182. Duplicate Emails
문제설명
주어진 Person 테이블은 id와 email 두개의 컬럼을 갖고 있다.
중복으로 갖고 있는 email을 DISTINCT하도록 추출하는 것이다.
SELECT DISTINCT email
FROM Person
GROUP BY email
HAVING COUNT(1) >= 2따라서 email을 GROUPBY를 진행하여 COUNT가 2개 이상인 것을 추출하였다.
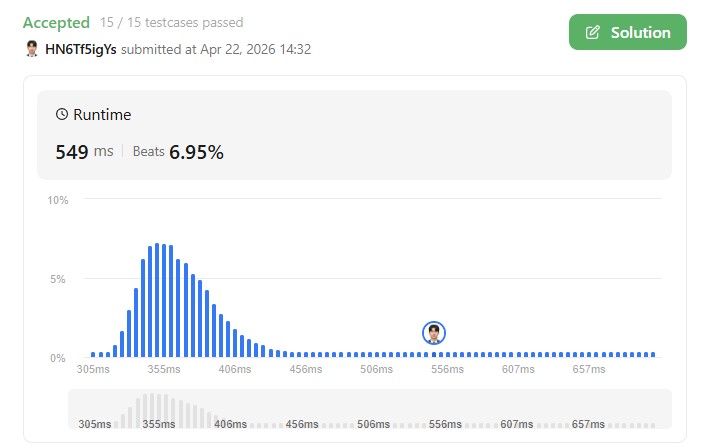
Runtime이 549ms로 어떻게 하면 더 줄일 수 있을까?
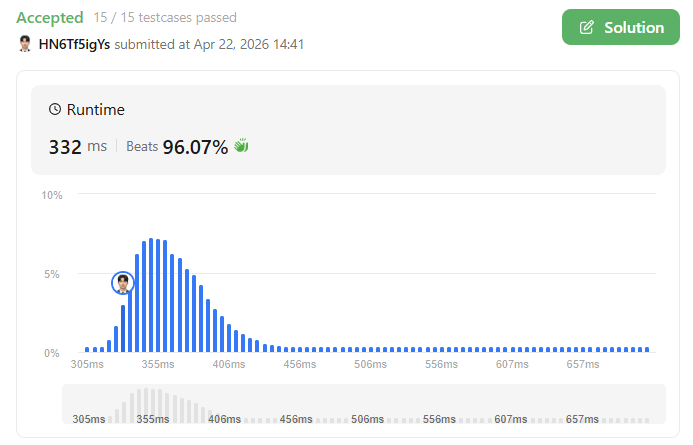
SELECT DISTINCT email
FROM Person
GROUP BY 1
HAVING COUNT(1) >= 2다음과 같은 방법으로 Runtime을 줄일 수 있었다.
해당 방법은 정리 후 게시할 예정이다.
183. Customers Who Never Order
문제설명
Write a solution to find all customers who never order anything.
Return the result table in any order.
Customers와 Orders 두개의 테이블이 존재하고, Orders에 존재하는 customerId를 보유하지 않은 Customers테이블의 컬럼을 출력하는 것이다.
생각한 방법은 두가지이다.
첫번째 방법은 NOT IN을 활용하여, 주문 테이블에 있는 모든 고객 ID를 제외한 나머지 고객"을 찾는 방식이다!
SELECT name AS Customers
FROM Customers
WHERE id NOT IN (
SELECT customerId
FROM Orders);두번째 방법은 NOT EXISTS를 활용한 방법이다.
SELECT c.name AS Customers
FROM Customers c
WHERE NOT EXISTS (
SELECT 1
FROM Orders o
WHERE o.customerId = c.id
);근데 생각해보니 제일 쉽고 간단한 방법이 있었다..
SELECT c.name AS Customers
FROM Customers c
LEFT JOIN Orders o ON c.id = o.customerId
WHERE o.id IS NULL;LEFT JOIN을 진행하면 대응되는 데이터가 없다면 Orders의 컬럼들은 NULL값을 갖게 된다. 이 때 WHERE절에 NULL인 것을 추출하는 조건을 넣어주면 끝.
196. Delete Duplicate Emails
문제 설명
Write a solution to delete all duplicate emails, keeping only one unique email with the smallest id.
For SQL users, please note that you are supposed to write a DELETE statement and not a SELECT one.
For Pandas users, please note that you are supposed to modify Person in place.
After running your script, the answer shown is the Person table. The driver will first compile and run your piece of code and then show the Person table. The final order of the Person table does not matter.
중복된 email을 삭제하고, 작은 id값을 가진 데이터만 남기는 문제.
처음에 SELECT 문을 하는데 왜 안되지 ..? 했는데 역시 문제를 꼼꼼히 읽지 않는 버릇은 중학생 때부터 고쳐지지 않는다.. 문제에 보면 SQL의 경우 SELECT 문이 아닌 DELETE 문을 사용하라고 적혀있다.
DELETE p1
FROM Person p1
JOIN Person p2
ON p1.email = p2.email
WHERE p1.id > p2.id -- -- 더 큰 ID 삭제197. Rising Temperature
문제설명
Write a solution to find all dates' id with higher temperatures compared to its previous dates (yesterday).
Return the result table in any order.
잘못된 쿼리
SELECT w2.id as Id
FROM Weather w1
JOIN Weather w2
ON w1.id = w2.id
WHERE w2.id > w1.id
AND DATEDIFF(w2.recordDate, w1.recordDate) = 1
AND w2.temperature - w1.temperature > 0 작성한 쿼리에서 문제점
-
조인 조건(ON)의 문제: ON w1.id = w2.id라고 작성하면, w1과 w2가 같은 행(Row)을 가리키게 된다.
-
WHERE 절의 모순: w2.id > w1.id 조건이 붙어있는데, 위에서 이미 id가 같다고 설정했기 때문에 이 조건은 수학적으로 절대 만족할 수 없는 조건(x > x)이 된다.
그래서 결과가 나오지 않았던 것이다..
수정된 쿼리
SELECT w2.id
FROM Weather w1
JOIN Weather w2
ON DATEDIFF(w2.recordDate, w1.recordDate) = 1
WHERE w2.temperature > w1.temperature;511. Game Play Analysis I
문제설명
Write a solution to find the first login date for each player.
Return the result table in any order.
SELECT player_id, MIN(event_date) AS first_login
FROM Activity
GROUP BY player_id;위의 문제를 풀기 위해서는 단순히 첫 로그인 날짜만을 필요로 하기 때문에 MIN()을 사용하는 것이 효율적인 쿼리이다. 하지만 다른 세부적인 정보가 필요할 때에는 ROW_NUMBER()를 활용하는 것이 더욱 효율적이다.
GROUP BY + MIN(): "요약"이 필요할 때
이 방식은 "데이터를 압축" 하는 방식이다. 여러 개의 행을 하나의 행으로 뭉쳐서 통계 값을 뽑아낼 때 주로 사용합니다.
장점: 코드가 매우 짧고 직관적이다.
한계: '첫 로그인 날짜'는 알 수 있지만, 그날 어떤 기기(device_id)로 로그인했는지는 바로 알 수 없습니다. 만약 첫 로그인 날짜와 함께 그날의 기기 정보까지 가져오려면 다시 JOIN을 해야 하는 번거로움이 생긴다.
ROW_NUMBER(): "상세 내역"이 필요할 때
이 방식은 "전체 행을 유지하면서 순번만 매기는" 방식입니다. 데이터의 원형을 보존하고 싶을 때 사용합니다.
용도: 첫 로그인 날짜뿐만 아니라, "첫 로그인을 했을 때의 device_id나 games_played 정보도 함께 보고 싶을 때" 사용합니다.
장점: 첫 번째 행을 고른 뒤, 그 행의 나머지 데이터(기기 정보 등)를 그대로 가져올 수 있다.
"상위 3명", "날짜별 순위" 등 복잡한 조건(Top-N 문제)을 처리할 때 매우 강력!!
한계: GROUP BY보다는 문법이 조금 더 길고 복잡하다.
ROW_NUMBER() 를 활용한 쿼리
SELECT player_id, event_date AS first_login
FROM (
SELECT player_id, event_date,
ROW_NUMBER() OVER(PARTITION BY player_id ORDER BY event_date ASC) as rn
FROM Activity
) t
WHERE rn = 1;