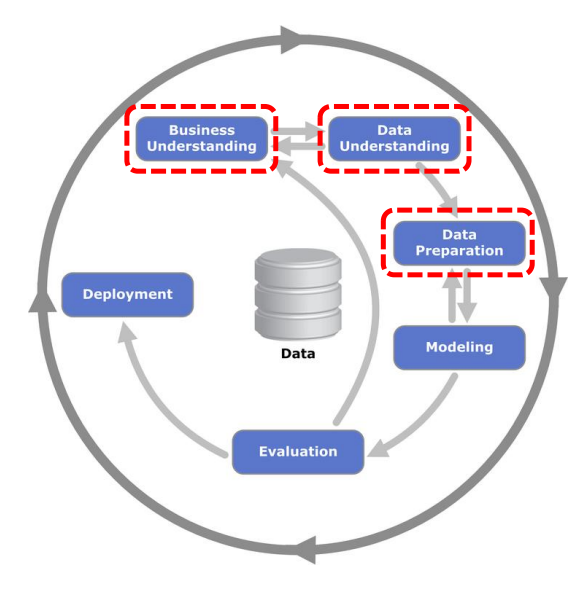
CRISP-DM 프로세스
-
비지니스 이해(Business Understanding)
비즈니스 목표 설정, 상황 파악, 데이터 마이닝 목표 정의, 프로젝트 계획 수립. -
데이터 이해
분석에 사용할 데이터를 수집,특징 파악
초기 데이터 수집, 데이터 기술(Description), 탐색적 데이터 분석(EDA), 데이터 품질 확인. -
데이터 준비
데이터 선택, 데이터 정제(Cleaning), 데이터 생성(Feature Engineering), 데이터 통합 및 포맷팅. -
모델링
다양한 분석 알고리즘을 선택하고 매개변수를 최적화합니다.
모델링 기법 선택, 테스트 설계(Train/Test Split), 모델 구축, 모델 평가. -
평가
기술적인 관점이 아니라 비즈니스 목표 달성 여부를 기준으로 모델을 검증합니다.
결과 평가, 프로세스 검토, 다음 단계 결정.
- 전개
완성된 모델을 실제 운영 환경에 적용하거나 최종 보고서를 작성합니다
전개 계획 수립, 유지보수 계획 수립, 최종 보고서 작성 및 리뷰.
2,3번이 시간이 제일 오래걸린다.
실무 분석 프로세스

분석 정의
Target(관심대상군, 실험군) 정의
- Target 정의
내가 예측하려는 대상 그룹을 정의
분석을 기획하는 단계의 축소판
예) 손해율 증가 -> 보험금 감소 -> 보험 과다청구 건 예측
- Target의 조작적 정의
타겟을 어떤 케이스로 볼건지 정하고, 여러가지 case를 정의함
예) 지금으로부터 1년 이내에 최종 심사 결과 면책된 보험 청구 건
- Target 기초탐색
데이터를 뽑아서 탐색하고, 적절한 분석 기간을 정의한다.
회귀모델 같은 경우 이상치/특이치를 확인함.
예) 코로나 기간 같은 경우는 데이터의 패턴이 깨졌음.
패턴을 찾기 위해서는 적절한 건수가 존재해야되며, 안정성이 확보되어야함.
- non-Target 조작적 정의
Target과 반대되는 그룹, 전체 고객을 포함할 필요는 없고, Target 그룹과 확연한 차이가 있을수록 좋다.
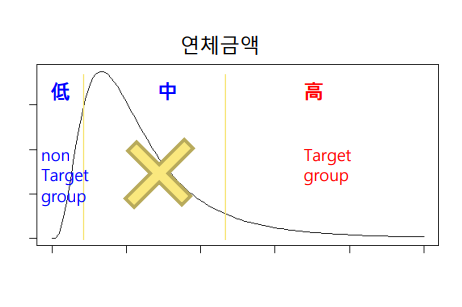
이 때, 애매모호한 그룹은 대상에서 제외하는 것이 좋다.
예) 과거 데이터 기준으로 연체 기간이 완료, 금액이 큰 그룹이 Target 그룹이다.
분석기간 정의
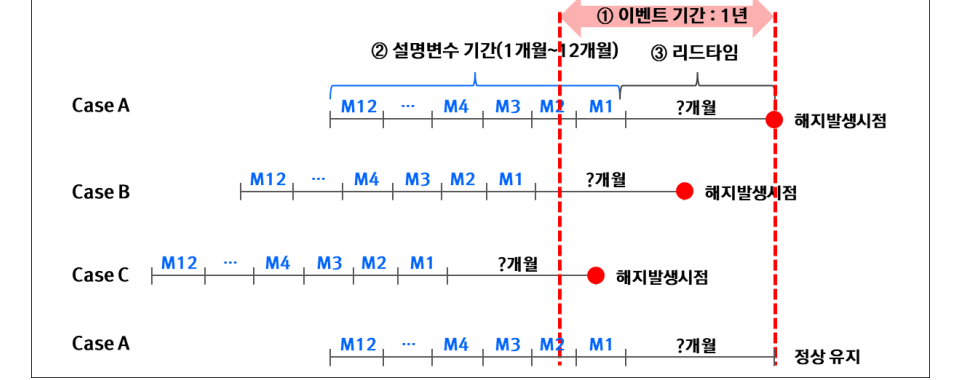
- 이벤트 기간
정답을 라벨링 하는 구간
'해지 예측 모델'이라면, 특정 시점으로부터 향후 12개월 동안 실제로 해지한 사람을 1(해지), 유지한 사람을 0(정상)으로 정의합니다.
이 기간이 너무 짧으면 표본이 부족하고, 너무 길면 데이터의 최신성이 떨어집니다.
- 설명 변수 기간
원인 데이터를 수집하는 구간
고객의 과거 행태(로그인 횟수, 구매 금액, 민원 횟수 등)를 1, 3, 6, 12개월 단위로 집계하여 변수를 생성합니다.
이벤트 기간과 겹치지 않아야 하며, 리드타임을 사이에 두고 앞단에 위치해야 합니다.
- 리드 타임
예측 정보를 정의하기 위한 마케팅 활동에 필요한 최소의 기간
-> 적용해서 액션을 취하기 위한 기간
분석가가 Input 데이터를 어떻게 적용하느냐에 따라 다름.
예측 결과가 나와도 그것을 실행(Action)에 옮길 물리적 시간이 없다면 그 예측은 무용지물이다
예) 리드 타임 적용: 최소 3일 전에는 예측 결과가 나와야 마케팅 캠페인을 세팅할 수 있다"라고 정의한다면, 분석가는 오늘 기준으로 3일 뒤의 사건을 예측해야 합니다.
Sub 모형 정의
특성이 다르다면 모델을 구분해서 만들어야겠지만, 구축에 대한 시간/비용적인 문제가 있음.
-> 특성을 고려한 1~2개의 변수만 고려하는 것이 현실적
모형 구분 변수의 범주 개수만큼 독립적인 sub 모형이 생성됨.
시계열 모형 같은 경우는, 상품,지역에 따라서 모형을 만들기때문에 모형 개수가 많은특징이 있음.
메스 모델 만들어서 오차율을 뽑아서, 오차율이 큰 것 부터, 중요한 제품부터 모델링을 시작함.
데이터 탐색 목적
- 사용할 수 있는 설명 변수 탐색
가장 먼저 우리가 가진 '재료'가 무엇인지 파악하는 단계(사용할 수 있는 설명 변수들을 탐색)
특이값, 결측치를 통해 분석 대상에서 제외할 데이터를 정제함.
2. 파생 변수 탐색
추가로 사용할 수 있는 설명 변수들이 무엇이 있는지 탐구(feature 엔지니어링)
도메인 기반의 가설을 세우고 , 변수를 파생
- Target 유의성 분석
수백개의 변수 중 정답(Target)에 관련있는 변수를 골라냄.
데이터 탐색
변수의 파생
- 통합과 세분화
ex) 통화 시간 -> 주간 통화시간, 야간 통화시간 .....
- 특성의 시점
최근성 고려 : 최근 1,2개월 평균
주기성 고려 -> 12개월 평균, 24개월 평균
- 증감율
단기간 증감율 : 과거 3개월 대비 1개월 평균 비율
장기간 증감율
- 구간화
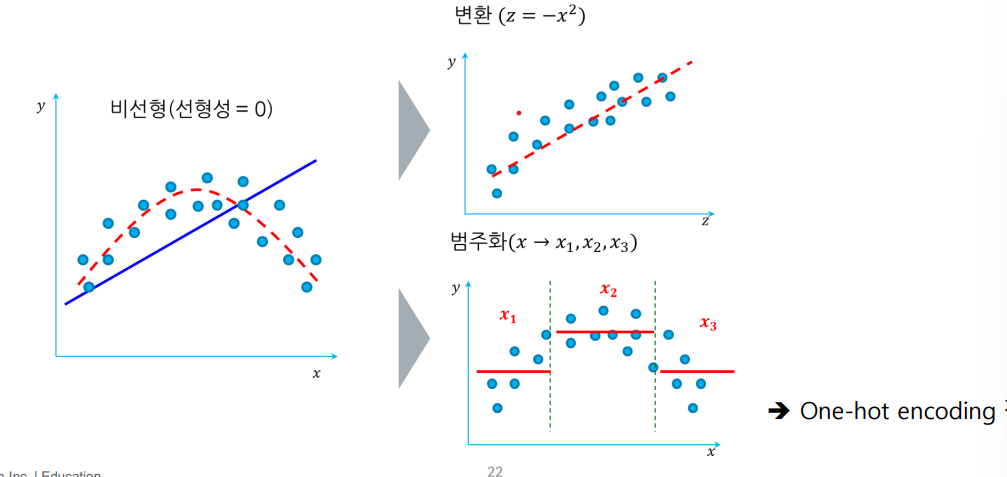
범주화 할 때, 여부 변수로 만들어서 넣음.(가변수,정보의 손실이 일어날 수도 있다.)
알고리즘은 행렬계산이기 때문에 선형적인 걸 선호함.
선형적인 관계를 만들어주기 위해 연속형 변수를 구간으로 나눔.
알고리즘을 태운다는건 텍스트(비정형데이터)도 청킹해서 숫자로 바꿔서 행렬로 바꿔서 알고리즘에 투입을 시키는거임.-> 통계학에서는 가변수라고 명명
-
가변수 (One-hot encoding)
-
sav데이터의 ed 변수 -> 2. ed 변수의 빈도 분석 결과 -> 가변수의 생성: 연속형으로 변경해주기 위해 기준 범주를 결정하여 가변수를 생성함.
데이터의 통계적 특성(스케일, 상관계수, 해석 가능성)을 고려하지 않고 0,1 형태의 가변수 숫자 형태에만 만족해서는 안 됨
변수의 선택
-
모든 변수를 사용 ?
수행 시간 및 비용: 변수가 많아질수록 모델 학습 시간과 실제 서비스 적용 시 연산속도가 늘ㅇ남.
변수 관리의 어려움: 적용 단계에서 갯수가 많은거보다, 핵심 변수 10개를 관리하는 것이 효율성
과적합: 너무 많은 변수는 노이즈까지 학습. 새로운 데이터에서 성능이 떨어짐. -
모델의 간명성
-
변수 선택 방법론
단계 선택법
IV
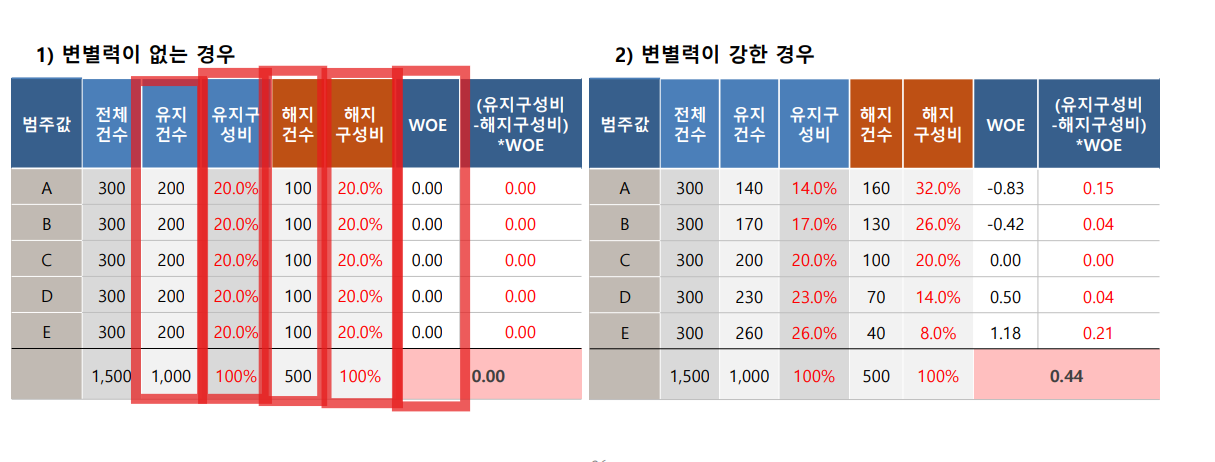
유지랑 해지를 차이를 보는 통계량
WOE = LN(유지구성비/해지구성비)
∑(유지구성비-해지구성비)*LN(유지구성비/해지구성비)
유지구성비:세로 합
값이 클수록 유의미한 변수임을 의미, 명확한 기준을 없으나, 보통 0.1 기준을 많이 사용함.
1:1로 보기 때문에, 타이트하게 치게 되면 교호작용이 적용되어서 데이터값이 이상해질수도 있어서, 보수적으로 너무 이상한 것만 뺀다.
교호작용 : 두 개 이상의 변수가 결합했을 때, 개별 변수가 가진 영향력의 합보다 더 크거나 다른 효과를 내는 현상입니다.
wrapper Method - Boruta 알고리즘
통계적으로 유의미한 변수인지 검증하는 것이 목적
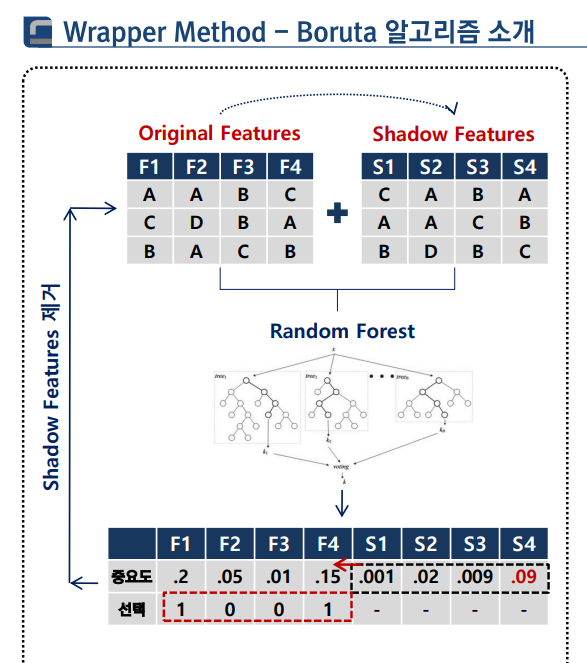
-
섀도우 피처(Shadow Features) 생성
방법: 원본 변수(F1~F4)들의 값을 무작위로 섞어서(Permutation) 가짜 변수(S1~S4)를 만듬. -
원본 변수와 섀도우 피처를 한데 묶어 모델을 학습시킨 후 랜덤 포레스트를 만들어서 각각의 변수 중요도(Feature Importance)를 뽑음.
-
쉐도우 피쳐들이 보이는 중요도에서 제일 높은애 보다도 낮은 중요도를 보이는 애들을 쓰지않음.
변수 선택 예시
전체 변수 POOL(영역별 단일 변수, 기간 별 요약 변수, 파생 변수) -> 1차 변수 선택 -> 2차 변수 선택(Boruta 알고리즘 적용)
최종 데이터 셋 구조
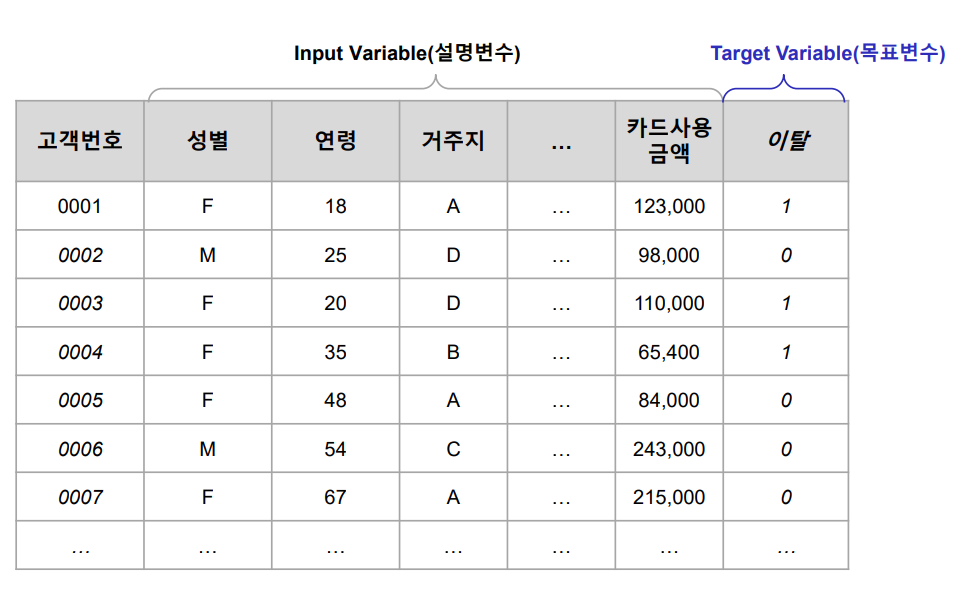
모델링
모델을 만들어나가는 과정을 모델링이라고 함
모델이란
어떤 현상을 일반화된 규칙이나 산술식으로 표현한 것.
예측 모델은 Target의 변동을 다른요소(설명 변수)를 이용한 규칙이나 산술식으로 표현한 것
예측 분석 알고리즘의 분류
예측하고자 하는 Target(목표)변수가 있는가?
- 지도(통제 학습)
예측하고자 하는 Target 변수가 있느냐
GLM(일반화 선형 모형)
- 선형회귀, 로지스틱회귀, 감마회귀
Decision Tree(의사결정 나무)
SVM(서포트 벡터 머신)
Random Forest
GBM, XGBoost
DNN, RNN, CNN
- 비지도(비통제)하습
예측하고자 하는 Target 변수가 없음.
정답이 없음
Factor Analysis(요인분석)
PCA(주성분분석)
Cluster Analysis(군집분석)
Anomalies(이상치 탐지)
KNN(최근접 이웃법)
지도(통제)학습
주로 예측 분석을 할 때 쓰임.
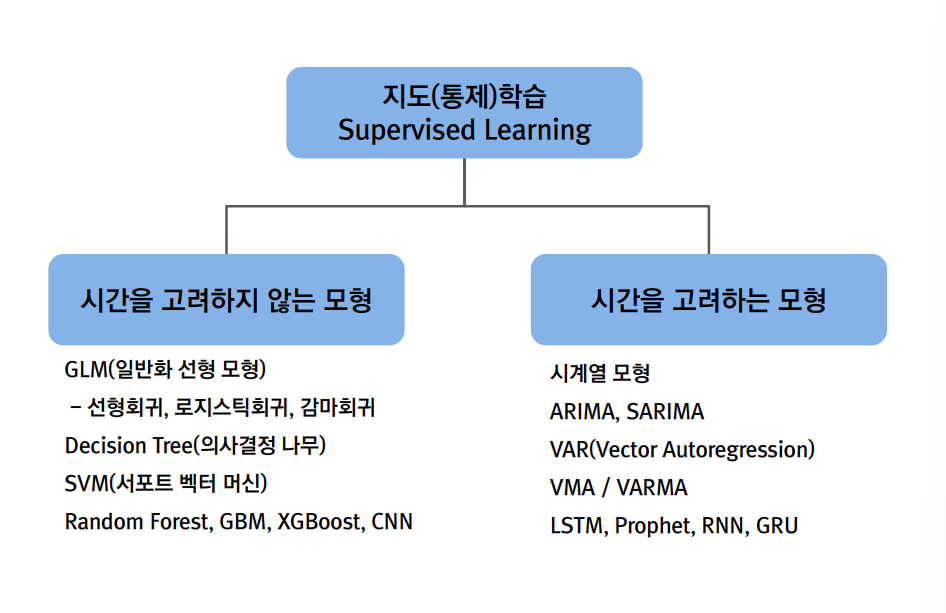
1. 시간을 고려하지 않는 모형
변수 내에서 과거 시점 값들을 새로운 설명변수처럼 변환해서 사용함.
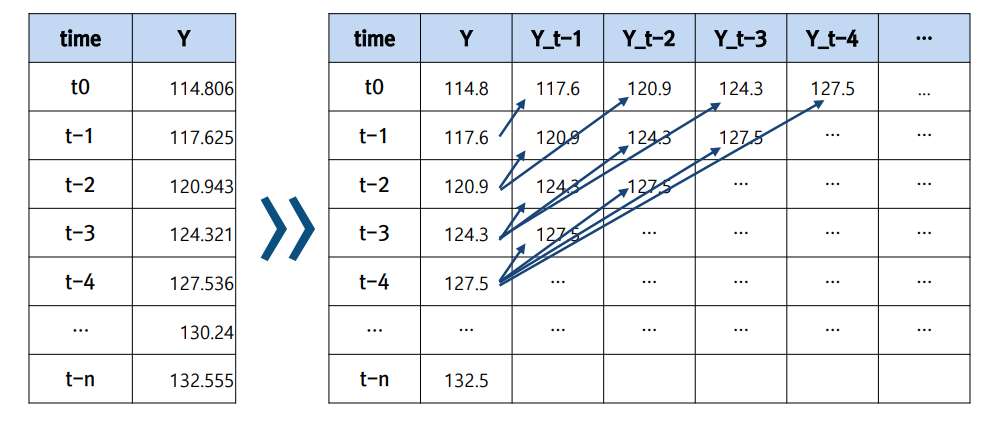
이걸 랜덤포레스트에 그냥 때려넣으면 뭐가 뭔지 모름.
Y값을 두고 예측을 해야되는데,이 값에 영향을 주는 t-1,t-2 등 설명변수로 만들어줌.
-> 무작정 까지 변수를 만들면 모델이 너무 복잡해지고 연산 비용이 커지게 되니까 ACF, 도메인 지식 바탕으로 적절한 과거를 결정함.
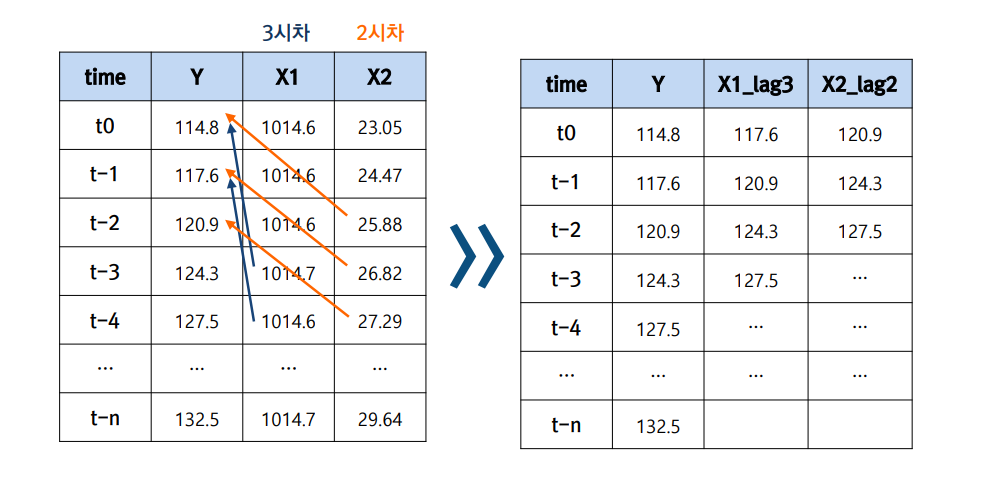
변수마다 결과()에 영향을 주는 시점(Lag)이 다름.
Granger Causality(그랜저 인과관계) 분석 등을 통해 "X의 과거 값이 Y의 현재 값을 예측하는 데 통계적으로 얼마나 유의미한가?"를 계산하여 최적의 시차를 결정.
2. 시간을 고려하는 모형
Time이라는 변수를 고려해줘야한다.
몇가지 빼고는 상호배반적이다.
알고리즘 특성상 설명 변수를 많이 고려할 수 없다.
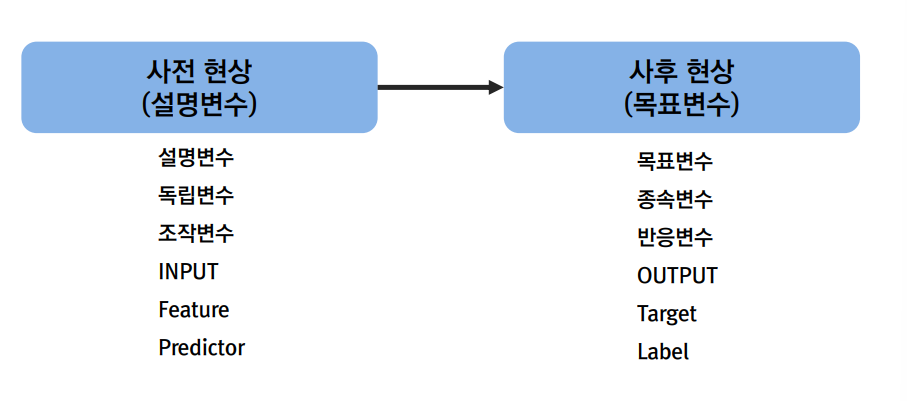
결국 인과관계의 패턴을 파악하는 것이 모델의 학습 과정이다.
사전현상(설명 변수) -> 사후 현상(목표 변수)
- 분류모델(Classification Model) : 목표변수가 범주형인 경우
- 회귀모델(Regresion Model) : 목표변수가 연속형인 경우
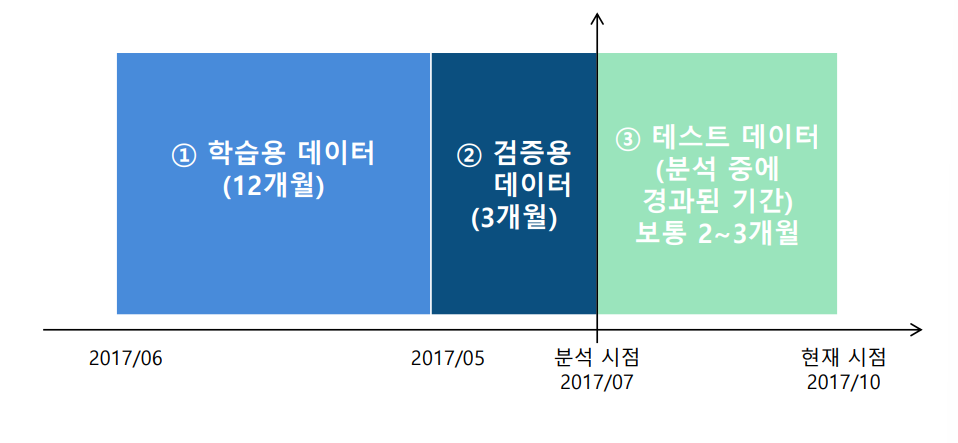
데이터 파티션
1. 일반화
1) 랜덤 샘플링에 의한 방법
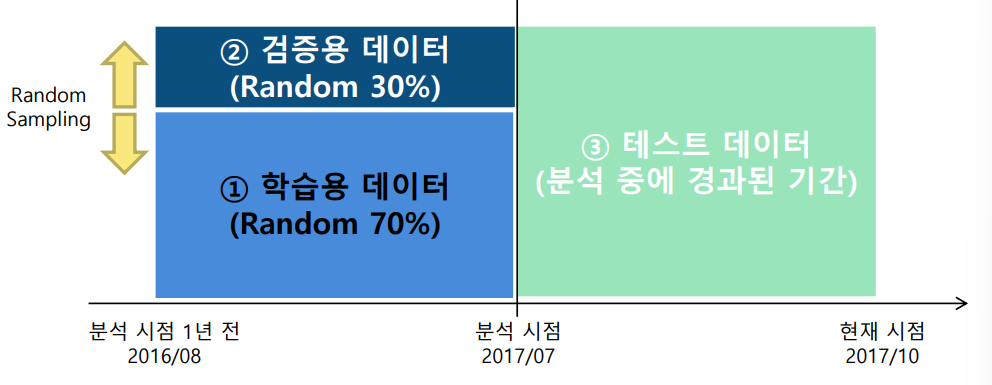
- 학습용 데이터: 모형을 생성하는데 사용하는데 데이터
- 평가용 데이터: 생성된 모형을 적용해 안정성을 평가
- 테스트 데이터: 분석시작 후 경과된 기간에 새로 발생한 데이터
2. 시간에 의한 방법
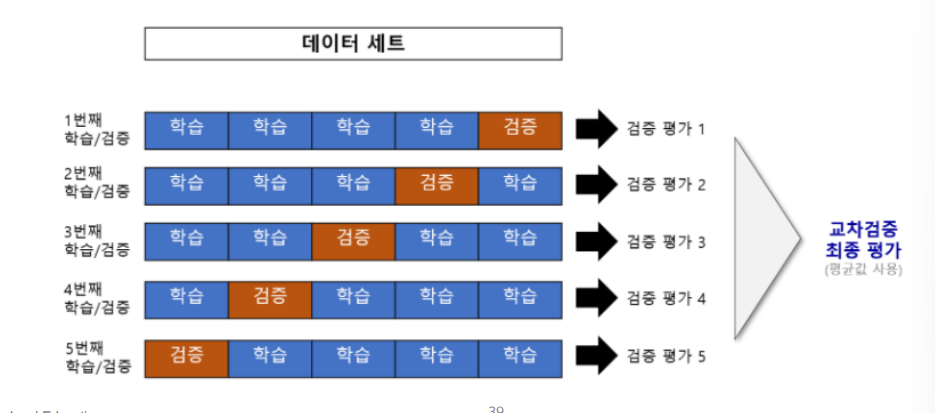
3. k-fold Cross Vaildation
교차 검증의 절차
샘플링이 편향되면 어떡하지?에서 나온 방법
밸런싱
회귀모델 경우 상관이 없지만, 분류 모델일 경우 집단이 적절히 섞여있어야 패턴화하기 수월하기 때문에 밸런싱을 해준다.
Target 그룹의 비율이 너무 작은 경우 패턴이 잘 잡히지 않을 수 있기 때문에 7:3 ~5:5 비율로 맞추고 모델링을 해 보는 것이 필요
Under/Over Sampling

over sampling은 과적합 이슈로 잘 쓰지 않음.
모델 결과
분류 모델의 최종 결과: 확률(P)
분류 모델은 단순히 "이탈이다/아니다"라고 단정 짓기보다, 먼저 0과 1 사이의 연속적인 확률값을 내놓음.
분류 모델은 단순히 "이탈이다/아니다"라고 단정 짓기보다, 먼저 0과 1 사이의 연속적인 확률값을 내놓음.
Logistic Regression, Random Forest, GBM, Neural Network 등은 각각의 수학적 방식으로 저 확률을 계산
사전 비율에 따른 예측 Score와 평가를 위한 기준점
분류 모델을 만든 후, 모델이 뱉어내는 '확률값'을 어떻게 해석하고 최종 의사결정에 활용
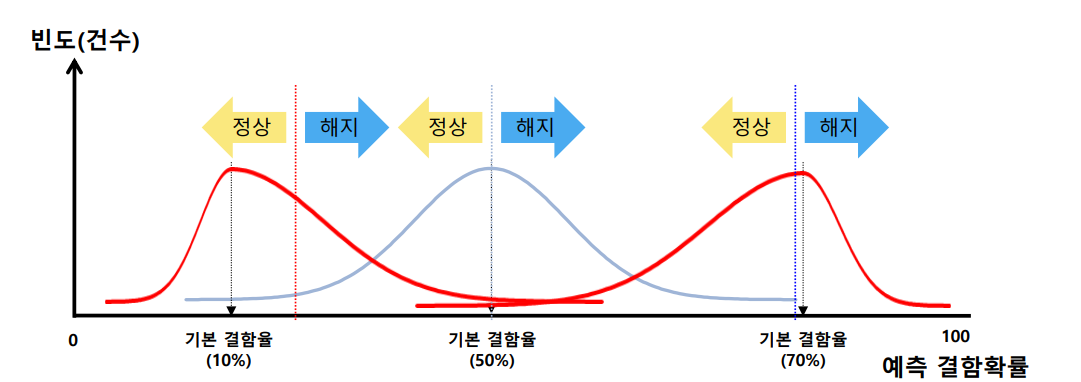
- 예측 점수는 '사전비율' 근방에서 분포됨
모델은 아무런 정보가 없을 때 "원래 데이터에 결함이 있는 확률(사전비율)"을 기준으로 예측을 시작
- 예측 점수는 '사전비율' 근방에서 분포됨
- 기준점 설정
모델이 0~100 사이의 점수를 주면, 우리는 어디선가 선을 그어 "여기서부터는 결함(해지)이다."라고 선언
- 기준점 설정
예측된 분포가 사전 비율이 뭐냐에 따라서 달라짐.
1. 사전 비율 10%인 곳에서 받은 60점: "이 데이터는 기본(10%)보다 6배나 위험해! 이건 확실한 결함이야!"
2. 사전 비율 70%인 곳에서 받은 60점: "이 데이터는 기본(70%)보다 오히려 깨끗해! 이건 정상이야!"
결론: 절대적인 점수 수치(60점)보다 "기본(사전 비율)보다 얼마나 더 높은가?"가 훨씬 중요함.
추정(Estimation) / 회귀(Regression)의 특징
평가
혼돈 행렬
Target이 범주형인 경우, 모델링 결과 도출된 예측 값과 실제 값을 비교하기 위한 표
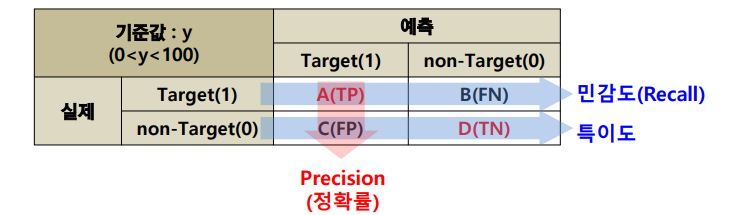

스레시홀드(Threshold, 문턱값)를 정함에 따라 이 표 안의 A, B, C, D 숫자가 완전히 뒤바뀜.
ROC
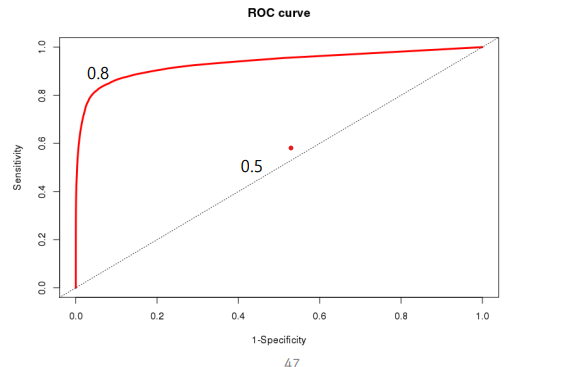
ROC 곡선
Score를 Threshold 값을 변경해 가면서 특이도와 민감도를 산출
1-특이도(Specificity)와 민감도(Sensitivity)를 x, y축으로 놓은 그래프
AUROC
ROC 곡선 아래의 면적
1에 가까울수록 성능이 우수한 모델
Precision 도표와 Lift(향상도)
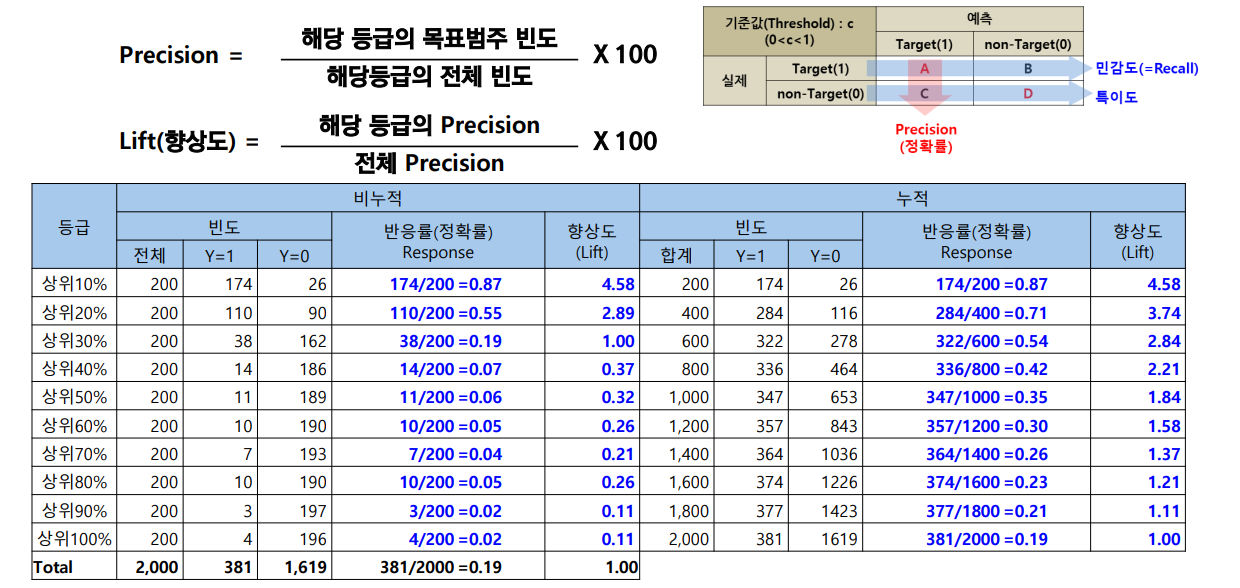
1. 분석 방법 (Methodology)
- 데이터 분할: 모델 예측 점수(Score)를 기준으로 전체 데이터를 내림차순 정렬.
- 등급화: 상위 10%씩 동일 인원()으로 총 10개 등급(Decile) 생성.
- 특징: 상위 등급일수록 타겟() 밀도가 높으며, 추출 인원()을 줄일수록 Precision은 상승함
score값을 기준으로 동일한 n수가 들어가도록 함. 그 중에 내가 찾고자 하는 개체 수를 씀. 그곳에 precision을 구함.
상위 score 일수록 y=1이 많음.
n수를 적게 뽑으면 뽑을수록 precision이 올라감.
-> 모델이 우수할수록 상위 등급에 (타겟)이 쏠리게 됨. 수를 적게 뽑을수록(예: 상위 1%만 추출) 그 안의 정답 밀도는 극도로 높아지므로 Precision(정밀도)은 자연스럽게 올라가게 됨.
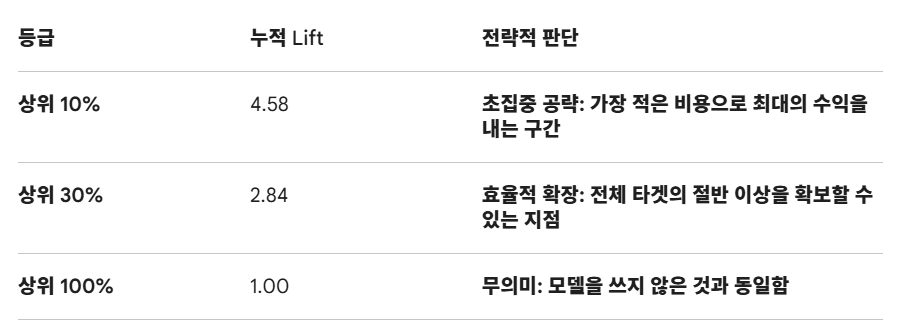
여기서 19프로 대비해서 87프로에 대해서 얼마나 성능이 좋냐가 lift임.
약 4.5배
이 모델을 사용하면 아무나 잡고 마케팅할 때보다 4.58배 더 효율적으로 고객을 찾아낼 수 있음.
그 외 접합도 평가 방법
Target이 연속형인 경우
오차율을 고려하여 직관적인 평균절대오차율(MAPE)을 주로 사용

예측 모델링 기법의 이해
1. 로지스틱 회귀 모형
통계 모형
분류 모델. 선형관계인지 보고 회귀 분석을 해야됨.
- 오즈 : 실패 대비 성공의 비율"
log 오즈를 취하면 로지스틱 함수에서 x의 선형결합으로 표현이 된다.확률은 0과 1 사이로 갇혀 있지만, 오즈는 성공 확률이 높아질수록 까지 쭉 뻗어 나갈 수 있습니다. 즉, 선형적인 수치로 영향력을 비교하기 훨씬 좋아짐
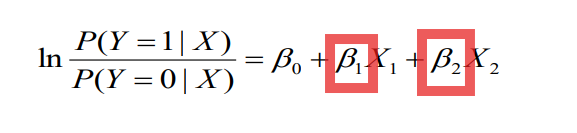
는 각 설명변수() 앞에 붙는 계수(Coefficient)
ex) 이 '상담원 통화 횟수'이고 이 0.5라면: "상담원과 통화를 한 번 더 할수록 이탈 확률이 약 배만큼 높아진다"라고 현업에 해석을 제공할 수 있습니다.
설명변수들 간에 교호작용을 고려하기 어려움
2. Decision Tree
다중 if 문
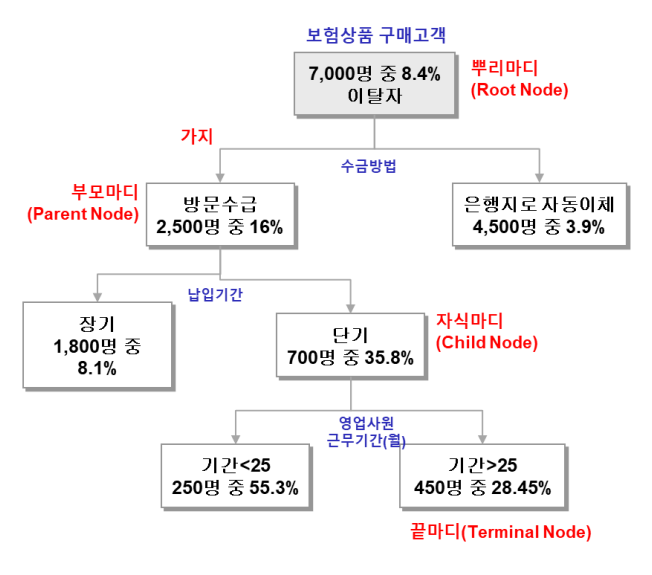
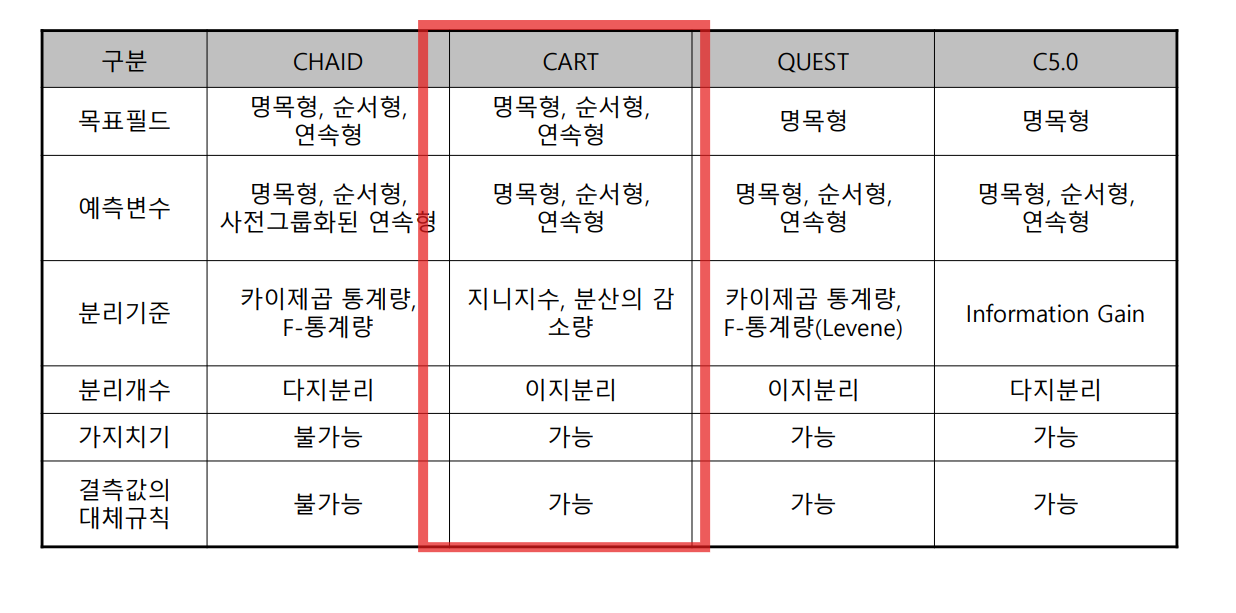
설명변수들 간 교호 작용을 자동으로 찾아줌(회귀 분석에 비해 교호 작용 고려가 쉬움)
하지만, 과적합 문제가 발생 -> 머신러닝이 나옴
Neural Network(신경망)
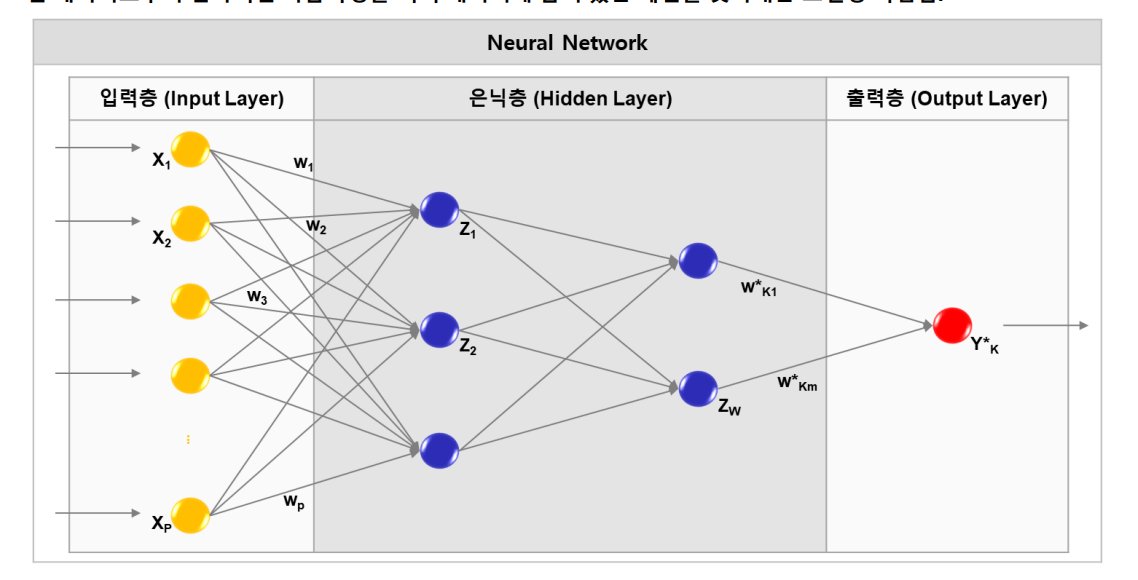
은닉층 안에 있는 각 노드들은 활성화 함수이다.
비선형 모형이기 때문에 예측결과에 대한 원인을 설명할 수 없음(Black-Box)
앙상블
예측모형의 Bias와 Variance
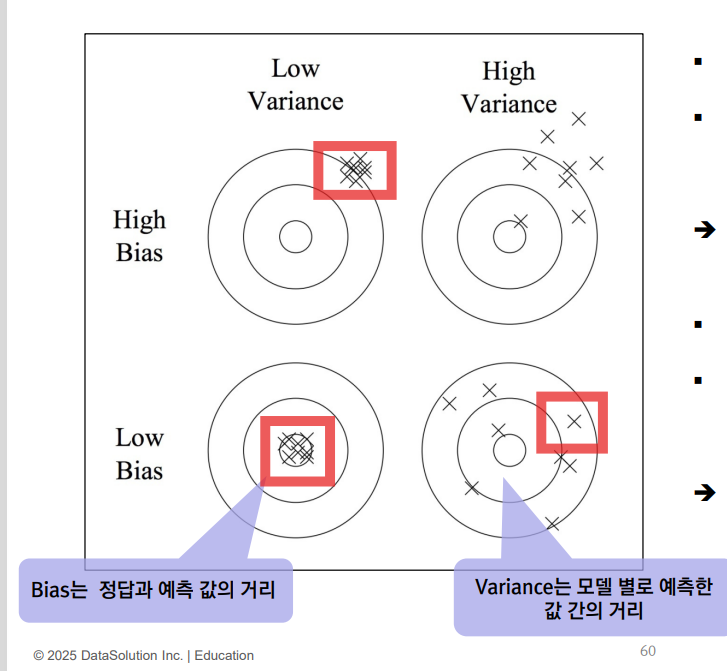
여러개의 모델을 합침. = 머신러닝 기법
분산이 큰 경우 = 배깅
편차가 큰 경우 = 부스팅
Bagging(배깅)
대표적인 방법 : 랜덤 포레스트
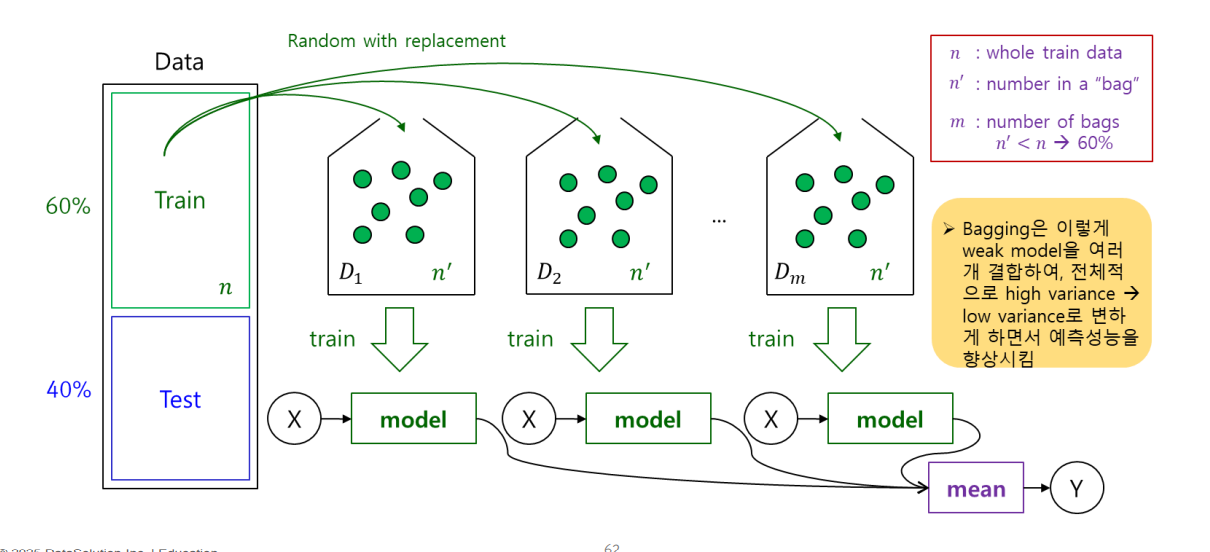
학습 데이터를 랜덤으로 sampling하여 여러 개의 bag으로 분할하고, 각 bag별 로 학습한 후, 각 결과를 합하여 최종 결과를 추출함
모델을 동등하게 보고 병렬적으로 평가해 결과값을 추출함.
부스팅(boosting)
대표적인 방법: Adaboost
Adaboost
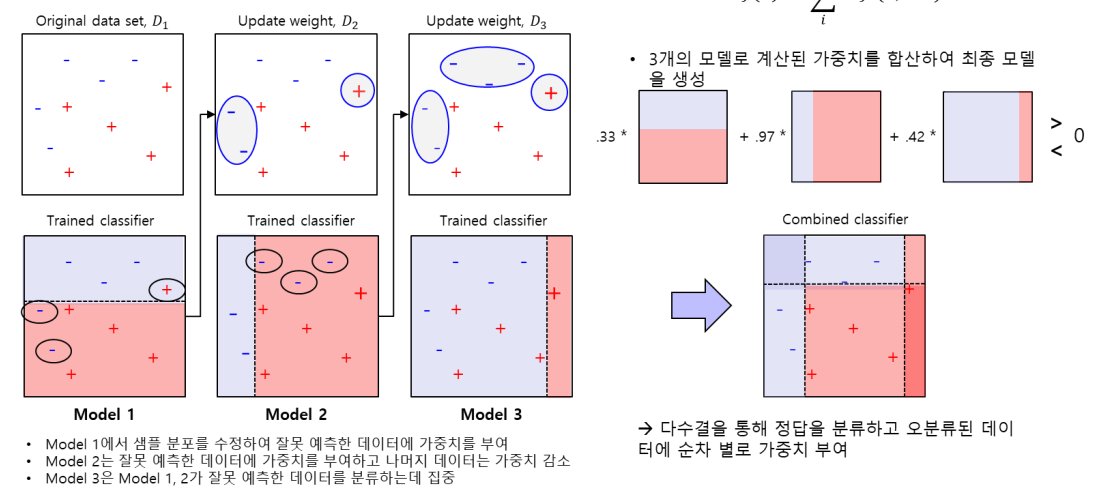
오분류하면 데이터에 가중치를 부여해 비용을 세게 줌.
GBM
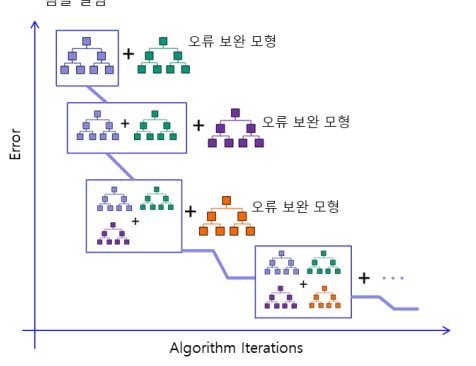
직렬
Support Vector Machine
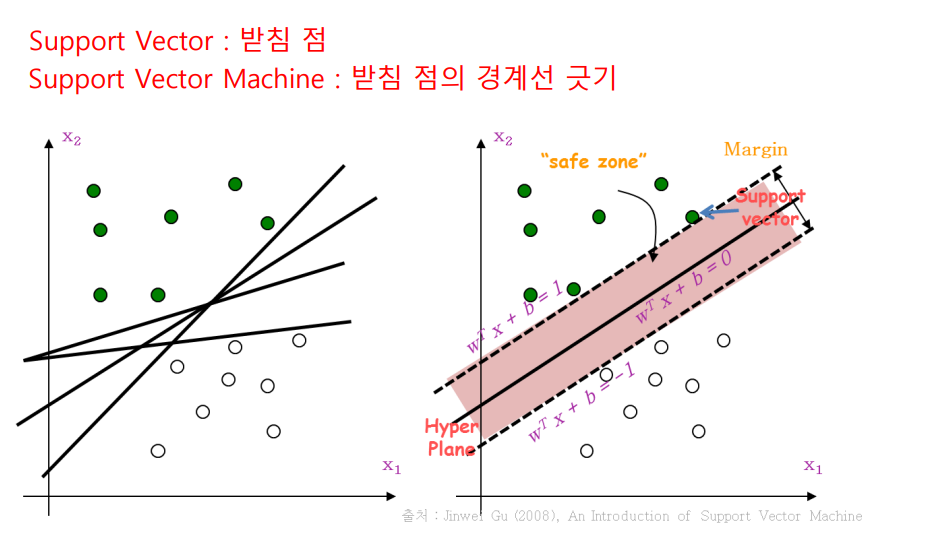
초평면이 가장 큰 직선을 선택함.
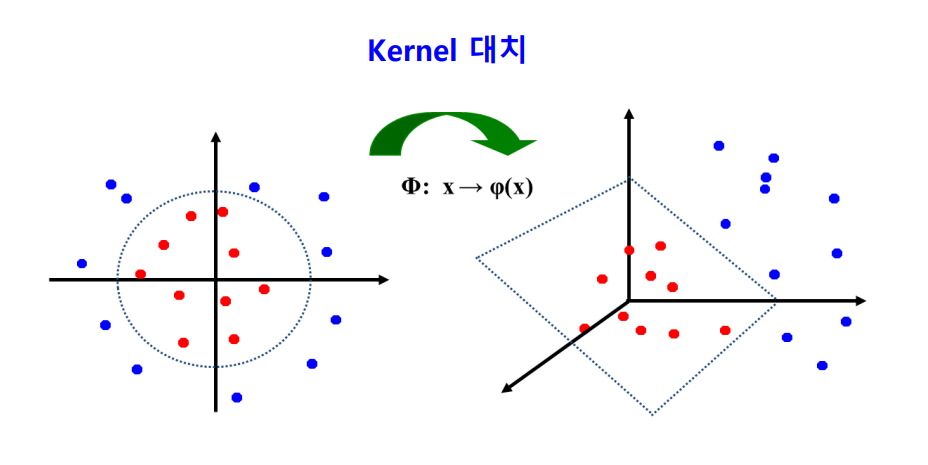
선형분리가 불가능한 경우 데이터를 왜곡시켜 선형으로 만듦.
딥러닝
Neural Network의 변형
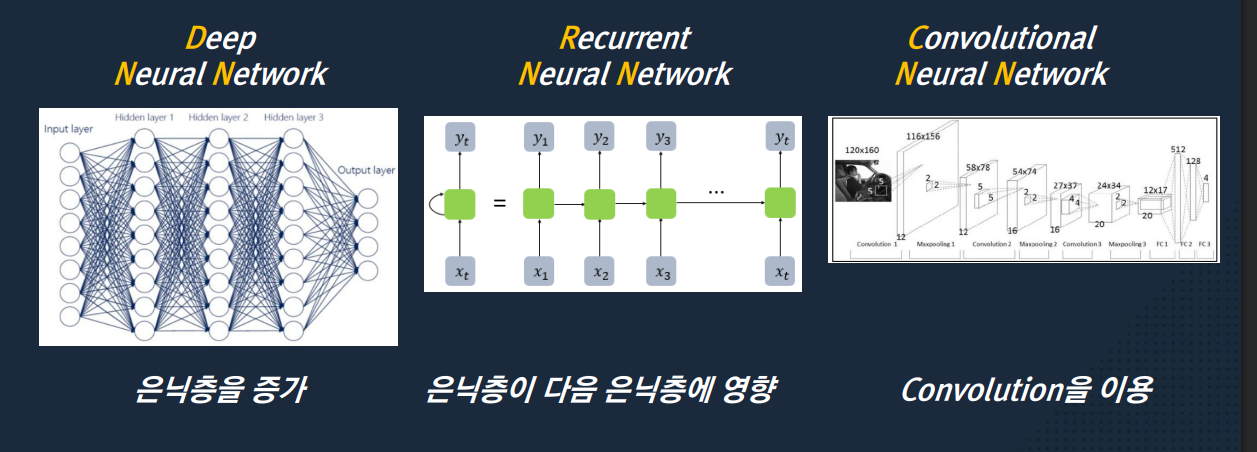
- DNN: 가장 기본적인 딥러닝 형태로, "정형 데이터"를 다룸
- RNN: 데이터에 "순서(Sequence)"나 "시간의 흐름"이 중요할 때 사용. 이미지에서 은닉층이 다음 층에 영향을 준다는 화살표가 바로 '기억'을 한다는 의미
자연어 처리나, 시계열 예측, 음성 인식 등에 쓰임.
- CNN: 주로 이미지 분석할 때 씀.
RGB가 수치값이기 때문에 합성곱(Convolution) 연산
