LLM의 동작 원리와 효율적인 사용법 (챗봇 설계 기술 검토)

LLM의 동작 원리와 효율적인 사용법
서론
LLM(Large Language Model)을 효과적으로 사용하기 위해서는 내부 동작 원리를 이해하는 것이 중요하다.
이 글에서는 LLM의 핵심 개념들을 정리하고, 실무에서 활용할 수 있는 팁을 공유한다.
1. LLM의 기본 특성
Stateless 특성
LLM은 상태를 유지하지 않는다(stateless). 즉, 이전 대화를 자체적으로 "기억"하지 못한다.
그럼에도 multi-turn 대화가 가능한 이유는 이전 대화 내용을 매번 현재 입력에 포함시켜 전달하기 때문이다.
대화 처리 예시
Turn 1 - User: "안녕"
API 호출: ["안녕"]
Assistant: "안녕하세요!"
Turn 2 - User: "내 이름은 철수야"
API 호출: ["안녕", "안녕하세요!", "내 이름은 철수야"] ← 이전 대화 전부 포함
Assistant: "반갑습니다, 철수님!"
Turn 3 - User: "내 이름이 뭐라고?"
API 호출: ["안녕", "안녕하세요!", "내 이름은 철수야", "반갑습니다, 철수님!", "내 이름이 뭐라고?"]
Assistant: "철수님이라고 하셨습니다!" ← 기억하는 것처럼 보이지만, 실제로는 입력에 다 들어있음웹앱 vs API
웹앱에서 사용하는 LLM과 API로 사용하는 LLM은 동일한 모델이다.
차이점은 입력 프롬프트를 어떻게 구성하느냐에 있다.
(시스템 프롬프트, 파라미터 설정, 부가 기능 등 세부적인 차이는 존재한다.)
2. Context Window
Context Window란
Context window는 LLM이 한 번에 처리할 수 있는 최대 토큰의 양이다.
1M으로 되어 있으면 최대 100만 토큰까지 처리할 수 있다는 의미이다.
최신 모델들은 Max Input Tokens와 Max Output Tokens가 별도로 제한되어 있어서 Context Window는 Max Input Tokens를 의미한다.
| 모델 | Max Input Tokens | Max Output Tokens |
|---|---|---|
| GPT-5.2 | 400,000 | 128,000 |
| Claude Opus 4.5 | 200,000 | 64,000 |
| Claude Sonnet 4.5 | 200,000 (기본) / 1M (beta) | 64,000 |
| Gemini 3 Pro | 1,000,000 | 64,000 |
| Gemini 3 Flash | 1,000,000 | 64,000 |
긴 Context의 문제점
Context window가 크더라도, 긴 context가 입력되면 성능이 저하될 수 있다.
- Lost in the Middle 현상 발생 가능 (다음 섹션에서 상세 설명)
- 이전 대화를 요약하여 입력하는 과정에서 정보 손실/변형 가능
- Attention 연산 복잡도 증가로 답변 생성 속도 저하
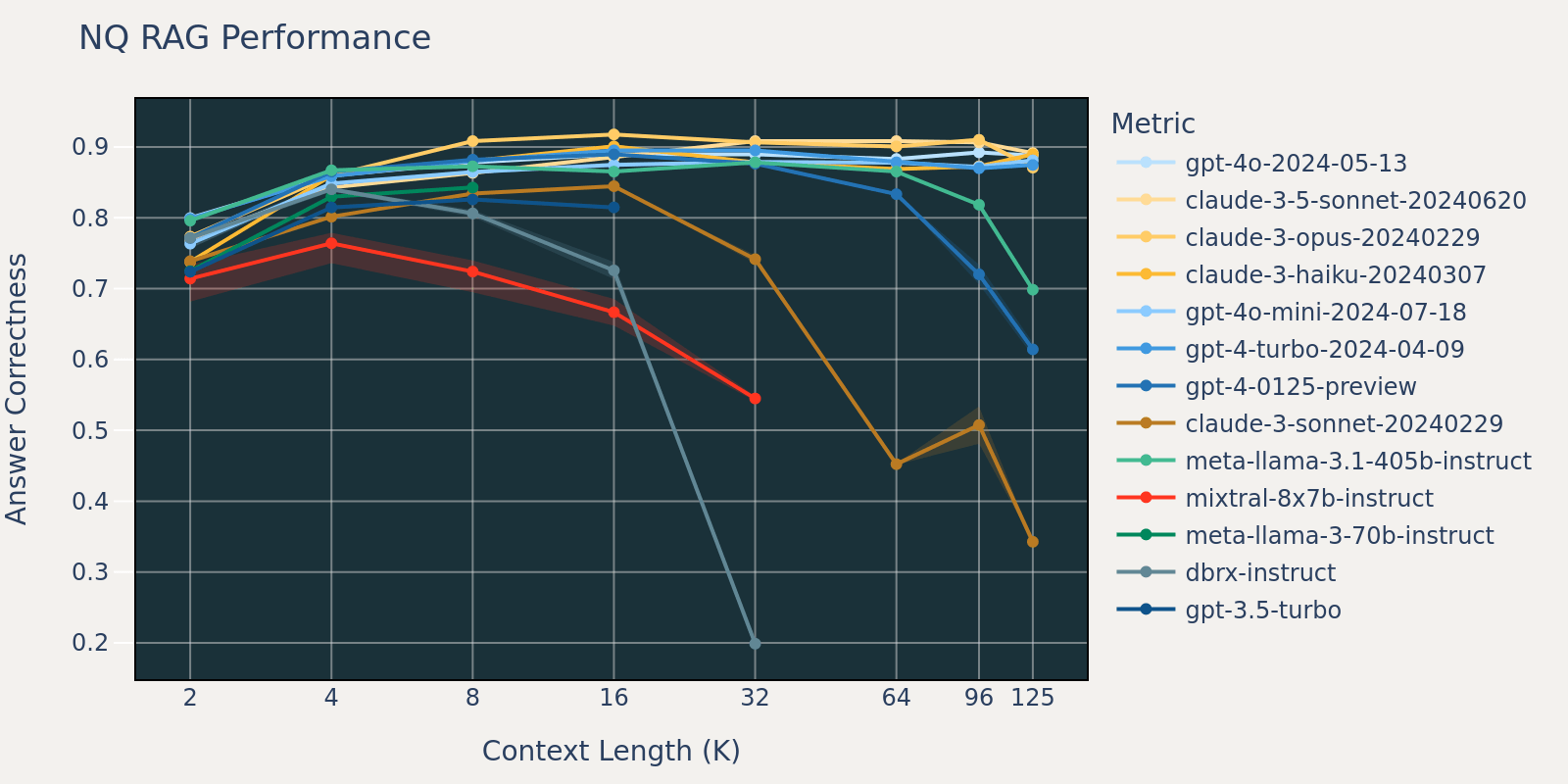
적절한 Context의 이점
반면, 어느 수준까지는 context가 길어질수록 성능이 좋아진다.
사용자의 needs, 배경 지식, 상황, 조건이 충분히 제공되면 더 정확한 답변이 가능하기 때문이다.
권장 사항
- 초기에 사용자의 needs를 명확하게 프롬프트에 포함
- 배경 지식, 상황, 조건 등을 잘 정리하여 입력
- 실질적인 입력 토큰은 API에서 50K, 웹앱에서는 100K 미만으로 유지하는 것이 안정적
- 답변 속도가 느려지거나 퀄리티가 낮아지면, 대화를 요약하여 새 채팅 시작 권장
참고: 모델별 Context Window
| 모델 | Context Window |
|---|---|
| Claude 4.5 series | 200K |
| GPT 5.2 series | 400K |
| Gemini 3.0 series | 1M |
3. Causal Decoder와 Attention
Causal Decoder의 동작 원리
Causal decoder는 답변을 생성할 때 앞에 있는 token들을 참조하여 다음에 올 단어를 하나씩 예측한다.
이때 사용되는 것이 attention이다.
Attention은 말 그대로 "어디에 주목할 것인가"를 수치적으로 계산하는 메커니즘이다.
여기서 causal masking이 적용되어 현재 위치 이후의 토큰은 참조하지 못하도록 제한된다.

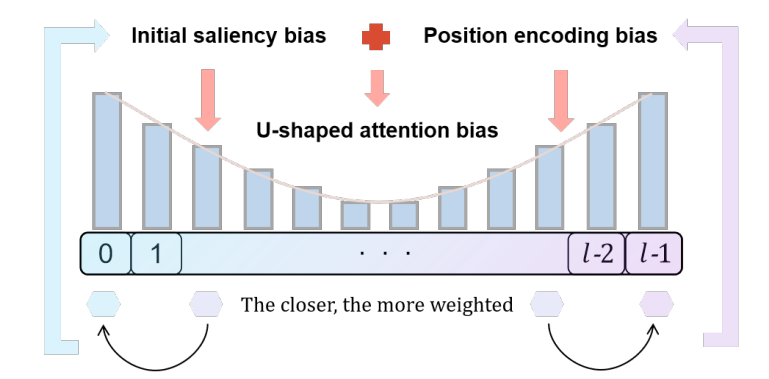
Primacy Effect - 앞부분 중요도 상승
첫 번째 토큰은 모든 연산에서 항상 참조 대상에 포함된다.
또한 모델이 특별히 attention을 줄 곳이 없을 때, 첫 번째 토큰에 attention을 몰아주는 경향이 있다.
이를 Attention Sink 현상이라고 한다.
이로 인해 앞부분의 중요도가 높아진다.
Recency Effect - 뒷부분 중요도 상승
질문(쿼리)과 가까이 위치한 뒷부분 토큰들은 거리상 가깝기 때문에 높은 attention 값을 받는다.
이로 인해 뒷부분의 중요도 역시 높아진다.
Lost in the Middle - 중간부분 중요도 하락
앞부분(Primacy)과 뒷부분(Recency) 사이에 끼인 중간 부분은 상대적으로 attention을 적게 받는다.
이 현상을 U-shaped Attention 또는 "Lost in the Middle"이라고 부른다.
이것은 causal decoder의 구조적인 특성에서 비롯된 문제로, 완전한 해결은 어렵지만 완화는 가능하다.
실제 적용 사례
문서 1, 문서 2, 문서 3과 쿼리(질문)가 주어진 상황을 가정하자.
모델이 쿼리에 대한 답변을 생성할 때, 문서 1과 문서 3의 내용은 잘 참조하여 답변한다.
하지만 문서 2에 있는 내용은 상대적으로 누락될 가능성이 높다.
4. System Prompt
System Prompt의 역할
System prompt는 모델의 행동 방식, 페르소나, 제약 조건을 정의하는 특별한 입력이다.
모든 대화에서 최상단에 위치하며, Primacy Effect로 인해 강한 영향력을 가진다.
구성 요소
- 역할/페르소나 정의
- 출력 형식 지정
- 제약 조건 및 금지 사항
- 배경 지식 및 컨텍스트
활용 예시
- 역할 부여: "너는 10년차 백엔드 개발자야. 코드 리뷰를 해줘."
- 출력 형식: "답변은 반드시 JSON 형식으로만 해."
- 제약 조건: "확실하지 않은 내용은 추측하지 말고 모른다고 답변해."
- 언어 지정: "모든 답변은 한국어로 해."
System prompt는 매 요청마다 전송되므로, 토큰 효율성을 위해 간결하게 작성하는 것이 좋다.
5. 생성 파라미터
Temperature
Temperature는 답변의 무작위성을 조절하는 파라미터이다.
0에 가까울수록 일관적이고 예측 가능한 답변을 생성하고, 높을수록 다양하고 창의적인 답변을 생성한다.
원리:
- 다음 토큰 예측 시 각 토큰의 확률 분포가 계산됨
- Temperature가 낮으면 확률 높은 토큰에 집중 (sharp distribution)
- Temperature가 높으면 확률 분포가 평탄해짐 (flat distribution)
권장 설정:
| 용도 | Temperature |
|---|---|
| 코드 생성, 팩트 기반 답변 | 0 ~ 0.3 |
| 일반 대화, 설명 | 0.5 ~ 0.7 |
| 창작, 브레인스토밍 | 0.8 ~ 1.0 |
Top-p / Top-k
- Top-p (nucleus sampling): 누적 확률이 p에 도달할 때까지의 토큰만 후보로 사용
- Top-k: 확률 상위 k개 토큰만 후보로 사용
예시 (Top-p = 0.9):
- "the" (0.5) + "a" (0.3) + "an" (0.15) = 0.95 → 이 세 개만 후보
- 나머지 토큰은 후보에서 제외
Temperature와 함께 사용하여 답변의 다양성과 품질을 조절할 수 있다.
6. 언어별 효율성
토큰 효율성
한글로 입력했을 때와 영어로 입력했을 때는 토큰 소모량에 차이가 있다.
대부분의 LLM tokenizer가 영어 중심으로 학습되었기 때문에, 한글은 같은 의미를 표현하더라도 더 많은 토큰을 사용한다.
예시:
- "hello" → 1 token / "안녕하세요" → 3~5 tokens
- "the" → 1 token / "그" → 1~2 tokens
답변 품질
LLM의 학습 데이터에서 영어가 차지하는 비중이 압도적으로 높다.
따라서 영어로 질문했을 때 모델이 학습한 지식이 더 잘 활성화될 가능성이 있다.
같은 의미라도 한글 입력과 영어 입력은 내부적으로 다른 경로로 처리된다.
영어로 학습된 지식이 많기 때문에, 영어 입력이 해당 지식과 더 직접적으로 연결될 수 있다.
결론
한국에 특화된 정보를 질문하는 것이 아니라면, 영어로 질문하는 것이 효율적일 수 있다.
체감할 정도로 큰 차이는 아닐 수 있지만, 성능 최적화를 위해 시도해볼 가치는 있다.
결론
LLM을 효과적으로 사용하기 위한 핵심 포인트:
- LLM은 stateless하므로 필요한 정보는 매번 입력에 포함해야 한다. (API에 해당하는 내용)
- Context window의 한계를 인식하고, 적정 수준의 입력 토큰을 유지한다.
- Lost in the Middle 현상을 고려하여 중요한 정보는 앞이나 뒤에 배치한다.
- System prompt를 활용하여 모델의 행동을 제어한다.
- 용도에 맞게 Temperature와 Top-p를 조절한다.
- 가능하다면 영어로 질문하여 토큰 효율성과 답변 품질을 높인다.
이러한 원리를 이해하고 적용하면 LLM을 더욱 효율적으로 활용할 수 있다.
참고 문헌
[1] Liu et al., "Lost in the Middle: How Language Models Use Long Contexts", arXiv:2307.03172, 2023
https://arxiv.org/abs/2307.03172
[2] Zhang et al., "Found in the Middle: How Language Models Use Long Contexts Better via Plug-and-Play Positional Encoding", arXiv:2403.04797, 2024
https://arxiv.org/abs/2403.04797
[3] Qiang et al., "Uncovering the Role of Initial Saliency in U-Shaped Attention Bias", arXiv:2512.13109, 2025
https://arxiv.org/abs/2512.13109
[4] Chen et al., "A Survey on Recent Advances in LLM-Based Multi-turn Dialogue Systems", arXiv:2402.18013, 2024
https://arxiv.org/abs/2402.18013
[5] Databricks, "Long Context RAG Performance of LLMs", 2024
https://www.databricks.com/blog/long-context-rag-performance-llms
[6] 3Blue1Brown, "트랜스포머, ChatGPT가 트랜스포머로 만들어졌죠. - DL5"
https://www.youtube.com/watch?v=g38aoGttLhI
