1. SQL의 분류
-
DML: 데이터 조작 언어, 로 테이블의 행을 대상으로 한다. 트랜잭션이 발생한다.- SELECT
- INSERT
- UPDATE
- DELETE
-
DDL: 데이터 정의 언어, 데이터베이스, 테이블, 뷰, 인덱스 등 데이터베이스 개체를 생성,삭제,변경하는 역할을 한다. 트랜잭션을 발생시키지 않는다.- CREATE
- ALTER
- DROP
- TURNCATE
-
DCL: 사용자에게 권한을 부여하거나 빼앗을 때- CLMMIT
- ROLLBACK
- GRANT ON TO (WITH GRANT OPTION)
- REVOKE ON FROM
- MYSQL 쉘 로그인 : https://myvelop.tistory.com/24
- 쉘에서 .sql 파일사용
source C:\Users\cha\Downloads\ig_clone_data.sql2. 기본 SQL
-
SHOW database : 현재 서버에 있는 데이터베이스들을 조회
-
USE DB이름 : 사용할 DB 지정
-
SHOW TABLE STATUS : 현재 DB의 테이블들을 조회
-
DESC 테이블이름 : 해당 테이블의 열을 조회
-
열의 이름에 별칭 설정 : 컬럼 뒤에 AS 로 설정
SELECT NAME AS 이름 , GENDER 성별 FROM employees;-
DROP DATABASE (IF EXISTS) 이름 : DB 삭제
-
SELECT database(); : 현재 사용중인 DB를 확인할 때 사용
-
조건절이 숫자인 경우 BETWEEN AND를 사용할 수 있다.
SELECT name, height FROM USERTBL WHERE height BETWEEN 180 AND 183;- 조건절이 연속적인 값이 아닌 경우에는 IN을 사용할 수 있다. IN과 =ANY는 동일한 결과를 출력한다(같은 뜻)
SELECT name, addr FROM USERTBL WHERE addr IN ('경남', '경북', '전남');- 문자를 검색하기 위해서 LIKE를 사용할 수 있다. 인덱스가 있더라도 사용하지 않고 전체 데이터를 검색하므로 비효율적이다.
SELECT name, addr FROM USERTBL WHERE name LIKE '김%';
SELECT name, addr FROM USERTBL WHERE name LIKE '_길동';- 서브쿼리 :
ANY(조건 중 하나만 만족해도 됨),ALL(모두 만족)
SELECT name, height FROM USERTBL WHERE height >
(SELECT height FROM USERTBL WHERE Name = '홍길동');
SELECT name, height FROM usertbl WHERE
height = (SELECT MAX(height) FROM usertbl)
OR
height = (SELECT MIN(height) FROM usertbl)- ORDER BY : 정렬(오름차순이 기본 설정), ORDER BY는 성능을 상당히 떨어뜨릴 소지가 있기 때문에 사용에 주의해야 한다.
SELECT name, mDate FROM USERTBL ORDER BY mDate DESC, name ASC;- DISTINCT : 중복제거, 중복을 제거하고 결과값을 1개씩만 보여준다
SELECT DISTINCT addr FROM USERTBL;- LIMIT : 출력 개수 제한
SELECT name, mDate FROM USERTBL ORDER BY mDate DESC LIMIT 5;- CREATE TABLE 새로운 테이블 (SELECT 복사할 컬럼 또는 전체(*) FROM 기존테이블)
기존 테이블이 가지고 있는 PK, FK는 복사되지 않는다
CREATE TABLE buytbl2 (SELECT userID, proName FROM buytbl1);- GROUP BY, 집계함수 : 함께 사용되는 경우가 많다. 테이블의 행을 GROUP BY 조건별로 묶는다.
SELECT userId as '사용자 아이디', SUM(price*amount) as '총 구매액'
FROM buytbl GROUP BY userId;- HAVING : GROUP BY와 함께 사용하며 WHERE과 같은 기능
SELECT userID AS '사용자', SUM(price*amount) AS '총구매액'
FROM buytbl GROUP BY userID
HAVING SUM(price*amount) > 1000;- ROLLUP : GROUP BY와 함께 사용, 총합 또는 중간 합계
// 각 항목에 대한 계산 , 전체에 대한 계산
SELECT
title, AVG(rating)
FROM
full_reviews
GROUP BY title WITH ROLLUP; --> title별 평균값과 전체 title의 평균을 반환
SELECT
title, COUNT(rating)
FROM
full_reviews
GROUP BY title WITH ROLLUP;
SELECT
first_name, released_year, genre, AVG(rating)
FROM
full_reviews
GROUP BY released_year , genre WITH ROLLUP;
->연도와 장르별 평균, 연도별 평균, 연도와 장르의 전체 평균- AUTO_INCREMENT : 값을 자동을 증가시킨다.
// 초기값을 1000으로 설정하고 3씩 증가한다.
ALTER TABLE testTable AUTO_INCREMENT=1000;
SET @@auto_increment_increment=3;- INSERT INTO 테이블이름 (열이름1, 열이름2 ...)
SELECT문 : 다른 테이블의 데이터를 가져와서 대량으로 입력하는 효과
CREATE TABLE testTable (id int, name varchar(50));
INSERT INTO testTable VALUES(1, '차승준');
INSERT INTO testTable
SELECT emp_no, name
FROM employees;- UPDATE 테이블이름 SET 열1 = 값1, 열2 = 값2... WHERE 조건;
WHERE절은 생략이 가능하지만 생략하면 테이블의 전체 행이 변경된다. 원상태로 복구하기 위해서는 아주 복잡하거나 다시 되돌릴 수 없는 경우도 있다.
UPDATE testTbl SET name = '없음'
// 이렇게하면 모든 name 데이터가 '없음'으로 변경된다- DELETE FROM 테이블이름 WHERE 조건 (LIMIT 5);
WHERE문에 생략되면 전체 데이터를 삭제한다. LIMIT가 있으면 상위 데이터 몇 개만 삭제한다. DELETE는 트랜잭션 로그를 기록하는 작업 떄문에 삭제가 오래 걸린다.
DELETE FROM testTbl WHERE name = 'cha';-
TRUNCATE TABLE 테이블이름
TRUNCATE는 테이블은 남기고 안에 데이터만 삭제한다, DDL이므로 트랜잭션이 발생하지 않아서 속도가 빠르다. 하지만 삭제된 데이터를 복구할 수 없다. DELETE문은 ROLLBACK이 가능하다. -
INSERT (IGNORE) INTO : INSERT과정에서 문제가 생긴 행은 제외하고 나머지 INSERT 수행
-
ON DUPLICATE KEY UPDATE : pk가 중복되면 update문이 실행되고, 중복되지 않으면 일반 insert문으로 실행된다.
INSERT INTO testTable VALUES ('BBK', '비비코', '미국')
ON DUPLICATE KEY UPDATE name='비비코', addr='미국';- 테이블 삭제 : 외래키의 기준테이블인 경우 외래키 테이블을 먼저 삭제해야한다.
DROP TABLE 테이블이름;
여러 테이블을 동시에 삭제하려면
DROP TABLE 테이블1, 테이블2, 테이블3; - 테이블 수정
1. 열의 추가
ALTER TABLE 테이블이름
ADD 컬럼명 속성
2. 열의 삭제
ALTER TABLE 테이블이름
DROP 컬럼명
3. 컬럼명 변경
ALTER TABLE 테이블명
RENAME COLUMN address to address2;
4. 컬럼명과 데이터 형식을 같이 수정할 때는 change (잘 사용안한다)
ALTER TABLE 테이블이름
CHANGE 현재컬럼명 새로운컬럼명 VARCHAR(20) NULL;
5. 컬럼의 데이터 형식을 수정
ALTER TABLE 테이블이름
MODIFY 컬럼명 VARCHAR(20) NULL;
4. 열의 제약조건 추가 및 삭제
ALTER TABLE 테이블이름
DROP PRIMARY KEY;
5. 테이블 명 변경
rename table 원래이름 to 변경할 이름;
ALTER TABLE 테이블이름
DROP FOREIGN KEY 외래키이름;- 다중 Insert
INSERT INTO PEOPLE (first_name, last_name, age)
VALUES
("linda", "belcher", 45),
("Phillip", "Frond", 38),
("Calvin", "Fischoeder", 70);- DISTINCT : 중복제거
SELECT DISTINCT CONCAT(author_fname,' ', author_lname) FROM books;
SELECT DISTINCT author_fname, author_lname FROM books;
-> 둘 다 같은 결과를 반환한다.- ORDER BY : 정렬
SELECT * FROM books
ORDER BY author_lname;
SELECT * FROM books
ORDER BY author_lname DESC;
SELECT * FROM books
ORDER BY released_year;
-------------------------
SELECT book_id, author_fname, author_lname, pages
FROM books ORDER BY 2 desc; -> author_fname 기준으로 정렬
SELECT book_id, author_fname, author_lname, pages
FROM books ORDER BY author_lname, author_fname;
-> 첫번째 정렬기준 충족 후 두번째 정렬기준을 적용한다
select released_year as ry
from books order by ry asc; -> 별칭을 이렇게 사용할 수 있다.- like : '%', '_'
SELECT title, author_fname, author_lname, pages
FROM books
WHERE author_fname LIKE '%da%';
SELECT title, author_fname, author_lname, pages
FROM books
WHERE title LIKE '%:%';
SELECT * FROM books
WHERE author_fname LIKE '____';
-> _는 한개의 문자를 의미한다. author_fname가 네글자인 books 데이터를 찾는 것이다.
SELECT * FROM books
WHERE author_fname LIKE '_a_';
---------------------------------
-- To select books with '%' in their title:
SELECT * FROM books
WHERE title LIKE '%\%%';
-> %가 들어간 데이터를 찾고 싶을 때는 앞에 역슬래쉬를 붙여준다
-- To select books with an underscore '_' in title:
SELECT * FROM books
WHERE title LIKE '%\_%';
-> _가 들어간 데이터를 찾고 싶을 때는 앞에 역슬래쉬를 붙여준다- HAVING : GROUP BY로 얻은 그룹을 필터링하는데 사용
SELECT
title,
AVG(rating),
COUNT(rating) AS review_count
FROM full_reviews
GROUP BY title HAVING COUNT(rating) > 1;- SQL 모드 보는법
SELECT @@GLOBAL.sql_mode; - 글로벌 설정
SELECT @@SESSION.sql_mode; - 현재 세션을 설정- JPA에서 컬럼명 대문자로 넣기
jpa:
properties:
hibernate:
physical_naming_strategy: org.hibernate.boot.model.naming.PhysicalNamingStrategyStandardImpl- IFNULL()
select first_name, last_name, IFNULL(sum(amount), 0) from customers
left join orders on customers.id = customer_id
group by first_name, last_name;3. 데이터 형식
3-1 숫자 데이터 형식
- TINYINT, INT, SMALLINT :
UNSIGNED(부호 없는 정수를 지원) - DECIMAL(총자릿수, 소수점 뒤에오는 자릿수) : DECIMAL(5,2)가 최댓값이다. 즉 999.99가 최대이다.
CREATE TABLE CAT(
NAME VARCHAR(20) NOT NULL,
AGE TINYINT UNSIGNED NOT NULL,
PRICE DECIMAL(5,2) NOT NULL
);3-2 문자 데이터 형식
CHAR(N): 고정길이 문자형으로 자릿수가 고정되어 있다. CHAR(100)에 ABC를 저장해도 100자리를 모두 확보한 후 97자리는 공백이 추가된다. 삽입되는 데이터가 항상 같은 크기(고정된 길이)라면 CHAR가 효율적이다.
ex)
YES/NO flags: Y/N
zip code: 16953, 58971
VARCHAR(N): 가변길이 문자형으로 VARCHAR(100)는 3글자를 저장할 경우 3자리만 사용하게된다. 공간을 효율적으로 사용할 수 있지만 CHAR형식이 INSERT/UPDATE 시에 더 좋은 성능을 발휘한다.
3-3 날짜와 시간 데이터 형식
- 필요한 것은 여기서 찾아본다.
https://dev.mysql.com/doc/refman/8.4/en/date-and-time-functions.htmlDATE: YYYY-MM-DD (날짜만 저장하고 시간은 저장하지 않는다)TIME: HH:MM:SSDATETIME: YYYY-MM-DD HH:MM:SS, 값의 범위가 1000년 ~ 9999년이다.TIMESTAMP: YYYY-MM-DD HH:MM:SS, 값의 범위가 1970년 ~ 2038년이다. 세계적으로 국가마다 다른 표준시간을 정해놓고 사용하는데, TIMESTAMP는 해당 국가의 표준시간에 맞춰 저장을 하게 도와준다.
CURDATE(): 현재 날짜CURRENT_TIME() = CURTIME(): 현재 시간CURRENT_TIMESTAMP() = NOW(): 현재 날짜와 시간
-----------------------------------------------
CREATE TABLE people (
name VARCHAR(100),
birthdate DATE,
birthtime TIME,
birthdt DATETIME
);
INSERT INTO people (name, birthdate, birthtime, birthdt)
VALUES ('Hazel', CURDATE(), CURTIME(), NOW());3-3-1 date 함수
DAY(): 날짜 중 일 가져오기
SELECT DAY(birthdate) FROM people;DAYOFWEEK(): 요일 가져오기(일요일=1, 월요일=2 .. 토요일=7)
3-3-2 날짜 형식 변경
date_format(date, format): 날짜 표현 형식변경time_format(time, format)datediff(날짜1, 날짜2), timediff(시간1, 시간2): 날짜1 - 날짜2(또는 시간)를 하고 일수(시간)를 반환한다date_add, date_sub: 날짜를 더하거나 뺀다. (interval을 사용한다)
SELECT birthdate, DATE_FORMAT(birthdate, '%a %b %D') FROM people;
SELECT birthdt, TIME_FORMAT(birthdt, '%H:%i') FROM people;
select birthdate, datediff(curdate(), birthdate) from people;
select date_add(curdate(), interval 1 year);
select NOW() - interval 18 YEAR;current_timestamp, on update current_timestamp: TIMESTAMP, DATETIME 타입 둘 다 적용이 가능하다.
CREATE TABLE captions2 (
text VARCHAR(150),
created_at TIMESTAMP default CURRENT_TIMESTAMP,
updated_at TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
);- YEAR(), MONTH(), HOUR()
SELECT * FROM PEOPLE WHERE YEAR(birthdate) < 2000;
SELECT * FROM PEOPLE WHERE HOUR(birthdate) < 11 ;- 기타 데이터 형식
- GEOMETRY : 점, 선, 다각형 등 공간 데이터를 저장
- JOSN
4. 변수 사용
- SET @변수이름 = 값;
SELECT @변수이름;
SET @TESTVAR = 5;
SELECT @TESTVAR;
SET @TESTVAR2 = '가수 이름 ==> `;- LIMIT에는 원칙적으로 변수를 사용할 수 없으나 PREPARE, EXECUTE문을 사용해서 변수를 사용할 수 있다.
- PREPARE문은 쿼리이름에 쿼리문만 준비해놓고 실행하지는 않는다
SET @TESTVAR = 5;
PREPARE 쿼리이름 FROM '쿼리문';
PREPARE TESTQUERY FROM 'SELECT name, height FROM USERTBL
ORDER BY height LIMIT ?;
EXECUTE TESTQUERY USING @TESTVAR;5. 피벗 테이블
6. JSON 데이터
- 테이블 데이터를 JSON으로 출력하는 방법
SELECT JSON_OBJECT('name', name, 'age', age) AS person_json FROM usertbl;
+-------------------------+
| person_json |
+-------------------------+
| {"name": "John", "age": 30} |
+-------------------------+7. 문자열 함수
- concat(), concat_ws() : 문자열 결합
select concat(author_fname, ' ' ,author_lname) as author_name from books;
select concat_ws('!', author_fname ,author_lname) as author_name from books
-> 각각의 값뒤에 !가 붙으면서 문자열이 결합된다- substr() : substring() 와 동일한 기능
SELECT SUBSTRING('Hello World', 1, 4); -> Hell
SELECT SUBSTRING('Hello World', 7);
SELECT SUBSTRING('Hello World', -3);
SELECT SUBSTRING(title, 1, 10) AS 'short title' FROM books;
SELECT SUBSTR(title, 1, 10) AS 'short title' FROM books;- concat()과 substr() 결합
SELECT CONCAT
(
SUBSTRING(title, 1, 10),
'...'
) AS 'short title'
FROM books;
----------------------------------------
SELECT CONCAT
(
SUBSTRING(author_fname, 1, 1),
'.',
SUBSTRING(author_lname, 1, 1),
'.'
) AS 'short author_Name'
FROM books; -> J.L.- replace : 문자열 대체 , 실제 테이블의 데이터를 수정하는 것이 아니다.
SELECT REPLACE('Hello World', 'Hell', '%$#@'); -> %$#@o World
SELECT REPLACE('Hello World', 'l', '7');
SELECT REPLACE('Hello World', 'o', '0');
SELECT REPLACE('HellO World', 'o', '*');
SELECT
REPLACE('cheese bread coffee milk', ' ', ' and ');
SELECT REPLACE(title, 'e ', '3') FROM books;
SELECT REPLACE(title, ' ', '-') FROM books;- reverse() : 문자열 뒤집기
SELECT REVERSE('Hello World');
SELECT REVERSE('meow meow');
SELECT REVERSE(author_fname) FROM books;
SELECT CONCAT('woof', REVERSE('woof'));
SELECT CONCAT(author_fname, REVERSE(author_fname)) FROM books;- char_length(), length() : char_length는 글자수, length()는 바이트 기준
SELECT CHAR_LENGTH('Hello World');
SELECT CHAR_LENGTH(title) as length, title FROM books;
SELECT author_lname, CHAR_LENGTH(author_lname) AS 'length' FROM books;
SELECT CONCAT(author_lname, ' is ', CHAR_LENGTH(author_lname), ' characters long') FROM books;- UPPER, LOWER : 대문자, 소문자로 변경
SELECT UPPER('Hello World');
SELECT LOWER('Hello World');
SELECT UPPER(title) FROM books;
SELECT CONCAT('MY FAVORITE BOOK IS ', UPPER(title)) FROM books;
SELECT CONCAT('MY FAVORITE BOOK IS ', LOWER(title)) FROM books;8. 집계함수
- count
SELECT COUNT(*) FROM books;
SELECT COUNT(author_lname) FROM books;
SELECT COUNT(DISTINCT author_lname) FROM books;- GROUP BY : 동일한 데이터를 요약 또는 집계해서 하나의 열로 만든다. 그룹을 기준으로 데이터를 가져온다.
(~별)
SELECT author_fname, author_lname, COUNT(*)
FROM books
GROUP BY author_lname, author_fname;
--------------------------------------
SELECT CONCAT(author_fname, ' ', author_lname) AS author, COUNT(*)
FROM books
GROUP BY author;
author별 COUNT(*)
-----------------------------------------
select released_year, avg(stock_quantity) from books GROUP BY released_year;
released_year별 avg(stock_quantity)- MIN, MAX : 최솟값, 최댓값
SELECT MAX(pages) FROM books;
SELECT MIN(author_lname) FROM books;- 서브쿼리
SELECT title, pages FROM books
WHERE pages = (SELECT MAX(pages) FROM books);
SELECT title, released_year FROM books
WHERE released_year = (SELECT MIN(released_year) FROM books);- SUM()
select author_fname, author_lname, sum(pages)
from books
GROUP BY author_fname, author_lname;- AVG()
select released_year, avg(stock_quantity)
from books
GROUP BY released_year;9. 논리연산자
!=
SELECT * FROM books
WHERE released_year != 2017;LIKE,NOT LIKE
SELECT * FROM books
WHERE title NOT LIKE '%e%';
제목에 e가 들어가 있지 않은 책 검색AND: 모든 조건을 만족하는 결과를 출력
SELECT title, author_lname, released_year FROM books
WHERE released_year > 2010
AND author_lname = 'Eggers'
AND title LIKE '%novel%';OR: 조건들 중 하나만 만족해도 출력
IN, NOT IN: 조건이 많을 때는 IN을 사용하는 것이 효율적
SELECT title, author_lname, released_year FROM books
WHERE author_lname='Eggers' OR
released_year > 2010;
SELECT title, pages FROM books
WHERE pages < 200
OR title LIKE '%stories%';
-------------------------------
<IN>
SELECT title, author_lname FROM books
WHERE author_lname IN ('Carver', 'Lahiri', 'Smith');
SELECT * FROM BOOKS WHERE released_year NOT IN('2001', '2004', '2010');
SELECT title, released_year FROM books
WHERE released_year >= 2000
AND released_year % 2 = 1;
BETWEEN, NOT BETWEEN: 범위의 양쪽 끝이 포함된다
select * from books where released_year >= 2004 and released_year <= 2015;
select * from books where released_year BETWEEN 2004 and 2015;
select * from books where released_year NOT BETWEEN 2004 and 2015;시간, 날짜 비교하기
SELECT * FROM PEOPLE WHERE YEAR(birthdate) < 2000;
SELECT * FROM PEOPLE WHERE HOUR(birthdate) < 11 ;
SELECT * FROM people WHERE HOUR(birthtime)
BETWEEN 12 AND 16;
SELECT * FROM people WHERE birthtime
BETWEEN CAST('12:00:00' AS TIME)
AND CAST('16:00:00' AS TIME);CASE WHEN THEN ELSE END AS
SELECT title, released_year,
CASE
WHEN released_year >= 2000 THEN 'modern lit'
ELSE '20th century lit'
END AS genre
FROM books;
--------------------------------------------
SELECT
title,
stock_quantity,
CASE
WHEN stock_quantity <= 40 THEN '*'
WHEN stock_quantity <= 70 THEN '**'
WHEN stock_quantity <= 100 THEN '***'
WHEN stock_quantity <= 140 THEN '****'
ELSE '*****'
END AS stock
FROM
books;
---------------------------------
SELECT author_fname, author_lname,
CASE
WHEN COUNT(*) = 1 THEN '1 book'
ELSE CONCAT(COUNT(*), ' books')
END AS count
FROM books
WHERE author_lname IS NOT NULL
GROUP BY author_fname, author_lname;IS NULL, IS NOT NULL: NULL인 것과 NULL이 아닌 것을 선택
DELETE FROM BOOKS WHERE title IS NULL;10. 윈도우 함수
- GROUP BY와 기능이 유사하지만 GROUP BY처럼 그룹별로 하나의 행으로 묶지 않고, 전체 행을 가져온 후, 값을 계산해서 해당 값을 각 행별로 보여준다.
OVER()
select department, avg(salary) from employees GROUP BY department;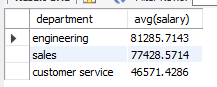
select department, avg(salary) over() from employees;
-> 전체 employees의 평균값이 전체 행에 같이 나온다.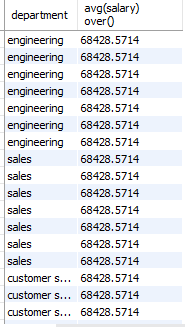
2. OVER(PARTITION BY ) : GROUP BY와 같은 기능
select department, avg(salary) over(PARTITION BY department)
from employees;
-> 부서별로 묶는다. 단 전체 행을 출력한다.
select emp_no, department, salary,
avg(salary) OVER(PARTITION BY department) AS department_avg,
avg(salary) OVER() AS company_avg from employees;
-> 이렇게 개인임금, 부서별 평균임금과 회사의 평균임금을 비교가능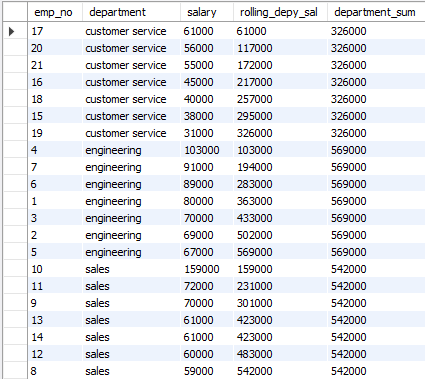
OVER(PARTITION BY ' ' ORDER BY ' ')
select emp_no, department, salary,
SUM(salary) over(PARTITION BY department ORDER BY salary DESC) AS rolling_depy_sal,
SUM(salary) over(PARTITION BY department) AS department_sum
FROM employees;SUM(salary)과 같은 집계연산을 할 때, PARTITION BY는 윈도우별로 값을 계산하는데 ORDER BY를 추가하면 차례대로 연산한 값을 출력한다. (롤링합계)
RANK()를 사용하여 순위를 계산할 수도 있다.
select emp_no, department, salary,
RANK() OVER(PARTITION BY department ORDER BY salary DESC) AS department_sal_rank,
RANK() OVER(ORDER BY salary DESC) AS overall_sal_rank
FROM employees ORDER BY emp_no;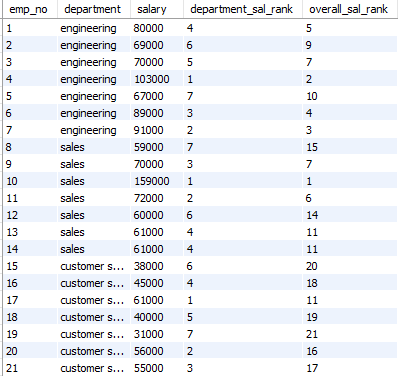
4. ROW_NUMBER(), DENSE_RANK() : RANK()는 순위를 매기기 때문에 동점이 있으면 다음 숫자로 넘어간다. (4등에서 동점이라면 5등없이 6등으로 넘어간다).
하지만 ROW_NUMBER()는 행의 개수가 몇개인지 체크한다. DENSE_RANK()는 중복되는 점수가 있더라도 순위를 건너띄지 않는다.
SELECT emp_no, department, salary,
RANK() OVER(PARTITION BY department ORDER BY salary DESC) AS department_sal_rank,
RANK() OVER(ORDER BY salary DESC) overall_sal_rank,
DENSE_RANK() OVER(PARTITION BY department ORDER BY salary DESC) AS overall_dense_rank,
ROW_NUMBER() OVER(PARTITION BY department ORDER BY salary DESC) as dept_row_number
FROM employees ORDER BY overall_sal_rank;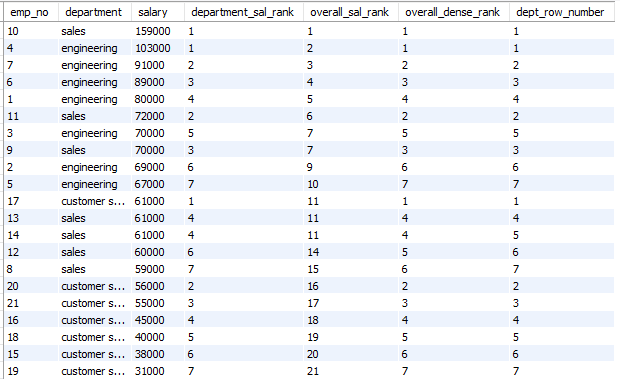
NTILE(4): 분위를 4로 나눈다. 분위가 낮을수록 값이 높다.
SELECT emp_no, department, salary,
NTILE(4) OVER(ORDER BY salary DESC) AS salary_qurt,
NTILE(4) OVER(PARTITION BY department) AS dept_salary_qurt
FROM employees;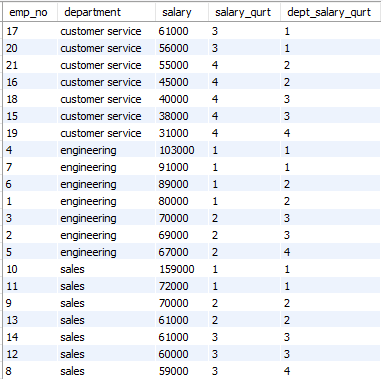
6. FIRST_VALUE() : 첫번째 값을 가져온다. 전체 사원중 급여가 가장 높은 사원의 번호, 부서별로 급여가 가장 높은 사원의 번호
SELECT emp_no, department, salary,
FIRST_VALUE(emp_no) OVER(ORDER BY salary DESC),
FIRST_VALUE(emp_no) OVER(PARTITION BY department ORDER BY salary DESC)
FROM employees;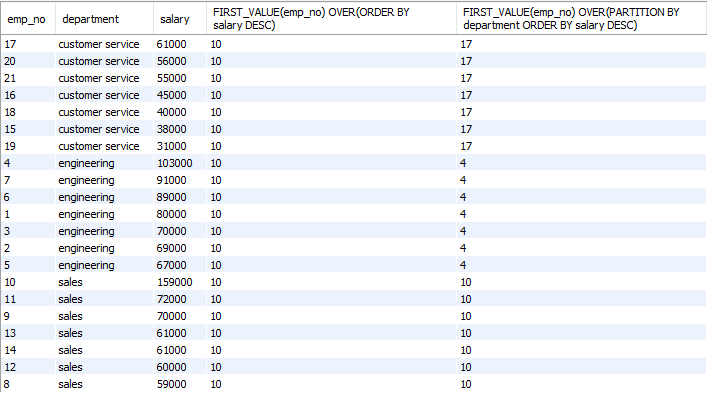
LAG(): 이전 행의 값을 가져온다. 이전 행과의 급여차이를 계산한다.
SELECT emp_no, department, salary,
salary - LAG(salary) OVER(PARTITION BY department ORDER BY salary DESC)
FROM employees;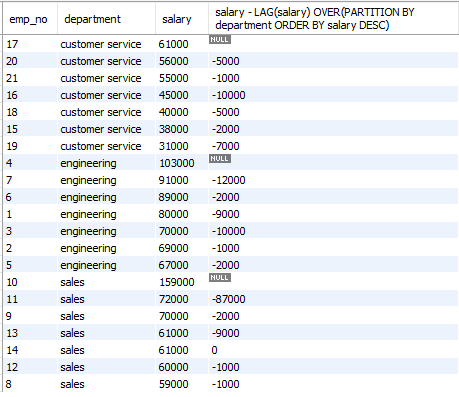
8. LEAD() : 다음 행의 값을 가져온다. 다음 행과의 차이를 계산한다.
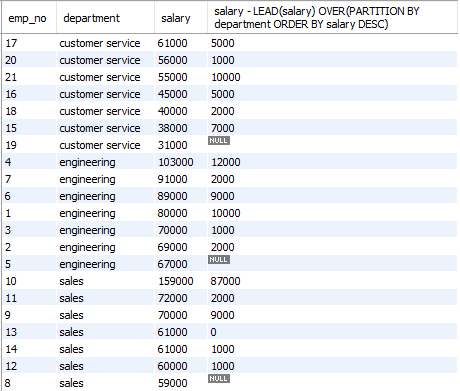
11. 제약조건
- NOT NULL
- UNIQUE
CREATE TABLE companies(
name VARCHAR(20) NOT NULL ,
address VARCHAR(20) NOT NULL
COMSTRAINT companies_name_address UNIQUE(name, address)
name이 같을 수 있고, address도 같을 수 있지만 ame, address 둘 다 일치해서는 안된다.
(다중열 제약조건)
);- UNSIGNED
- CHECK
CREATE TABLE people (
age INT
COMSTRAINT age_over_0 CHECK(age > 0)
COMSTRAINT로 설정한 제약조건에 이름을 설정한다.