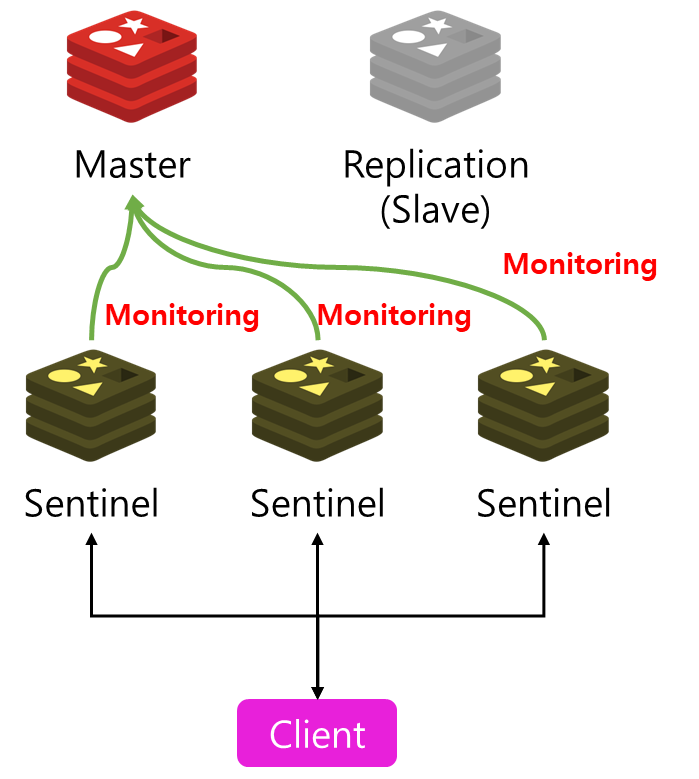
Redis에서는 고가용성 확보를 위하여 Sentinel 기능을 지원한다
Sentinel은 Redis Master서버를 모니터링 하다가 Master서버에 문제가 발생하면 Slave서버로 Failover를 수행하는 역할을 한다
Slave서버는 Master의 Replica서버로 FailOver가 되면 Slave서버가 새로운 Master서버가된다
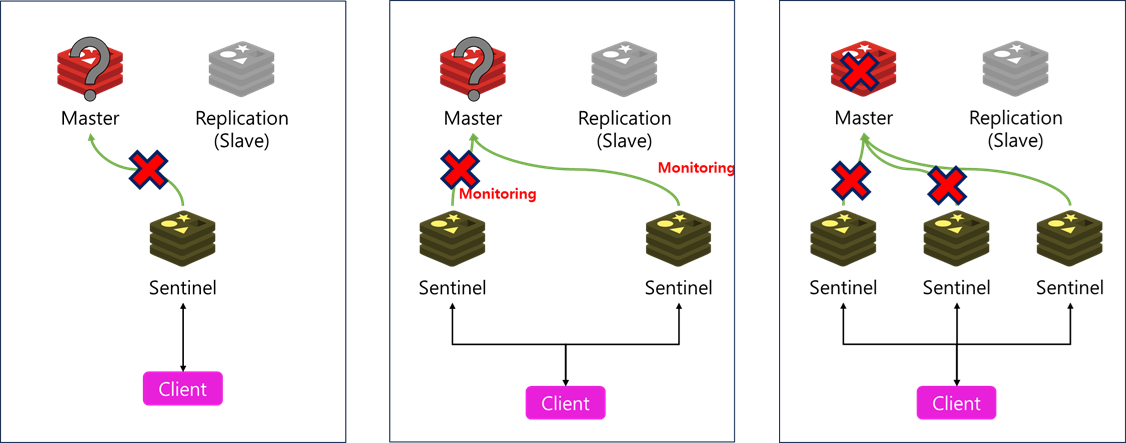
장애여부 판단을 위하여 Sentinel은 3대 이상의 홀수로 구성한다
1대로 구성시 Master서버가 아닌 Sentinel서버의 장애(네트워크차단)로 인한 장애 상황을 탐지할 수 없다
2대로 구성시 1대에만 장애가 발생하면 1:1상황으로 동일하게 판단이 불가능하다
3대로 구성시 2대에서 장애가 발생하면 과반수 이상이 장애로 판단하면 Sentinel서버가아닌 Master 서버의 문제로 판단하여 FailOver를 수행한다
홀수로 구성된 Sentinel 서버는 Quorum을 구성하며 설정한 임계치 이상으로 Sentinel서버가 장애를 인지하면 FailOver를 수행한다
장애탐지는 아래와 같이 판단된다
Subjectively Down(SDOWN)
- Sentinel -> Master로 HealthCheck(Ping)을 수행하며 응답이 없는 경우 탐지된다
Objectively Down(ODOWN)
- 설정된 Quorum 이상 SDOWN이 탐지되면 ODWON으로 인지하고 FailOver를 수행한다
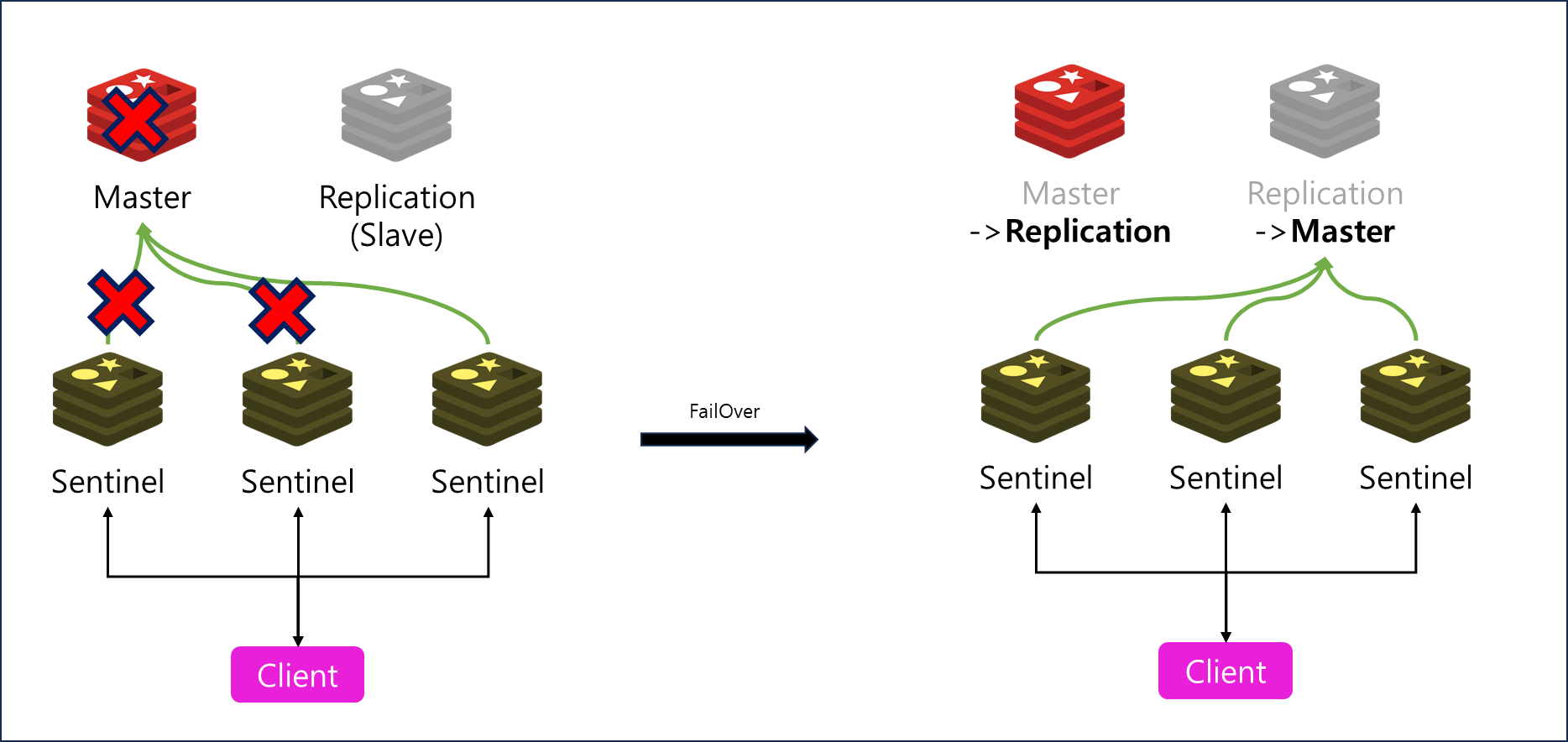
또한 Sentinel 구성에서 Client - Sentienl - Master로 구성이 되어 Master서버가 변경되더라도 Sentinel에서 Redirection을 수행하기 때문에 Client에서 이를 관리할 필요가 없다
Cluster
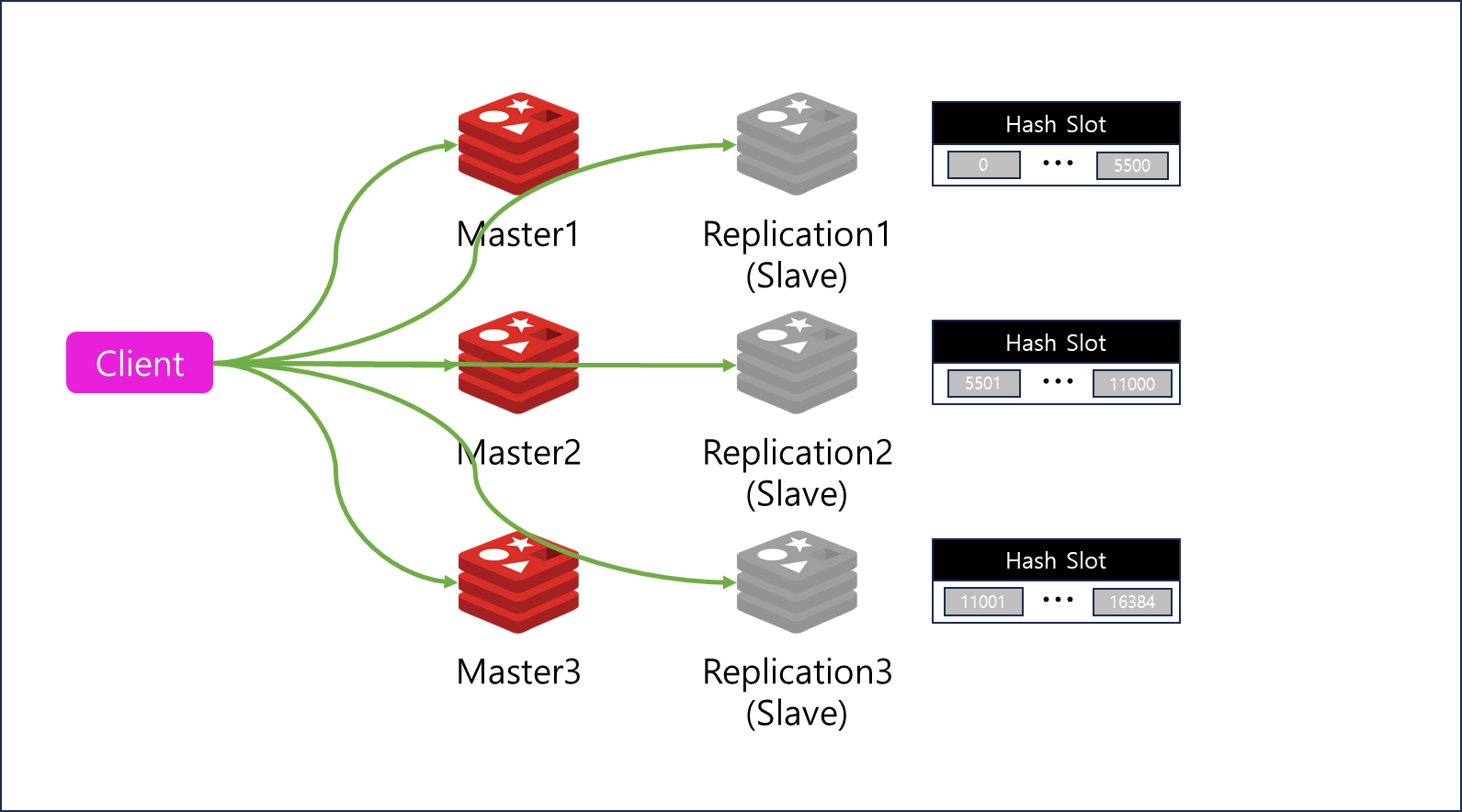
Cluster는 여러대의 Master가 존재할 수 있다. 여러대의 Master에 Hash Slot을 통해 Data를 분산해서 저장한다 ( Sharding을 지원한다 )
Data를 Single-Master가 처리한다면 Scale-Up을 해야하지만 Multi-Master에서 분산 처리하기 때문에 Scale-Out으로 더 많은 처리가 가능하다
Redis Cluster는 Scale-Out시 Online으로 ReSharding 기능을 지원한다
반면 단점으로는 Multi Key Operation이 제한되며 Database도 0번만 사용이 가능하다
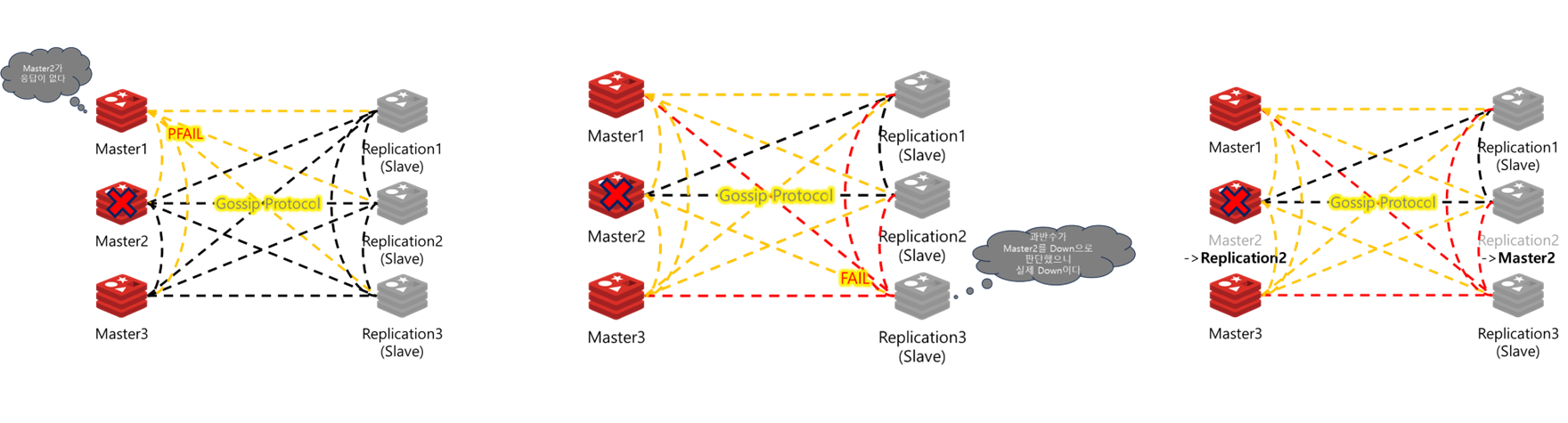
Cluster의 Node는 모두 연결 되어 있다 ( Full-Mesh ) 모두 연결된 Node들은 Gossip Protocol을 통해 상태를 공유한다. Gossip에서 의미하는것처럼 소문이 퍼저나가듯 Node사이의 정보들이 퍼지게 된다.
Cluster는 Master Node중 일부의 장애가 탐지되면 Replica Server를 Master로 승격시킨다
Cluster는 Gossip Protocol을 통해 통신한다 최초로 장애를 탐지한 서버가 장애가 의심되는 메시지(PFAIL)를 보낸다 다른 서버들 또한 메시지를 보내고 과반수를 넘어서면 의심이 아닌 장애 확정 메시지(FAIL)를 송출한다
이 후 Replica서버를 Master서버로 승격 시킨다
Redis의 복제는 비동기 복제로 복제가 완료되지않은 상태에서도 ack를 전달하여 consistency가 약하다. 일부 데이터의 유실이 발생할 수 있다
결론
Sentinel과 Cluster를 비교하면 Sentinel은 단일 서버의 고가용성에 초점을 두고 Cluster는 확장성과 분산처리에 초점을 둔다
Redis구축시 요구되는 Spec에 따라 고려되어야 한다
