1. 프로세스
1-1 개념
- 프로세스는 할당받은 메모리에 올라가 실행중인 작업단위을 의미한다. 응용프로그램은 여러개의 프로세스로 구성될 수 있다.
일반적으로 하나의 프로그램은 하나 이상의 프로세스를 가지고 있고, 하나의 프로세스는 반드시 하나 이상의 스레드를 갖는다. 그리고 기본적으로 프로세스는 별도의 주소공간에서 실행되기 때문에 다른 프로세스의 메모리에 접근할 수 없다.
1-2 구조
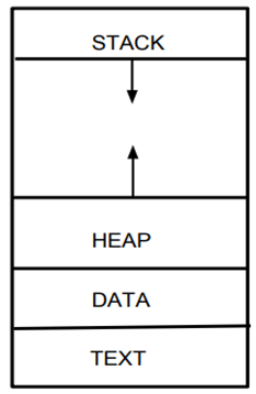
-
text/code : 코드 영역으로 프로그래머가 작성한 프로그램 함수들의 코드가 CPU가 해석 가능한 기계어 형태로 저장되어 있다.
-
data : 전역 변수나 static 변수가 모여있고, 컴파일 시점에 정의된 변수들의 메모리 공간이 할당된다. 할당된 메모리는 애플리케이션이 종료될 때 돌아온다.
-
Heap : 생성자, 인스턴스와 같은 동적으로 할당되는 데이터들을 위한 공간이다. JAVA의 경우 개발자가 메모리를 직접 해제할 수 없는 언어이기때문에 GC가 Heap영역에서 사용하지 않는 인스턴스를 제거하여 메모리를 관리한다.
-
Stack : 지역 변수, 매개변수 등 함수 호출시 필요한 정보들이 저장된다. 함수를 호출할 때 메모리가 할당되며, 함수의 실행이 종료되면 메모리를 수거한다.
SP라는 스택의 최상단을 가리키는 레지스터를 사용해서 위치를 추적하고 관리한다.
Stack과 Heap영역은 프로세스가 실행되는 동안 크기가 늘어났다 줄어들기도 하는 동적 영역이다.
1-3 프로세스 스케줄링 시스템
1-3-1 배치 처리 시스템
- 한번에 등록된 여러 프로그램들을 실행 요청 순서에 따라 순차적으로 실행하는 방식이다. 모든 작업이 종료된 후에 결과를 얻을 수 있기 때문에 사용자입장에서 대기시간이 길다
1-3-2 시분할 시스템
- 여러 사용자가 하나의 컴퓨터를 동시에 사용할 수 있게 하는 시스템으로 CPU의 사용시간을 여러 사용자들에게 균등하게 할당한다.
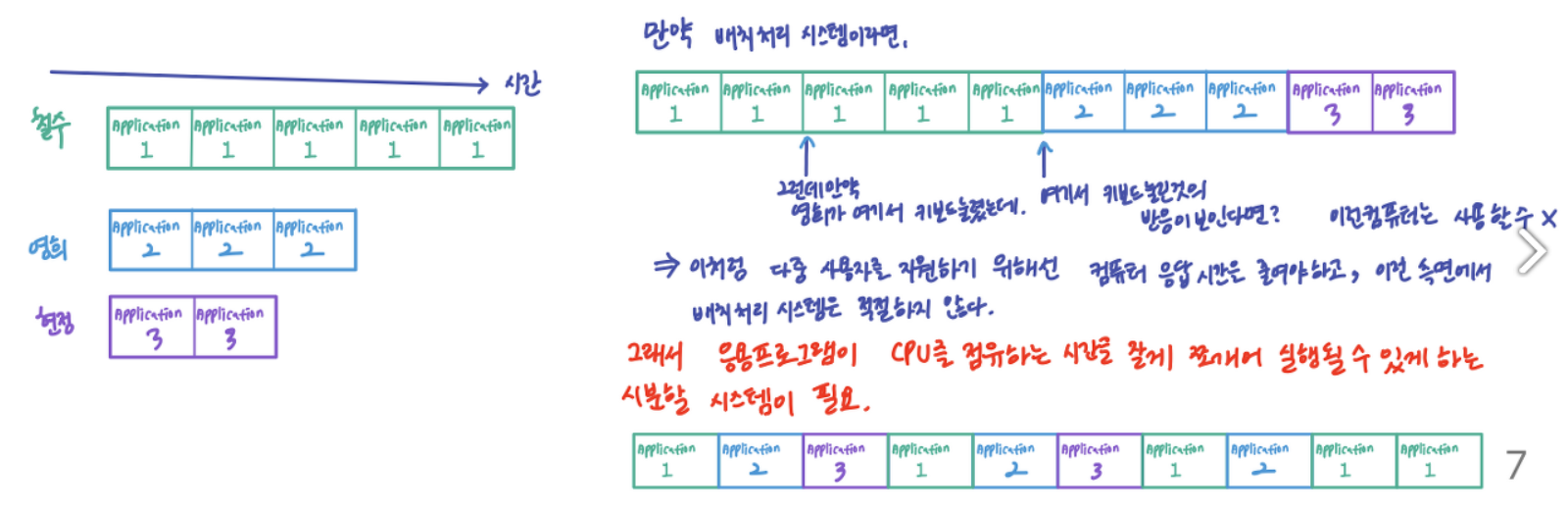
1-3-3 멀티 테스킹
- 단일 사용자가 여러 프로그램을 동시에 실행하는 시스템으로 시분할 시스템과 기본개념은 동일
1-3-4 멀티 프로그래밍
- 여러 CPU에 하나의 프로그램을 병렬로 실행해서 실행속도를 극대화시키는 시스템이다.
1-4 PCB
- PCB는
프로세스 스케줄링을 위해 프로세스에 관한 모든 정보 저장하는 임시 저장소이다.
프로세스를컨텍스트 스위칭할때 기존 프로세스의 상태를 어딘가에 저장해 둬야 다음에 똑같은 작업을 이어서 할 수 있을 것이고, 새로 해야 할 작업의 상태 또한 알아야 어디서부터 다시 작업을 시작할지 결정할 수 있을 것이다. 프로세스가 생성되면 커널메모리에 PCB가 생성되어 저장되며 프로세스가 종료되면 PCB가 지워진다
메인 메모리는 프로세스의 실행과 데이터 저장을 위한 주 기억 장치이고, 커널 메모리는 운영 체제가 실행되고 관리되는 영역으로서 메인 메모리 내에 할당되는 일부 영역입니다.
- PCB에는 다음의 정보들이 들어있다.
-
포인터 (Pointer) : 프로세스의 현재 위치를 저장하는 포인터 정보
-
프로세스 상태 (Process state) : 프로세스의 각 상태 - 생성(New), 준비(Ready), 실행(Running), 대기(Waiting), 종료(Terminated) 를 저장
-
프로세스 아이디 (Process ID, PID) : 프로세스 식별자를 지정하는 고유한 ID
-
프로그램 카운터 (Program counter) : 프로세스가 다음에 실행할 명령어의 주소
-
레지스터 (Register) : 누산기, 베이스, 레지스터 및 범용 레지스터를 포함하는 CPU 레지스터에 있는 정보
-
메모리 제한 (Memory Limits) : 운영체제에서 사용하는 메모리 관리 시스템에 대한 정보
-
열린 파일 목록 (List of open file) : 프로세스를 위해 열린 파일 목록
1-5 프로세스 간 통신방법
-
프로세스는 독립된 실행객체로 다른 프로세스의 영향을 받지 않는다. 따라서 다른 프로세스와 통신하기 위해서는 IPC기법이 필요한데 파일사용을 제외한 나머지 방식은 모두 커널공간을 사용한다.
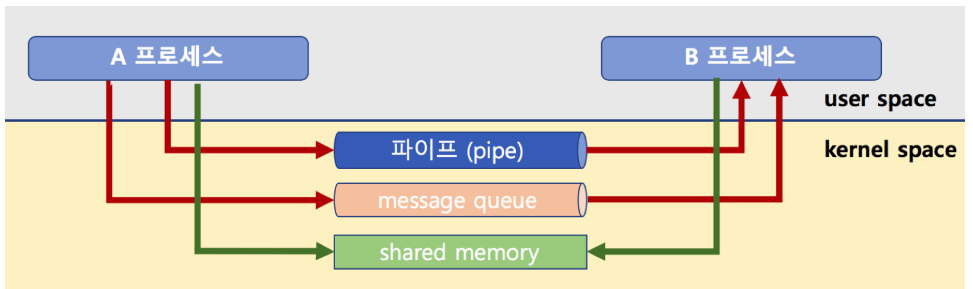
-
커널 : 프로세스는 사용자 영역과 커널 영역으로 나뉘는데, 커널 영역은 운영체제만 접근할 수 있는 공간입니다. 프로세스는 사용자 영역에서 실행되며, 커널 영역으로의 접근은 시스템 호출(system call)을 통해서만 가능합니다.
-
파일 사용: 파일을 공유해서 데이터를 주고 받는 방식이다. 프로세스 간에 주고받는 데이터를 파일로 저장하거나, 로그 파일을 공유하는데 유용하게 사용된다.
단순한 방법이지만, 여러 프로세스가 파일을 동시에 열어서 수정할 경우 데이터 불일치 문제가 발생할 수 있다. 그리고 통신이 필요할 때마다 파일을 읽고 커널정보가 변경될 때마다 파일을 업데이트 해야한다는 단점이 있다. -
Message Queue: 커널 내 메시지 큐를 이용해서 데이터를 주고받는 방식이다. 각 프로세스는 메시지를 큐에 보내고, 다른 프로세스는 해당 큐에서 메시지를 받아 처리한다. 각 메시지를 독립적으로 처리되고, 전송하는 데이터에 식별자나 우선순위를 붙임으로써 데이터를 쉽게 다룰 수 있습니다. -
Shared Memory: 공유 메모리(Shared Memory)는 두 개 이상의 프로세스가 하나의 메모리 영역을 공유하는 방식이다. 프로세스가 공유 메모리 할당을 커널에 요청하면 커널은 해당 프로세스에게 시스템메모리 공간을 할당해준다. 다른 프로세스들은 해당 메모리영역에 접근할 수 있다. 빠른 속도로 데이터를 주고 받을 수 있으나, 프로세스 간 데이터 동기화 및 보호에 대한 처리가 필요하다. -
Pipe: 파이프는 두 프로세스 사이에서 데이터를 주고받는 방법 중 하나이다. 파이프의 동작모드에는 읽기모드와 쓰기모드가 있다. 읽기 모드로 열린 파이프에는 데이터가 쓰여질 때까지 대기하고, 데이터가 쓰여지면 해당 데이터를 읽는다. 쓰기 모드로 열린 파이프에는 데이터를 쓴다. 하나의 파이프만 사용하면 교착상태가 발생할 수 있기 때문에, 읽기전용 파이프와 쓰기전용 파이프를 따로 만들어서 사용한다. -
Signal: 시그널(Signal)은 프로세스에게 이벤트(Interrupt)가 발생했음을 알리는 방법이다. 시그널은 다른 프로세스로 데이터를 전달하기 위한 목적으로 사용될 수도 있다.
비동기적인 방식이기 때문에 신호를 받는 프로세스가 신호를 처리하지 않으면 신호의 우선순위나 반복수신 문제로 프로세스가 무한 대기 상태에 빠질 수 있다. -
Semaphore: 프로세스 간에 공유하는 카운팅 세마포어나 이진 세마포어를 이용해서 상호 배제 기능을 구현하는 방식이다. -
Socket: 인터넷에서 데이터를 주고 받는 데 사용하는 소켓을 이용해서 프로세스 간 통신을 구현하는 방식이다. 다른 IPC 기법에 비해 느리지만, 여러 대의 컴퓨터에서 실행 중인 프로세스 간에도 통신이 가능하다.
소켓을 사용하기 위해서는 생성해주고, 이름을 지정해주어야 한다. 또한 domain과 type, Protocol을 지정해 주어야 한다.. 서버 단에서는 bind, listen, accept를 해주어 소켓 연결을 위한 준비를 해주어야 하고 , 클라이언트 단에서는 connect를 통해 서버에 요청하며, 연결이 수립 된 이후에는 Socket을 send함으로써 데이터를 주고 받게 된다. 연결이 끝난 후에는 반드시 Socket 을 close()해주어야 한다.
-
2. 쓰레드
2-1 개념
- 쓰레드는 하나의 프로세스 내 작업흐름의 단위를 의미한다

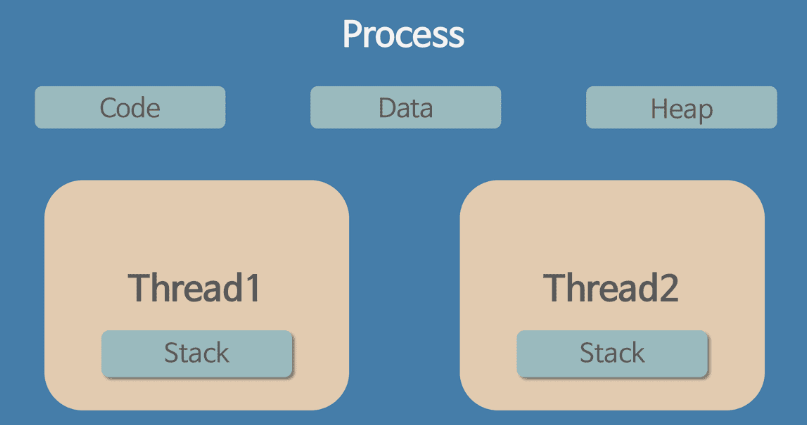
- 프로세스의 4가지 메모리 영역(Code, Data, Heap, Stack) 중 스레드는 Stack만 할당받아 복사하고 Code, Data, Heap은 프로세스내의 다른 스레드들과 공유된다.
독립적인 스택을 가졌다는 것은 독립적인 함수 호출이 가능하다 라는 의미이다. 그리고 독립적인 함수 호출이 가능하다는 것은 독립적인 실행 흐름이 추가된다는 말이다.
2-2 멀티 쓰레드의 장단점
- 장점
- 사용자에 대한 응답성 향상
- 자원을 공유하는데에 효율성 향상
- 작업이 분리되어 코드가 간결해짐
- 단점
- 하나의 쓰레드만 문제가 있어도 전체 프로세스가 영향을 받음
- 스레드를 많이 생성하면, Context Switching이 많이 일어나, 성능 저하
- 동기화 코드를 적절히 추가하지 않으면 동기화 문제가 발생할 수 있다.
3. 프로세스와 쓰레드 동시실행
- 컴퓨터 내부적으로 프로세스와 스레드를 동시에 처리하는 일을 멀티 태스킹이라고 한다. 멀티태스킹의 원리를 알아본다
CPU에는코어와 쓰레드라는 용어로 스펙을 설명한다. 여기서 코어는 명령어를 메모리에서 뽑아 해석하고 실행하는 반도체 유닛을 말한다.
4코어 8쓰레드라면 물리적 코어 하나가 스레드 두 개 이상을 동시에 실행 가능하다는 의미가 된다. 즉, 운영체제가 8개의 작업을 동시에 처리할 수 있다는 뜻이다. 여기서 말한 CUP의 쓰레드는 하드웨어적인 쓰레드를 말한다.
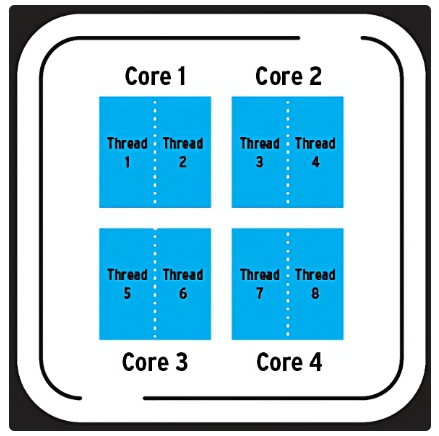
8개의 작업을 동시에 처리할 수 있지만 수십개의 프로그램을 켜놓아도 문제없이 처리가 가능하다. 이것이 가능한 이유는 병렬성과 동시성 덕분이다.
-
병렬성 : 여러개의 코어에 맞춰 여러개의 프로세스, 스레드를 돌려 병렬로 작업들을 동시 수행하는 것을 말한다. 말 그대로 코어 개수가 늘어나면서 한번에 수행할 수 있는 작업 개수가 늘어나는 것이다.
-
동시성 : 여러개의 작업을 동시에 실행하는 것인데 실제로 동시에 실행되는 것이 아닌, 작업들을 아주 잘게 나누어 아주 조금씩만 작업을 수행하고 다음 작업으로 넘어가는 식으로 동작된다. 이때 다음 작업으로 넘어가는 것을
Context Switching이라고 한다. 코어는 한 번에 하나의 프로세스만 실행할 수 있으므로, 멀티 코어인 경우 여러 개의 프로세스를 번갈아가며 실행하여 CPU 활용률을 높이는 것이다. 이러한 컨텍스트 스위칭이 일어날 때 다음번 프로세스는스케줄러가 결정하게 된다. 즉, 컨텍스트 스위칭을 하는 주체는 스케줄러이다.
진짜 동시에 수행하는 것이 아닌데 동시성이 필요한 이유 CPU에 수십개의 코어를 달 수 없다는 점과 여러 개의 작업 중 짧은 시간이 걸리는 것과 긴 시간이 걸리는 작업이 섞여 있을 때 짧은 시간 작업의 대기시간 문제를 고려하여 동시성 개념을 채택한 것이다. -
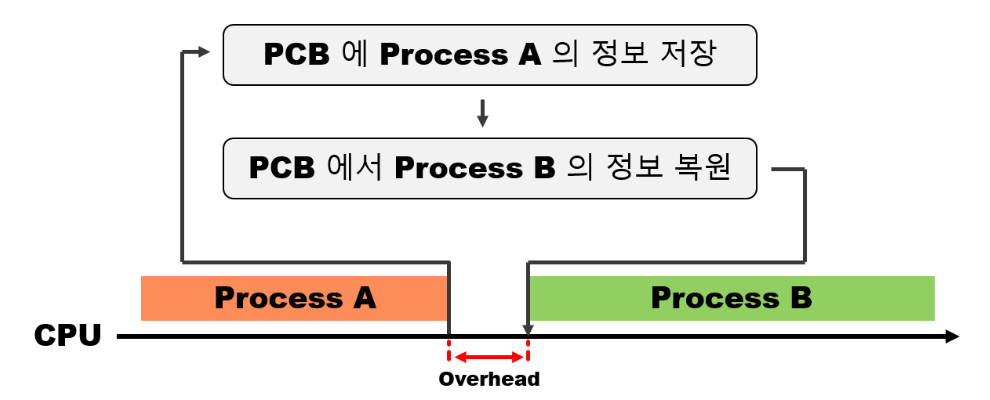
Context Switching Overhead
실행되는 프로세스의 변경 과정에서 프로세스의 상태, 레지스터 값 등이 저장되고 불러오는 등의 작업이 수행하기 때문에 비용이 발생하게 되는데 이를 Context Switching Overhead라고 한다. 컨텍스트 스위칭 과정에서 PCB를 저장하고 복원하는데 비용이 발생하며, 프로세스 자체가 교체되는 것이니 CPU의 캐시 메모리에 저장된 데이터가 무효화가 된다.
4. 동기화 기법
-
동기화 문제는 멀티스레드 환경에서 공유 자원에 접근하고 조작할때 발생할 수 있는 문제들을 의미한다.
-
공유자원에 접근할 때, 데이터의 정확성을 보장하고 프로세스나 스레드 간의 안정적인 작업수행을 위해 동기화를 해야하고 동기화(Synchronization) 기법을 사용해야한다. 동기화란 작업의 순서나 시점을 맞추는 것을 말한다.
-
임계영역: 공유 자원에 대한 접근을 보호하기 위한 코드 영역으로 임계영역 안에 있는 공유자원을 임계자원이라고 한다. 여러 개의 프로세스나 스레드가 동시에 접근하면 경쟁상태 등의 문제가 발생할 수 있다. 동기화 문제를 해결하기 위한 조건은 다음과 같다.-
상호배제 : 어떤 프로세스가 임계영역에 들어가 있으면, 다른 프로세스는 그들의 임계영역에 접근할 수 없어야 한다.
-
진행 : 임계 영역에 들어간 프로세스가 없는 상황에서 영역에 들어가려고 하는 프로세스가 여러 개라면 어떤 것이 들어갈지 결정해주어야 한다.
-
한정 대기 : 임계영역에 들어가려고 하는 프로세스의 수에 제한이 있어야 하며, 어떤 프로세스가 임계영역에 들어가려고 기다리고 있는 시간이 유한해야 한다.
-
-
동기화 문제를 해결하기 위한 기법
-
뮤텍스: 뮤텍스는 임계영역에 대한 상호배제를 위해 lock과 unlock 두 가지 기본 연산을 제공한다. 스레드는 lock 연산을 통해 뮤텍스를 획득하고, 임계영역에 진입하여 임계자원을 사용한 뒤 unlock 연산을 통해 뮤텍스를 반환한다. 뮤텍스는 오직 하나의 스레드만이 소유할 수 있으며, 다른 스레드가 뮤텍스를 획득하려 할 때는 대기한다. -
세마포어(이진, 카운팅 세마포어) : 뮤텍스와 달리 여러 개의 스레드가 동시에 접근할 수 있는 동기화 기법입니다. 세마포어는 정수형 변수와 wait, signal 두 가지 기본 연산을 제공합니다. 세마포어 변수의 값은 몇 개의 스레드가 동시에 접근할 수 있는지를 나타냅니다.wait 연산(P연산)은 임계자원에 접근을 시도할 때 세마포어 변수 값을 감소시키고, 세마포어 변수 값이 0보다 작아질 때는 접근을 시도한 프로세스나 스레드는 대기 상태로 전환합니다.signal 연산(V연산)은 세마포어 변수 값을 증가시키고, 대기 상태의 스레드 중 하나를 깨워 실행할 수 있도록 한다. -
모니터: 둘 이상의 스레드나 프로세스가 공유 자원에 안전하게 접근할 수 있도록 공유 자원을 숨기고 해당 접근에 대해 인터페이스만 제공한다.
-
4-1 DB에서 사용하는 동기화 기법
-
데이터베이스에서 동시성 제어를 위해 사용되는 기법으로는 락(Lock)이 있습니다. 락은 데이터베이스에서 여러 트랜잭션이 동시에 접근하는 것을 제어하여 데이터의 일관성을 보장하고 경쟁 상태를 방지하는데 사용됩니다.
-
뮤텍스와 락은 비슷한 개념으로 보일 수 있지만,
뮤텍스는 하나의 프로세스 내에서 스레드 간의 상호 배제를 위한 것이고,락은 여러 프로세스나 스레드가 접근하는 데이터베이스에서 데이터의 일관성과 동시 접근 제어를 위해 사용되는 것입니다.
Pessimistic Lock
실제로 데이터에 Lock 을 걸어서 정합성을 맞추는 방법입니다. exclusive lock 을 걸게되며 여러 프로세스나 스레드가 함께 사용하는 로우나 테이블 단위로 데이터에 락을 걸어서 다른 트랜잭션에서는 lock 이 해제되기전에 데이터를 가져갈 수 없게됩니다.
데드락이 걸릴 수 있기때문에 주의하여 사용하여야 합니다. 스프링 데이터 jpa에서는 락을 쉽게 사용할 수 있도록 @Lock 어노테이션을 제공합니다.
@Query("select s from Stock s where s.id = :id")
@Lock(value = LockModeType.PESSIMISTIC_WRITE)
Stock findByIdWithPessimisticId(@Param("id") Long id);Optimistic Lock
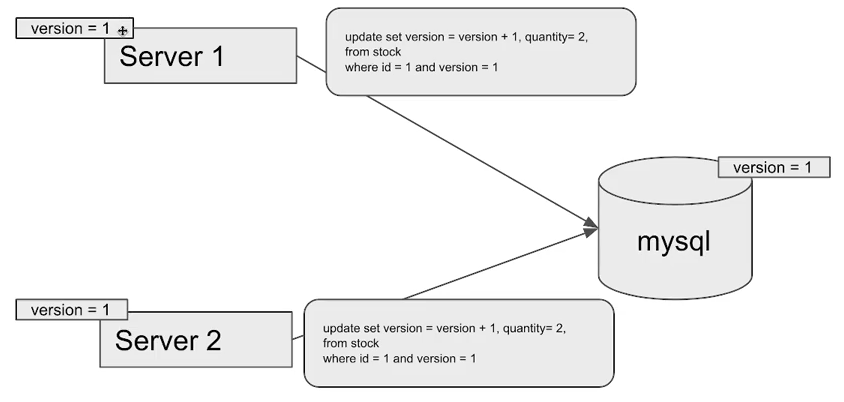
실제로 Lock 을 이용하지 않고 version이라는 속성을 확인하여 Entity의 변경사항을 감지하는 메커니즘 입니다. 업데이트에 실패했을 때, 재시도 로직을 개발자가 작성해주어야한다.
-
비즈니스 로직에서 데이터를 읽을 때, DB에서 select 쿼리를 사용하여 데이터를 가져옵니다. 이때, 해당 데이터의 버전(예: timestamp, version number 등)을 함께 가져옵니다.
-
update 쿼리를 날리기 전에, 다시 한 번 DB에서 select 쿼리를 사용하여 데이터를 읽어옵니다. 이때, 이전에 가져온 버전과 현재 데이터의 버전을 비교합니다. 버전이 같아서 업데이트를 하게 되면 데이터를 수정하고, 트랜잭션은 버전속성을 증가하는 업데이트 하게 됩니다.
-
이전에 수정사항이 생겨서 버전이 달라진 경우에는 application에서 다시 읽은후에 작업을 수행해야 합니다.
엔티티에 버전정보를 설정하기 위해 어노테이션과 멤버변수를 설정
@Version
private Long version;
-------------------------------------------
@Service
@RequiredArgsConstructor
public class OptimisticLockStockFacade {
private final OptimisticLockStockService optimisticLockStockService;
public void decrease(Long id, int quantity) throws InterruptedException {
while (true) {
try {
optimisticLockStockService.decrease(id, quantity);
break;
} catch (Exception e) {
Thread.sleep(50);
}
}
}
}Named Lock
이름을 가진 metadata locking 입니다. 이름을 가진 lock 을 획득한 후 해제할때까지 다른 세션은 이 lock 을 획득할 수 없도록 합니다. 주의할점으로는 transaction 이 종료될 때 lock 이 자동으로 해제되지 않습니다. 별도의 명령어로 해제를 수행해주거나 선점시간이 끝나야 해제됩니다.
4-2 동기화 문제
교착상태: 교착 상태는 여러 프로세스나 스레드가 서로 상대의 작업이 끝나기를 기다리는 상태로, 이 상태에서는 아무리 기다려도 자신의 작업을 진행할 수 없게 된다. 주로 여러 프로세스가 동일 자원을 사용하려고 할 때 발생한다
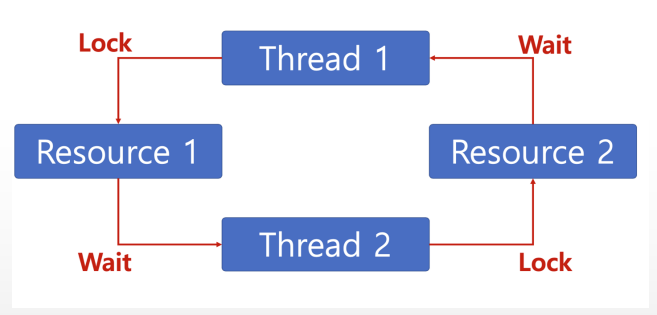
기아상태: 특정 프로세스의 우선순위가 낮아서 원하는 자원을 계속 할당 받지 못하는 상태를 말한다. 여러 프로세스가 부족한 자원을 사용하려고 할 때 발생한다
해결방법으로는 다음이 있다- 프로세스 우선순위를 수시로 변경해서, 각 프로세스가 높은 우선순위를 가질 기회주기
- 오래 기다린 프로세스의 우선순위를 높여주기
- 우선순위가 아닌, 요청 순서대로 처리하는 FIFO 기반 요청큐 사용하기
경쟁상태: 여러 스레드가 동시에 공유 자원에 접근하여 값을 변경하려고 할 때, 스레드 실행 순서나 타이밍 등에 따라 예상치 못한 결과가 발생하는 것을 말한다.
5. 스케줄러
- 한정된 메모리를 효율적으로 사용할 수 있도록 여러 프로세스나 스레드를 상황에 맞게 선택해서 실행하는 작업을 한다.
5-1 Scheduling Queues
- 스케줄러가 사용하는 프로세스들을 관리하는 데 사용되는 자료 구조이다.
- Job Queue(batch queue) : 시스템 안의 모든 프로세스의 집합이다.
- Ready Queue : 메모리에 로드되어 실행 대기 상태의 프로세스들이 들어가는 큐
- Device Queue : 입출력 작업은 외부 장치와의 상호작용을 필요하기 때문에, 장치별로 입출력 작업이 완료될 때까지 기다리는 프로세스들이 들어가있는 큐이다.
5-2 스케줄러의 종류
-
장기 스케줄러(Long-term scheduler): 어떤 프로세스를 메모리에 할당하여 ready queue로 보낼지 결정하는 역할을 한다. 메모리의 사용량과 디스크 I/O의 부하를 고려하여 로드할 프로세스의 수를 제어한다.
-
단기 스케줄러(Short-term scheduler): 준비 상태에 있는 프로세스 중에서 다음에 실행할 프로세스를 선택한다. 프로세스의 우선순위, CPU 사용 시간, 대기 시간 등을 고려하여 결정됩니다.
-
중기 스케줄러(Medium-term scheduler): 일부 프로세스를 보조기억장치에
스왑 아웃,스왑인하면서 메모리의 한계를 극복하고 실행 중인 프로세스를 유연하게 관리할 수 있게 합니다.
스왑아웃은 메모리의 사용량을 조절하기 위해 현재 실행 중인 프로세스 중 일부를 백업 저장하고, 실행 중인 상태를 중단하는 과정을 말한다.
스왑인은 스왑 영역에 저장된 프로세스 중 필요한 프로세스를 선택하여 메모리로 스왑인합니다. 스왑인된 프로세스는 메모리에 로드되고 실행을 재개하는 것을 말한다.
5-3 스케줄링 알고리즘
-
여러 프로세스 또는 쓰레드들의 CPU 시간 할당과 실행순서를 결정하기 위해 사용되는 알고리즘이다.
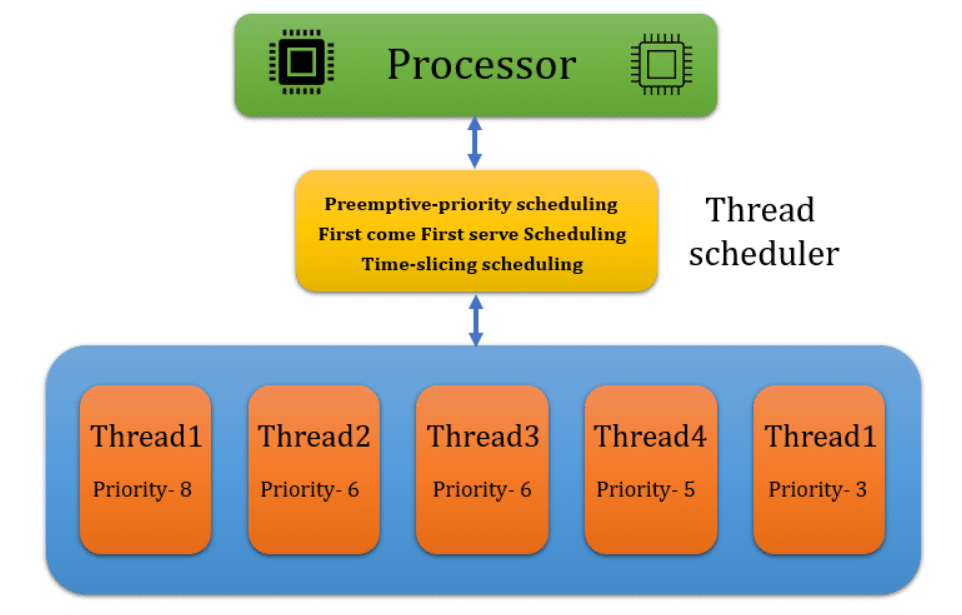
-
선점 스케줄링(Preemptive Scheduling)은 현재 실행중인 프로세스가 다른 프로세스에 의해 중단될 수 있는 스케줄링 방식으로 우선순위가 높은 프로세스가 먼저 실행된다. 프로세스의 응답시간이 빠른 대신 오버헤드와 기아상태가 발생할 수 있다. -
비선점 스케줄링(Non-preemptive Scheduling): 한 프로세스가 CPU 시간을 할당받으면 시간이 종료될 때까지 다른 프로세스는 CPU 점유가 불가능한 스케줄링 방식이다. 모든 프로세스를 공정하게 처리하며 오버헤드가 적은 대신 burst time이 긴 프로세스에 의해 burst time이 짧은 프로세스가 기다리는 현상이 생길 수 있다. burst time이란 프로세스가 작업을 처리하기 위해 CPU를 사용하는 시간을 말한다. -
FCFS(First Come First Served)
-
비선점형 스케줄링 방식
-
먼저 도착한 프로세스가 CPU를 먼저 할당 받는 방식, 큐를 이용해 쉽게 구현 가능하다.
-
콘보이 현상 발생 가능 : burst time 이 긴 프로세스가 먼저 도착해 다른 프로세스의 실행 시간이 전부 늦춰져 효율을 떨어뜨리는 현상
-
-
SJF(Shortest Job First)
-
비선점형 스케줄링 방식
-
burst time이 짧은 프로세스가 먼저 CPU를 할당받는 방법으로 먼저 도착했어도 burst time이 짧은 프로세스가 먼저 실행되어 Starvation 발생 가능하다.
-
우선순위 큐와 힙 자료구조 사용을 고려할 것
-
-
SRT(Shortest Remaining Time First)
-
선점형 스케줄링 방식
-
남은 burst time이 더 짧은 프로세스에 CPU를 할당하며 Starvation 발생 가능하다.
-
-
우선순위 스케줄링(Priority Scheduling)
-
선점과 비선점 두가지 방식에 모두 적용 가능 : 프로세스마다 우선순위를 미리 지정하는
정적 우선순위와 스케쥴러가 상황에 따라 우선순위를 동적으로 변경하는동적 우선순위방법이 있다. -
각 프로세스마다 우선순위를 지정하여 우선순위가 높은 프로세스에 CPU를 먼저 할당하는 방법이다. 기아 현상과 무기한 봉쇄가 발생할 수 있으며 먼저 도착한 프로세스가 나이를 계속 먹으며 우선순위가 올라가는 기법인 에이징 기법을 통해 해결할 수 있다.
-
-
라운드 로빈(RR, Round Robin)
-
선점형 스케줄링 방식
-
각 프로세스마다 균등하게 CPU 시간을 할당하는 방식(=시분할시스템)으로 주어진 시간내에 처리하지 못하면 큐의 가장 뒷부분으로 보내지고 다음 프로세스가 실행된다. 시간 할당량이 작을수록 다음 프로세스의 응답 시간이 빨라지지만, 너무 작은 할당량은 오버헤드를 높일 수 있다.
-
단, CPU 할당 시간(Time Quantum)이 길 경우, FCFS랑 같아진다.
-
-
다단계 큐(Multilevel Queue)
-
선점 방식
-
다단계 큐는 여러 개의 큐로 구성되며, 각 큐는 서로 다른 우선순위를 가지고 있다. 프로세스들은 우선순위에 따라 적절한 큐에 배치되고, 각 큐마다 프로세스의 요구사항에 맞는 적절한 스케줄링 알고리즘을 적용한다.
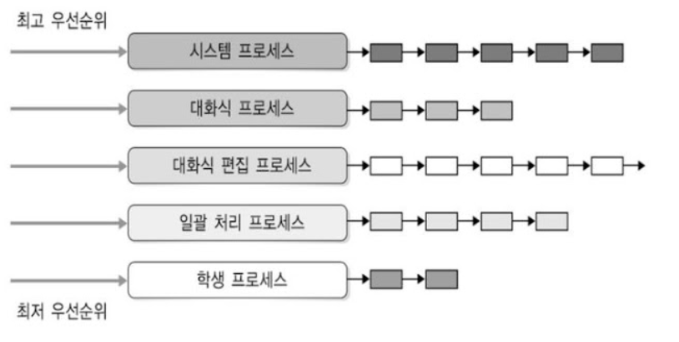
-
-
다단계 피드백 큐(Multilevel Feedback Queue)
-
다단계 피드백 큐는 시간할당량을 가지고 있는 여러 개의 큐로 구성되어있다. 하위 큐로 갈수록 시간 할당량은 늘어나 더 많은 실행기회를 가지게 되며, 각 큐는 서로 다른 우선순위를 가지고 있다. 초기에는 모든 프로세스가 가장 높은 우선순위를 가진 최상위 큐에 배치됩니다. 상황에 따라 우선순위가 높아지고 낮아지면서 자동으로 우선순위가 조정된다.
-
상위 큐에서 실행 중인 프로세스가 일정 시간 동안 실행을 완료하지 못한 경우, 우선순위를 낮추고 하위 큐로 이동할 수 있습니다.
-
입출력 등의 외부 작업을 요청하고 대기해야 하는 경우, 해당 프로세스는 하위 큐로 이동하여 입출력 작업이 완료될 때까지 대기
-
하위 큐에서 실행 중인 프로세스가 오래 대기하는 등 일정 조건을 충족하는 경우, 우선순위를 높이고 상위 큐로 이동할 수 있습니다
-
-
참고
Computer Science/Operating System [운영체제] 프로세스 스케쥴링 - 배치 처리 시스템, 시분할 시스템, 멀티..
완전히 정복하는 프로세스 vs 스레드 개념
[운영체제] 스케줄러(Scheduler)
https://jwprogramming.tistory.com/54
