1. 딕셔너리(Dictionary)
- 키(key)와 값(value)으로 구성된 한 쌍의 데이터를 담을 수 잇는 자료구조
- 중복된 키가 포함 될 수 없다
- 키는 수정 불가능한 것만 사용 가능(문자열, 숫자, 불린 값(True/False), 튜플 등)
- 키 값으로 리스트 사용 불가
- 값은 변경 가능
# 표현방법
{키1: 값1, 키2: 값2}
# 요소에 대한 접근
딕셔너리_이름[키] 또는 get(키)
{} # 빈 딕셔너리
{ "name" : "홍길동", "age" : 20,"취미" : ["영화 감상", "게임", "독서"] }
# 딕셔너리 요소 개수 확인
d = {}
d1 = {'a':1, 'b':2,'c':3 }
print(len({})) >> 0
print(len(d)) >> 0
print(len(d1)) >> 3
print(len({'a':1, 'b':2,'c':3 })) >> 3
#요소 접근
d = { "name" : "홍길동", "age" : 20, "취미" : ["영화 감상", "게임", "독서"] }
print(d["name"]) >> 홍길동
print(d["취미"]) >> ["영화 감상", "게임", "독서"]
print(d["이름"]) >> KeyError
print(d.get("name")) >> 홍길동
print(d.get("취미")) >> ["영화 감상", "게임", "독서"]
print(d.get("이름")) >> None
#키가 중복되면 나중에 나오는 값으로 지정
d = { "name" : "홍길동", "age" : 20, "취미" : ["영화 감상", "게임", "독서"],
"name" : "김길동" }
print(d["name"]) >> 김길동
📌 요소 값 추가/수정
- 단일 요소 수정
d = {1:2, False: 20, (1,2): "튜플"}
d[1]= 3
d[False] = "불린 값"
d[(1,2)] = [1,2]
d['key'] = 'value'
print(d[1]) >> 2
print(d[False]) >> 불린 값
print(d[(1,2)]) >> [1,2]
print(d['key']) >> value
- update(): 여러 요소 수정
d = { 1 : 2, False : 20, (1, 2) : "튜플" }
d.update({1:3, False:"불린 값", (1,2):[1,2],"key":"value" })
print(d[1]) >> 3
print(d[False]) >> 불린 값
print(d[(1,2)]) >>[1,2]
print(d["key"]) >> value
- in : 키가 딕셔너리에 있는지 확인
d = {1:2, False:20, (1,2): '튜플'}
if 1 in d:
print(d[1])
else:
print("1은 d의 키가 아닙니다")
>> 2📌 for문
- 키를 순차적으로 변수에 저장
d = {1:2, False:20, (1,2): '튜플'}
#1
for key in d:
print(f"{key}:{d[key]}")
#2
for key in d.keys():
print(f"{key}:{d[key]}")

딕셔너리의 모든 키와 해당하는 값을 출력해보자
>> person = {'name': 'John Doe', 'age': 28, 'hobby': 'Reading'}
>> 출력 형태는 "키: 값"
person = {'name': 'John Doe', 'age': 28, 'hobby': 'Reading'}
for key, value in person.items():
print(f"{key}: {value}")

- values(): 값만 한 개씩 접근
- items(): 키와 값에 동시에 접근
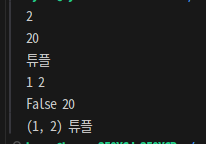
d = {1:2, False:20, (1,2): '튜플'}
for n in d.values():
print(n)
for k,v in d.items():
print(k, v)
📌 삭제
- del(딕셔너리_이름[키]): 특정 키만 삭제
- clear(): 딕셔너리 전체 삭제
d = {1:2, False:20, (1,2): '튜플'}
del(d[1])
print(d) >> {False:20, (1,2): '튜플'}
d = {1:2, False:20, (1,2): '튜플'}
d.clear()
print(d) >> {}💡 이름과 나이를 입력받아 딕셔너리에 저장하고, 저장된 딕셔너리를 출력해보자
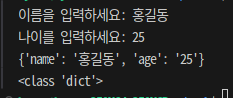
def store_in_dict():
name = input("이름을 입력하세요: ")
age = input("나이를 입력하세요: ")
person = {"name": name, "age":age}
print(person)
print(type(person))
store_in_dict()
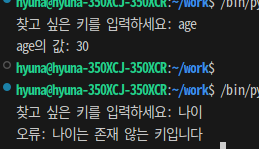
💡 키 값을 입력받고 해당 키에 대한 값을 딕셔너리에 찾아서 출력해보자
def access_dict():
data = {'name': 'Alice', 'age':30}
key = input("찾고 싶은 키를 입력하세요: ")
try:
print(f"{key}의 값: {data[key]}")
except:
print(f"오류: {key}는 존재 않는 키입니다")
access_dict()
💡 age키에 해당하는 값을 반환하는 코드를 작성해보자
>> my_info = {'name':'rokey', 'age':28, 'job':'developer'}
def solution(my_info):
my_info = {'name':'rokey', 'age':28, 'job':'developer'}
answer = my_info['age']
return answer
💡 딕셔너리에 'hobby'라는 키와 'Reading'이라는 값을 추가하고, 'hobby' 키에 대한 값을 반환하는 코드를 작성해보자
>> person = {'name': 'Suji Na', 'age': 28}
def solution(person):
person = {'name': 'Suji Na', 'age': 28}
person['hobby'] = "Reading"
answer = person['hobby']
returm answer
2. 집합(set)
-
수학에서 집합을 나타내는 자료 구조
-
합집합, 교집합, 차집합 등의 연산 가능
-
순서가 없고 동일한 데이터가 두 개 이상 존재 할 수 없다
-
요소의 순서가 랜덤하게 출력
-
리스트는 포함 불가, 튜플은 가능
💡 키 값 없이 값만 존재 💡
💡 set()을 사용하면 리스트를 인수로 전달받을 수 있다 💡# 집합을 리스트로 변환 lst = list(집합) # 구성 방법 s = set() set([1,2,3]) set("string")list = [1, 2, 3, 4, 5] s = set(list) print(s) >> s = {1, 2, 3, 4, 5}📌 요소 값 추가/수정
-
add() : 단이 요소 추가
-
update(): 여러 요소 추가
a = set([1,2,3])
a.add("string")
print(a) >> {1,2,3, 'string'}
a = set([1,2,3])
a.update("string")
print(a) >> {1, 2, 3, 't', 'n', 's', 'r', 'i', 'g'}- in: 요소가 집합에 있는지 확인
s = { 1, 2, 20, (1, 2), "문자열" }
if 1 in s:
print("1은 집합 s에 포함되어 있습니다")
else:
print("1은 집합 s의 요소가 아닙니다")
>> 1은 집합 s에 포함되어 있습니다📌 집합
- 교집합: &, intersection()
- 합집합: |, unions()
- 차집합: -, diffs()
s1 = { 1, 2, 20, (1, 2), "문자열" }
s2 = { 1, 2, 3 }
ints = s1 & s2
print(ints)
ints2 = s1.intersection(s2)
print(ints2)
unions = s1 | s2
print(unions)
unions2 = s1.union(s2)
print(unions2)
diffs = s1 -s2 # s1에 포함된 s2 요소 제거
diffs2 = s1.difference(s2)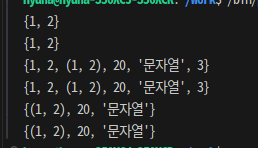
💡 여러 개 숫자를 입력받아 집합을 생성하고 출력해보자
def create_and_print_set():
num = input("숫자를 공백으로 구분하여 입력하세요: ").split()
num_set = set(num)
print("생성된 집합: ", num_set)
create_and_print_set()
💡 딕셔너리에 추가할 키와 값을 입력받아 기존 딕셔너리에 추가해서 출력해보자
def update_dict():
data = {'name': 'Alice','age': 30}
key = input("추가할 키를 입력하세요: ")
value = input("추가할 값을 입력하세요")
data[key] = value
print("업데이트된 딕셔너리: ", data)
update_dict()

💡 주어진 딕셔너리에서 값이 20보다 큰 아이템만 포함하는 새 딕셔너리를 생성해 출력해보자
>> data = {'Alice': 25, 'Bob': 19, 'Cathy': 34, 'Dan': 20}
def filter_dict():
data = {'Alice':25, 'Bob':19, 'Cathy':34, 'Dan':19}
filtered_data = {k:v for k,v in data.items() if v >20}
print("값이 20보다 큰 아이템: ", filtered_data)
filter_dict()

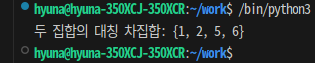
💡 대칭 차(양쪽 집합 중 어느 한쪽에만 속하는 요소들의 집합)계산해서 출력하기
def symmetric_difference_of_sets():
set1 = {1, 2, 3, 4}
set2 = {3, 4, 5, 6}
symmetric_difference = set1 ^ set2
print("두 집합의 대칭 차집합:", symmetric_difference)
symmetric_difference_of_sets()
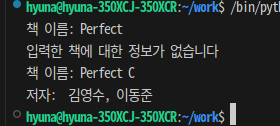
💡 책에 대한 정보를 저장한 딕셔너리에 대해 다음과 같이 출력하는 프로그램을 작성해보자
>> books = {'파이썬 개론‘: [’홍길동’], ‘Perfect C': [’김영수‘, ’이동준‘],'컴퓨터 개론’: [‘최환수‘, ’주용호‘, ’박해성‘]}
>> 책이름: Perfect C 저자이름: 김영수, 이동준
books = {"파이썬 개론": ["홍길동"],
"Perfect C": ["김영수", "이동준"],
"컴퓨터 개론": ["최환수", "주용호", "박해성"]}
while True:
name = input("책 이름: ")
if name in books:
author = ', '.join(books[name])
print("저자: ", author)
break
else:
print("입력한 책에 대한 정보가 없습니다")