
엘리베이터에 거울이 있는 이유
1853년, 미국 오티스사는 세계 최초로 안전장치가 부착된 엘리베이터를 개발했다. 다른 엘리베이터에 비해 안전성은 확보됐지만 속도가 느린 게 단점이었다.
🤯: 엘리베이터가 너무 느려서 답답해요!
🧐: 흠… 엘리베이터 속도를 높여야겠군.
(뚝딱뚝딱… 🛠🪓🛠🪓)
🧐: 아무리 생각해도 속도를 높이는 방법이 안 나와! 좋은 방법이 없을까…?
… 아하 😲 !
엘리베이터에 거울을 달면 사람들이 거울을 보느라 엘리베이터 속도에 신경을 덜 쓰게 될 거야!
엘리베이터 속도 == API 응답 지연속도, 거울 == Skeleton UI에 비유할 수 있다.
Skeleton UI
실제 데이터가 렌더링 되기 전 보이게 될 화면의 윤곽을 먼저 그려주는 로딩 애니메이션.
도입 배경
사용자 API 요청 지연 시간 측정
깜지 에서는 현재 약 80인의 챌린저가 깜지에서 전공 과목에 대한 챌린지를 진행하고 있다. 실제 유저가 있는 서비스를 운영하다보니 사용자 경험에 대한 고려가 필수적이다. 깜지 프론트엔드 파트에선 Firebase Performance Monitoring을 통해 사용자 지표를 수집하고 있다.
Firebase Performance Monitoring을 사용하면 아주 심플하게 무료로! API 응답 지연속도 지표를 확인할 수 있다. 다음은 깜지 사용자들의 API 응답 지표이다. 100ms대부터 2s대까지 다양한 지표들이 수집되었다.
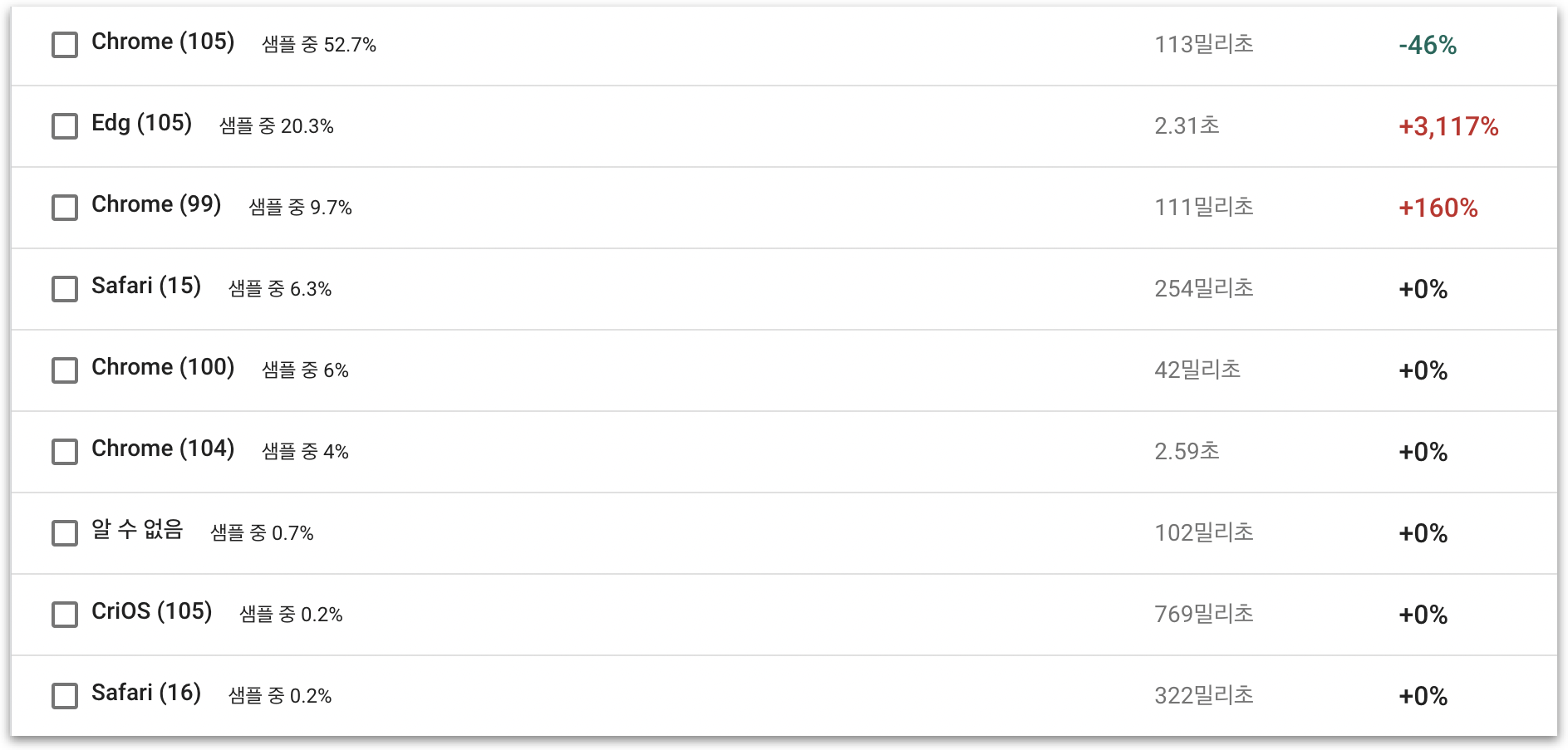
지표들을 그래프화 하면 다음과 같다. 64%의 사용자(API 요청)는 약 110ms의 응답 지연을 경험하고 있는 반면 24%의 사용자는 약 2500ms의 응답 지연을 경험하고 있다.
실제로 사용자는 어떤 화면을 보게 될까?
2500ms라고 했을 때 꽤 느릴 것 같긴한데... 잘 감이 안 와서 크롬 개발자도구를 통해 테스트 해보았다. Network 탭에서 지연 시간을 Custom으로 추가해서 간단히 테스트해볼 수 있다.
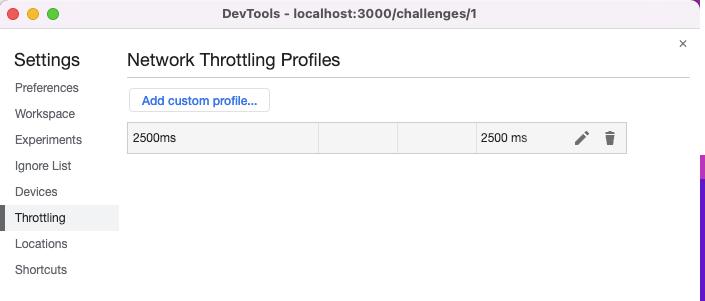
요청되는 데이터가 많아 무거운 퀴즈 리스트를 호출해보았다.
- Latency 110ms
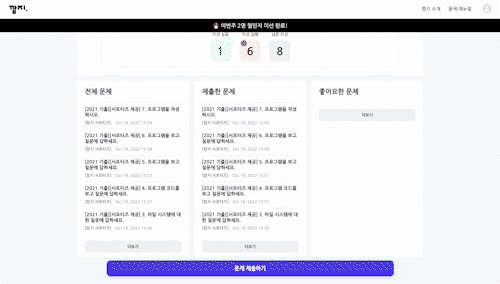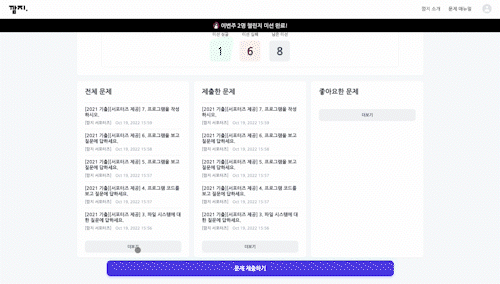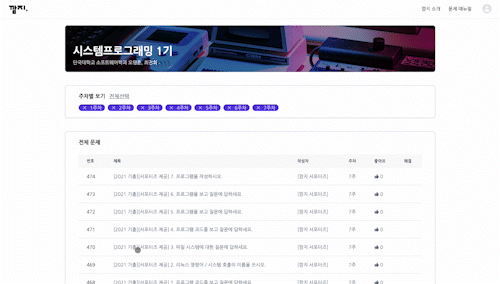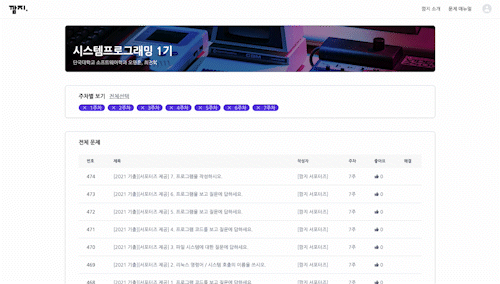
- Latency 2500ms
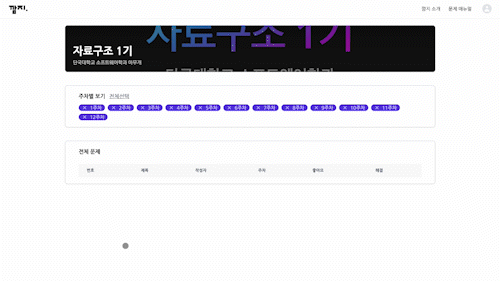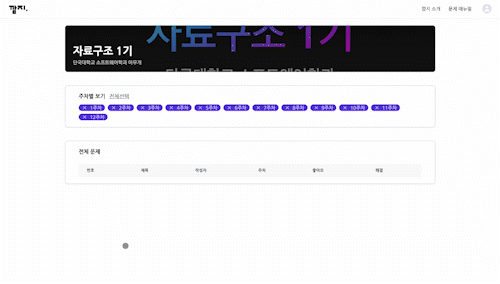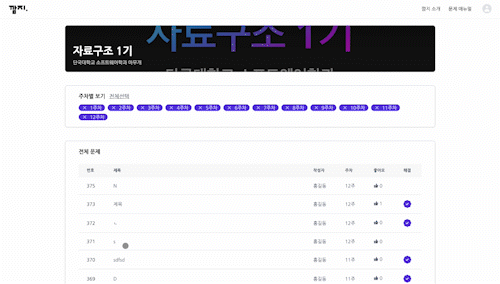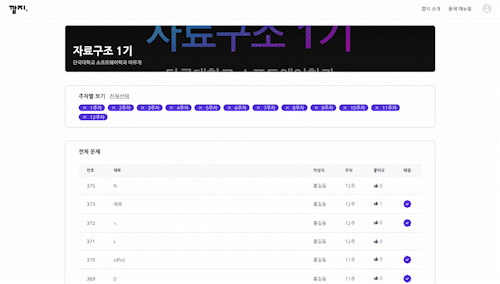
지연 시간이 2500ms일 땐 마치 리스트에 데이터가 존재하지 않는 것처럼 보인다. 네트워크가 매우 열악한 환경(ex. 지하철)에서 이 같은 상황이 오랫동안 지속된다면 사용자가 이탈할 확률이 높아진다.
Skeleton UI 도입
데이터 양이 많은 컴포넌트부터
데이터 양이 많은 퀴즈 리스트 컴포넌트에 우선적으로 Skeleton UI를 도입했다..
- 2500ms
같은 2500ms의 요청인데 빈화면만 보고 있는 것보다 빠르게 응답하는 것처럼 느껴진다. (저만 그런가요?)
Skeleton UI가 언제나 좋을까?
-
110ms
110ms의 latency에서는 Skeleton 컴포넌트가 나오기도 전에 리스트 컴포넌트가 나타난다. 크게 의미가 없다.
-
600ms
600ms의 latency에서는 다음과 같이 보인다.
-
300ms
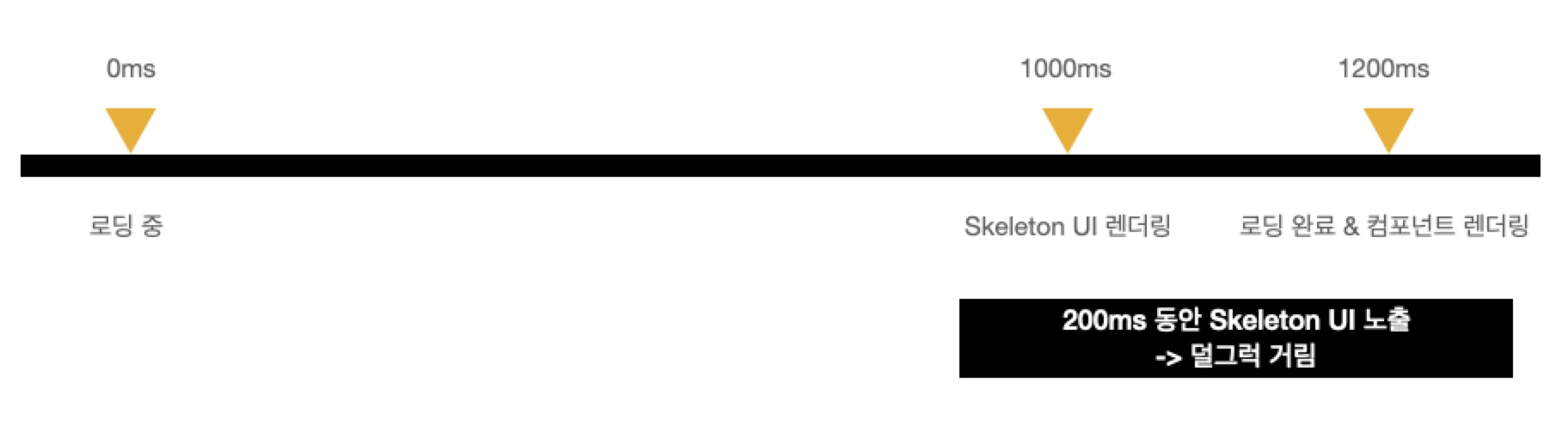
300ms의 latency에서는 다음과 같이 보인다. Skeleton 컴포넌트가 굉장히 짧게 나왔다가 사라져 덜그럭거리는 느낌을 준다.
UX 리서치 그룹 닐슨 노먼에서 발표한 Progress Indicators에 대한 지침에는 다음과 같은 항목이 있다.
약 1초 이상 걸리는 작업에 Progress Indicator를 사용하라.
로드하는 데 1초 미만이 소요되는 항목에 애니메이션을 사용하면 주의가 산만해지고 깜빡이는 내용에 대해 불안을 느낄 수 있다.
그렇다면 Skeleton UI를 어느 시점에 노출해야 할까? 1초의 딜레이 후 노출하면 될까? 하지만 데이터가 로딩되기 전까지는 몇 초의 latency가 발생할지 모른다. 예를 들어, 로딩을 시작한지 1초 후부터 Skeleton을 노출하면 1.2초의 latency를 겪는 사용자는 0.2초만 Skeleton 컴포넌트를 보게 되고 위와 같은 덜그럭거림을 느낄 것이다.
다시 지표로 돌아가보면, 우리 사이트의 사용자의 64%는 110ms을, 24%의 사용자는 2500ms을, 6%의 사용자는 250ms의 latency를 겪고 있다. 250ms부터 2500ms의 latency를 경험하는 사용자는 극소수이다. 따라서 Skeleton으로 인한 덜그럭거림을 느끼는 사용자가 반드시 존재한다면 그 수를 가장 적게 하자라는 결론을 내리게 됐다.
결론적으로 깜지 프론트엔드 파트는 API 요청 Latency가 300ms 이상인 사용자에게만 Skeleton UI를 노출하기로 했다. 250ms 이하로 latency를 겪는 76%의 사용자는 Skeleton UI를 보지 않고, 기존과 같은 사용자 경험을 가지게 된다. 2500ms의 latency를 겪는 24%의 사용자는 Skeleton UI로 보다 부드러운 사용자 경험을 가지게 될 것으로 예상된다.
Skeleton 지연 컴포넌트
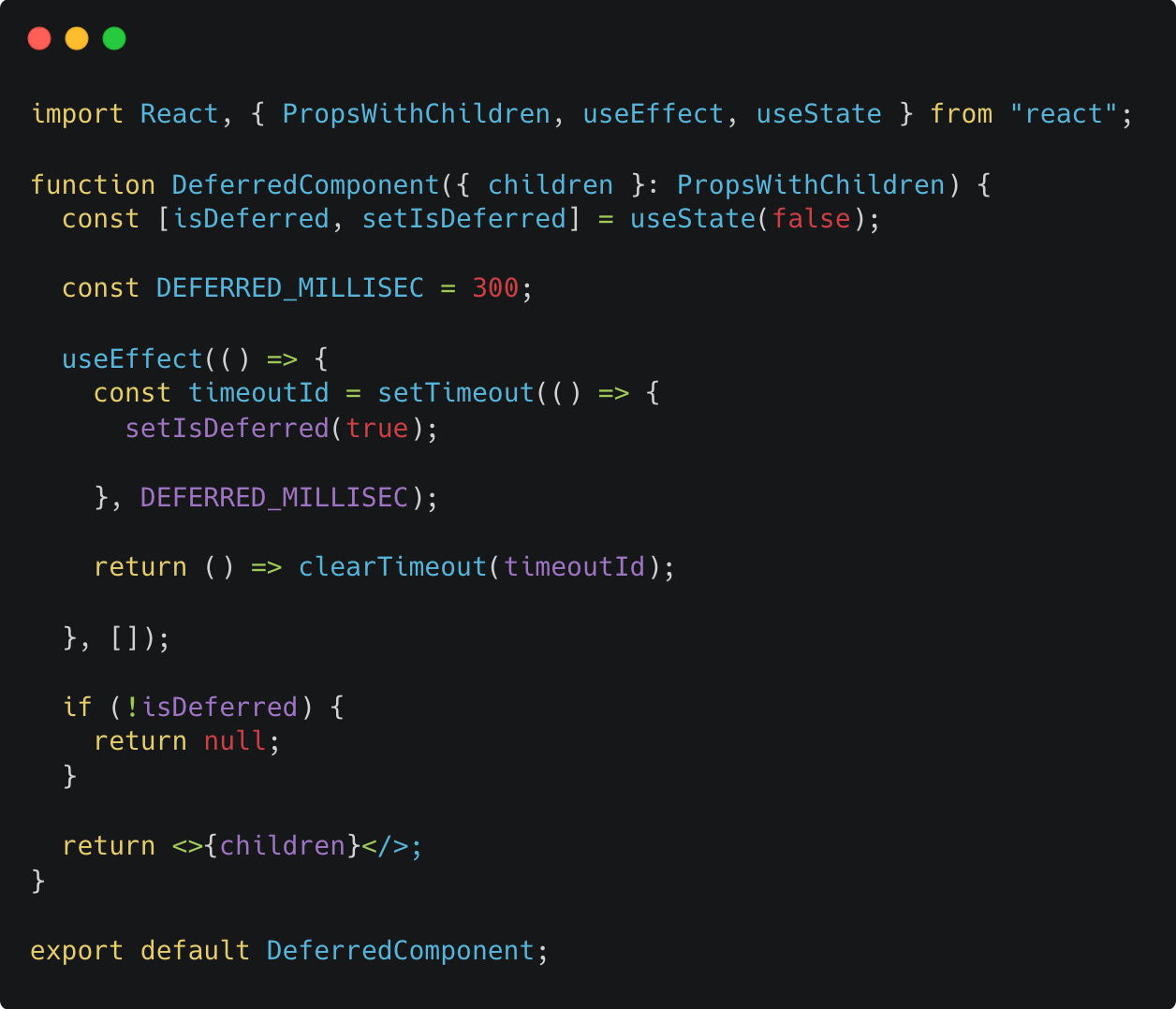
Skeleton 컴포넌트를 지연 컴포넌트(DeferredComponent)로 감싸주면 설정한 지연 시간 이전에는 Skeleton 컴포넌트가 노출되지 않는다.
React Suspense 도입
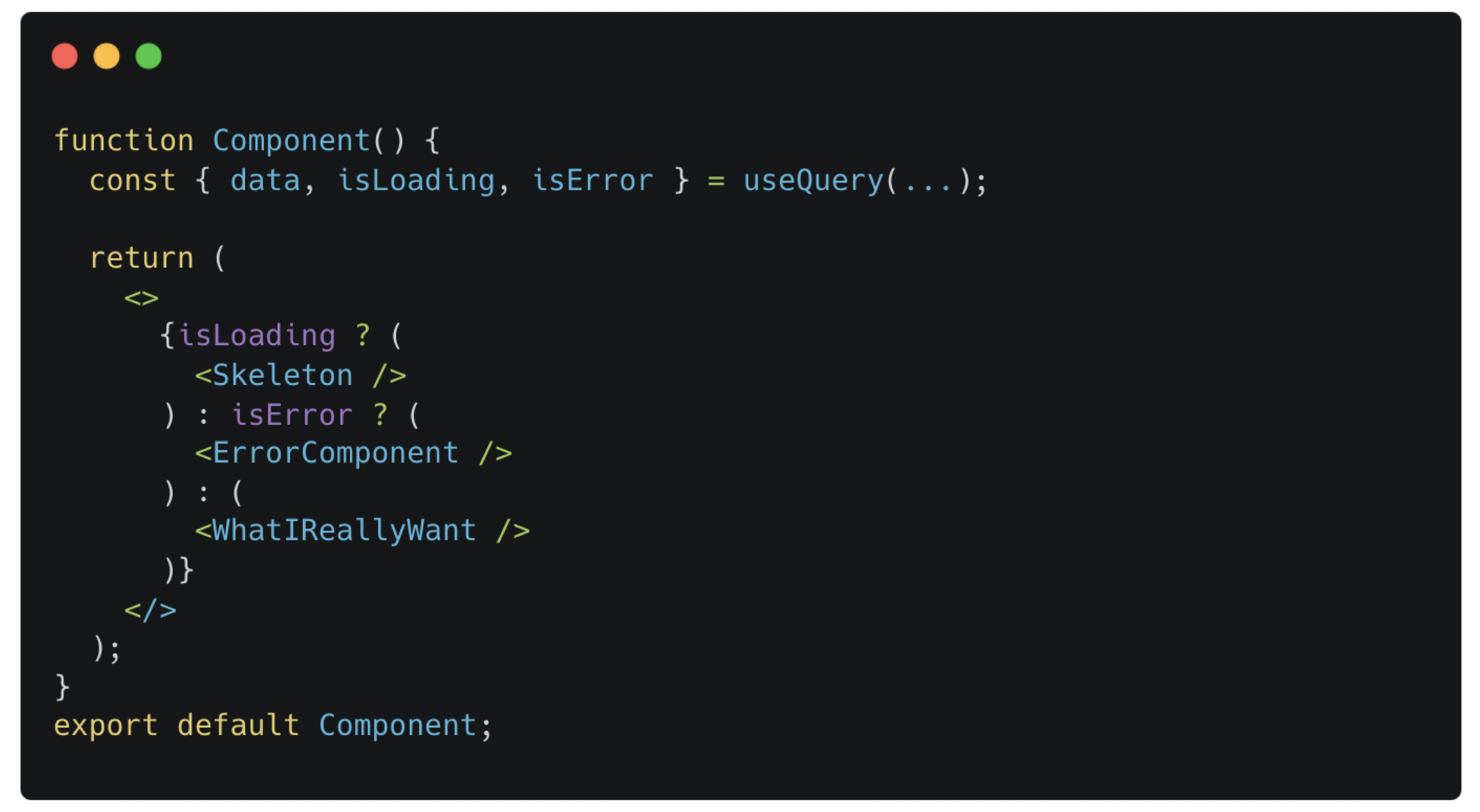
React Query와 함께 간단히 Skeleton UI를 사용할 수 있다. 삼항 연산자를 쓰거나 if-else 구문으로 데이터가 로딩 중일 때 Skeleton 컴포넌트를 노출시키면 된다. 하지만 화면에서 관리해야 하는 상태가 isLoading만은 아니다. isError 등 여타의 상황과 같이 관리를 해주려면 코드의 복잡도가 높아진다.
만약 A와 B라는 컴포넌트가 각각 필요한 데이터를 불러오고, 둘 모두의 데이터가 로딩됐을 때 A, B를 렌더링해야 하는 상황이라면? 이런 상황이 여러 개라면? 상태관리가 굉장히 복잡해질 것이다.
Suspense
React 18에서 정식 기능으로 릴리즈된 Suspense를 사용하여 이러한 상황을 해결할 수 있다. Suspense는 어떤 컴포넌트의 데이터가 아직 준비되지 않았음을 감지하고 다른 컴포넌트를 보여줄 수 있다. 위의 코드가 이러한 내용을 직접 구현한다면 Suspense는 이러한 내용을 컴포넌트로 추상화해주는 것이다.
아래 코드에는 ErrorBoundary도 포함되어 있는데 isError일 때 ErrorComponent를 띄워주는 부분을 컴포넌트로 추상화해준 것이다.
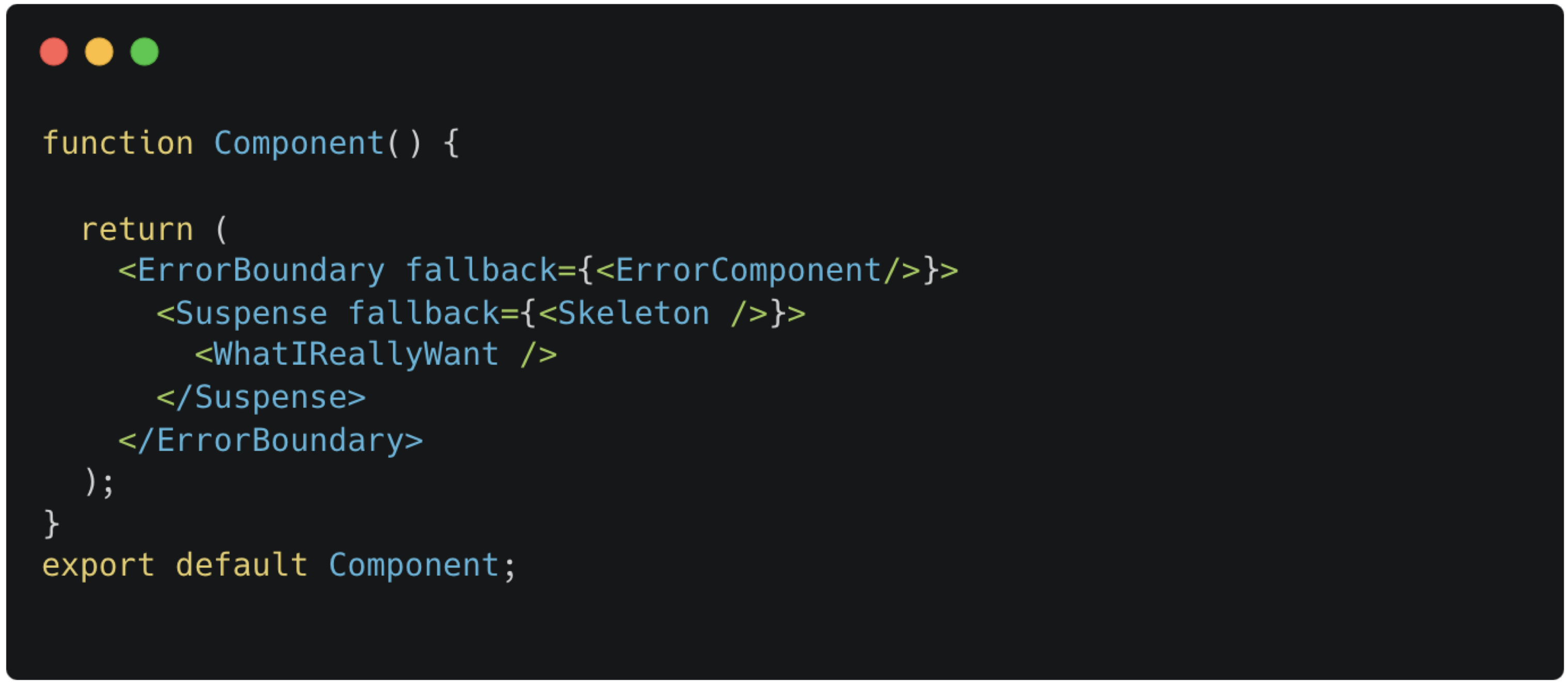
React.lazy
React 공식 문서의 예제를 살펴보자. Suspense의 자식인 OtherComponent가 React.lazy를 통해 import되었다.
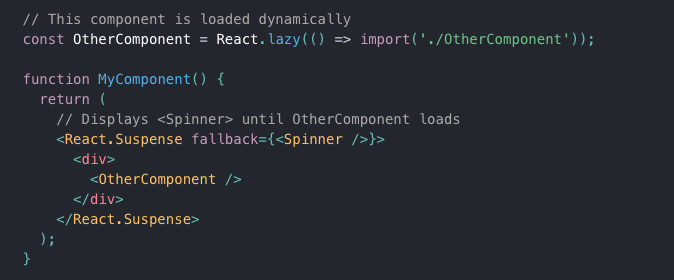
React.lazy는 dynamic import()를 호출하는 함수를 인자로 가진다. 이 함수는 React 컴포넌트를 default export로 가진 모듈 객체가 resolve되는 Promise를 반환해야 한다.
Javascript import() 표현식은 모듈을 읽고 모듈이 내보내는 것들을 모두 포함하는 객체를 담은 fulfilled 상태의 Promise를 반환한다.
내부 구현이 궁금해져 React 프로젝트에 들어가 React.lazy 함수의 코드를 뜯어보았다. 인자로 Promise를 반환하는 함수를 받아 LazyComponent 형식으로 리턴한다.
- packages/react/src/ReactLazy.js
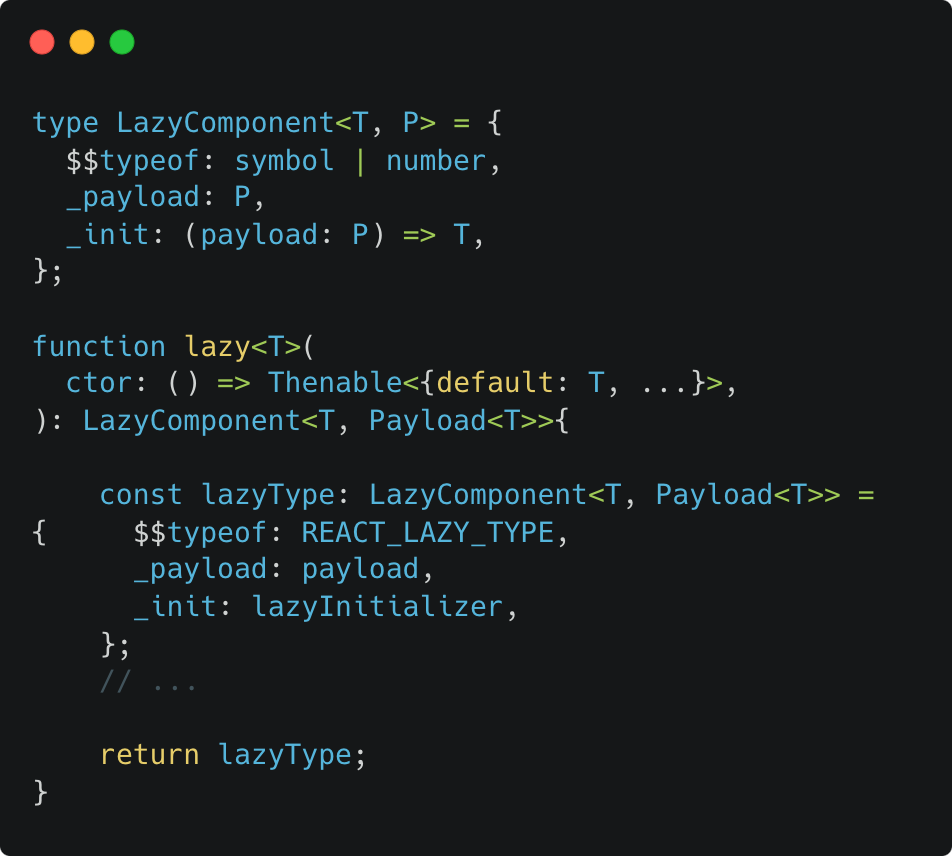
아래 코드는 실제 코드를 바탕으로 구성한 컴포넌트 렌더링 코드이다. 흐름을 보면 LazyComponent가 호출되면 init(payload), 즉 lazyInitializer({_status: Uninitialized, _result: ctor})가 실행된다.
lazyInitializer 함수는 인자로 받은 Promise ctor의 상태에 따라 moduleObject를 반환하거나 error 또는 Promise를 throw 한다.
- LazyComponent 호출
- Initializer 호출
- 객체 return 시 객체 렌더링, Promise throw 시 fallback UI 렌더링

그림으로 보면 다음과 같은 원리이다.
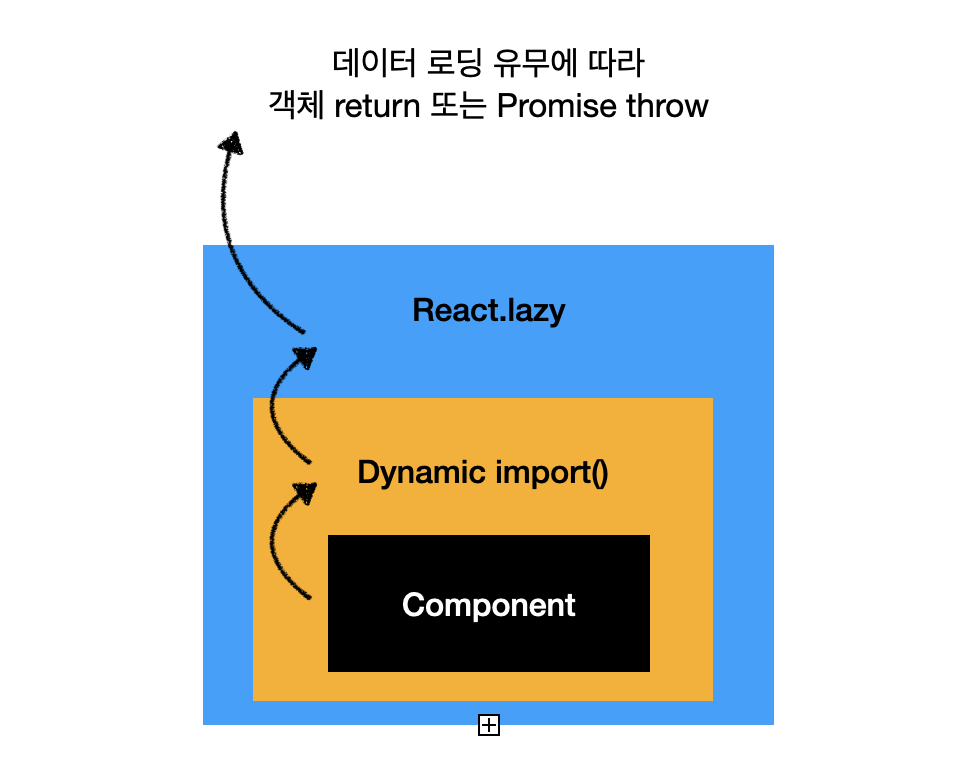
Suspense 원리
Suspense의 conceptual하게 이해할 수 있는 예제이다. 실제 내부 코드는 아니고 이해를 돕기 위한 개념적 모델 정도로 생각하면 된다. 이 글에서 가져왔다.
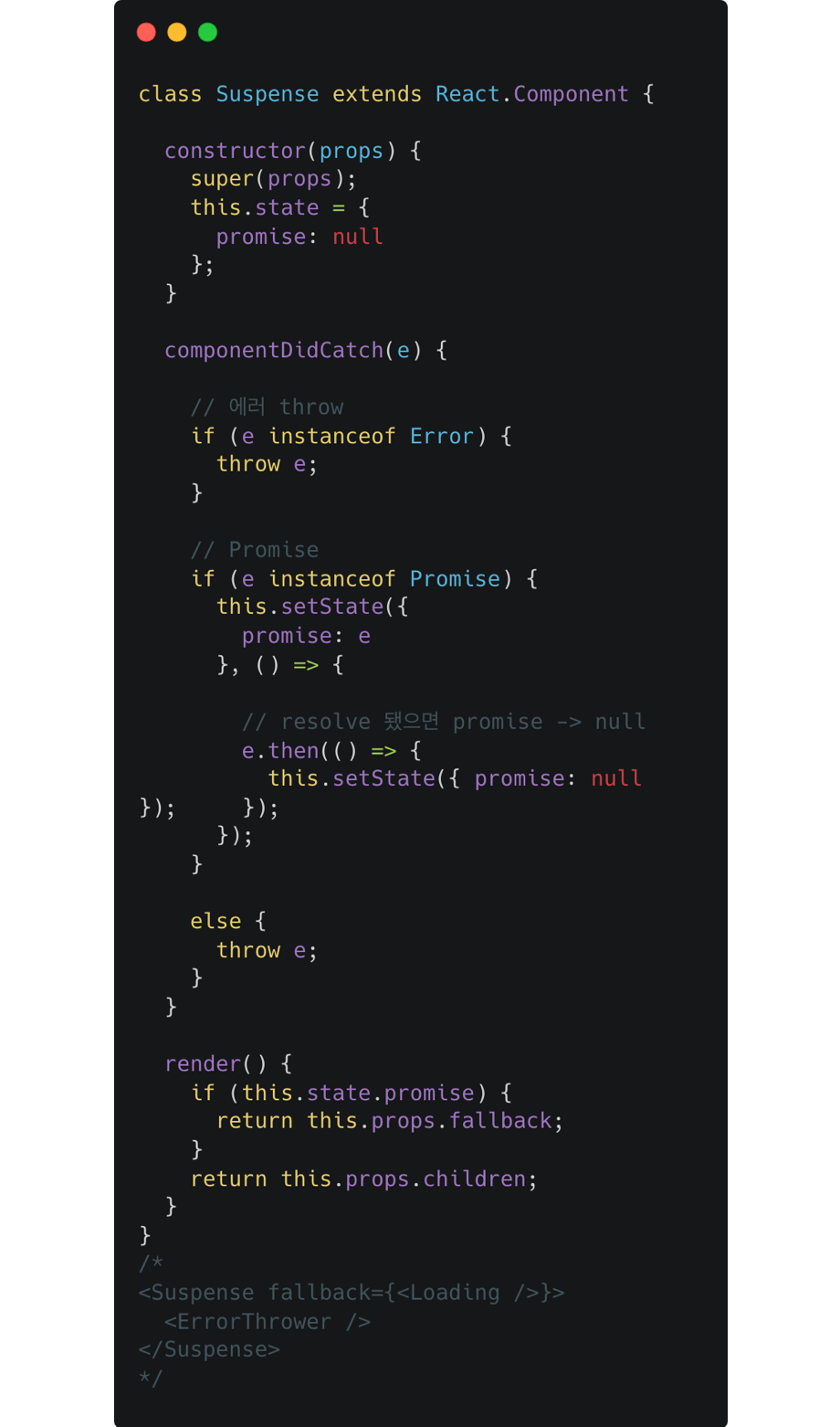
결론: Suspense의 자식 컴포넌트에서 발생하는 비동기 흐름을 감지하여 Promise의 상태에 따라 fallback UI 혹은 children을 렌더링한다.
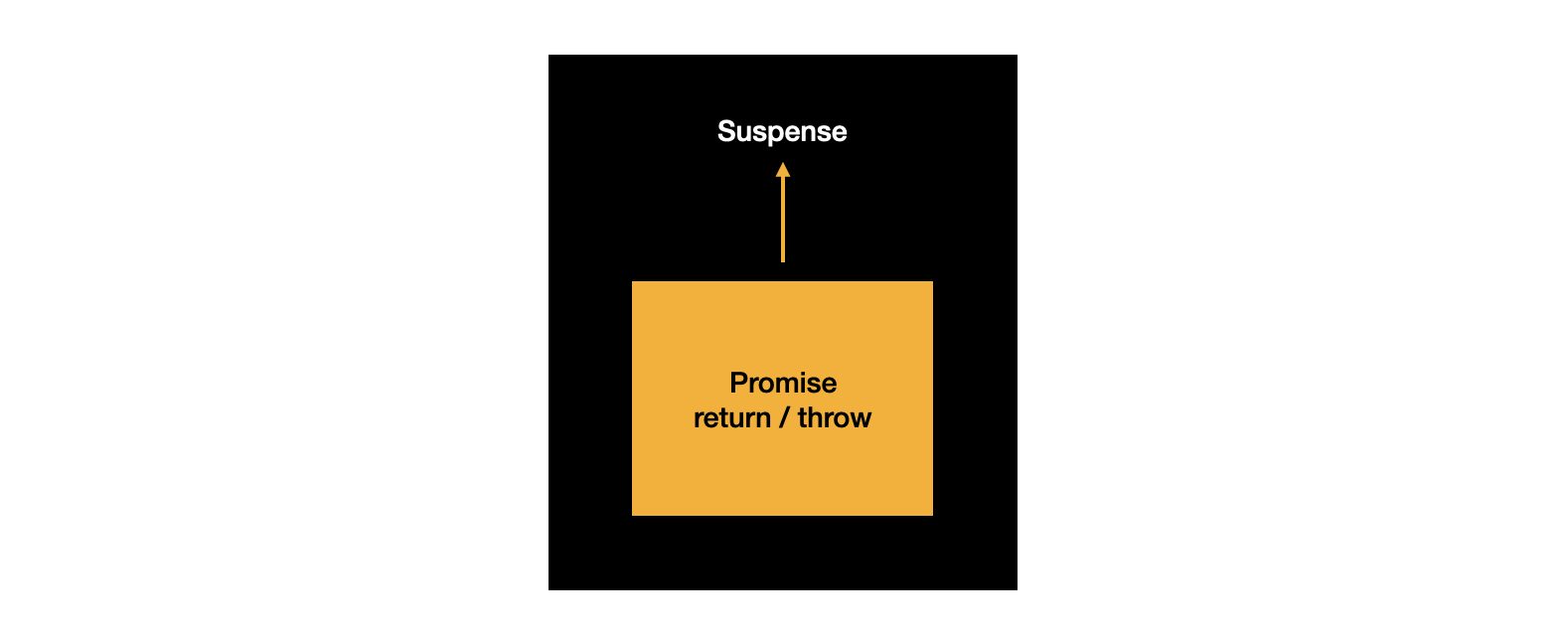
난관 1. Next.js의 Server Side Rendering
깜지는 Next.js 프레임워크로 구현되었고 다음과 같이 동작한다. 각 단계별로 이전 단계가 끝나기 전까진 다음 단계가 수행될 수 없는 waterfall한 구조를 갖고 있다.

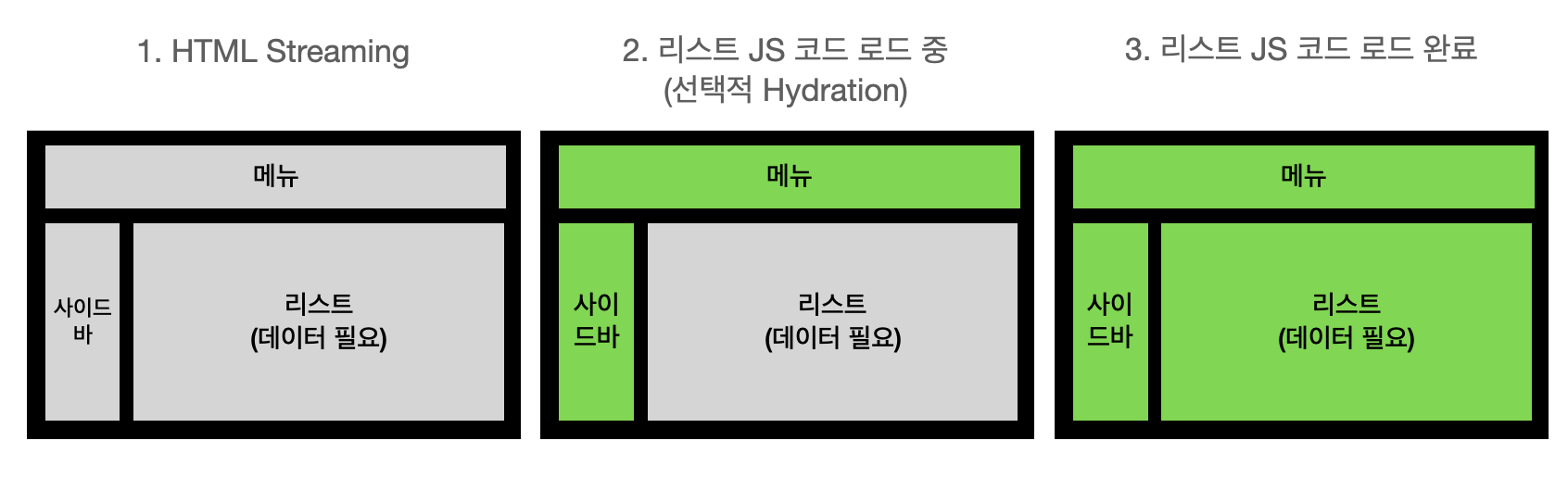
만약 다음과 같이 레이아웃이 구성되어 있다고 하자. 그림에서 회색은 HTML 스트리밍은 완료되었지만 아직은 상호작용할 수 없는 상태를, 초록색은 JavaScript의 hydration이 완료되어 상호작용이 가능한 상태이다.
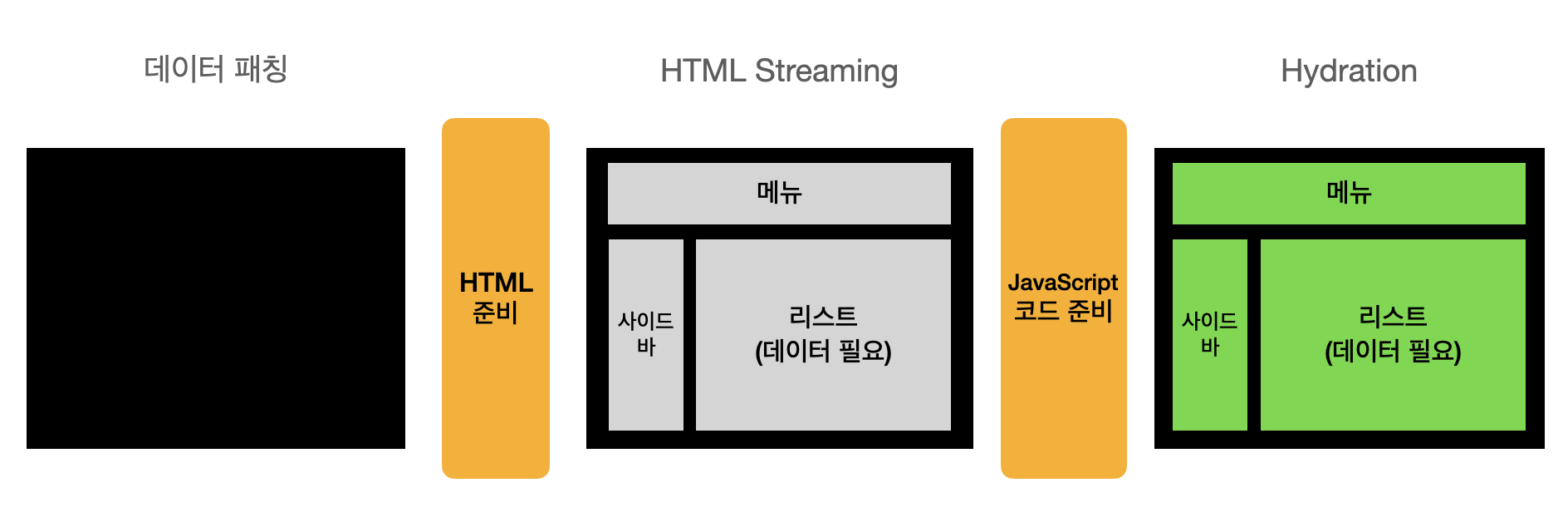
문제 1
만약 리스트 데이터가 매우 커서 응답이 지연된다면 리스트의 데이터가 준비될 때까지 모든 컴포넌트가 렌더링되지 못하고 기다리며, 사용자는 데이터가 준비되는 동안 빈 화면을 볼 수밖에 없다.문제 2
만약 리스트 컴포넌트의 JavaScript 코드가 매우 커서 응답이 지연된다면 모든 컴포넌트가 hydration 하지 못하고 기다리며, 사용자는 모든 컴포넌트에서 상호작용(ex. 메뉴 이동, 사이드 바를 통한 기능) 할 수 없다.
React에서 발표한 New Suspense SSR Architecture in React 18에서 이를 극복할 수 있는 다음과 같은 Feature들을 제공하고 있다.
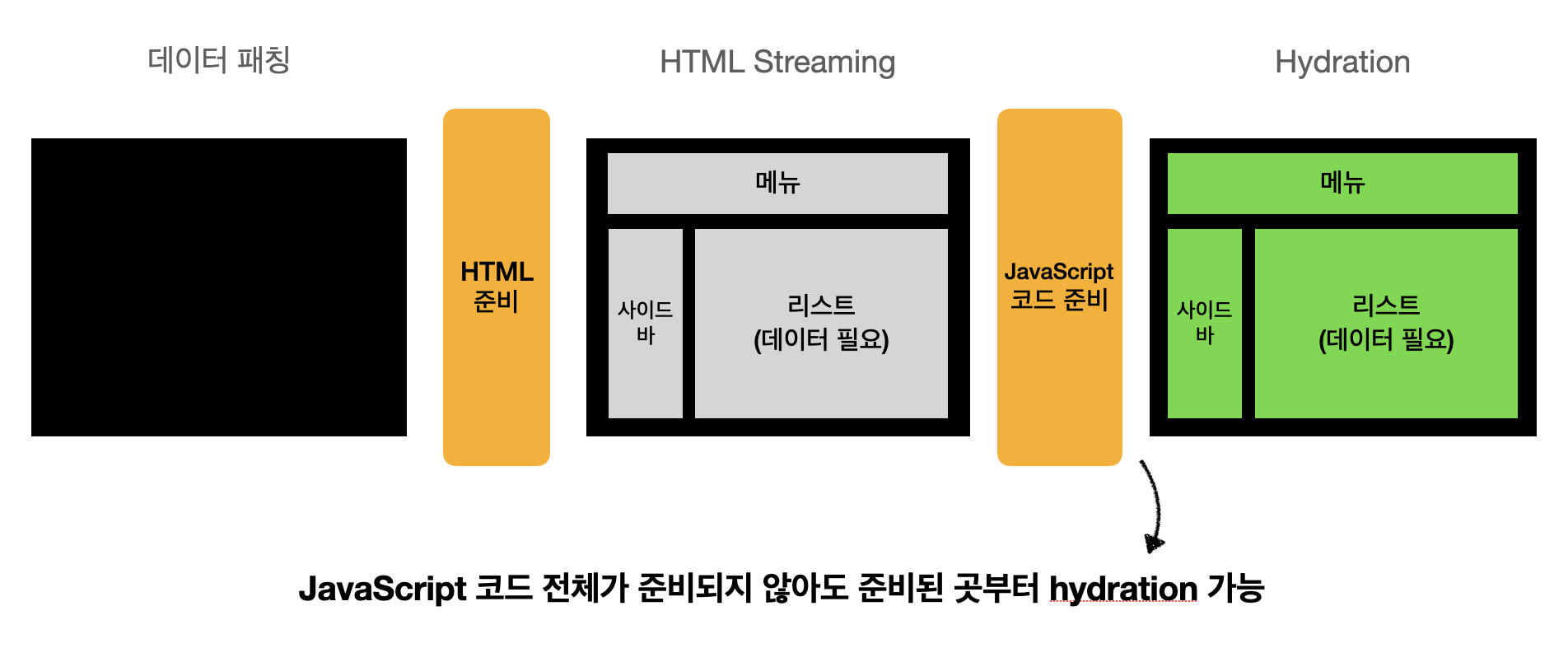
Feature 1: 모든 데이터를 불러오기 전에 HTML을 스트리밍
React 18에서 Suspense를 사용하면 데이터가 준비되기 전까지 Skeleton 컴포넌트를 보여줄 수 있다.
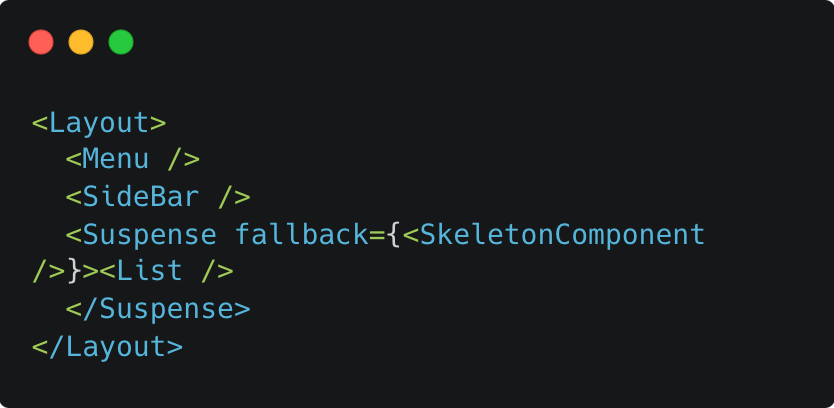
최초 HTML이 다음과 같이 구성된다. 리스트는 찾을 수 없다.
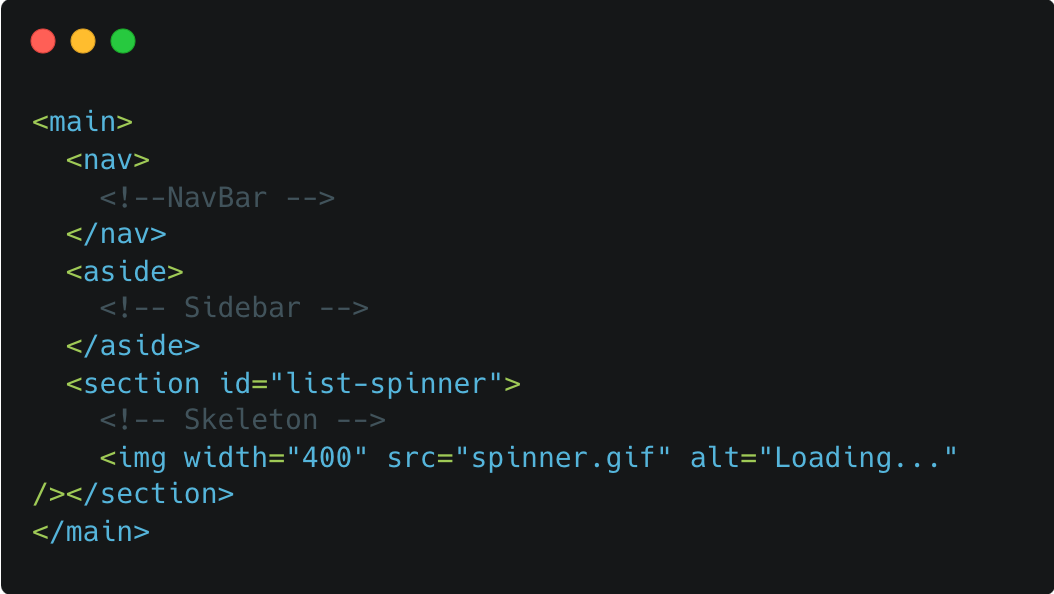
서버에서 리스트 데이터가 준비되면, React는 동일한 스트림에 추가되는 HTML과 해당하는 HTML을 "올바른 장소"에 위치시키기 위한 인라인 script를 보낸다.
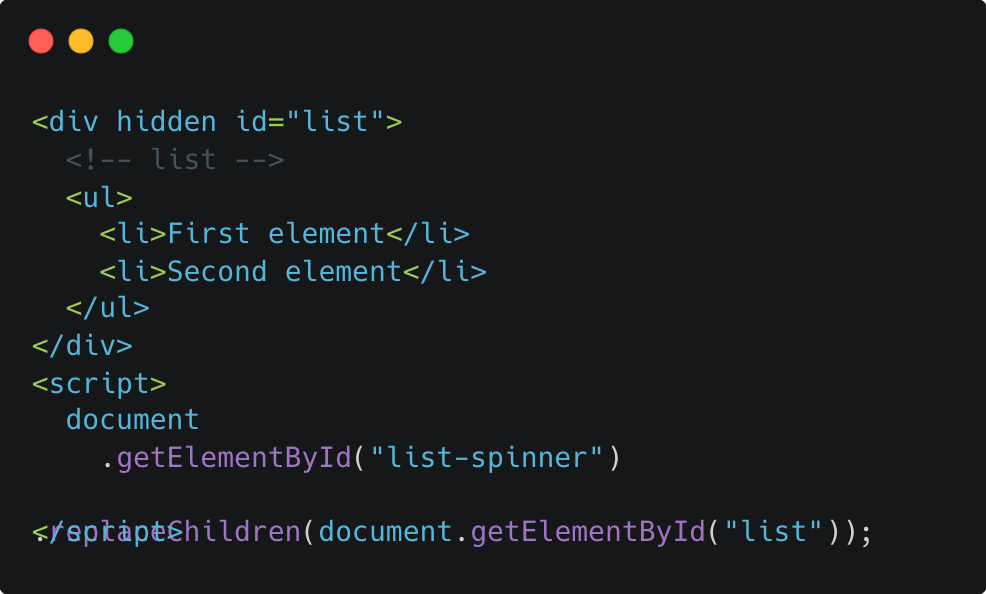
이렇게 늦게 도착한 댓글 부분의 HTML이 들어오게 되고, 사용자는 데이터가 준비되는 동안 빈화면을 볼 필요가 없어진다.
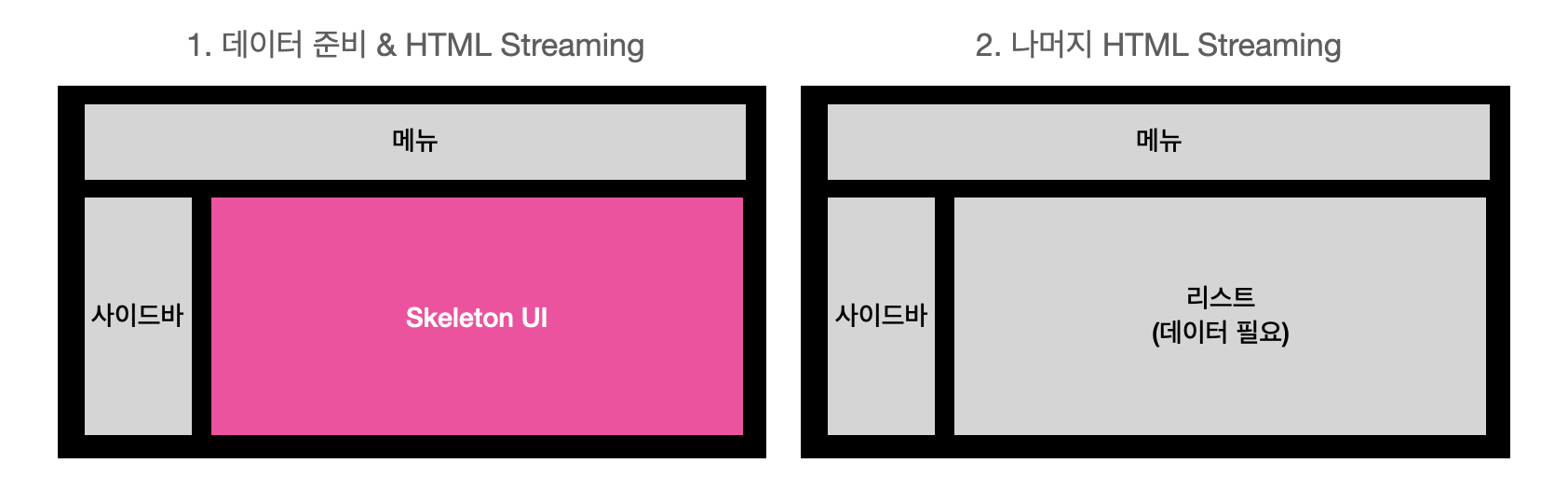
문제 1
만약 리스트 데이터가 매우 커서 응답이 지연된다면 리스트의 데이터가 준비될 때까지 모든 컴포넌트가 렌더링되지 못하고 기다리며, 사용자는 데이터가 준비되는 동안 빈 화면을 볼 수밖에 없다. -> 해결!
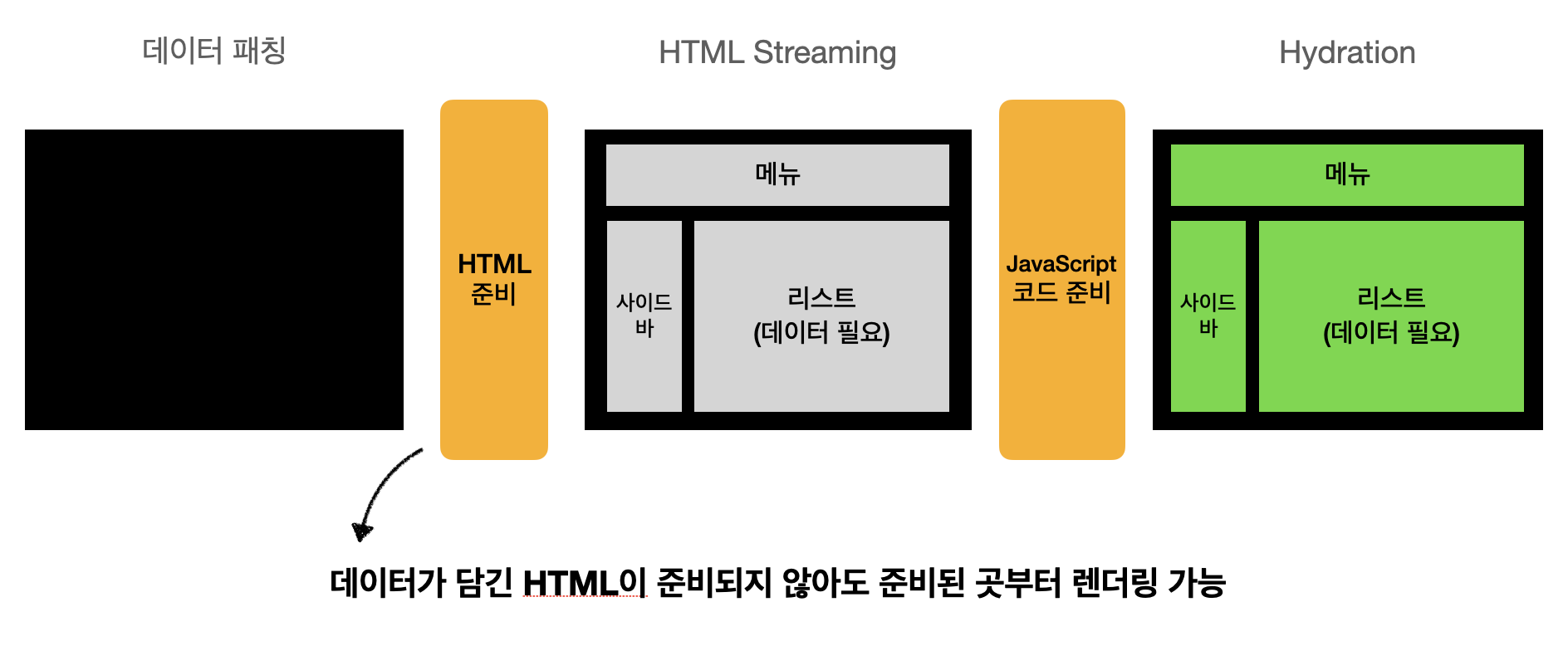
Feature 2: 코드가 모두 불러와지기 전에 페이지 hydrating
최초 HTML을 더 이른 시점에 보낼 수 있지만, 리스트를 위한 JavaScript 코드가 로딩되기 전 클라이언트상에서 애플리케이션을 hydration 할 수 없다. 다른 요소의 JS 코드보다 리스트를 위한 JS 코드가 훨씬 무겁다고 가정한다면, 리스트의 JS 코드가 로드되기 전까지 다른 모든 요소의 상호작용이 Block되는 것은 사용자에게 나쁜 경험을 줄 것이다.
Code splitting을 사용하면 이 부분을 해결할 수 있다. 특정 코드의 부분이 동기적으로 로드될 필요 없다고 명시해주면, 번들러가 별도의 <script> 태그로 분리해준다. 말 그대로 코드를 분할 로딩하여 사용자가 느끼기에 로드 속도가 빨라지도록 하는 것이다. 앞에서 이야기했던 React.lazy로 이를 적용시킬 수 있다.
Next.js에서는 Dynamic Import로 Code splitting을 지원하고, 이는 React.lazy의 extension이라고 공식 문서에서 이야기 하고 있다.
결론적으로 다음과 같이 선택적 Hydration이 가능해진다.
문제 2
만약 리스트 컴포넌트의 JavaScript 코드가 매우 커서 응답이 지연된다면 모든 컴포넌트가 hydration 하지 못하고 기다리며, 사용자는 모든 컴포넌트에서 상호작용(ex. 메뉴 이동, 사이드 바를 통한 기능) 할 수 없다. -> 해결!
더 자세한 몇몇 Feature에 대해서는 'New Suspense SSR Architecture in React 18'을 번역한 이 글에 자세히 나와있다.
난관 2. 기존 컴포넌트의 재사용 구조 사용 불가
기존 QuizList 컴포넌트의 구조는 다음과 같다. 전체 퀴즈, 내가 낸 퀴즈, 좋아요한 퀴즈 리스트의 형태가 모두 같기 때문에 부모 컴포넌트에서 QuizSummary 형식의 데이터를 내려주고 QuizList 컴포넌트가 props를 받아서 쓰고 있었다.
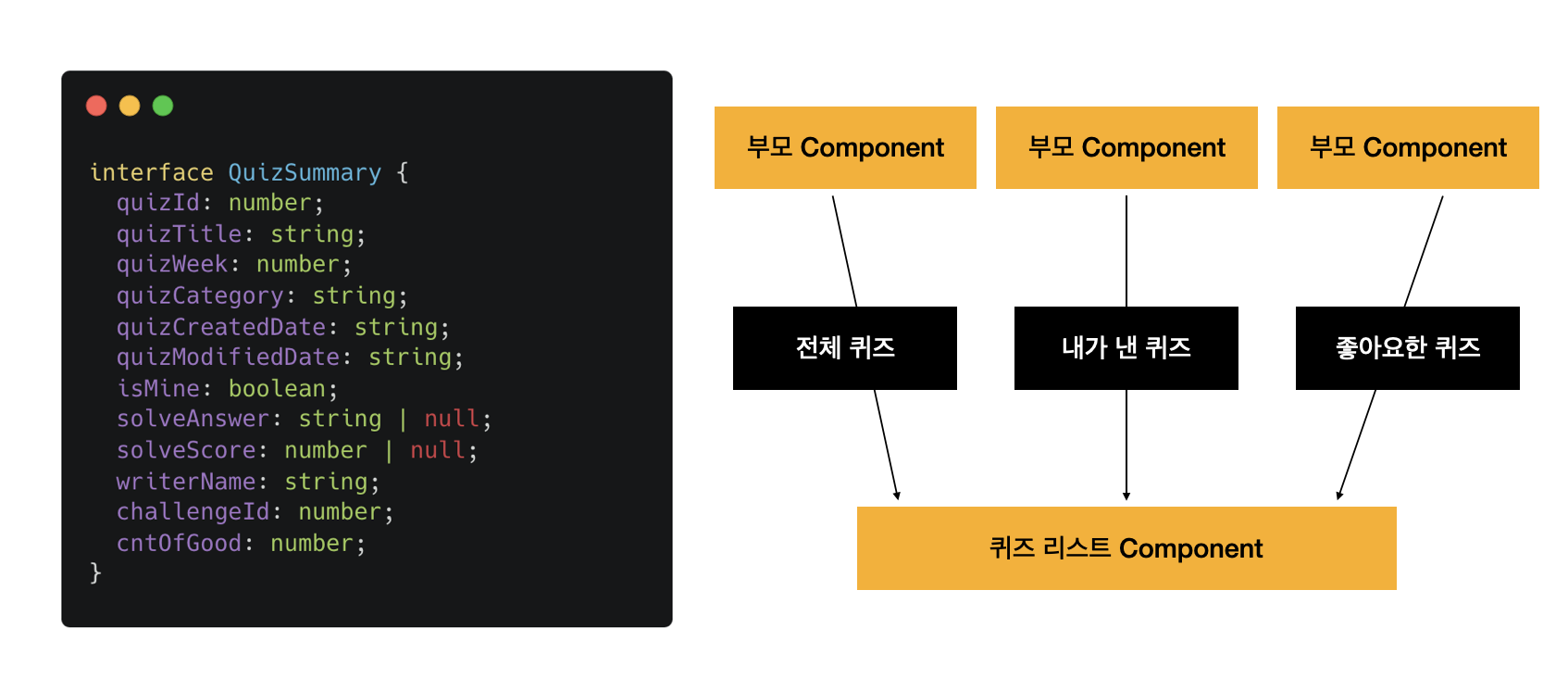
이 구조는 Suspense의 동작원리와 충돌한다. 앞에서 이야기했듯, Suspense는 자식에서 발생하는 비동기 흐름을 감지하여 fallback UI 혹은 children을 렌더링한다. 하지만 데이터를 부모에서 내려주게되면 데이터에 대한 비동기 요청-응답을 감지할 수 없다.
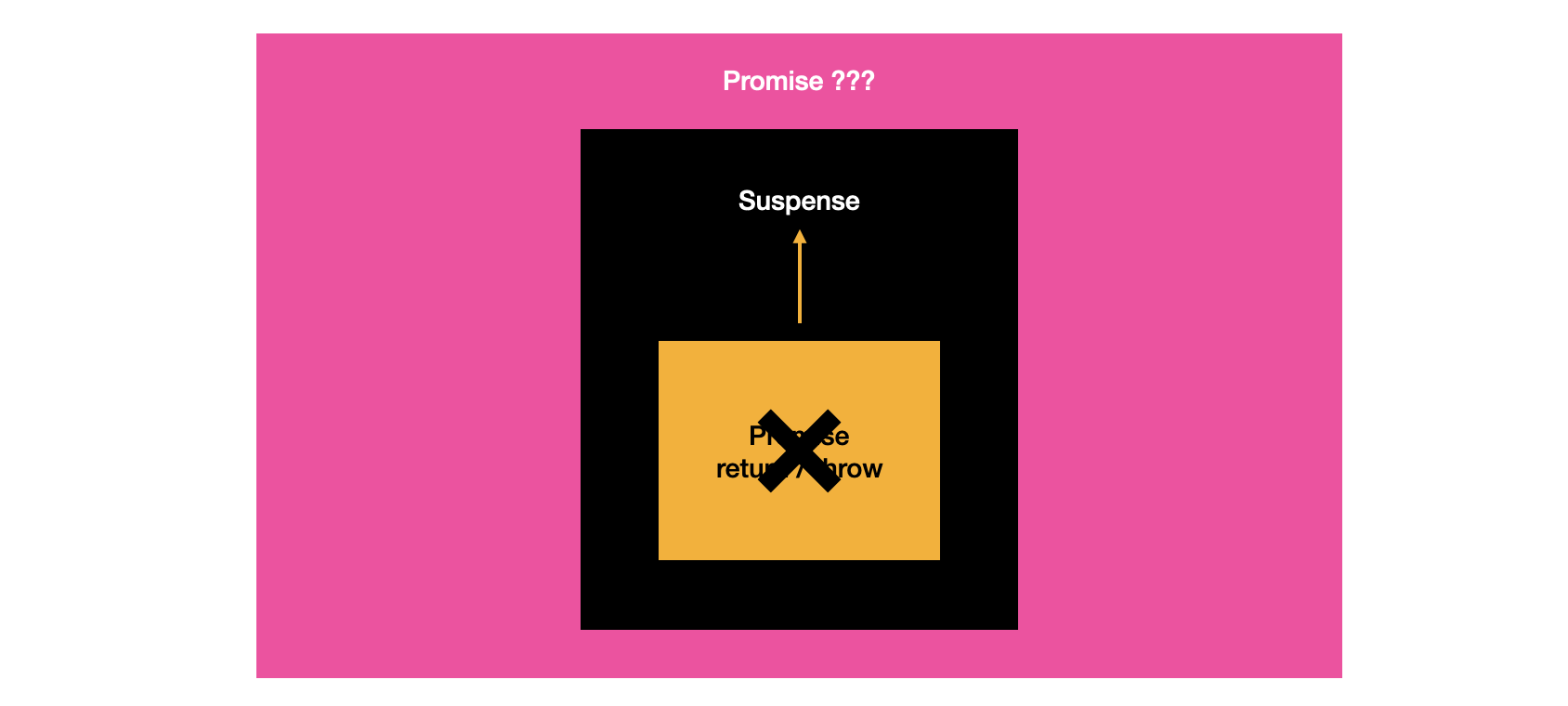
그래서 다음과 같은 구조를 고안했다. 퀴즈 리스트 컴포넌트에서 모든 퀴즈 데이터를 불러오고 상황에 맞게 데이터를 가지고 와서 렌더링하는 것이다. 물론 React Query를 사용하면 알아서 fetching 해주니까 상관없지만... 내가 낸 퀴즈만 보고 싶은데 전체 퀴즈까지 가져오면 부하가 심할 것으로 예상됐다.

해결 방법: Query Hook으로 분기 처리
퀴즈 리스트 컴포넌트에서 데이터를 불러오되 상황에 따라서 불러오게 하기로 결정했다. React Query options의 enabled 속성으로 컴포넌트 안에서 처리할 수도 있었지만, 관리자가 낸 문제, 푼 문제 등... 해당 컴포넌트의 확장성이 매우 높기 때문에 코드의 가독성과 유지보수성을 높이기 위해 데이터 요청 부분을 hook으로 분리했다.
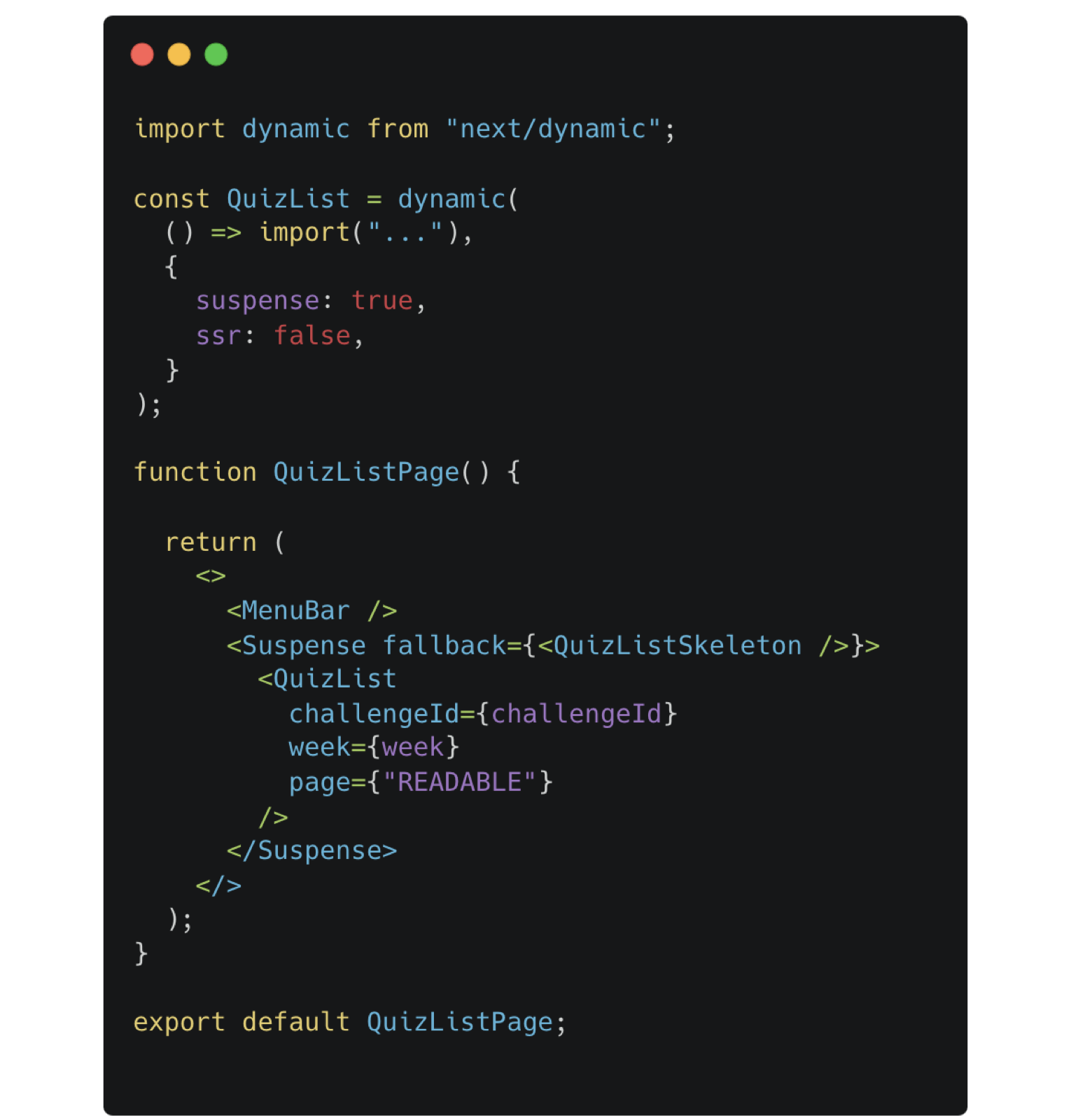
퀴즈 리스트의 부모에서 어떤 데이터를 불러오고 싶은지 page로 인자를 넘겨준다.
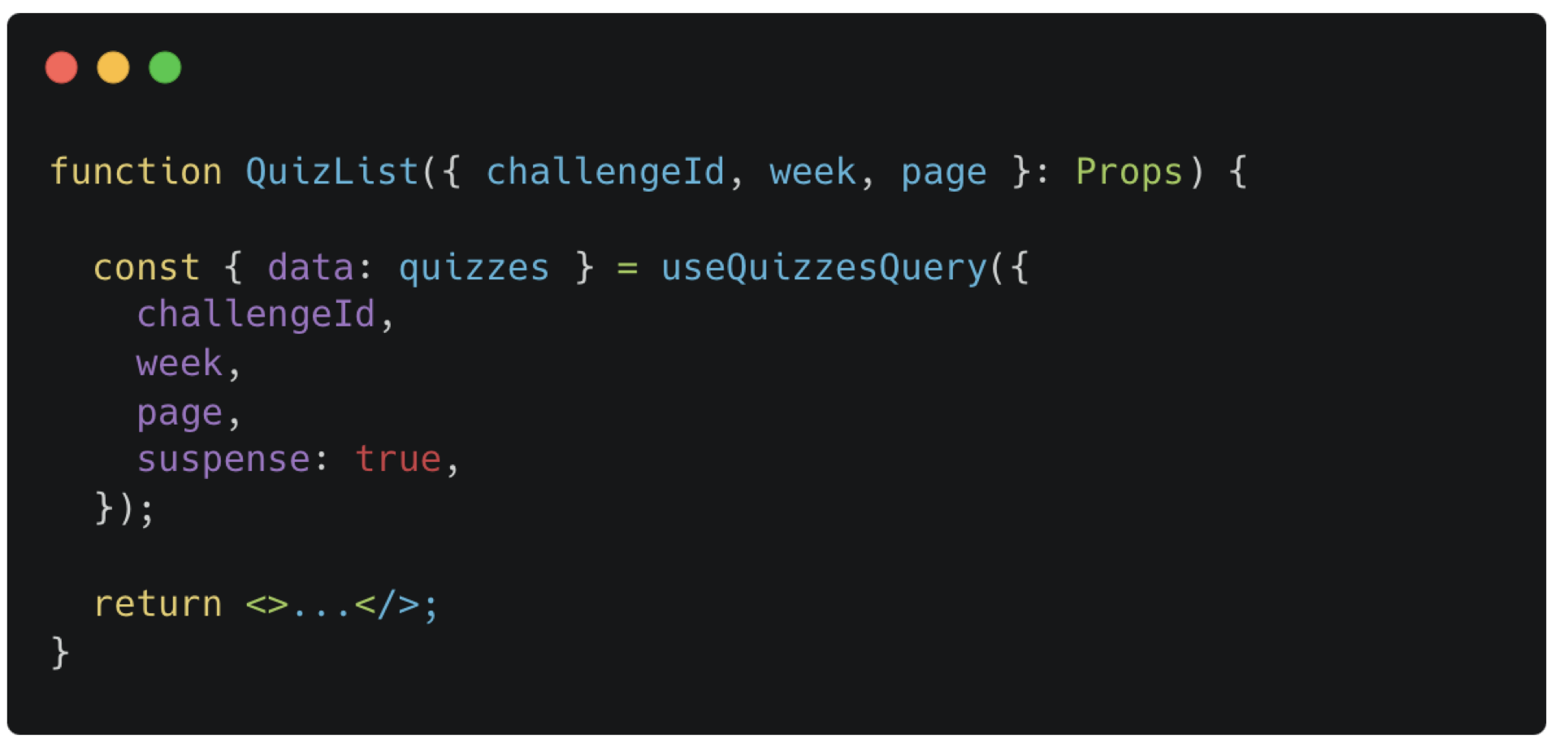
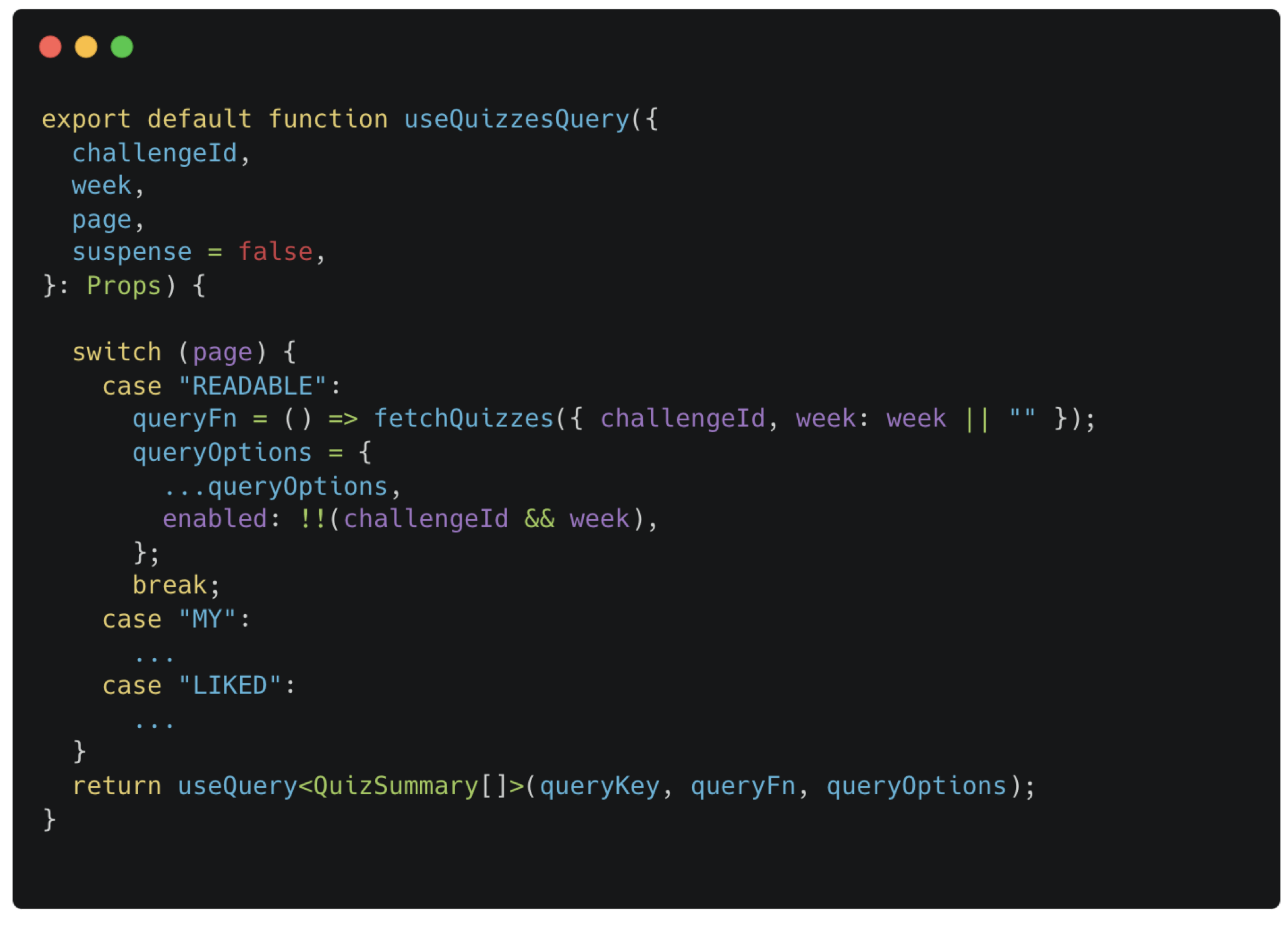
Hook에서는 넘겨받은 page에 따라 다른 fetch 함수를 호출하여 데이터를 가져온다.
마무리
Skeleton UI에 관한 기술 블로그 포스트를 보고 우리 서비스에 적용하면 좋겠다 싶어 시작해본 공부인데 파고 파다보니 분량이 꽤나 늘어났다.
공부하는 중에 콴다 팀 블로그에 작성된 양질의 Suspense 시리즈 글을 봤는데 훨씬 딥한 내용을 다루고 있어 이 부분을 더 공부해보려고 첨부해놓는다. (마치 다이어트 하기 전에 주변에 선포하듯...)
- Conceptual Model of React Suspense
- Algebraic Effects of React Suspense
- Suspense SSR Architecture in React 18
실제 React 코드들을 뜯어보는 건 처음이었는데 생각보다 어렵지 않고 재밌었다. 처음 봤을 때는 이게 뭐지 싶었는데 각잡고 찬찬히 읽어보니 어느정도 이해가 됐다. 양이 워낙 방대해서 구조를 완벽하게 파악할 수는 없었지만 Suspense와 React.lazy가 어떤 구조로 연결돼있는지 알 수 있어서 이해에 한층 도움이 되었다.
어떻게 마무리 하지...

앞으로도 열심히 하자..!

좋은 내용 잘 봤습니다!