🙋♂️학습 정리
📚 Docker(도커)란?
- 컨테이너 기반의 오픈소스 가상화 플랫폼
🔖 도커가 등장하게 된 배경
- 어떤 앱/서비스를 배포하기 위해서는 먼저 개발자용 컴퓨터에서 서비스를 개발하고 테스트를 거쳐 아무런 이상이 없으면 서버용 컴퓨터를 통해 해당 서비스를 배포한다
- 그렇기 때문에 개발자용 컴퓨터와 서버용 컴퓨터의 개발 환경이 똑같아야 한다
- 하지만 서비스를 1개만 개발/배포하는 것이 아니라 여러 서비스를 개발/배포해야 하고, 만약 각각의 서비스가 필요한 개발 환경이 다르면?
- 예를 들어, 서비스 A에는 node.js 버전 9가 필요하지만 서비스 B에는 node.js 버전 10이 필요함. 이를 같은 컴퓨터/개발 환경에서 다루면 서로 충돌 및 에러가 발생할 수 있으며, 복잡한 설정을 세팅해야 한다
- 이를 위해 각각의 개발 환경이 독립된 공간에 따로 작동할 수 있는 컨테이너 기술이 나오게 된다.
- 컨테이너 기술을 통해 똑같은 개발 환경을 저비용으로 다른 컴퓨터에서 손쉽게 세팅할 수 있다
🔖 컨테이너란?
- 컨테이너는 격리된 공간에서 프로세스가 동작하는 기술
- OS 위에 독립된 작업 공간을 일컫는다. 컨테이너에는 OS가 설치되어 있는게 아니라 앱(작업)을 실행하는데 필요한 라이브러리나 실행 파일만 존재(Lib/Bins)
- 서비스를 실행하는데 필요한 앱들을 하나의 컨테이너에 같이 넣고 작업을 실행하거나 각각의 컨테이너를 연결하여 서비스를 실행할 수도 있다.
- 컨테이너 플랫폼은 리눅스에서 사용되는 기술이며, 실제로 도커를 실행하면 도커에서 리눅스 OS(리눅스 가상환경)를 알아서 설치해서 사용하게 된다
🔖 가상 OS VS Docker
- 가상 OS(virtual box 등)는 컴퓨터 OS를 분할하고 그 위에 가상 OS를 생성하기 때문에 컴퓨터 자원도 나눠서 사용한다. 따라서, 자원을 활용하는데 한계(분할된 컴퓨터 자원이 최대 자원)가 있으며, OS위에 다시 OS를 설치했기 때문에 실행속도가 상대적으로 느리다
- Docker는 컴퓨터 OS 위에 독립된 작업 공간을 분할한다. 그래서 컴퓨터 자원을 공유하기 때문에(상황에 따라 컴퓨터 자원을 모두 활용 가능) 효율적으로 자원을 활용할 수 있고 실행 속도도 빠르다.
🔖 이미지란?
- 이미지는 컨테이너 실행에 필요한 파일과 설정값등을 포함하고 있는 것으로 상태값을 가지지 않고 변하지 않습니다(Immutable). 컨테이너는 이미지를 실행한 상태라고 볼 수 있고 추가되거나 변하는 값은 컨테이너에 저장됩니다.
- 쉽게 말해 이미지는 컨테이너를 만들어내는 툴 또는 무한 생상 가능한 컨테이너 조립 키트.
- 로컬 저장소에서 검색어에 해당하는 이미지가 없으면 docker hub으로부터 해당 이름으로 등록된 이미지를 찾아 다운로드함
- docker hub에서 이미지를 다운받는 작업을
pull이라 함 - 다운받은 이미지를 실행하는 작업을
run이라 함- run을 하면 이미지가 컨테이너가 되면서 컨테이너에 안에 있는 프로세스들이 작동됨
- docker hub에서 이미지를 다운받는 작업을
📚 Docker(도커) 설치 과정
- 도커다운로드 에 접속하여 운영체제에 맞는 도커를 다운로드 및 설치한다
- (윈도우전용) 앞서 설명했다시피, 도커는 리눅스 OS에서 작동되는 플랫폼이기 때문에 WSL2를 필수적으로 설치해야 한다
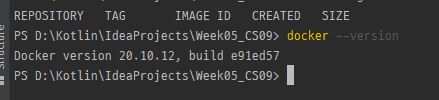
- powershell 또는 터미널에 docker --version을 하고 정상적으로 출력된다면 설치 완료!
- 도커허브 에 접속 ->
explore->container항목에서 원하는 이미지를 검색할 수 있음
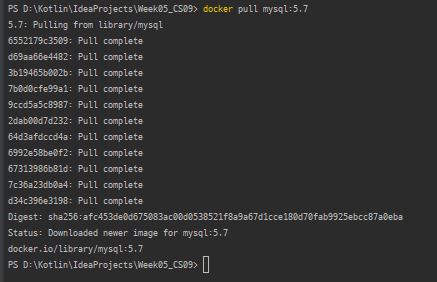
- 있다면 명령어를 통해
docker pull mysqlpull 가능 (여기서는 미션에 나와있는 요구대로 5.7버전을 설치docker pull mysql:5.7)
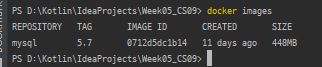
- 이미지가 정상적으로 pull했는지 확인하기 위해서는 명령어
docker images를 입력
📚 도커 명령어로 mySQL 실행하기

1. docker run -p 3306:3306 -e MYSQL_ROOT_PASSWORD=linus --name mysql_linus mysql:5.7 명령어로 mySQL 컨테이너 생성하기
1. run : 이미지를 실행하여 컨테이너를 생성
2. -p 3306:3306 : 호스트의 3306포트와 컨테이너의 3306포트를 연결한다. 즉 호스트에 3306포트 접근이 발행하면 해당 컨테이너에 접속이 된다.
3. -e MYSQL_ROOT_PASSWORD=linus : 컨테이너를 생성하면서 환경변수를 지정한다. root계정의 비밀번호를 설정한다.
4. -name mysql_test : 컨테이너의 이름은 mysql_linus로 지정한다.
5. mysql:5.7 : mysql 버전은 5.7 버전으로 컨테이너 생성
2. docker ps 명령어를 통해 실행되고 있는 컨테이너 확인

3. docker exec -it mysql_linus bash 명령어로 mysql 컨테이너의 bash에 접속

4. 우분투 패키지 업데이트 및 한글 설정
1. apt update
2. apt upgrade
3. apt-get install -y locales locales-all (미션에서는 apt install language-pack-ko 였지만 에러가 발생해서 전체 언어팩을 설치)
4. locale-gen ko_KR.UTF-8
5. update-locale LANG=ko_KR.UTF-8 LC_MESSAGES=POSIX
1. 또는 직접로케일설정
6. sudo 명령어가 먹히지 않으면 apt-get -y install sudo 입력
5. mysql -u root -p 명령어로 mysql 서버에 접속
1. mySQL접속하기
6. utf-8 설정을 아래의 사이트를 참고했다
1. nano를 통해 직접설정
7. restart하는 명령어는 sudo service mysql restart 이다. $ sudo systemctl restart mysql 은 리눅스 버전 차이로 안된다
📚 HeidiSQL를 통해 사용자 추가하기
- 먼저 root 계정으로 접속
- 도구 -> 사용자 관리자로 이동
- 사용자 계정 추가
- 이름 및 암호 입력
- 권한 설정
HeidiSQL 사용자추가
👉 SQL 문법
- 데이터 삽입하기
INSERT INTO table_name VALUES (data1,data2,data3)
- 문자열 합치기
CONCAT(A,B)결과는 AB
- 랜덤 내장 함수
rand()0~1 사이의 랜덤 수를 반환
- 랜덤 문자열, 숫자
CHAR(RAND() * 24 + 97)랜덤 문자열 생성CAST(RAND() * 9 as decimal)랜덤 숫자를 만들고 10진수로 변환
- 지역 변수 선언하기
DECLARE name TYPE이후에SET 변수이름 = 할당- 만약 다른 테이블값을 변수에 담고 싶다면?
- `SET 변수 = (SELECT * FROM table_name where 조건)
FLOOR()내림함수- 지정한 날짜 사이의 랜덤 날짜 만들기
- '2009-10-01 00:00:00' 부터 '2010-02-28 00:00:00' 까지 랜덤하게 뽑아오는 방법..
- FROM_UNIXTIME(FLOOR(unix_timestamp('2009-10-01 00:00:00')+(RAND()*(unix_timestamp('2010-02-28 00:00:00')-unix_timestamp('2009-10-01 00:00:00')))))
- 참고
- 날짜 함수
NOW()현재 시간SUBDATE(NOW(),INTERVAL 30 DAY)지정한 날짜로부터 30일을 뺀 날짜
- mySQL에서 데이터 베이스 조회하기
show databases;현재 있는 데이터 베이스 목록 출력user database_name특정 데이터 베이스 사용show tables;특정 테이블 보기select * from table_name데이터 조회
- 프로시저 내용
BEGIN
DECLARE i DECIMAL;
DECLARE word CHAR(50);
SET i = 1;
WHILE i <=1000000 DO
SET word = (SELECT * FROM data ORDER BY RAND() LIMIT 1);
INSERT INTO user_log(nickname,money,last_visit) VALUES (CONCAT(word, CHAR(RAND() * 24 + 97), CHAR(RAND() * 24 + 97), CHAR(RAND() * 24 + 97), CAST(RAND() * 9 as decimal) , CAST(RAND() * 9 as decimal) , CAST(RAND() * 9 as decimal), CAST(RAND() * 9 as DECIMAL)),
FLOOR((RAND() * 100000)),
FROM_UNIXTIME(FLOOR(unix_timestamp(SUBDATE(NOW(),INTERVAL 30 DAY))+(RAND()*(unix_timestamp(NOW())-unix_timestamp(SUBDATE(NOW(),INTERVAL 30 DAY)))))));
SET i = i+1;
END WHILE;
END-
결과
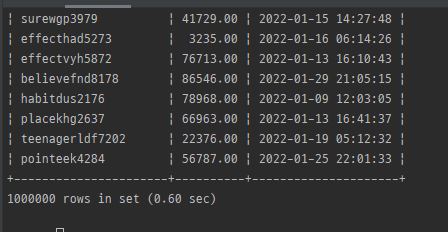
-
많은 데이터를 넣을 때는 bulk insert를 기억하자!
👉 mySQL Connector 이용해서 docker mySQL 접속하기 - JDBC 이용
📚 JDBC 다운로드 및 인텔리제이(코틀린)과 연동하기
- mySQL 공식사이트 에서 Connector/J ZIP 파일 다운하기(저는 여기서 Platform Independant로 함)
- ZIP을 풀고 jar을 특정 폴더에 넣기
- 인텔리제이를 실행하고 file -> Project Structure -> Libraries 에 방금 다운받은 connector jar 파일 추가하기(main 모듈에다가 적용해야 함)
- 뭔지 모르겠지만 인텔리제이가 알아서 라이브러리 dependencies에 추가해줘서 Class.ForName() 없이도 사용 가능
🔖 Connection 클래스
곧 업데이트
🔖 Statement 클래스
곧 업데이트
🔖 ResultSet 클래스
곧 업데이트
