Sequential search
ex) 오름차순 정렬 후, search 5 => list[3]까지만 확인하면 됨
list[0]=1
list[1]=3
list[2]=4
list[3]=6
list[4]=9
list[5]=11
list[6]=15
list[7]=17
for문을 통해 내가 찾고자 하는 값이 있다면 그 index 출력
Iterative binary search
Searching an ordered list
int binsearch(int list[], int searchnum, int left, int right) { // list[] : 배열, searchnum : 찾으려는 값 // left, right : list[] 배열의 시작 원소와 끝 원소 int middle; while (left <= right) { // left > right => search할 값이 배열에 없음을 의미 middle = (left + right) / 2; switch (COMPARE(list[middle], searchnum)) { case -1: left = middle + 1; // list[middle] < searchnum break; case 0: return middle; // list[middle] == searchnum case 1: right = middle - 1; // list[middle] > searchnum } } , , return -1; }Binary search는 sequential search보다 빠르게 search 가능. (단, 정렬되어 있어야 함.)
- 찾는 값이 배열에 없는 경우
ex) search 7
list[0]=1
list[1]=3
list[2]=4
list[3]=6
list[4]=9
list[5]=11
list[6]=15
list[7]=17
............................
(left, middle, right)
(0, 3, 7)
(4, 5, 7)
(4, 4, 4)
(4, x, 3) => left, right 위치 바뀜 => while문 빠져나옴 => return -1
Time complexity
T(P) = c + Tp(n)
T(p) : 프로그램 P 실행 시간
c : 컴파일 시간 (고정적)
Tp : 런타임
n : instance characteristics (가변적) => 프로그램 실행 시간에 영향을 주는 요소
Program Steps
- Program Step : 프로그램에서 syntactically(구조적으로), semantically(의미적으로) 의미있는 부분
Matrix addition
void add(int a[][MAX_SIZE], int b[][MAX_SIZE], int c[][MAX_SIZE], int rows, int cols) { // rows, cols : instance characteristics int i, j; // 명령어 아님(step에 포함 x) for (i = 0; i < rows; i++) // step => rows+1번 for (j = 0; j < cols; j++) // step => rows(cols+1)번 c[i][j] = a[i][j] + b[i][j]; // step => rows*cols번 }Number of steps? => (rows+1) + (rows(cols+1)) + (rows*cols)
float sum(float list[], int n) // n : instance characteristics { float tempsum = 0; // step => 1번 int i; for (i = 0; i < n; i++) // step => n+1번 tempsum += list[i]; // step => n번 return tempsum; // step => 1번 }total steps : 1 + n+1 + n = 2n+3
float rsum(float list[], int n) { if (n) // step => n+1번 return rsum(list, n-1) + list[n-1]; // step => n번 return 0; // step => 1번 }total steps: n+1 + n + 1 = 2n + 2
Asymptotic notation (Big-O, Omega, Theta)
-
알고리즘의 정확한 step 개수를 세는 것은 어려움.
-
step의 기준이 명확하지 않음 - 비교 목적으로 사용하기엔 유용하지 않음.
80n, 85n, 75n => 75n이 가장 효율적인 알고리즘이라고 확신할 수 없음.
예외: 10000n+10 vs. 3n+3 => 3n+3이 더 효율적인 알고리즘. -
예를 들어, c1, c2, c3라는 음수가 아닌 상수가 있다.
n이 충분히 큰 값일 때, c1n^2 + c2n > c3n 라고 할 수 있는가? => Yes!
ex)
n^2 + 2n > 100n (n is sufficiently large)
n^2 + 2n - 100n > 0
n^2 - 98n > 0
n(n-98) > 0
.......................................................................................
n이 98이상이라면 위 식을 항상 만족함
break even point(손익분기점) : n = 98
Definition [Big "oh"]
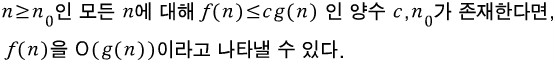
- g(n)은 f(n)의 upper bound
- g(n)은 가능한 가장 작은 값이 되어야 함.
- g(n)에 상수 c만 곱해주면 f(n)보다 항상 크거나 같음.
- upper bound로 여러 값이 주어진다면 그 중 가장 작은 값을 택해야 의미가 있음.
ex) 2n^2 + n = O(n^2), O(n^3), O(n^4)...
이 중 smallest value인 O(n^2)이 의미 있는 표기법임.
예제 1) 35n + 7을 O(n)이라고 할 수 있을까?
Big-O notation : f(n) = O(g(n))
f(n) = 35n + 7
n = g(n)
35n + 7 <= c*n
c = 36이라고 하면,
-> 35n + 7 <= 36n
-> n - 7 >= 0
-> n >= 7
=> n이 7이상이라면 위의 식은 항상 성립함. 이때, 7이 n0임.
예제 2) 3n + 3을 O(n)이라고 할 수 있을까?
f(n) = 3n + 3
n = g(n)
3n + 3 <= c*n
n = 4라고 하면,
-> 3n + 3 <= 4n
-> n - 3 >= 0
-> n >= 3
=> n이 3이상이라면 위의 식은 항상 성립함. 이때, 3이 n0임.
- 3n^2 + 3은 O(n)이라고 할 수 없음.
- 3n + 3은 O(n^2)이라고 할 수 있음.
- O(1) < O(log n) < O(n) < O(nlogn) < O(n^2) < O(n^3) < O(2^n)
