프로젝트
대용량 DATA ETL 및 분석 프로젝트
프로젝트 개요
이 프로젝트는 대용량 데이터 ETL(Extract, Transform, Load) 및 분석을 목표로 합니다. 주어진 데이터는 아마존 리뷰 데이터로, 총 187GB로 replication을 3으로 설정하여 총 561GB의 저장 용량을 차지하고 있습니다. 데이터는 리뷰와 메타데이터로 구성되어 있으며, 전체 리뷰 수는 약 2억 건에 해당합니다.
프로젝트 진행과정
-
데이터 다운로드와 저장 구조
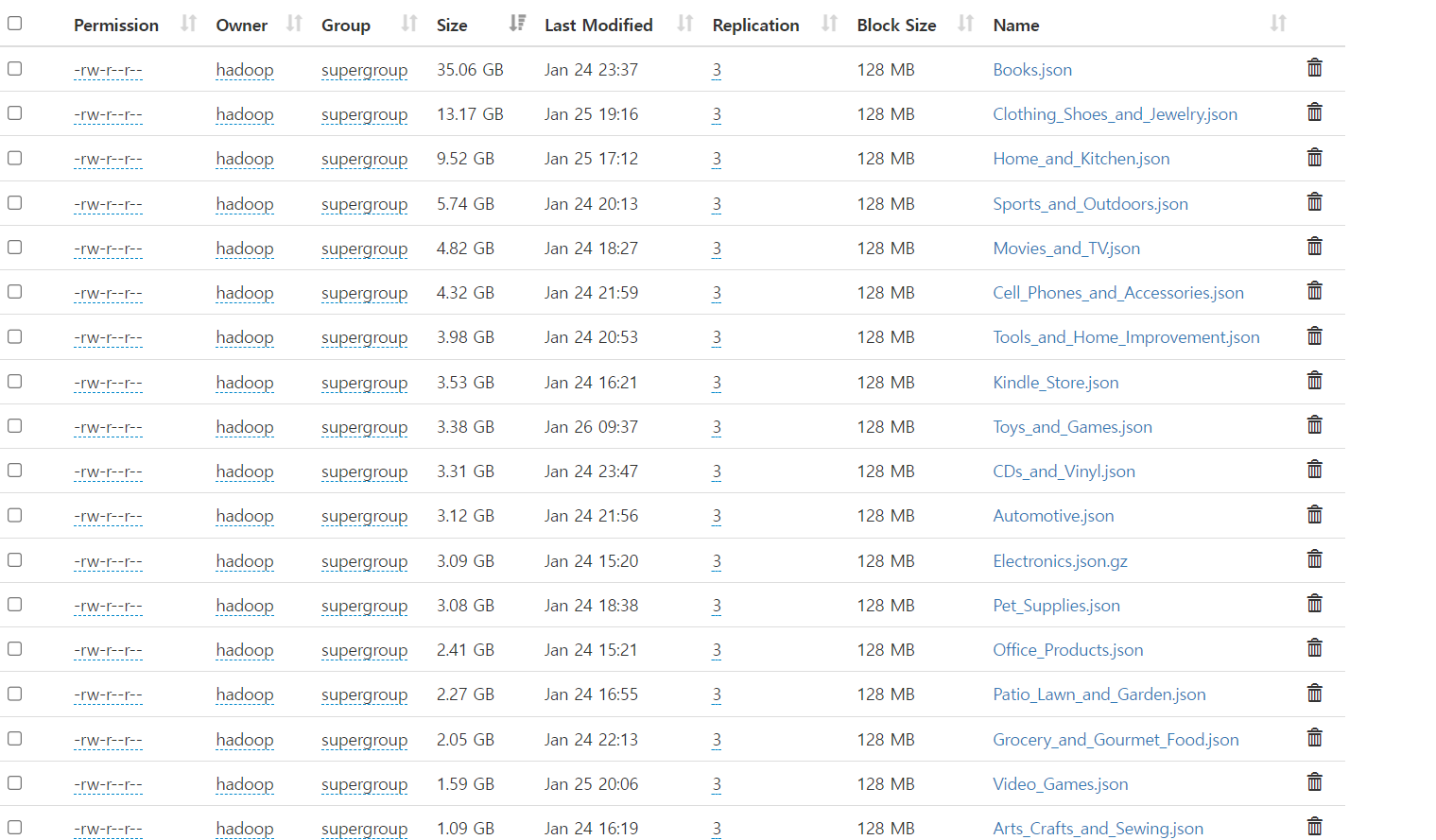
데이터는 카테고리별로 나눠서 다운로드한 후 Hadoop에 put하는 과정을 거쳤습니다. 이로써 데이터의 내고장성이 확보되었습니다.
- 총 리뷰 수: 228,764,070
- 총 제품 수: 11,867,792
-
데이터 병합과 처리
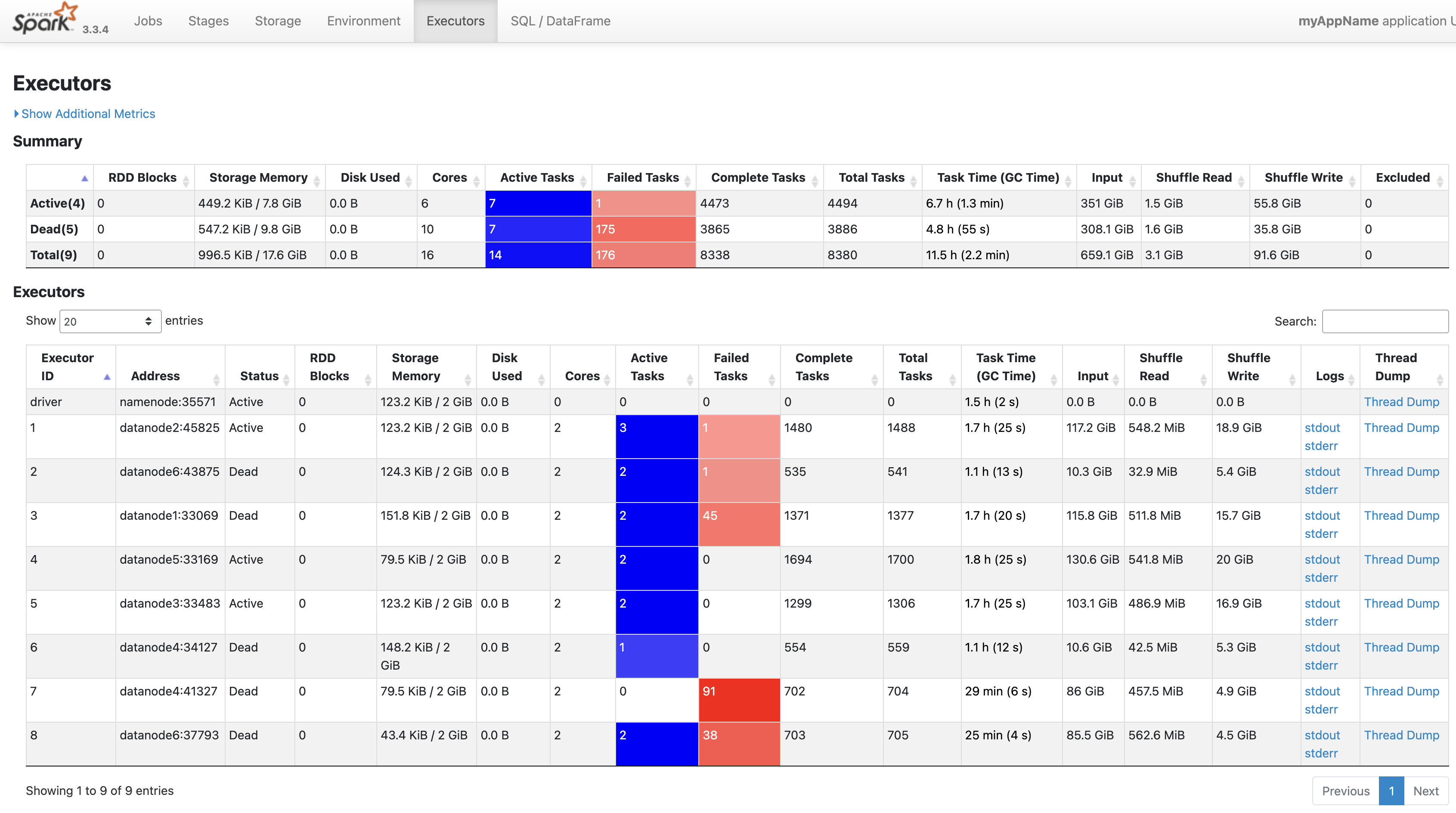
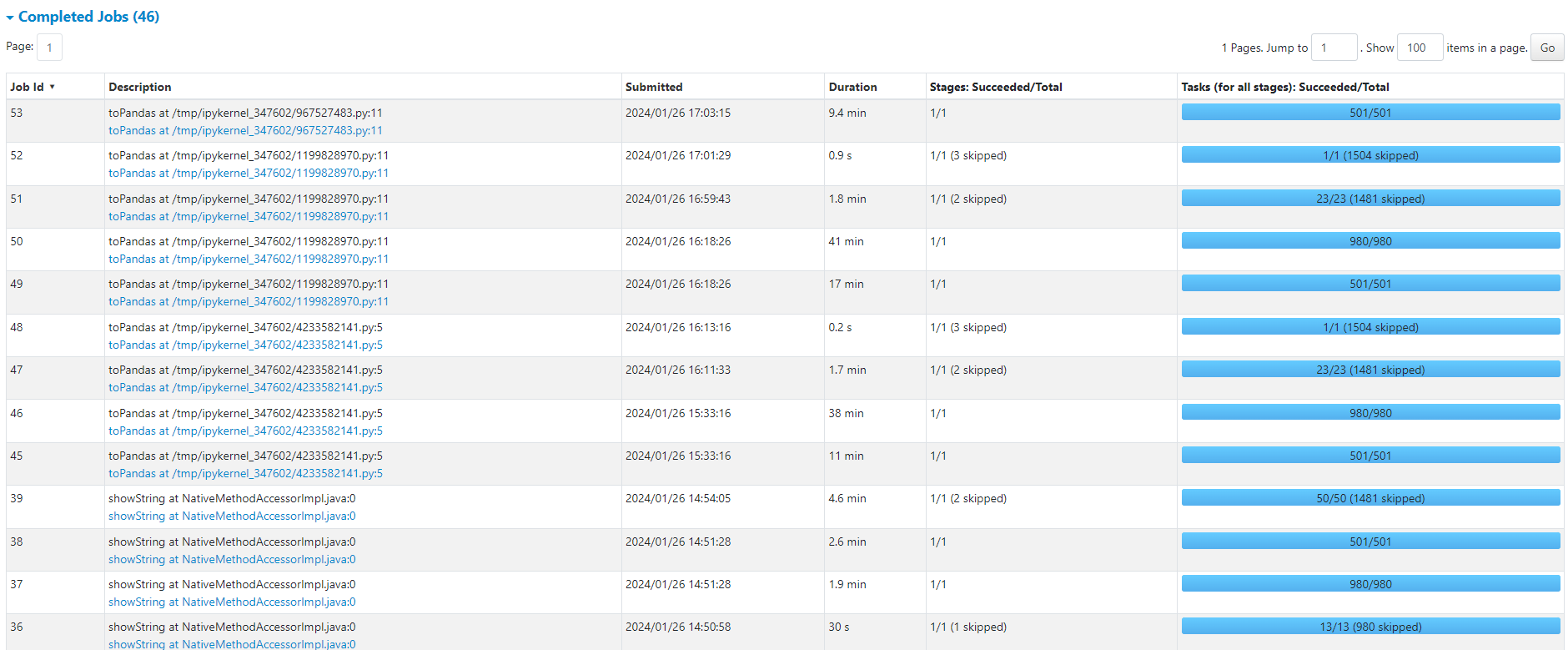
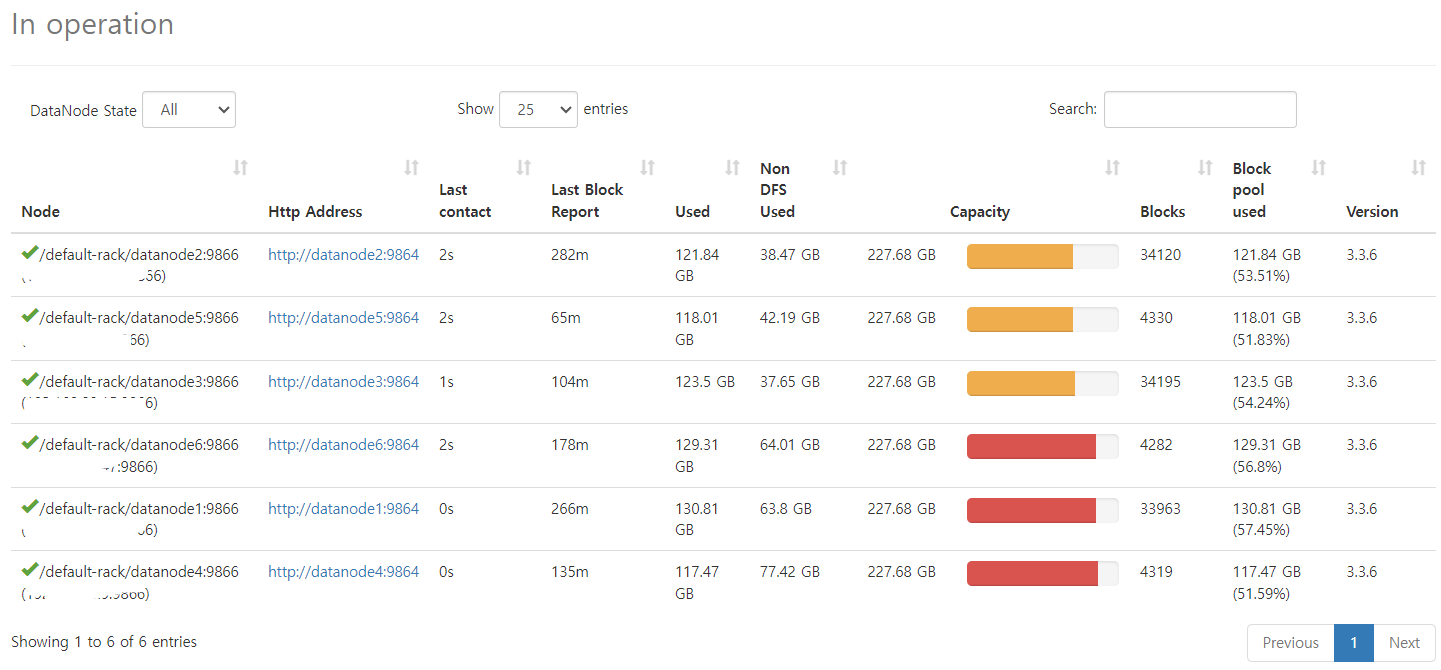
데이터를 Spark를 사용하여 처리하였습니다. Datanode를 6개 사용하며 각각의 Executor를 최대한 활용하기 위해 리소스를 튜닝했습니다. 데이터는 Parquet 파일로 저장되었습니다.
# Spark 설정 예시 from pyspark.sql import SparkSession spark = (SparkSession.builder .appName("myAppName") .config("spark.executor.instances", "6") .config("spark.executor.cores", "2") .config("spark.executor.memory", "4g") .config("spark.driver.memory", "4g") .config("spark.yarn.executor.memoryOverhead", "1g") .config("spark.yarn.driver.memoryOverhead", "1g") .config("spark.master", "yarn") .getOrCreate())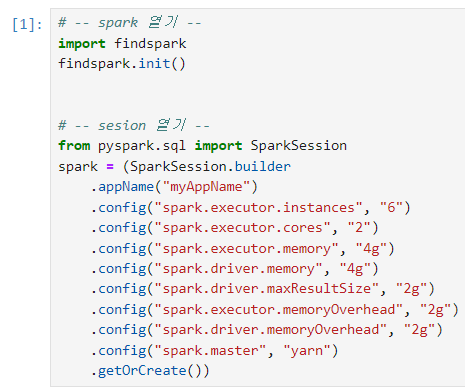
-
데이터 분석
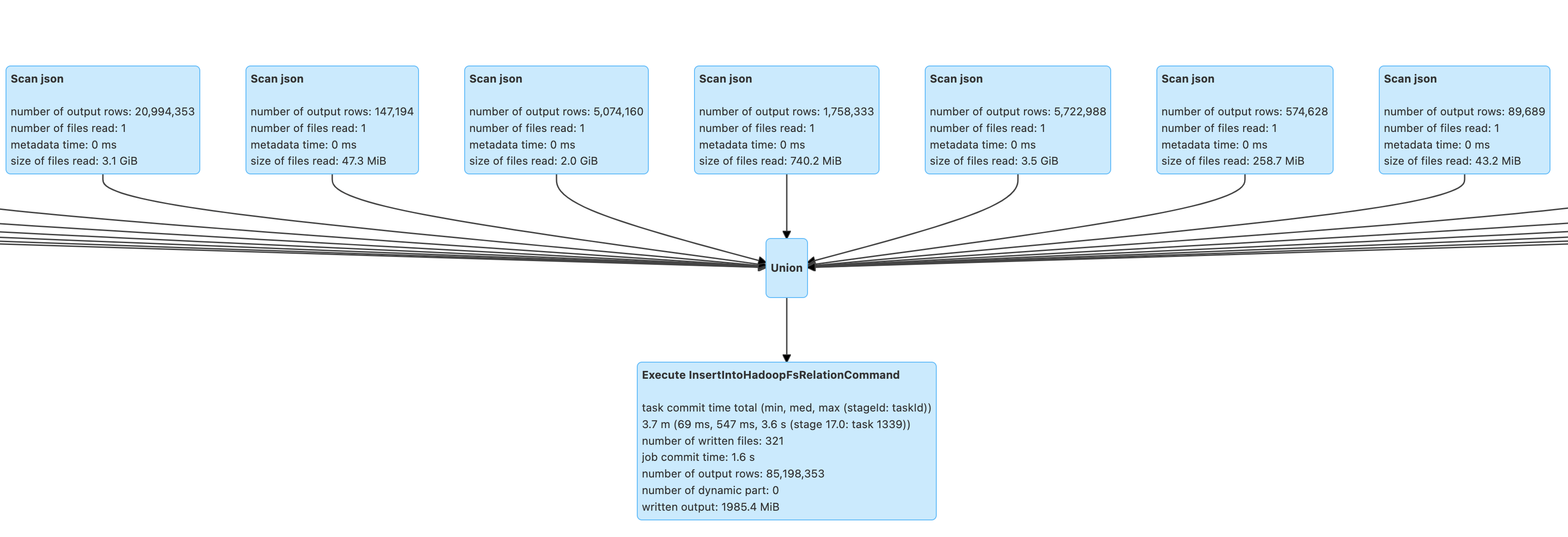
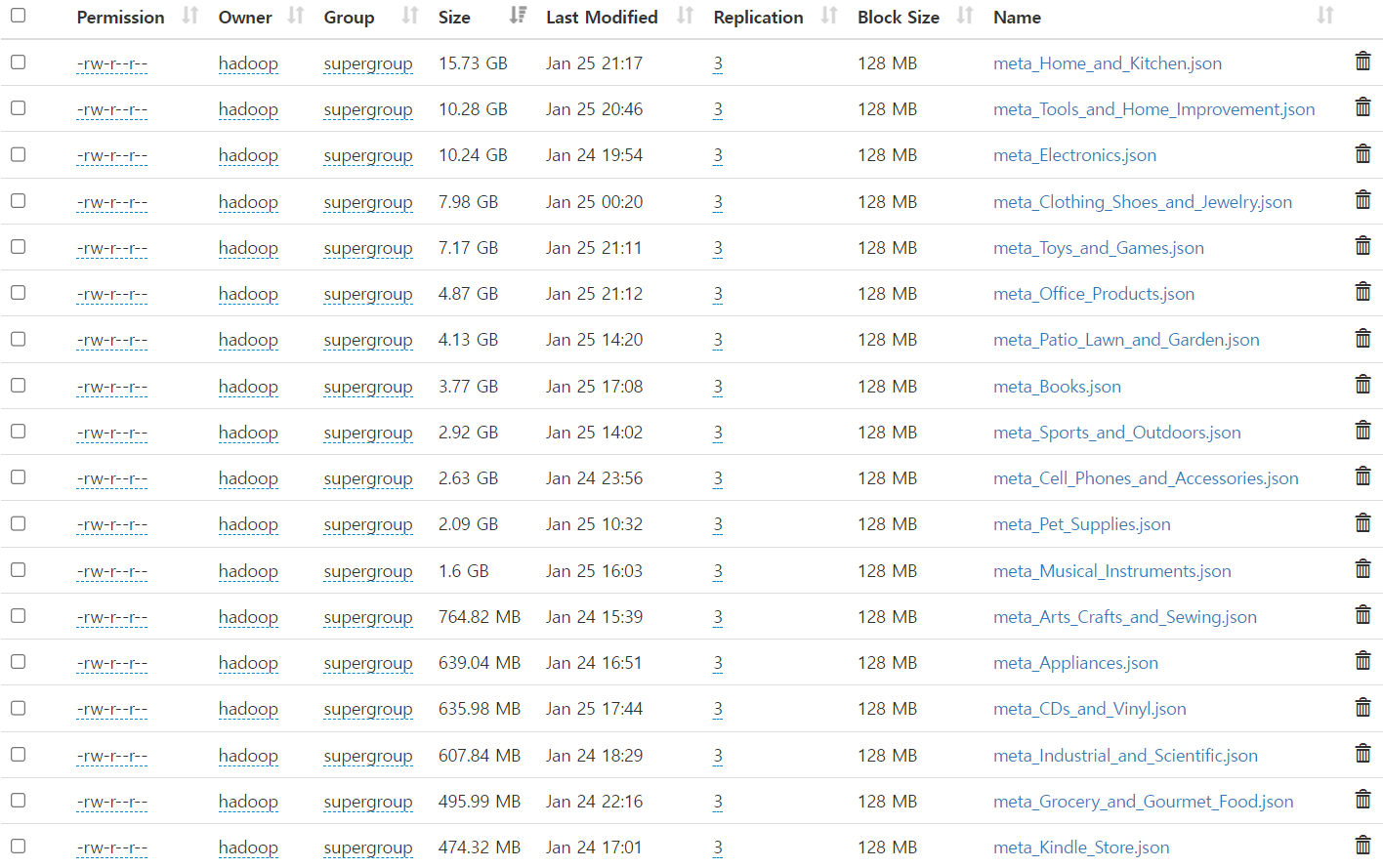
데이터를 Parquet 파일로 저장한 후, Spark를 사용하여 리뷰 데이터와 메타데이터를 각각의 테이블로 분리하였습니다.
- Review 데이터: df_reviewer_id, df_review
- Meta 데이터: df_product, df_also_view, df_also_buy
최종적으로 Hadoop에 저장된 데이터는 아래와 같은 구조를 갖추게 되었습니다.
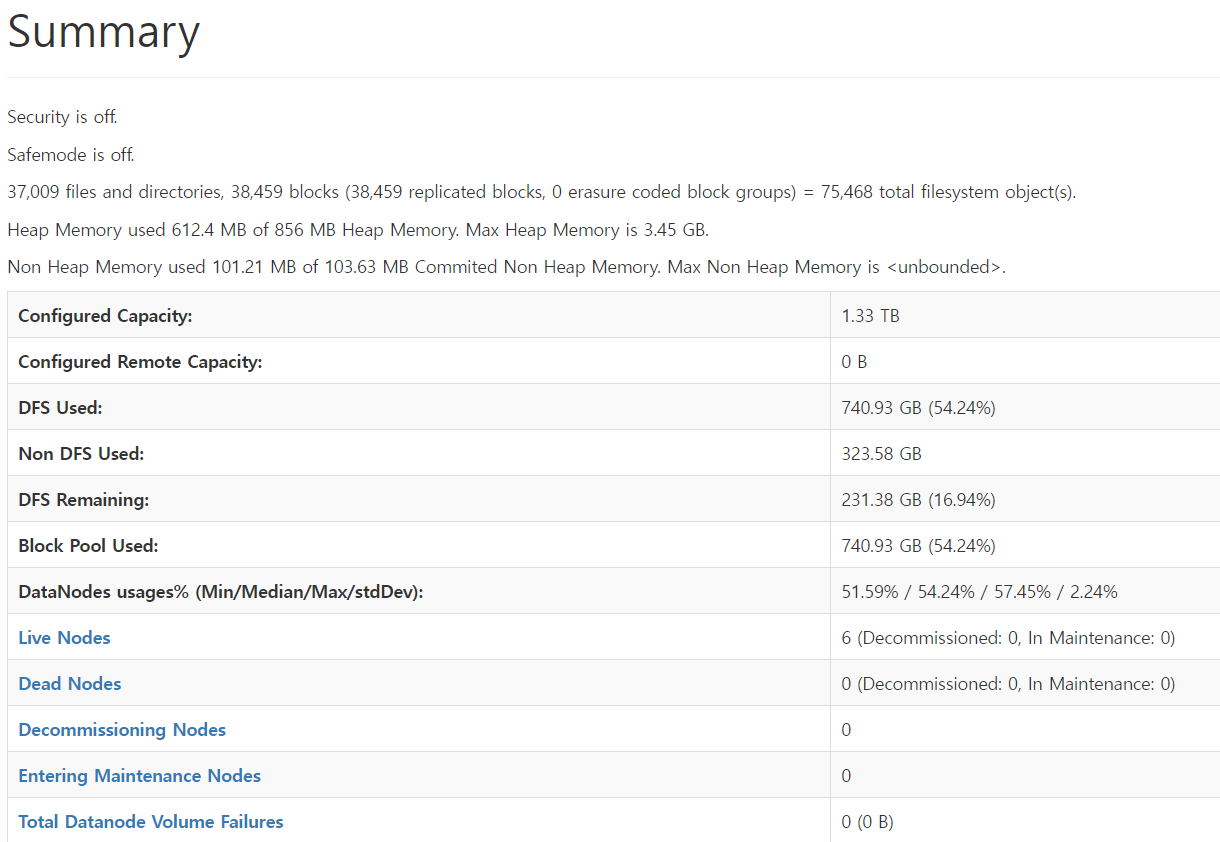
프로젝트에서 발생한 이슈와 해결과정
-
네트워크 문제와 DHCP 고정
초기에는 공유기를 통한 네트워크 문제가 발생하였습니다. DHCP 고정을 통해 IP를 설정하여 이를 해결하였습니다.
-
데이터 다운로드 용량 문제
데이터 다운로드 과정에서 용량 문제가 발생하였습니다. 카테고리별로 나눠 다운로드하고 Hadoop에 put하여 이를 극복하였습니다.
-
Spark Executor 설정과 메모리 문제
Spark Executor를 높게 설정했을 때 초기화 과정에서 시간이 오래 걸렸습니다. 메모리 문제로 인해 여러 번 실패하였으나, 조정을 통해 해결하였습니다.
-
Datanode 추가 및 환경 설정
Datanode를 추가하는 과정에서 몇몇 사람이 중간에 작업하다보니 오차가 발생하였습니다. 이를 해결하기 위해 세심한 조정이 필요했습니다.
데이터 분석 결과
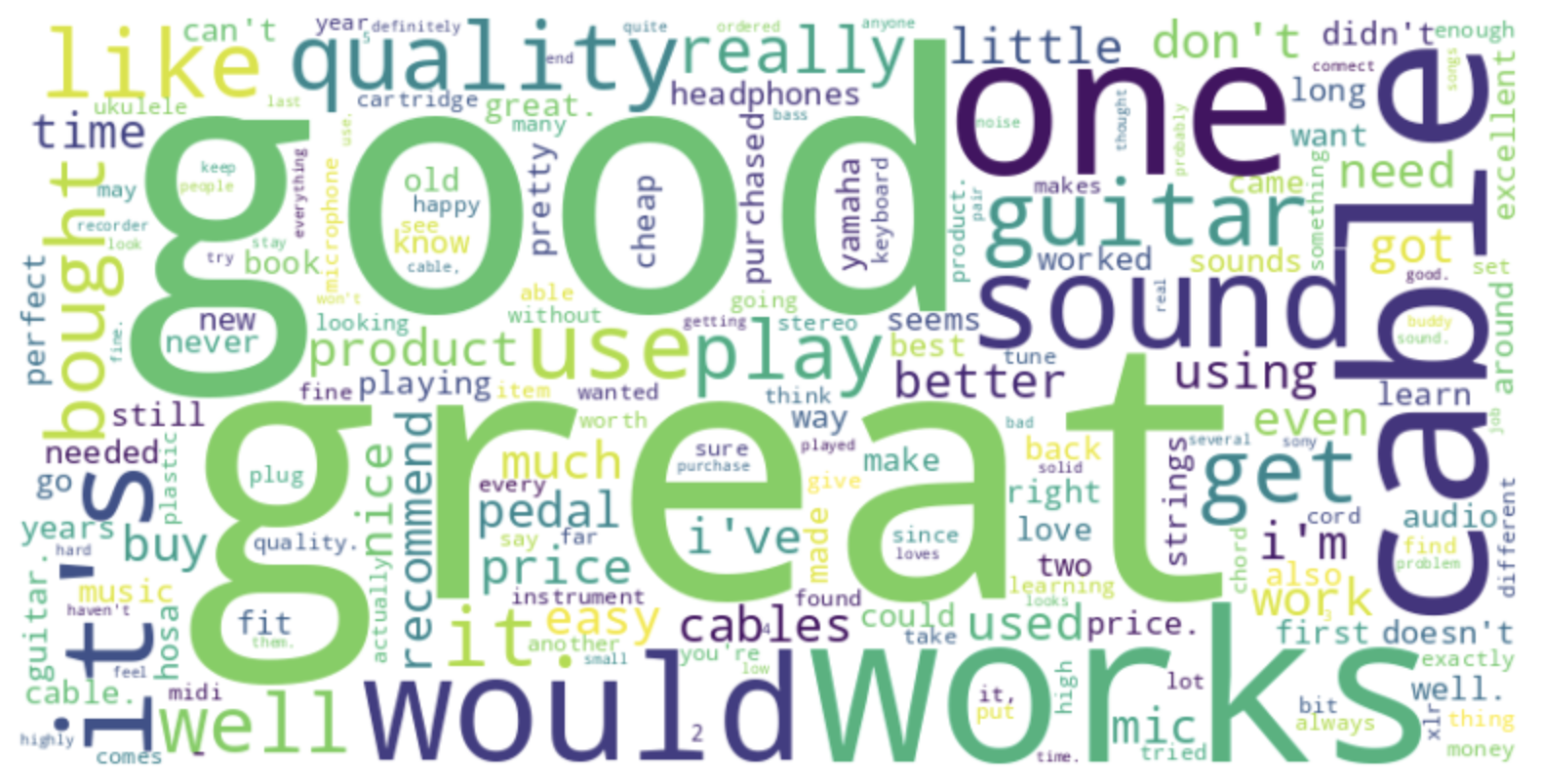
최종적으로 Hadoop에 저장된 데이터를 기반으로 리뷰에 대한 Wordcloud를 생성하여 아래와 같은 시각화를 얻었습니다.
-
별점 5점에 대한 Wordcloud
![Wordcloud for 5-Star Reviews]
-
별점 1점에 대한 Wordcloud
![Wordcloud for 1-Star Reviews]

아쉬운 점 및 향후 계획
프로젝트를 진행하면서 외부 데이터 활용, 데이터 전처리, 자동화 등 여러 측면에서 더 발전할 수 있는 부분이 있었습니다. 향후에는 이러한 아쉬운 점들을 보완하고 추가적인 분석 및 기능 개선을 계획하고 있습니다.
스파크 작업