Intro
SSM은 트랜스포머와 RNN과 마찬가지로 정보의 시퀀스를 처리한다.
subset of existing representations, namely linear invariant (or stationary) systems
딥러닝의 문맥에서 SSM은 선형 불변 (or 정상) 시스템의 하위 집합을 의미한다.
논문 Efficiently Modeling Long Sequences with Structured State Spaces에서 좋은 성능을 보여줘서 Transformers에 대한 대안으로 주목받았다.
Attention is all you need 논문에서 Transformer의 기초를 다뤘듯이, S4는 새로운 유형의 신경망 아키텍처의 기초가 된다. (S4: 딥러닝 상태 공간 모델의 기반)
Definition
상태 공간
: 시스템을 완전히 설명하는 최소한의 변수들을 포함한다. 시스템의 가능한 상태들을 정의하여 문제를 수학적으로 표현하는 방법이다.
더 간단히 설명하자면, 미로를 탐색한다고 생각했을 때 상태 공간은 모든 가능한 위치(상태)의 지도이다. 각 지점은 미로의 고유한 위치이고, 출구까지의 거리와 같은 세부 정보를 포함한다.
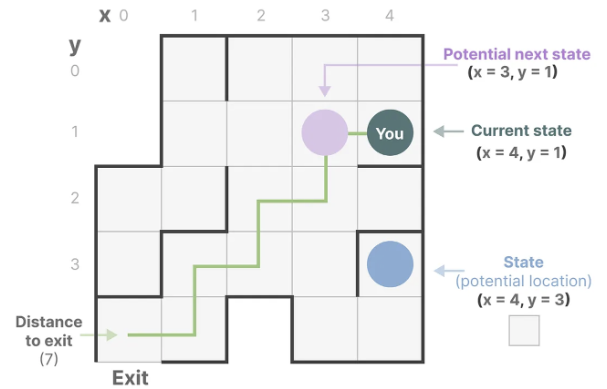
상태 공간 표현을 이 지도로 설명할 수 있다. 현재 위치, 다음에 갈 수 있는 곳(가능한 미래 상태), 다음 상태로 이동하는 변화(오른쪽 or 왼쪽으로 가는 것)가 표시된다.
상태 공간 모델은 방정식과 행렬로 이러한 행동을 추적한다.
상태 공간 모델(SSM): SSM은 상태 표현을 설명하고, 입력에 따라 다음 상태가 어떻게 될지 예측하는 모델이다.
시간 t에서 SSM은
- 입력 시퀀스 x(t)를 매핑한다. -- (e.g. 미로에서 왼쪽 아래로 움직임)
- 잠재 상태 표현 h(t)로 -- (e.g. 출구까지의 거리와 x,y 좌표)
- 예측된 출력 시퀀스 y(t)를 도출한다. -- (e.g. 출구에 더 빨리 도달하기 위해 다시 왼쪽으로 이동)
하지만, 한 번에 왼쪽으로 이동하는 이산 시퀀스를 사용하는 대신, 연속 시퀀스를 입력으로 받아 출력 시퀀스를 예측한다.
SSM은 동적 시스템(e.g. 3D 공간에서 움직이는 객체같은 것)이 시간 t에서의 상태를 통해 두 방정식을 예측할 수 있다고 가정한다.
-- State equation
-- Output equation
이 방정식을 풀면, 관측된 데이터(입력 시퀀스와 이전 상태)를 기반으로 시스템의 상태를 예측하는 통계 원칙을 알아낼 수 있다고 가정한다. 입력에서 출력 시퀀스로 이동할 수 있도록 하는 h(t)를 찾는 것이 목적이다. 이 방정식들이 상태 공간 모델의 핵심이다.
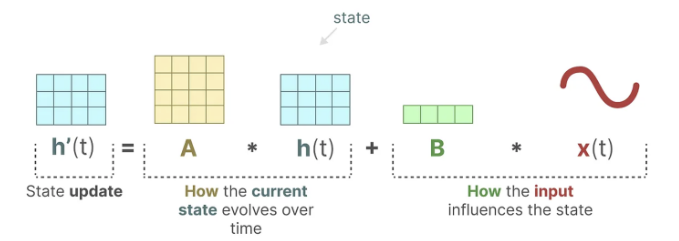
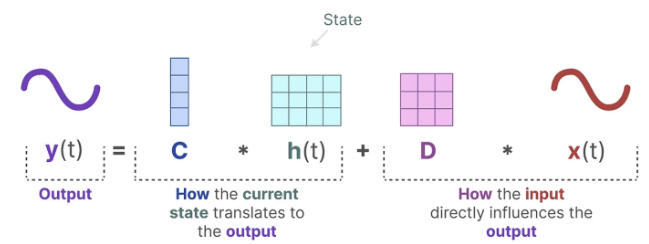
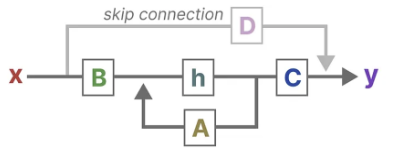
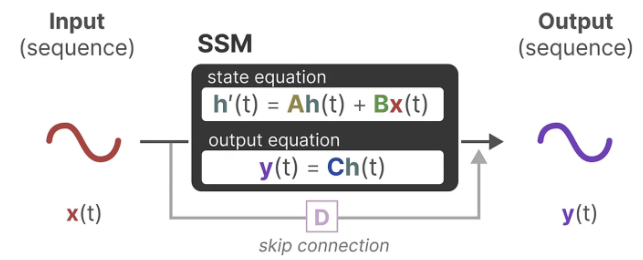
이 두 방정식은 함께 관측된 데이터로부터 시스템의 상태를 예측하려고 한다. 입력이 연속적으로 예상되기 때문에, SSM의 주요 표현은 연속 시간 표현(continuous-time representation)이다.
Definition of SSM in deep learning
🔽 View of a continuous, time-invariant SSM
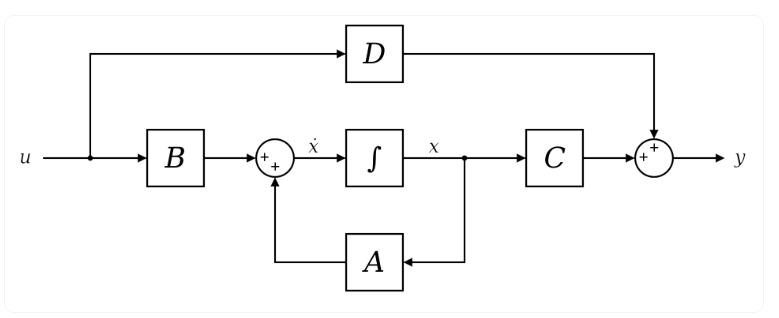
SSM은 시간 t에 따라 변하는 세가지 변수 x(t), u(t), y(t)에 기반
-
∈ : n state variables
-
∈ : m state inputs
-
∈ : p outputs
-
: state matrix (latent state x control)
-
: control matrix
-
: output matrix
-
: command matrix
위 이미지에 따라 이렇게 식이 나온다.
로 간단히 쓸 수 있다. (∵ t에 따라 변수들이 변하는게 확실해서)
딥러닝 SSMs에서 이라서
로 더 간단히 쓸 수 있다.
이 식은 연속이라서 컴퓨터에 공급되기 전에 먼저 이산화되어야 한다.
Discretization
SSM에서 가장 중요한 것이 discretization(이산화)이다.
🔽 Structured State Spaces: Combining Continuous-Time,Recurrent, and Convolutional Models
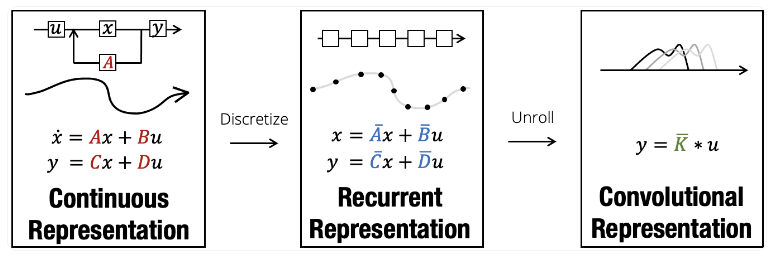
SSM의 모든 효율성은 이산화 단계에 달려있다. 왜냐하면 이 과정을 통해 SSM의 연속적인 관점에서 두 가지 다른 관점인 재귀적 관점과 합성적 관점으로 전환할 수 있기 때문이다.
요약
SSM(상태 공간 모델)은 연속적 관점, 이산화(Discretization)되었을 때의 재귀적 관점, 그리고 합성적 관점의 세 가지 관점을 가진 모델이다.
이러한 아키텍처의 도전과제는 프로세스의 단계(훈련 또는 추론)와 처리되는 데이터 유형에 따라 어느 관점을 우선시할지 아는 것이다.
이 모델은 텍스트, 비전(이미지), 오디오, 시계열 데이터(또는 그래프) 작업에 적용될 수 있습니다.
이 모델의 강점 중 하나는 일반적으로 다른 모델(ConvNet 또는 트랜스포머)보다 적은 수의 파라미터로 매우 긴 시퀀스를 처리할 수 있다는 점이고, 매우 빠르다.
