
7일차
Python 마무리, pandas, numpy 입문
Python 마무리
가상환경 만들기
py 3.11 -m venv .venv
python -m pip install --upgrade pip
pip install jupyter numpy pandas
pip list
함수 만들기
간단한 절댓값 만드는 함수 만들어보기
def fnc_abs(lst:list) -> list:
result_lst=[]
for i in lst:
if i >= 0 :
result_lst.append(i)
else:
result_lst.append(i*-1)
return result_lst
a=[1,-3,2,4,-4,-6,-7]
fnc_abs(a)pandas 입문
s=pd.Series(data= np.random.randn(5), index=['a','b','c','d','e'])
s
s[(s<0.21) & (-2.0<s)] # 0.21 보다 작고, -2.0보다 큰 숫자만 뽑기.min()
.max()
.mean()
.describe()
조건에 not을 붙이려면 앞에 ~ 하면된다. (ex. iris[~cond] )
df = pd.DataFrame(값, index=행, columns=열)
iloc와 loc
df.iloc[a,b]
위치정보로 정보를 가져온다. (숫자를 넣어 사용)
a행 b열의 정보를 가져온다.
b가 공백일경우 모든 열의 정보를 가져온다.
df.loc[]
위치정보가 아닌 진짜 이름을 이용하여 가져온다. (숫자도 사용하지만 진짜 이름을 사용)
df [ '칼럼이름' ] 하나의 열만 인덱싱
df [ [ '칼럼이름' ] ] 하나의 열만 인덱싱 하는데 데이터프레임모양으로 출력
df.isnull().sum(): 컬럼별 널 확인
df.info(): 전체 수, null이 있는 컬럼, 데이터 타입 등을 알 수 있음
df_number = df.select_dtypes(include=np.number)
df_object['who'].value_counts()
x.map(y)
맵은 도킹하는 걸 의미하는듯 x의 value값과 y의 index값이 같을때 두개를 합쳐줌
x의 value값을 바꾸는 것이기때문에 이것을 활용하여 value의 값들을 바꿀 수 있다.
ex) df['성별'].map({'male':0, 'female':1})
참고: wikidocs
df.apply(lambda x:x.sum(), axis=1)
axis=0은 column에 대하여 진행하라는 뜻 default는 axis=0이다.
행끼리 연산을 원할경우 axis=1으로 두면된다.
pivot_table
pd.pivot_table(df, index='b', columns='c',values='d',aggfunc='e')
df라는 DataFrame을 index에는 'b'열의 값을, columns에는 'c'열의 값을 가져오고 index의 값은 'd'에서 가져오는데 가져올때 값들을 어떤 형태로 가져올지 정하는게 'e'이다. 'e'에는 min, meanm, max 등이 올 수 있다.
groupby
df.groupby(['열이름'])
해당 열의 인덱스 값들로 그룹화한다. 분석하기 용이하게 해준다.
agg
df['열이름'].agg(함수)
해당 column값을 함수로 계산하여 통계낸다. 함수에는 'mean', 'sum', lambda와 같은 것들이 올 수 있다.
8일차
pd.merge(df1,df2, on=[" column 이름"]
두개의 DataFrame을 합쳐주는 함수이다. on뒤에 써주는 column에 맞춰서 합쳐진다. on 뒤에 들어간 컬럼은 df1과 df2 모두에 존재해야한다. 같은 column이름을 갖더라도 row값이 다를 수도 있는데, 그때 다른 row값을 갖는 row는 제외하고 같은 값만 갖는 row만 합쳐진다.
위 함수에 인자로 how=''이 올수 있는데 '' 사이에 left, right, inner, outer가 올 수 있다. 합치는 기준에 대한 것인데, 간단하다.

pd.concat(df1, df2, axis=1)
df1과 df2를 그냥 붙인다. concat은 index를 정리해주지 않고 그냥 가져와서 냅다 붙여버리기 때문에 주의해야한다. 재정의를 해주지 않는다.
matplotlib
그래프를 그려주는 모듈
x축은 인덱스 y축은 column 값이라고 볼 수 있다.
plt.plot(그릴거)
그릴거를 괄호안에 넣는다.
plt.show()
도화지 켜기
plt.subplot(2,2,1)
도화지를 분할하여 사용하기
fig, ax = plt.subplots(2,2,figsize=[15,5])
도화지 분할하는 다른 방법, (2,2)로 나눠서 총 4개를 사용가능
ax[0].plot(x,y)
ax를 사용해서 0~3까지 사용가능
fig.suptitle("figure title")
도화지의 제목을 설정한다.
.set_xlabel('')
x축 이름을 설정한다.
.tick_params(axis="x", labelrotation=90)
눈금 설정
ax[0,1].plot(y,marker="v",linestyle='--',color="y")
눈금 모양, 색깔 등 설정가능
plt.bar()
막대모양 그래프
plt.scatter()
산점도 그래프
plt.hist()
히스토그램
plt.boxplot()
박스 플롯
Pandas EDA
데이터를 분석할때, test data는 모델과 분리되어 있어야하는것이 중요하다.
분석방법으로는 상관관계를 확인하는 상관계수를 분석하는 것이 있다. 상관계수는 -1 ~ 1의 값을 갖고 음의 상관관계, 양의 상관관계, 상관관계 없음으로 세가지가 존재한다.
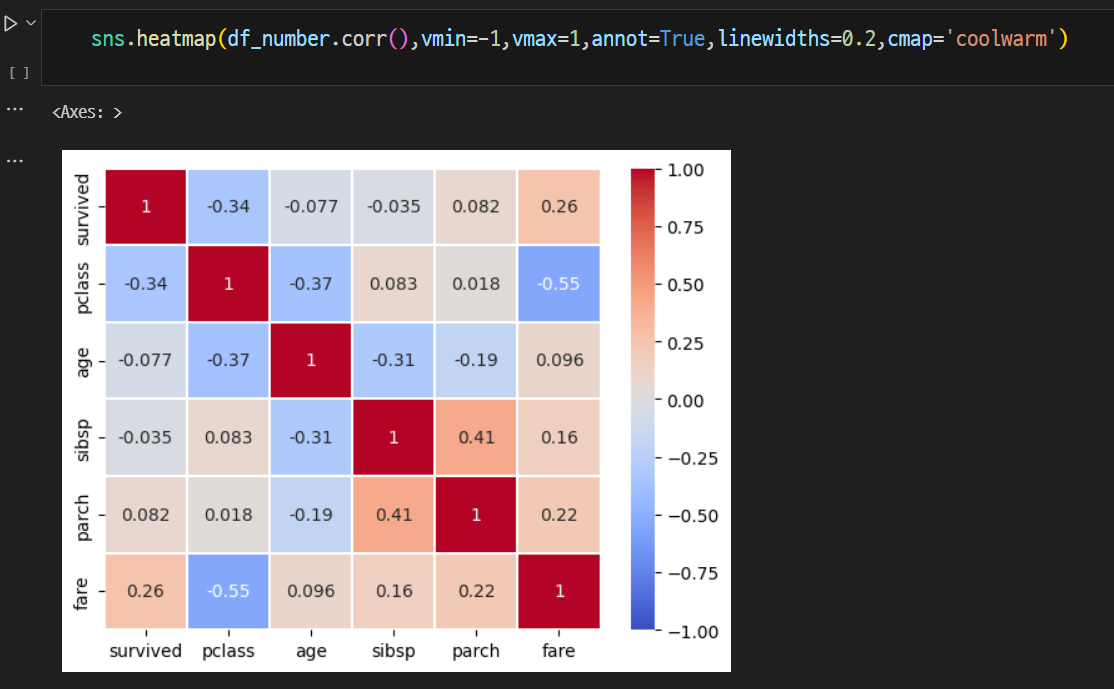 상관관계 분석표
상관관계 분석표
이상치
데이터 분석을 할 때, 평균이나 표준편차를 많이 사용한다. 이런 경우 데이터에 이상치가 있으면 왜곡된 의미를 전달할 가능성이 높다. 그래서 이상치가 있는지를 확인할 필요가 있고, 박스플롯을 활용하면 이상치가 얼마나 포함되어 있는지를 쉽게 판단할 수 있다.
9일차
EDA, Data Cleaning, Feature Extraction
데이터의 결측치를 확인해서 관리한다.
(이상치도 관리해야할까?)
치환과 삭제로 결측치 관리
df.isnull().sum().sum()하면 모든 feature의 결측치의 갯수를 알려준다
각 feature의 결측치를 index갯수로 나눠서 결측치 비율을 확인할 수 있다. 결측치 비율이 너무 높다면 해당 index는 제거하는 방향으로 가는 것이 좋다. 결측치 비율이 크게 높지 않다면 결측치를 치환하여 문제를 해결할 수 있다. 아예 결측치가 발생한 행또는 열을 제거하는 방법도 있다.결측치 비율은 50퍼정도를 기준으로 잡고 판단하는 것이 좋다고 생각한다.
치환할때 수치형 데이터는 전체 값의 median이나 mean을 사용하여 치환한다. 범주형 데이터는 최빈값으로 치환하는 것이 괜찮을 때가 많다. 또는 다른 feature와 연관이 있다면 그것을 활용하여 치환하는 것도 좋다.
예를 들어 age에서 결측치가 20퍼정도로 발생하였을때, 중앙값이나 평균으로 막연하게 채우는 것보단, age와 pclass 성분으로 묶고 pclass=1일떄 age의 결측값을 이떄의 평균이나 중앙값으로 치환하는 것이 좋다.
df.dropna(axis=0) 결측치가 발생한 행을 삭제한다.
df.fillna() 결측치를 원하는 값으로 채운다.
df.fillna( method = 'ffill' ) 을 사용하면 결측치를 앞의 값으로 채운다.
이것은 sort를 한 후에 사용하면 좋을 때가 있지만 맨앞과 맨뒤값은 채우기 곤란한 경우가 있다.
apply, lambda를 사용하여 결측치를 채울 수 있다. 아래 두줄 참고
fill_func = lambda x: x.fillna(fill_values[x.name])
df.group('그룹화할col명').apply(fill_func)
결측치를 랜덤한 값으로 변경하는 방법도 있다.
Test값의 결측치를 채울때 Test 데이터만을 사용하여 결측치를 채워야한다.
value_count()에서 dropna=False를 인자로 넣어주면 결측값이 몇개인지도 같이 세준다.
모델기반으로 결측치를 채울 수 있다.
sklearn의 SimpleImputer를 사용
from sklearn.impute import SimpleImputer
# strategy = mean, median, most_frequent
imputer = SimpleImputer(strategy="mean")
X_tr['age_simple_mean'] = imputer.fit_transform(X_tr[["age"]])
X_te['age_simple_mean'] = imputer.transform(X_te[["age"]])
X_tr[['age', 'age_simple_mean']].isnull().sum()평균값을 학습한 후에 결측치를 평균값(strategey="mean"이기에)으로 채운다. 학습은 train data로만 해야하고, test data를 채울때는 train data로 학습한 것으로 채운다.
sklearn의 KNNImputer를 사용
from sklearn.impute import KNNImputer
imputer = KNNImputer(n_neighbors=5)
X_tr['age_knn'] = imputer.fit_transform(X_tr[["age"]])
X_te['age_knn'] = imputer.transform(X_te[["age"]])
X_tr[['age', 'age_knn']].isnull().sum()인접한 5개(n_neighbors=5이기에)의 값을 바탕으로 학습하여 결측치를 채운다.
sklearn의 IterativeImputer를 사용
from sklearn.experimental import enable_iterative_imputer
from sklearn.impute import IterativeImputer
imputer = IterativeImputer(random_state=SEED)
X_tr['age_iter_none'] = imputer.fit_transform(X_tr[["age"]])
X_te['age_iter_none'] = imputer.transform(X_te[["age"]])
X_tr[['age', 'age_iter_none']].isnull().sum()sklearn의 RandomForestRegressor를 사용
from sklearn.ensemble import RandomForestRegressor
imputer = IterativeImputer(estimator=RandomForestRegressor(verbose=0, random_state=SEED),
max_iter=10, verbose=0, imputation_order='ascending', random_state=SEED)
X_tr['age_iter_none'] = imputer.fit_transform(X_tr[["age"]])
X_te['age_iter_none'] = imputer.transform(X_te[["age"]])
X_tr[['age', 'age_iter_none']].isnull().sum()커스터마이징이 가능하다.
tqdm 모듈을 사용하면 진행 정도를 알 수 있다.
10일차
Data Encoding
컴퓨터는 숫자로 된 값으로 읽기 떄문에, 범주형 데이터들을 encoding하여 컴퓨터가 이해하기 쉽게 만들어준다. 범주형 데이터에는 순서형 데이터(Ordinal)와 명목형 데이터(Nominal)이 있다.
Encoding의 종류로는 One hot Encoding, Mean Encoding, Target guided ordinal Encoding, Label Encoding 등이 있다. Encoding하기 전에 결측치는 모두 제거해줘야한다.
One Hot Encoding
흔히 사용하는 Encoding 방식 중 하나이다. 범주를 가장 잘 나타낼 수 있다.
Feature의 항목이 많을 때 연산이 오래걸리는 단점이 있다.
Mean Encoding
데이터량이 늘어나 연산이 오래걸리는 점을 해결하기 위하여 평균값으로 encoding한다.
하지만 이 경우에 컴퓨터는 이 data가 범주형 데이터라고 인지할 수 없다.
위 두 Encoding은 명목형 데이터에 사용하면 좋다.
아래 Encoding들은 순서형 데이터에 사용하면 좋다.
Label Encoding
각각의 자연어에 라벨로 숫자를 붙인다.
Target Encoding
Mean Encoding과 Label Encoding을 합쳐서 적용한다.
