
드디어 파이썬 마지막 시간 🤪
정규표현식에 대해 알아보자
정규표현식은 일정한 규칙을 가진 문자열을 표현하는 방법이다
이를 사용하면
✔ 특정 규칙(패턴)을 가진 문자열을 쉽게 찾을 수 있다
✔ 반복적인 텍스트 처리 자업을 자동화할 수 있다
✔ 어렵고 복잡한 검색 조건을 구현해 문자열을 검색 할 수 있다
정규표현식(Regex)
일정한 규칙을 가진 문자열을 표현하는 방법
- 정규표현식은 re모듈을 가져와서 사용
📌 r (raw string)
* 문자열 안에 있는 백슬레시('\')를 그대로 해석하도록 하는 문자열 리터럴
# 일반 문자열
pattern = '^Hello'
pattern_with_newline = '^Hello\\nWorld'
# raw string
pattern_raw_with_newline = r'^Hello\nWorld' # 이 경우 백슬래시를 한 번만 써도 된다
print(pattern) >> ^Hello
print(pattern_with_newline) >> ^Hello\nWorld
print(pattern_raw_with_newline) >> 출력: ^Hello\nWorld
1. match/search
✔ match: 문자열이 특정 패턴으로 시작하는지 확인
* 문자열 시작부터 패턴이 일치하는지 확인
✔ search: 문자열에 특정 패턴이 포함되어 있는지 확인
* 문자열 전체를 검색해 어느 부분이든 패턴과 일치하는 첫 부분 찾기
| 함수 | 동작 방식 | 예시 | 매칭 여부 |
|---|---|---|---|
match | 문자열의 시작부터 패턴이 일치하는지 확인 | re.match(r"\d+", "123abc") | 매칭됨 |
re.match(r"\d+", "abc123") | 매칭되지 않음 | ||
search | 문자열 전체를 검색하여 첫 번째 패턴 일치 부분을 찾음 | re.search(r"\d+", "123abc") | 매칭됨 |
re.search(r"\d+", "abc123") | 매칭됨 |
2. findall
* 패턴에 매칭되는 모든 문자열 가져오기
re.findall('패턴', '문자열')
import re
d = re.findall('[0-9]+', '1 2 Fizz 4 Buzz Fizz 7 8')
print(d)
>> ['1', '2', '4', '7', '8']
📌 정규표현식 패턴
| 패턴 | 설명 | 예제 | 매치 결과 |
|---|---|---|---|
. | .이 있는 위치에 임의의 한 문자 (줄바꿈 문자 제외) | a.b | acb, aab |
^ | 문자열의 시작 | ^a | abc |
$ | 문자열의 끝 | a$ | cba |
* | 앞의 문자가 0번 이상 반복됨 | a* | aaa, `` |
+ | 앞의 문자가 1번 이상 반복됨 | a+ | aaa |
? | 앞의 문자가 0번 또는 1번 나타남 | a? | a, `` |
{m,n} | 앞의 문자가 m번 이상, n번 이하 반복됨 | a{2,4} | aaa |
[ ] | 대괄호 안의 문자 중 하나와 매치 | [abc] | a, b, c |
[^ ] | 대괄호 안에 없는 문자와 매치 | [^abc] | d |
[a-z] | 문자 범위와 매치 | [a-z] | m |
\d | 숫자와 매치 (0-9) | \d | 1 |
\D | 숫자가 아닌 것과 매치 | \D | a |
\s | 공백 문자와 매치 (스페이스, 탭, 줄 바꿈 등) | \s | (스페이스) |
\S | 공백 문자가 아닌 것과 매치 | \S | a |
\w | 단어 문자와 매치 (알파벳, 숫자, 언더스코어) | \w | a, _, 1 |
\W | 단어 문자가 아닌 것과 매치 | \W | ! |
| 'ㅣ' | OR 연산자 (a or b 가 있는지) | a\|b | a, b |
( ) | 그룹화 | (abc)+ | abcabc |
\b | 단어 경계 | \bword\b | word |
\B | 단어 경계가 아님을 나타냄 | \Bsword\B | swordsmith |
📌 그룹
* 해당 그룹과 일치하는 문자열을 얻어올 때 사용
match.group(그룹숫자)
(?P<이름>정규표현식)
match.group('그룹이름')
import re
m = re.match('[0-9]+ (0-0]+)', '10 925'
print(m.group(1))
>> '10'
print(m.group(2))
>> '295'
m = re.match(r'(?P<func>[a-zA-Z_][a-zA-Z0-9_]*)\((?P<arg>\d+)\)', 'print(1234)')
print(m.group('func'))
>>print
print(m.group('arg'))
>> 1234📌 sub
* 문자열을 다른 문자열로 바꿀 때 사용
re.sub('패턴', '바꿀문자열', '문자열', 바꿀횟수)text = "Hello! @world! This is 2024. @#$%^&*"'
pattern = r'[a-zA-Z0-9/s]'
re.sub(pattern, ' ', text)
>> Hello world This is 2024* 람다 표현식으로도 쓸 수 있다
import re
result = re. sub('[0-9]+', lambda m: str(int(m.group()) *10), '1 2 Fizz 4 Buzz Fizz 7 8')
print(result)
>> '10 20 Fizz 40 Buzz Fizz 70 80'
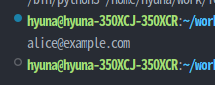
💡 정규표현식을 이용해 주어진 문자열에서 이메일 주소를 찾는 코드를 작성해보자
>> text = "alice@example.com 이 첫 번째 이메일이고, 다음은 bob.smith@mail.co.uk 입니다."
import re
text = "alice@example.com 이 첫 번째 이메일이고, 다음은 bob.smith@mail.co.uk 입니다."
pattern = r'^[a-zA-Z0-9._]+@[a-zA-Z0-9.-]+\.[a-zA-z]{2,}'
match = re.match(pattern, text)
if match:
print(match.group()) #pattern에 맞은 이메일 문자열 반환
else:
print("문자열 시작에 이메일이 없습니다")
💡 주어진 문자열이 특정 단어 'Hello'로 시작하는지 확인하는 코드를 작성해보자
>> text = "Hello, how are you today? Hello, I'm fine."
import re
text = "Hello, how are you today? Hello, I'm fine."
pattern = '^Hello'
match = re.match(pattern, text)
if match:
print('문자열이 "Hello"로 시작합니다')
else:
print('문자열이 "Hello"로 시작하지 않습니다')

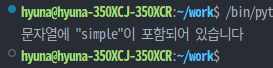
💡 주어진 문자열에서 특정 단어 'sample'가 있는지 확인하는 코드를 작성해보자
>> text = "This is a sample text with the word 'sample' in it."
import re
text = "This is a sample text with the word 'sample' in it."
pattern = r'sample'
result = re.findall(pattern, text)
if result:
print('문자열에 "simple"이 포함되어 있습니다')
else:
print('문자열에 "simple"이 포함되어 있지 않습니다')
💡 주어진 문자열에서 날짜 형식을 가진 문자열이 있는지 확인하는 코드를 작성해보자
>> text = "오늘의 날짜는 2023-06-28 이고, 내일은 2023-06-29 입니다."
import re
text = "오늘의 날짜는 2023-06-28 이고, 내일은 2023-06-29 입니다."
pattern = r'\d{4}-\d{2}-\d{2}'
match = re.findall(pattern, text)
if match:
print(match)
else:
print("날짜 형식을 가진 문자열이 없습니다")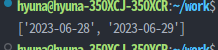
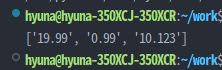
💡 주어진 문자열에 있는 소수점 두자리 이상을 가진 숫자를 찾는 코드를 작성해보자
>> text = "상품의 가격은 19.99 달러와 100.0 달러, 0.99, 10.123달러 입니다."
import re
text = "상품의 가격은 19.99 달러와 100.0 달러, 0.99, 10.123 달러 입니다."
pattern = r'\d+\.\d{2,}'
match = re.findall(pattern, text)
if match:
print(match)
else:
print("소수점을 포함한 숫자를 찾지 못했습니다")
💡 주어진 문자열(HTML)에서 모든 태그를 찾는 코드와 제거하는 코드를 작성해보자
>> text = "<html><head><title>Test</title></head><body><h1>Header</h1><p>Paragraph</p></
body></html>"
import re
text = "<html><head><title>Test</title></head><body><h1>Header</h1><p>Paragraph</p></body></html>"
pattern = r'<[^>]+>'
match = re.findall(pattern, text)
# 태그 찾기
if match:
print(match)
else:
print("태그를 발견하지 못했습니다")
#태그 제거하기
def remove_tag(text):
pattern = r'<[^>]+>'
match = re.sub(pattern, ' ', text)
return match
print(remove_tag(text))

