
AWS에서 대표적인 스토리지 서비스인 S3의 특징에 대해서 정리하려고 한다
S3의 기본 인터페이스는 REST API이다.
기본적으로 S3 서비스는 REST API를 통해서 제공된다. HTTPS 모드에서 SOAP API를 지원 한다고는 하지만, 새로운 S3에서는 지원하지 않을 예정이라고 하니 REST 방식을 사용하기를 권장한다고 한다.
S3는 특정 OS 기반의 파일 시스템이 아닌 웹 기반의 데이터 저장소이다.
S3 서비스는 기본적으로 ‘한 번 기록하고 여러 번 읽는’ 서비스이다. 전통적인 파일 시스템 또는 SAN 아키텍처와는 차이가 있다는 점을 알아야 한다.
S3는 기본적으로 여러 AZ에 데이터를 전파한다.
신뢰성을 지키기 위해서 S3는 해당 리전의 다른 AZ로 전파한다 그러나 다른 리전에는 전파하지 않는다. 다른 리전에 전파 하기 위해서는 수동으로 조작해야 한다.
아래는 S3의 인프라 구조이다. 해당 API 호출 시 로드밸런서를 통해서 웹 서버 -> 스토리지로 접근하게 된다. 그리고 스토리지는 또 다른 스토리지에 전파를 하는데 이 경우에 P2P 기반으로 작동을 하는지, 어떤 식으로 전파를 하는지는 아직 잘 모르겠다.
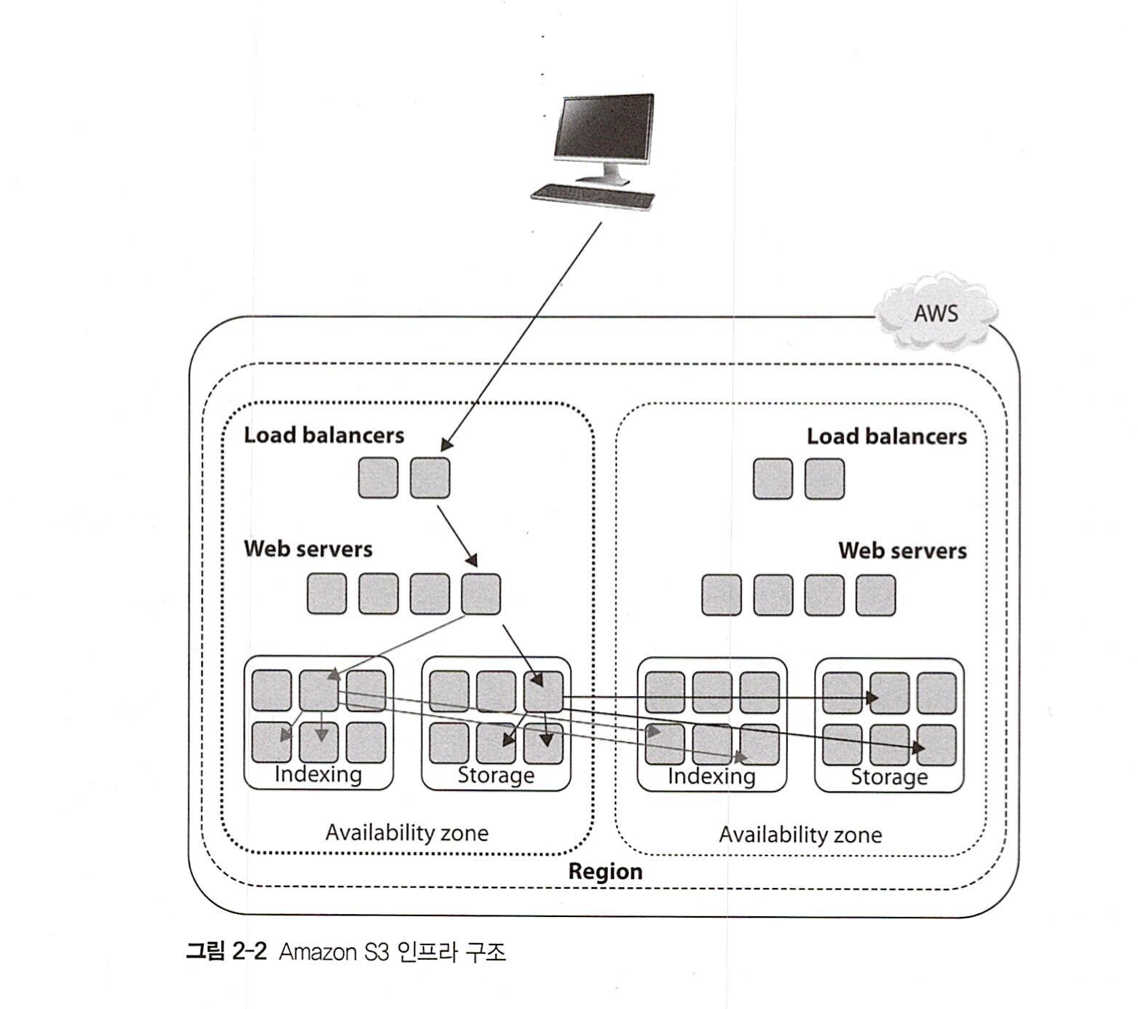
여러 AZ에 전파하게 된다면 데이터를 조작할때는 어떻게 되는 것일까?
새로운 데이터를 작성하고 저장해도, 변경사항이 완전히 확산되기 전까지는 조회를 해도 데이터가 나타나지 않는다. 그 이유는 다른 AZ로 데이터가 전파되지 않아서다. S3가 종국적 일관성 모델을 제공해 사용하기 때문인데 데이터가 자동으로 복제돼 동일 리전 내 다수의 시스템 및 다수의 AZ에 확산되므로 최신 내용으로 변경한 내용이 즉각적 으로 반영되지 않거나 업데이트 직후 데이터를 읽으려 할 때 변경된 내용을 확인할 수 없게 될 가능성이 있다.
동시 다발적으로 수정을 S3 내부에 있는 데이터를 변경한다면?
S3는 객체 잠금 기능을 지원하지 않기 때문에 동시 다발적으로 업데이트가 수행이 된다면 최종 마지막으로 변경된 값이 수정이 된다. 객체 잠금 기능은 애플리케이션 레벨에서 따로 구현해서 사용하면 된다고 한다.
S3의 성능을 고려한 설계를 해야 한다
S3 버킷에 초당 100회 이상의 PUT/UST/DELETE 요청을 하거나 300회 이상의 GET 요청을 해야 한다면, 해당 작업의 워크로드를 적절히 파티셔닝, 즉 분산할 수 있는 방법을 고려해야 한다.
S3는 자동으로 모든 버킷을 파티셔닝하는데 이 과정에서 잘못된 사용은 성능의 저하를 일으킬 수 있다.
예를 들어, awsbook 버킷에 다음과 같이 20 개의 이미지 객체를 저장하는 경우를 생각 해 보자. 기본적으로는 키 프리핀스에 따라 파티셔닝을 한다. 즉, 객체 키의 시작 단어인 chapter 의 첫 번째 부분인 C를 기준으로 파티셔녕한다.
chapter2/image/image2.1.jpg
chapter2/image/image2.2.jpg
chapter2/image/image2.3.jpg
chapter2/image/image3.1.jpg
chapter2/image/image3.2.jpg 이럴 경우 모든 파일이 awsbook/c라는 동일 파티션에 저장되는데 이런 이미지가 수백만개에 이른다면 이 버킷에 저장된 객체의 저장 관련 성능에 좋지 않은 영향을 주게 될것이다.
해결 방법
1. 키 이름 문자열의 역순배열
2chapter/image/image2.1.jpg
2chapter/image/image2.2.jpg
2chapter/image/image2.3.jpg
3chapter/image/image3.1.jpg
3chapter/image/image3.2.jpg
3chapter/image/image3.3.jpg위와 같은 방식으로 저장하면 awsbook/2, awsbook/3 과 같이 숫자를 기준으로 분산된다
2. 키 이름에 Hex Hash 프리픽스 추가하기
키 이름에 16진수 계열의 Hex Hash 프리픽스를 추가해서 적절한 무작위성을 반영한다
112a2chapter/image/image2.1.jpg
c9122chapter/image/image2.2.jpg
2a822chapter/image/image2.3.jpg
7a2d3chapter/image/image3.1.jpg
c3dd3chapter/image/image3.2.jpg
8ao93chapter/image/image3.3.jpg다만 위의 같은 방식으로 사용을 할때에는 너무 많은 파티션 키가 생성될 수 있다.
초당 100회의 요청 처리, 파티션별 2500만 개의 객체 저장 업무를 수행할 수 있으므로 실제로는 2~3개의 프리픽스 문자열로도 충분하다고 한다.
출처. AWS 공인 솔루션스 아키텍트 올인원 스터디 가이드
