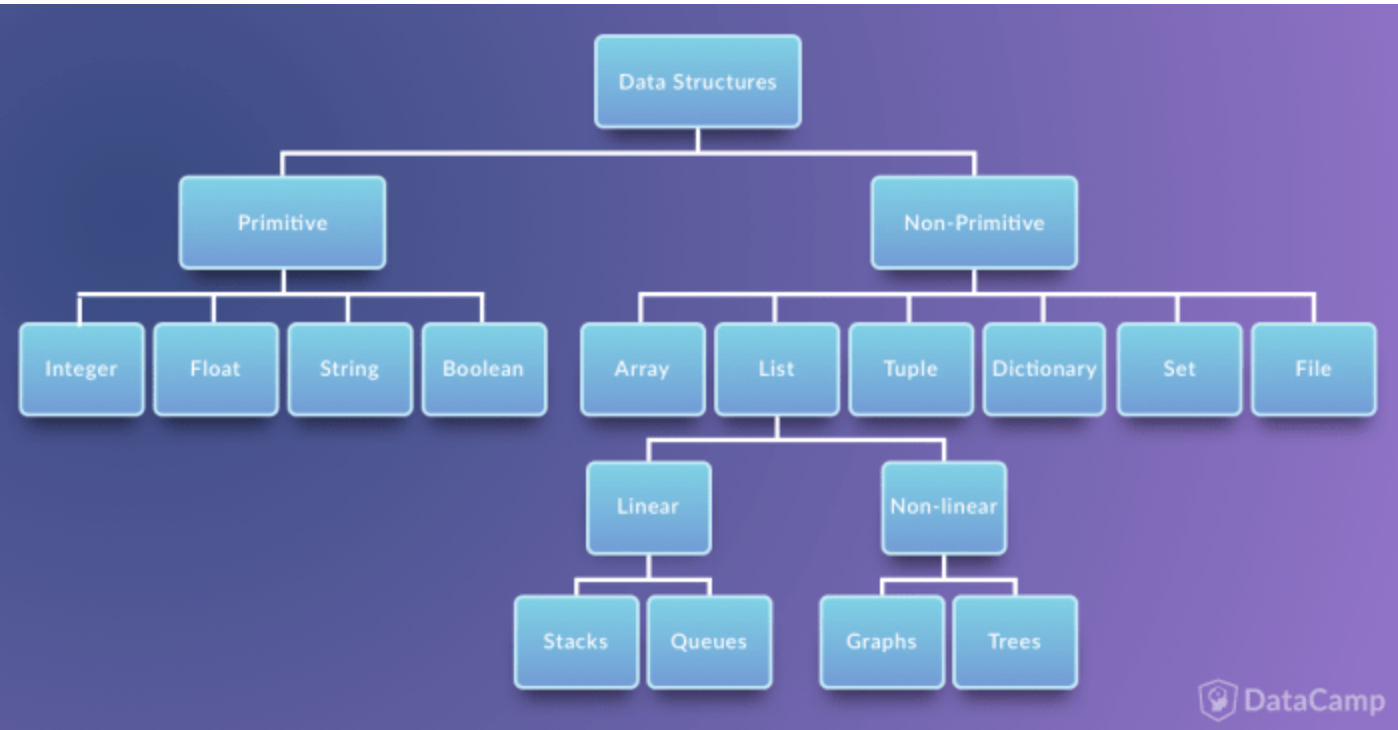
1. 자료 구조란?
- 자료구조 란 데이터에 편리하게 접근하고, 변경하기 위해서 데이터를 저장하거나 조직하는 방법 을 말합니다. 모든 목적에 맞는 자료구조는 없습니다.
- 따라서 각 자료구조가 갖는 장점과 한계를 잘 아는 것이 중요합니다.
- 자료구조는 언어별로 지원하는 양상이 다릅니다. 따라서 각각의 언어가 가진 자료구조의 사용방법도 중요하지만, 무엇보다 각 자료구조의 본질과 컨셉을 이해하는 것 이 중요합니다.
- 개념을 이해 한다면 해당 언어에 맞추어서 사용하기만 하면 됩니다.
2. 배열
Array는 가장 기초적이고 단순하면서도 가장 자주 사용되는 자료구조 (data structure) 입니다. 여러분들도 이미 많이 사용해 보신 자료구조 일겁니다.
Array의 특징
- Array의 가장 큰 특징은 순차적(ordered)으로 데이터를 저장한다는 점입니다. 자료구조에 저장하는 데이터는 일반적으로 요소(element)라고 합니다). Array는 주로 서로 연결된 데이터들을 순차적 으로 저장할때 사용합니다. 순서가 상관 없더라도 서로 연결된 데이터들을 저장할때 일반적으로 사용됩니다. 그래서 array가 가장 자주 사용되는 자료구조중 하나가 되는 것입니다.
Array의 다른 특징들
- 삽입(insertion) 순서대로 저장된다. (즉, 새로 삽입되는 요소는 array의 새로운 꼬리가 된다)
- 이미 생성된 리스트도 수정 가능하다(mutable).
- 동일한 값도 여러번 삽입 가능하다.
Array의 내부 구조
- Array가 순차적으로 데이터를 저장할 수 밖에 없는 이유가 있습니다. 그건 바로 실제 메모리 상에서 순차적으로 저장되기 때문입니다.
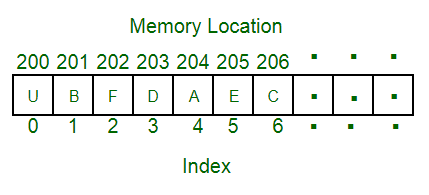
이렇게 순서가 있다보니 당연히 순차적으로 번호를 지정할 수 있습니다. 마치 학교에서 이름을 부르지 않고 번호를 불르는 것과 동일한 개념입니다. 이 번호를 index 라고 합니다.
Index는 0부터 시작됩니다. Index는 마이너스 부호를 가질 수 도 있습니다. 마이너스 index는 맨 마지막 요소 부터 시작합니다. 예를 들어, -1 은 맨 마지막 요소 입니다.
Indexing
순서가 있음으로 index가 있고 index가 있음으로 index를 사용해서 특정 요소를 array(list)로 부터 읽어들일 수 있습니다.
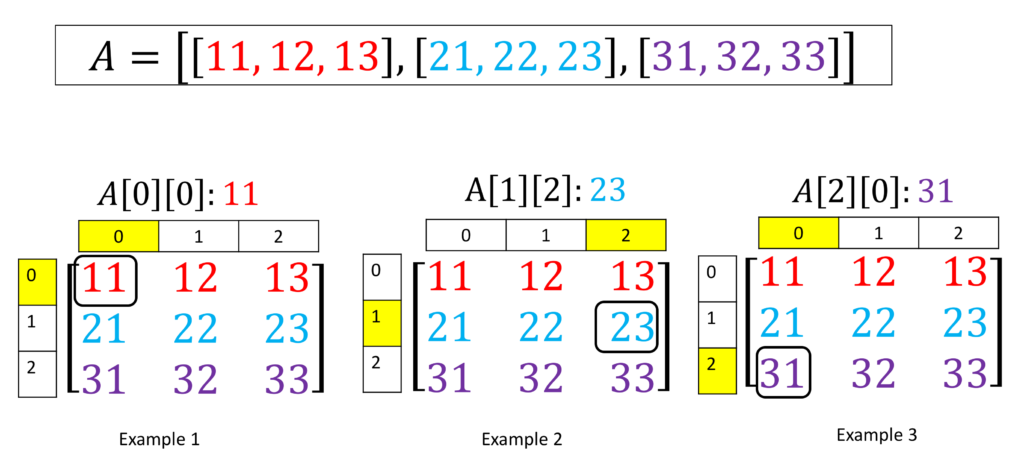
Multi Dimentional Array
Array의 요소가 array가 될 수 있습니다. 이러한 array를 다중차원(multi-dimentional) array라고 합니다. 일반적으로 2D (2차원) array가 많이 사용됩니다. (좌표,바둑 등등)
Array의 단점
앞서 본대로 Array는 메모리의 실제 주소도 순차적으로 되어있습니다. 그럼으로 indexing이 가능한 것을 비롯하여 여러 장점이 있지만 반대로 단점도 있습니다.
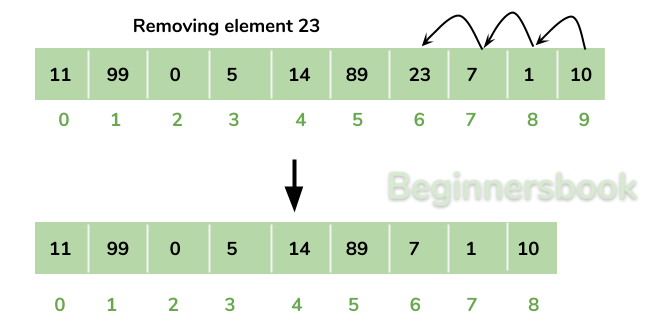
Removing Elements
항상 메모리가 순차적으로 이어져있어야 하기 때문에, 요소를 삭제하면 삭제된 요소로 부터 뒤에 있는 모든 요소들을 앞으로 한칸씩 이동시켜주어야 합니다. 이뜻은 배열에서 요소를 삭제하는 것은 다른 자료구조들에 비해 느릴 수 있다는 뜻입니다.
Inserting elements at the begining of the array
요소 삭제와 마찬가지의 이유로 배열의 맨 앞에 요소를 삽입 하는 것은 상대적으로 느린 operation 입니다.
Array Resizing
배열은 메모리가 순차적이어야 하다보니 배열이 처음 생성될때 어느정도 메모리를 미리 할당해놓습니다. 이를 전문 용어로 pre-allocation 한다 합니다. 메모리를 pre-allocation 함으로 새로 추가되는 요소들도 순차적으로 메모리에서 저장을 가능하게 합니다.
하지만 만일 처음에 잡아놓은 메모리 이상으로 요소들이 많아지면 resizing을 해야합니다. 즉 메모리를 더 할당해야 합니다. 그리고 추가적으로 할당된 메모리 또한 순차적이여야 합니다. 그럼으로 배열의 resizing은 상대적으로 시간이 오래걸리는 operation 입니다.
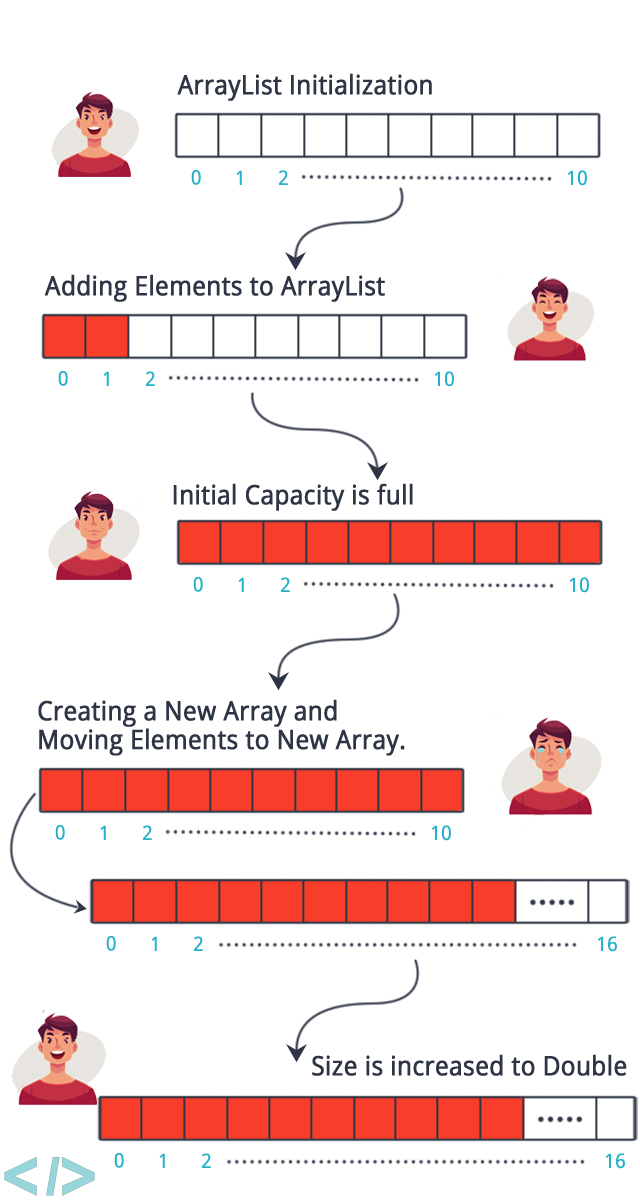
일반적으로 대부분의 언어에서는 배열의 메모리 pre-allocation과 resizing을 자동으로 실행해줍니다. 하지만 이러한 점을 알고 있어야 사이즈가 급격하게 자주 늘어날 확률이 있는 데이터는 array 말고 더 적합한 자료구조를 선택해야 한다는 것을 알 수 있는것입니다.
When To Use Array
순차열적인 데이터를 저장할때
어떠한 특정 요소를 빠르게 읽어야 할때
데이터의 사이즈가 급변하게 자주 변하지 않을때
그리고 요소를 자주 삭제해야 하지 않을때
3. Tuple
- List와 마찬가지로 데이터를 순차적으로 저장할 수 있는 순열 자료구조.
- 하지만 list와 틀리게 수정 할 수 없다 (immutable)
- 주로 2나 3개 정도의 소규모 데이터를 저정할 때 쓰입니다,
- 함수에서 리턴 값을 한개 이상 리턴 하고 싶을때 자주 쓰입니다.
추후 js코드로 정리 Tuple Is Not For Every Language
- Python 은 tuple이 있고 JavaScript는 없습니다.
- 그렇다고 Python > JavaScript 는 아닙니다. 다만 JavaScript에서는 tuple을 굳이 따로 안만든것 뿐입니다.
When To Use Tuple
Array나 list를 쓰기에 너무 간단한 데이터들을 표현할때.
Tuple이 list보다 더 가볍고 메모리더 적게 먹는다.
예를 들어, 좌표 데이터:
coordinations = [
(1, 2),
(3, 4),
(5, 6)
]4. Set
Set는 array나 list 처럼 순열 자료구조 (collection) 입니다.
하지만 set는 순서라는 개념이 존재하지 않습니다. Set의 특징은 다음과 같습니다.
- 데이터를 비순차적(unordered)으로 저장할 수 있는 순열 자료구조 (collection).
- 삽입(insertion) 순서대로 저장되지 않는다. 즉 특정한 순서를 기대할 수 없는 자료구조.
- 수정 가능하다(mutable).
- 동일한 값을 여러번 삽입 불가능하다. 동일한 값이 여러번 삽입 되면 하나의 값만 저장된다.
- Fast Lookup이 필요할때 주로 쓰인다.
추후 정리Set의 구조
enter image description here
- Array와 달리 set은 요소들을 순차적으로 저장하지 않습니다.
- Set에서 요소들이 저장될 때 순서는 다음과 같습니다.
1. 저장할 요소의 값의 hash 값을 구한다.
2. 해쉬값에 해당하는 공간(bucket)에 값을 저장한다. - 이렇게 set는 저장하고자 하는 값의 해쉬값에 해당하는 bucket에 값을 저장하기 때문에 순서가 없다. 순서가 없기 때문에 indexing도 없다.
- 그리고 해쉬값 기반의 bucket에 저장하기 때문에 중복된 값을 저장할 수 없는것이다.
- 해쉬값을 기반으로 저장하기 때문에 look up 이 굉장히 빠름.
- Look up: 특정 값을 포함하고 있는지를 확인 하는것 ==>5 in my_set
- Set의 총 길이와 상관없이 단순히 해쉬값 계산 후 해당 bucket을 확인하면 됨으로 O(1)hash는 단방향 (one way) 암호화 입니다. 단방향이란 한번 암호화 하면 복호화가 안된다는 뜻입니다. 실제 값의 길이와 상관없이 hash 값을 일정한 길이를 가집니다. 그럼으로 Hash는 주로 임의의 길이를 갖는 임의의 데이터에 대해 고정된 길이의 데이터로 매핑할때 사용됩니다.
#### When To Use Set
- 중복된 값을 골라내야 할때
- 빠른 look up 을 해야 할때(비열이면 하나하나 접근해서 키를 비교 하지만 Set에서는 찾고자 하는값이 있을때 해시값을 구해서 바로 접근하면 가능하니까 )
- 그러면서 순서는 상관 없을때
# 5.Dicitonary/ HashMap/HashTable
Dictionary (다른 언어에서는 hashmap 이나 hash table이라고 하기도 함)는 Key-value 형태의 값을 저장할 수 있는 자료구조 입니다. 이름은 "정우성" 등 실제 데이터 값과 데이터를 설명하는 key의 대응 관계를 표현할때 유용합니다.
Dictionary의 특성은 다음과 같습니다.
- Set과 마찬가지로 특정 순서대로 데이터를 리턴하지 않는다.
- Key의 값은 중복될 수 없다. 만일 중복된 key 가 있으면 먼저 있던 key와 value를 대체한다.
- 수정 가능하다(mutable).
```js
추후정리 Dictionary의 내부 구조
enter image description here
- Set와 비슷하게 key 값의 해쉬값을 구한 후 해쉬값에 속해있는 bucket에 값을 저장한다.
- 그럼으로 set와 마찬가지로 순서가 없고 중복된 key 값은 허용 되지 않는다.
When To Use Dictionary
- 마치 데이터베이스 처럼 키와 값을 묶어서 데이터를 표현해야 할때 유용하다. 실제로 데이터베이스 에서 읽어들인 값을 dictionary로 변환해서 사용 자주 함.
6.Stack Queue
Stack과 Queue는 비슷한 구조인데 자료를 읽어들이는 순서가 틀립니다.
Stack
Stack은 LIFO(Last In First Out) 이라고 합니다. 마지막으로 저장한 데이터가 처음으로 읽힌다는 뜻입니다. 마치 설겆이 한 접시를 하나 하나 쌓아올리는걸 생각하시면 쉽습니다.
enter image description here
- Stack에서 데이터 저장은
push라고 합니다. - 데이터를 읽어들이는 건
pop이라고 합니다. 다만pop은 읽어들임과 동시에 stack에서 삭제합니다.
리스트를 사용한 stack 구현 예제추후정리
### When to use stack
- 프로그램에서 함수 호출 기록을 stack으로 저장합니다. 그래서 StackOverflow 에러 라는것도 있는겁니다. 이 사이트도 stack overflow 이죠.
- Web browser 내역 혹등 내역인데 최신 내역이 먼저 나와야 하는 경우
### Queue
Queue는 Stack과 반대로 FIFO(First In First Out) 입니다. 즉 먼저 push 된게 먼저 pop 된다는 말입니다.
enter image description here
일반적인 queue 말고도 double ended queue, priority queue 등도 있습니다.
### 리스트를 사용한 Queue 구현 예제
```js
추후정리 When to use queue
- 맛집 예약 시스템
- OS 프로세스 스케쥴링 시스템 (priority queue 사용)
7. Tree
Tree 자료구조는 데이터를 마치 나무(거꾸로된) 형태로 저장하는 자료 구조 입니다. Tree 자료구조는 여러 유형이 있지만 그 중 가장 기본은 binary tree(이진 트리) 자료구조 입니다. 이진 트리는 두개의 자식 노드를 가진 트리 형태입니다.
Node: 트리 구조의 교점입니다. Node가 데이터를 가지고 있고 또한 자식 노드를 가지고 있습니다. 트리 자료구조는 노드를 기본으로 구성된다고 보시면 됩니다.Root Node: 트리 구조의 가장 위 노드, 즉 시작점이 되는 노드 입니다.
Tree 구조는 데이터의 저장의 의미 보다는 저장된 데이터를 더 효과적으로 탐색 하기 위해서 사용됩니다.
이진 트리는 앞서 언급한대로 각 노드가 최대 2개의 자식 노드를 가질 수 있습니다. 이 2개의 노드를 left node 그리고 right node라고 합니다. left node는 부모 node의 값 보다 적은 값이 저장되고 right node는 같거나 큰 값을 저장합니다.
예를 들어, [21, 28, 14, 32, 25, 18, 11, 30, 19, 15] 를 이진 트리로 저장하면 다음 그림과 같습니다.
이진 트리는 검색을 효율적으로 할 수 있습니다. 원하는 값을 찾을 때까지, 현재 node의 값이 원하는 값보다 크면 왼쪽으로, 작으면 오른쪽 으로 움직이면 됩니다.
그럼으로 일반 list는 검색이 O(N)인데에 비해 이진 트리는 O(log N) 이므로 리스트 보다 검색이 훨씬 효율 적입니다.
