Amazon EC2(Elastic Compute Cloud)
AWS에서 제공하는 클라우드 컴퓨팅 서비스
AWS에서 원격으로 제어할 수 있는 가상의 컴퓨터를 한 대 빌리는 것이라고 생각하자.
EC2를 통해서 할 수 있는 가장 기본적인 것은 웹 서버를 설치하고 서버를 통해서 사용자가 웹 브라우저에 요청하는 서비스를 제공하는 것이다.
What is Cloud Computing?
인터넷(클라우드)를 통해 서버, 스토리지, 데이터베이스 등의 컴퓨팅 서비스를 제공하는 서비스.
Elastic = 탄력있는, 유연한
왜 Elastic이 붙었을까?
후불제 PC방을 생각해보자.
집에서 게임을 하기 위해 기본적으로 지출해야 하는 돈은 필요 없이 게임을 하는 하나의 컴퓨터에 대한 비용만 지불하면 된다.
EC2서비스도 이와 같이 사용한 만큼 비용을 지불하기 때문에 탄력적인 의미의 Elastic이 붙었다.
비용적인 부분 외에도 필요에 따라 성능, 용량을 자유롭게 조절할 수 있다는 의미도 가지고 있다.
즉, EC2 서비스는 AWS에서 비용, 성능, 용량에서 탄력적인 클라우드 컴퓨팅을 제공하는 서비스라고 말할 수 있다.
EC2 장점
- 구성하는데 필요한 시간이 짧다.
- AMI를 통해서 필요한 용도에 따라 다양한 운영체제를 선택할 수 있다.
Instance
AWS에서 빌리는 컴퓨터를 Instance라고 한다.
인스턴스는 1대의 컴퓨터를 의미하는 단위이고, AWS에서 컴퓨터를 빌리는 것을 인스턴스를 생성한다고 한다.
AWS EC2 인스턴스를 생성한다는 것은 AMI를 토대로 OS, CPU, RAM 혹은 런타임 등이 구성된 컴퓨터를 빌리는 것이다.
AMI(Amazon Machine Image)
인스턴스를 생성하는데 필요한 소프트웨어 구성이 기재된 템플릿.(OS + 애플리케이션 서버 + 애플리케이션)
단순히 OS만 깔려있는 템플릿을 선택할 수도 있고, 사용 용도에 맞게 특정 런타임이 구성된 템플릿을 선택할 수도 있다. (Ubuntu + node.js / Windows + JVM ..)
RDS(Relational Database Service)
AWS에서 제공하는 관계형 데이터 베이스 서비스.
왜 사용할까?

EC2 인스턴스를 사용하면 데이터베이스와 관련해서 자동으로 관리를 담당하는 부분이 매우 적기 때문에 사용자가 일일이 시간을 투자하여 데이터베이스 엔진의 설치와 버전 관리, 데이터 백업을 해야 한다.
게다가 가용성과 내구성이 확보되지 않기 때문에 데이터베이스에 저장된 데이터가 유실되거나 정상적으로 사용하지 못할 확률이 커지고 후에 필요에 따라 데이터베이스의 규모를 확장하기 어렵다.
그에 반해 RDS를 이용하면 데이터베이스 유지보수와 관련된 일들을 RDS에서 전적으로 자동 관리한다. 사용자가 해야할 일은 초기 설정을 제외하고 데이터베이스에 저장된 데이터를 관리하는 일밖에 없기에 큰 편의성을 느낄 수 있다.
또한 다양한 데이터베이스 엔진 선택지를 제공한다.
필요와 목적에 맞게 엔진을 선택하여 효율성을 높일 수 있다.
S3(Simple Storage Service)
Cloud Storage?
쉽게 말하자면, 인터넷 공간에 데이터를 저장하는 저장소다.
컴퓨터 부품에 비유하면 하드디스크의 역할을 하는 서비스다.
구글의 Google Drive, 네이버의 MYBOX, 마이크로소프트의 Onedrive와 같은 서비스가 바로 클라우드 스토리지다.
클라우드 스토리지 서비스의 장점으로는 뛰어난 접근성이 있다.
클라우드 스토리지를 이용할 경우 웹 환경이라면 언제 어디서나 저장된 파일에 접근할 수 있다.
컴퓨터뿐만 아니라 웹에 접속이 가능한 다른 전자기기를 활용하여 데이터에 접속할 수 있다.
이점
높은 확장성
확정성이 높으면 많은 시간과 노력을 들이지 않고 스토리지 규모를 확장/축소할 수 있다.
S3에서는 스토리지의 용량을 무한히 확장할 수 있다.
사용한 만큼만 비용을 지불하면 되기 때문에 비용적인 측면에서 매우 효율적이다.
가용성 보장
가용성이 높으면 스토리지에 저장된 파일들을 정상적으로 사용할 수 있는 시간이 길어진다.
S3는 연간 99.99%의 스토리지 가용성을 보장하도록 설계가 되어 있다.
정적 웹 사이트 호스팅이 가능
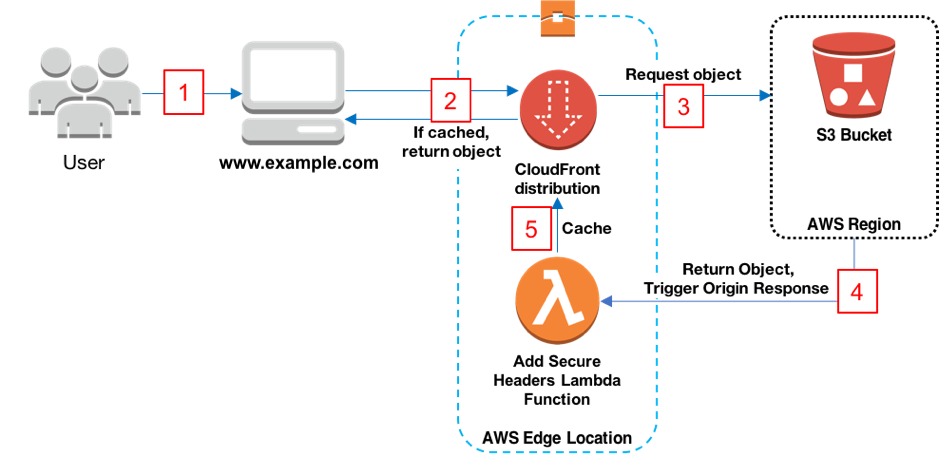
정적 웹 사이트 호스팅 ?
정적 파일은 서버의 개입없이 생성된 파일을 말한다.
반대로 클라이언트가 서버에 요청을 보내면, 서버가 요청에 맞추어 그 자리에서 생성한 파일을 동적 파일이라고 한다.
웹 호스팅 ?
웹 호스팅은 서버의 한 공간을 빌려주어 웹 사이트의 배포, 운영이 가능하게 만들어주는 서비스를 말한다.
S3에서는 버킷이라는 사용자들이 정적 웹 사이트를 배포할 수 있는 공간을 제공한다.
버킷에 정적 파일을 업로드하고 정적 웹 사이트 호스팅 용도로 구성하면 정적 웹 사이트를 배포할 수 있다.
그렇다면 버킷을 더 자세하게 알아보자.
버킷
버킷은 S3에 저장되는 파일들이 담기는 바구니라고 생각하자.
파일을 저장하는 최상위 디렉토리.
무한한 양의 파일을 저장할 수 있다.
버킷의 이름은 각 리전에서 고유해야 하고, 버킷 정책을 생성하여 해당 버킷에 대한 다른 유저의 접근 권한을 수정할 수 있다.
객체
S3에서는 버킷에 담기는 파일을 객체라고 부른다.
그 이유는, S3에서 저장소에 데이터를 저장할 때 키-값 페어 형식으로 데이터를 저장하기 때문이다.
S3에 저장되는 객체는 파일과 메타데이터로 구성된다.
파일의 값에는 실제 데이터를 저장하고, 데이터의 최대크기는 5TB다.
메타데이터는 객체의 생성일, 크기, 유형과 같은 객체에 대한 정보가 담긴 데이터다.
모든 객체는 고유한 키(식별자), 고유한 URL 주소를 가진다.
URL 주소 형식 : http://[버킷의 이름].S3.amazonaws.com/[객체의 키]
EC2 관련 용어
- 인스턴스 : 가상 컴퓨터, 가상 컴퓨팅 환경
- Amazon 머신 이미지(AMI) : OS + 애플리케이션 템플릿 (하드웨어 X)
- 키 페어 : 비대칭 키 암호화 (ssh; Secure Shell)
- 인스턴스 스토어 볼륨 : 인스턴스 자체 내장 HDD/SSD => 인스턴스 종료시 사라짐
- Amazon Elastic Block Store(Amazon EBS) : 인스턴스에 붙일 수 있는 저장공간 (HDD/SSD) => 인스턴스와 독립적으로 저장 가능.
- 리전 : AWS에서 클라우드 서비스를 제공하기 위해서 운영하는 물리적인 서버의 위치.
- 가용영역 (Availiability Zone) : 각 리전안에 존재하는 데이터센터(IDC).
- 보안그룹 : 방화벽
- 탄력적 IP 주소(EIP) :
- Virtual Private Clouds(VPC) :
