[NoSQL] MongoDB
NoSQL
NoSQL: Not Only SQL.
NoSQL은 매우 넓은 범위에서 사용하는 용어로, 관계형 테이블의 레거시한 방법을 사용하지 않는 데이터 저장소를 말한다.
대표적인 NoSQL 데이터베이스는 MongoDB, Redis, HBase 등이 있다.
기존의 RDBMS의 한계를 극복하기 위해 만들어진 새로운 형태의 데이터저장소다.
NoSQL 데이터베이스에서는 데이터를 행과 열이 아닌, 체계적인 방식으로 저장한다.
관계형 DB가 아니므로, RDMS처럼 고정된 스키마 및 JOIN 이 존재하지 않는다.
RDMS와의 비교
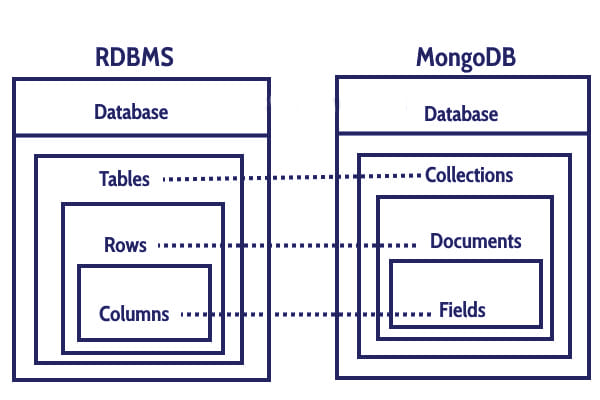
RDMS: Relational Database Management System (관계형 데이터베이스 관리 시스템).
RDMS은 행과 열로 된 2차원의 table로 데이터를 관리하는 데이터베이스 시스템이다.
Mysql, Oracle, DB2 등 시스템들이 속한다.
| RDBMS | MongoDB |
|---|---|
| Database | Database |
| Table | Collection |
| Tuple / Row | Document |
| Column | Key / Field |
| Table Join | Embedded Documents |
| Primary Key | Primary Key (_id) |
| Database Server & Client | |
| mysqld | mongod |
| mysql | mongo |
장점
- Schema-less : 스키마가 없기 때문에 유연하다.
언제든지 저장된 데이터를 조정하고 새로운필드를 추가할 수 있다. - 빠른
key-value접근. - 쉬운 유지보수.
- 복잡한 JOIN이 없다.
- 각 객체의 구조가 뚜렷하다.
- 문서지향적 Query Language를 사용하여 SQL만큼 강력한 쿼리 성능을 제공한다.
- 데이터는 애플리케이션이 필요로 하는
형식으로 저장된다.
이렇게 하면 데이터를 읽어오는 속도가 빨라진다. - 수직 및 수평 확장이 가능하므로 데이터베이스가 애플리케이션에서 발생시키는 모든 읽기 / 쓰기 요청을 처리 할 수 있다.
MongoDB
MongoDB는 대표적인 NoSQL 도큐먼트 데이터베이스이다.
도큐먼트 데이터베이스는 데이터를 테이블이 아닌, 문서처럼 저장하는 데이터베이스를 의미한다.
일반적으로 도큐먼트 데이터베이스에서는 JSON 유사 형식으로 데이터를 문서화한다.
각각의 도큐먼트는 데이터를 필드-값 의 형태로 가지고 있고, 컬렉션이라고 하는 그룹으로 묶어서 관리한다.
- MongoDB 특징
DocumentBASEOpen Source
데이터는 Document 기반으로 구성되어 있고, ACID 대신 BASE를 택해서 성능과 가용성을 우선시한다.
Open Source라서 무료로 이용 가능하다.
MongoDB가 왜 NoSQL 데이터베이스인지 ?
NoSQL은 데이터 구성을 위해 테이블, 행과 열을 사용하지 않음을 의미하며 이는 MongoDB의 대표적인 특징이다.
MongoDB는 관계형 테이블을 사용하지 않기 때문에 스키마리스(schemaless)라는 특징을 가지고 있다.
MongoDB Document


MongoDB는 Document 기반 데이터베이스다.
Database > Collection > Document > Field 계층으로 이루어져 있고, Document는 RDBMS의 Row에 해당한다.
-
도큐먼트(Document)
필드 - 값 쌍으로 저장된 데이터 -
필드(Field)
데이터 포인트를 위한 고유한 식별자 -
값(Value)
주어진 식별자와 연결된 데이터 -
컬렉션(Collection)
MongoDB의 도큐먼트로 구성된 저장소.
일반적으로 도큐먼트 간의 공통 필드가 있다.
데이터베이스 당 많은 컬렉션이 있고, 컬렉션 당 많은 도큐먼트가 있을 수 있다.
명령어
Database 생성 : USE
use DATABASE_NAME 명령어를 통해서 database를 생성할 수 있다.
> use mongodb_test
switched to db mongodb_test현재 사용 중 인 데이터베이스를 확인하려면 db 명령어를 사용한다.
> db
mongodb_test데이터베이스 리스트를 확인하려면 show dbs 명령어를 사용한다.
> show dbs
admin 0.000GB
config 0.000GB
local 0.000GB왜 방금 만든 mongodb_test 데이터베이스가 없지 ?
리스트에서 방금 만든 데이터베이스를 보기 위해서는 최소 한개의 Document를 추가해야 한다.
여기서 book은 Collection인데, 미리 생성하지 않고 이렇게 작성해도 된다.
> db.book.insert({"name": "MongoDB Tutorial", "author": "chayezo"});
WriteResult({ "nInserted" : 1 })
> show dbs
admin 0.000GB
config 0.000GB
local 0.000GB
mongodb_test 0.000GBDatabase 제거 : db.dropDatabase()
먼저 db.dropDatabase() 명령어를 사용해서 제거하기 전에, use DATABASE_NAME 으로 삭제하고자 하는 데이터베이스를 선택해줘야 한다.
> use mongodb_test
switched to db mongodb_test
> db.dropDatabase();
{ "dropped" : "mongodb_test", "ok" : 1 }Collection 생성 : db.createCollection()
Collection을 생성할 때는 db.createCollection(name, [options]) 명령어를 사용한다.
name은 생성하려는 컬렉션의 이름이고 option은 document 타입으로 구성된 해당 컬렉션의 설정값이다.
options 매개변수는 optional이다. 필요에 따라 사용하자.
/* books 컬렉션을 옵션없이 생성 */
> db.createCollection("books")
{ "ok" : 1 }/* articles 컬렉션을 옵션과 함께 생성 */
> db.createCollection("articles", {
... capped: true,
... autoIndex: true,
... size: 6142800,
... max: 10000
... })
{ "ok" : 1 }/* createCollection 메서드를 사용하지 않아도
document를 추가하면 자동으로 컬렉션이 생성된다. */
> db.user.insert({"name" : "chacha"})
WriteResult({ "nInserted" : 1 })Collection 리스트를 확인하려면 show collections 명령어를 사용
한다.
> show collections
articles
books
userCollection 제거 : db.COLLECTION_NAME.drop()
명령어를 사용해서 제거하기 전에, 데이터베이스를 우선 설정해준다.
> use test
switched to db test
> show collections
articles
books
user
> db.user.drop()
true
> show collections
articles
booksDocument 추가 : db.COLLECTION_NAME.insert(document)
> db.books.insert({"name" : "NodeJS Tutorial", "author" : "yezo"})
WriteResult({ "nInserted" : 1 })
> db.books.insert([
... {"name": "Book1", "author": "yezo"},
... {"name": "Book2", "author": "yezo"}
... ]);
BulkWriteResult({
"writeErrors" : [ ],
"writeConcernErrors" : [ ],
"nInserted" : 2,
"nUpserted" : 0,
"nMatched" : 0,
"nModified" : 0,
"nRemoved" : 0,
"upserted" : [ ]
})컬렉션의 도큐먼트 리스트를 확인할 때는 db.COLLECTION_NAME.find() 명령어를 사용한다.
Document 제거 : db.COLLECTION_NAME.remove(criteria, justOne)
이 메서드의 두 가지 매개변수를 알아보자.
| parameter | type | 설명 |
|---|---|---|
| criteria | document | 삭제할 데이터의 기준값. 이 값이 {}이면 컬렉션의 모든 데이터를 제거한다. |
| justOne | boolean | 선택적 매개변수. true면 1개의 도큐먼트만 제거. 기본값은 false(모든 도큐먼트 제거). |
도큐먼트 삭제하려다가 실수하지 않도록, find()를 먼저 해서 확인하자.
> db.books.find({"name": "Book1"})
{ "_id" : ObjectId("56c097f94d6b67aafdeb88ac"), "name" : "Book1", "author" : "yezo" }
> db.books.remove({"name": "Book1"})
WriteResult({ "nRemoved" : 1 })
> db.books.find()
{ "_id" : ObjectId("56c08f3a4d6b67aafdeb88a3"), "name" : "MongoDB Tutorial", "author" : "yezo" }
{ "_id" : ObjectId("56c08f474d6b67aafdeb88a4"), "name" : "NodeJS Tutorial", "author" : "yezo" }
{ "_id" : ObjectId("56c097f94d6b67aafdeb88ad"), "name" : "Book2", "author" : "yezo" }Document 조회 : db.COLLECTION_NAME.find(query, projection)
| parameter | Type | 설명 |
|---|---|---|
| query | document | Optional. 도큐먼트 조회할 때 기준. 모든 도큐먼트 조회 : 매개변수를 비우거나 {}를 전달. |
| projection | document | Optional. 도큐먼트 조회할 때 보여질 field를 정한다. |
도큐먼트들을 깔끔하게 정리된 코드로 보고싶다 ?
find() 메서드 뒤에 .pretty()를 붙여주자.
/* 모든 도큐먼트 깔끔하게 조회 */
> db.articles.find().pretty()
{
"_id" : ObjectId("56c0ab6c639be5292edab0c4"),
"title" : "article01",
"content" : "content01",
"writer" : "yezo",
"likes" : 0,
"comments" : [ ]
}
{
"_id" : ObjectId("56c0ab6c639be5292edab0c5"),
"title" : "article02",
"content" : "content02",
"writer" : "chacha",
"likes" : 23,
"comments" : [
{
"name" : "Bravo",
"message" : "Hi hello"
}
]
}/* witer 값이 "yezo"인 Document 조회 */
> db.articles.find({"writer" : "yezo"}).pretty()
{
"_id" : ObjectId("56c0ab6c639be5292edab0c4"),
"title" : "article01",
"content" : "content01",
"writer" : "yezo",
"likes" : 0,
"comments" : [ ]
}Query 연산자
여러 종류의 연산자는 mongoDB 매뉴얼을 참고하자.
비교 연산자
| operator | 설명 |
|---|---|
| $eq | (equals) 주어진 값과 일치하는 값 |
| $gt | (greater than) 주어진 값보다 큰 값 |
| $gte | (greater than or equals) 주어진 값보다 크거나 같은 값 |
| $lt | (less than) 주어진 값보다 작은 값 |
| $lte | (less than or equals) 주어진 값보다 작거나 같은 값 |
| $ne | (not equal) 주어진 값과 일치하지 않는 값 |
| $in | 주어진 배열 안에 속하는 값 |
| $nin | 주어진 배열 안에 속하지 않는 값 |
/* likes 값이 10보다 크고 30보다 작은 Document 조회 */
> db.articles.find({'likes': {$gt: 10, $lt: 30}}).pretty()
{
"_id" : ObjectId("56c0ab6c639be5292edab0c5"),
"title" : "article02",
"content" : "content02",
"writer" : "Alpha",
"likes" : 23,
"comments" : [
{
"name" : "Bravo",
"message" : "Hi hello"
}
]
}
/* writer 값이 배열 ['Alpha', 'Bravo'] 안에 속하는 값인 Document 조회 */
> db.articles.find({'writer': {$in:['Alpha', 'Bravo']}}).pretty()논리 연산자
| operator | 설명 |
|---|---|
| $or | 주어진 조건 중 하나라도 true일 때 true |
| $and | 주어진 모든 조건이 true일 때 true |
| $not | 주어진 조건이 false일 때 true |
| $nor | 주어진 모든 조건이 false일 때 true |
/* title값이 'article01'이거나 writer값이 'Alpha'인 Document 조회 */
> db.articles.find({ $or:[{'title': 'article01'}, {'writer': 'Alpha'}] })
/* writer값이 'yezo'이고 likes값이 10미만인 Document 조회 */
> db.articles.find({ $and: [{'writer': 'yezo'}, {'likes': {$lt: 10}}] })
> db.articles.find({ 'writer': 'yezo', 'likes': {$lt: 10} })CRUD
CREATE
모든 MongoDB 도큐먼트는 모든 도큐먼트가 _id 필드를 기본값으로 반드시 가지고 있어야 한다는 공통점이 있다.
이 _id 필드의 값은 각 도큐먼트를 구별하는 역할을 한다.
도큐먼트 내 필드와 값이 똑같다 할지라도, _id 값이 다르면 서로 다른 도큐먼트로 간주한다.
필드와 값이 같은 도큐먼트가 존재하더라도 같은 컬렉션 내부에 새로운 도큐먼트로 추가가 가능하다.
반면에, 도큐먼트 내 필드와 값이 다르다고 하더라도, _id값이 같다고 하면 서로 같은 도큐먼트로 여겨 에러를 발생시킨다(컬렉션에 저장되지 않는다).
따라서 각 도큐먼트는 고유한 _id 값을 가지고 있어야 한다.
새로운 도큐먼트를 추가할 때, _id 값에 임의적으로 고유한 값을 생성해서 사용할 수도 있지만 보통은 ObjectId 타입(12byte, 24char)의 값으로 사용한다.
또한 도큐먼트를 추가할 때, _id 필드와 값을 특정하지 않았다면, 자동적으로 _id 필드가 생성되고 값에 ObjectId 타입이 할당된다.
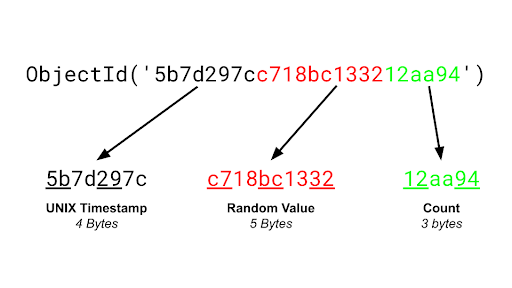
ObjectId는 RDBMS의 Primary Key와 같이 고유한 키를 의미한다.
차이점은 PK는 DBMS가 직접 부여하지만 ObjectId는 클라이언트에서 생성한다.
빈 fruits 컬렉션에 새로운 3개의 도큐먼트를 추가하기 위해서 사용할 수 있는 명령어
> db.fruits.insert([{ 'fruit': 'apple' }, { 'fruit': 'banana' }, { 'fruit': 'orange' }]);- 배열 내부의 요소인 도큐먼트는
_id값이 없기 때문에 자동적으로 고유한_id의 값이 생성되어 배열의 인덱스 순서대로 추가된다.
// 1번
> db.fruits.insert([{ "_id": 1, "fruit": "apple" },
{ "_id": 1, "fruit": "banana" },
{ "_id": 3, "fruit": "blueberries" },
{ "_id": 4, "fruit": "pineapple" }], { "ordered": true })
// 2번
> db.fruits.insert([{ "_id": 1,"fruit": "apple" },
{ "_id": 1, "fruit": "banana" },
{ "_id": 3, "fruit": "blueberries" },
{ "_id": 4, "fruit": "pineapple" }], { "ordered": false })- 1번은 오답
- insert 명령어의 첫번째 인자로는 추가하려는 도큐먼트가 담긴 배열, 두번째 인자로는
ordered필드와 값인 true가 들어가 있는데, 이때ordered필드의 값이 true이기 때문에, 배열 안의 인덱스 순서대로 insert 작업이 수행된다. 그러나_id필드의 값이 같은 것이 있다면duplicate key에러가 발생한다. 해당 필드와 값 이후의 요소들은 추가되지 않는다.
- insert 명령어의 첫번째 인자로는 추가하려는 도큐먼트가 담긴 배열, 두번째 인자로는
- 2번은 맞다.
- 1번과 같지만, 두번째 인자의 값이 false이기 때문에 배열 내부의 요소의 순서에 상관없이 고유한
_id의 값을 가진 도큐먼트는 모두 새로운 도큐먼트로 추가된다.
- 1번과 같지만, 두번째 인자의 값이 false이기 때문에 배열 내부의 요소의 순서에 상관없이 고유한
> db.fruits.insert([{ "_id": 1,"fruit": "apple" },
{ "_id": 2, "fruit": "banana" },
{ "_id": 3, "fruit": "blueberries" },
{ "_id": 3, "fruit": "pineapple" }]) ordered필드가 정해지지 않으면 true가 기본값으로 설정된다.
배열의 요소 순서대로 삽입되기 때문에 인덱스 0부터 2번까지의 도큐먼트 3개가 새로운 도큐먼트로 추가된다.
READ
도큐먼트를 조회할 때 find() 메서드를 사용하자.
/* 전체 목록 조회 */
> db.users.find()
/* {}를 넣으면 all document를 의미한다 */
> db.users.find({})
/* 최근에 입력한 순서대로 목록을 조회해보자(내림차순) */
> db.users.find().sort({ _id: -1 })
/* findOnd() : find()메서드를 사용해 추출할 수 있는 배열의 가장 첫번째 데이터 */
> db.users.findOne()
UPDATE
update() 메서드를 통해 컬렉션 안의 도큐먼트들을 수정할 수 있다.
특정 field를 수정할 수도 있고 이미 존재하는 도큐먼트를 대체(replace)할 수도 있다.
update() 메서드의 기본 옵션으로는 단 하나의 도큐먼트를 수정한다.
db.collection.update()
db.collection.update(
<query>,
<update>,
{
upsert: <boolean>,
multi: <boolean>,
writeConcern: <document>
}
)다수의 데이터를 업데이트 해야할 때는 updateMany() 명령어를 사용하자.
- 특정 field 업데이트 하기
$set 연산자를 사용하자 !
주어진 필드에 값을 업데이트 한다.
주어진 필드가 존재하지 않으면? 새롭게 필드를 생성한 뒤 값을 할당한다.
> db.user.update( { name: 'Mino' }, { $set: { age: 20 }} )- document replace하기
이렇게 새로운 document로 replace할 때_id는 바뀌지 않는다.
> db.user.update( { name: 'yezo' }, { name: 'yezo 2nd', age: 1 } )- 특정 field를 제거하기
> db.user.update( { name: 'cha cha' }, { $unset: { score: 1 }} )- 여러 document의 특정 field를 수정하기
/* age가 20보다 낮거나 같은 document의 score를 10으로 설정 */
> db.user.update(
... { age: { $lte: 20 }},
... { $set: { score: 10 }},
... { multi: true }
... )- updateMany: 특정 필드의 값을 주어진 만큼 증가($inc)
첫번째 인자는 어떤 도큐먼트를 업데이트 할지 결정하는 쿼리문
두번째 인자는 발생할 업데이트 내용을 특정한다.
> db.zips.updateMany( { 'city': 'ALPINE' }, { '$inc': { 'pop': 10 }} )- 배열에 값 추가하기
$push 연산자를 사용하기 !
필드가 도큐먼트에 존재하면, 배열 타입의 값에 새로운 요소를 추가하여 업데이트 한다.
필드가 존재하지 않으면 필드의 값으로 빈 배열을 생성하여 그 안에 요소로 값을 추가한다.
/* yezo document의 skills 배열에 'Reactjs' 추가 */
> db.people.update(
... { name: 'yezo' },
... { $push: { skills: 'Reactjs' }}
... )- 배열에 값 여러개 추가하기 + 오름차순 정렬
내림차순으로 정렬하려면-1
/* yezo documentdml skills에 'python', 'java'를 추가하고 알파벳순으로 정렬 */
> db.people.update(
... { name: 'yezo' },
... { $push: {
... skills: {
... $each: [ 'python', 'java' ],
... $sort: 1
... }
... }
... }
... )- 배열에 값 제거하기
/* yezo document에서 skills 값의 mongodb 제거 */
> db.people.update(
... { name: 'yezo' },
... { $pull: { skills: 'mongodb' }}
... )DELETE
도큐먼트를 삭제하려면 deleteOne(), deleteMany() 메서드를 사용할 수 있다.
deleteOne()은 주어진 기준에 맞는 다수의 도큐먼트 중 첫번째 도큐먼트 하나를 삭제한다.
그렇기 때문에 deleteOne()을 사용하는 경우, _id 값으로 쿼리해 온 도큐먼트를 삭제하는 것이 좋은 접근법이다.
만약 _id 값으로 쿼리를 하지 않는다면, 검색 쿼리문에 다양한 도큐먼트가 적합할 수 있기 때문이다.
기준을 충족하는 도큐먼트가 많을 경우에는 deleteMany()를 사용하여 다수의 도큐먼트를 삭제할 수도 있다.
컬렉션을 삭제하기 위해서는 drop 명령어를 사용한다.
