-
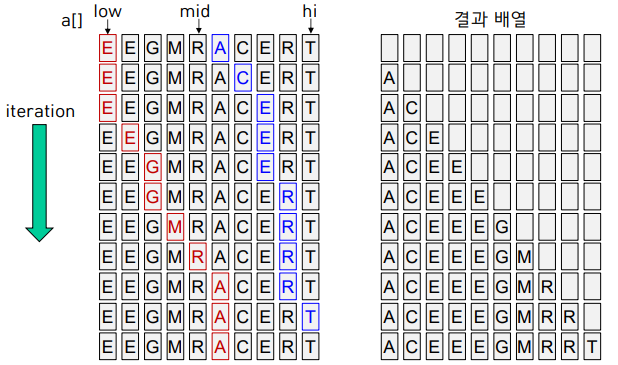
Merge Sort : 두 정렬된 배열에 총 N개의 원소가 저장되어 있을 때, ~N 시간에 하나의 배열에 정렬된 상태로 병합해 담을 수 있다는 사실에 기반한 방법
-두 배열이 a[low~mid]와 a[mid+1~hi]에 담겨 있으며, 각각 오름차순으로 정렬되어 있다고 가정
-두 배열의 시작 지점에 포인터를 하나씩 둠. (i=low, j=mid+1)
-a[i]와 a[j] 중 더 작은 쪽을 결과 배열에 담고, 담은 쪽의 포인터를 1 증가시키기를 반복
-한 배열을 결과 배열에 모두 옮겨 담았다면(i>mid or j>hi), 다른 배열에 남은 값을 차례로 결과 배열에 옮겨 담음.
-
Merge 위해서는 ~N만큼의 추가 space 필요
-정렬한 결과를 추가 space에 담거나,
-정렬한 결과를 a[ ]에 담고 싶다면, 정렬 전에 입력 데이터 a[ ]를 추가 space에 옮겨 담은 후 정렬한 결과를 a[ ]에 저장 -
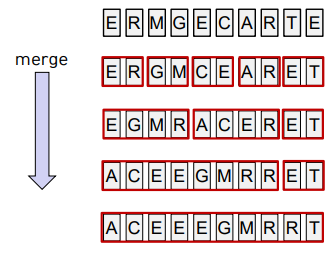
두 배열의 크기가 각각 1이라면, 미리 정렬할 필요 없이 merge만으로 정렬 가능 ex) [E],[A] --merge--> [A, E]
-크기 1인 N개의 조각으로 분리 -> 인접한 두 조각끼리 merge 반복
-
Merge 코드
#Merge a[lo~mid] with a[mid+1~hi] using the extra space aux[]
def merge(a, aux, lo, mid, hi):
for k in range(lo, hi+1):
aux[k] = a[k]
i, j = lo, mid+1
for k in range(lo, hi+1):
if i > mid: #첫 번째 조각의 값을 모두 a[]에 옮겨 담았다면,
a[k], j = aux[j], j+1
elif j > hi: #두 번째 조각의 값을 모두 a[]에 옮겨 담았다면,
a[k], i = aux[i], i+1
# aux[i]와 aux[j] 중 더 작은 값을 a[]에 옮겨 담고, 담은 쪽의 포인터 1 증가
elif aux[i] <= aux[j]:
a[k], i = aux[i], i+1
else:
a[k], j = aux[j], j+1- Merge Sort 코드
입력 데이터를 작은 조각들로 나눈 후 두 조각끼리 merge해 가는 코드
# Halve a[lo~hi], sort each of the halves, and merge them
# using the extra space aux[]
def divideNMerge(a, aux, lo, hi):
if (hi <= lo): #조각의 길이가 1이 되면 더 쪼갤 수 없으므로 바로 리턴
return a
mid = (lo + hi) // 2 #a[lo~hi]를 두 조각으로 나눔
divideNMerge(a, aux, lo, mid)
divideNMerge(a, aux, mid+1, hi)
merge(a, aux, lo, mid, hi)
def mergeSort(a):
aux = [None] * len(a)
divideNMerge(a, aux, 0, len(a)-1)-
Merge Sort의 성능 : ~Nlog2(N)
-N개 값 merge를 위해 N에 비례한 횟수의 비교/메모리 접근 수행
-N개 원소를 크기 1이 될 때까지 두 조각으로 나눈 후, 두 조각끼리 merge해가므로 ~Nlog2(N)에 비례한 횟수의 비교/메모리 접근 수행
(2->4->...-> N/4->N/2->N) : ~ log2(N) -
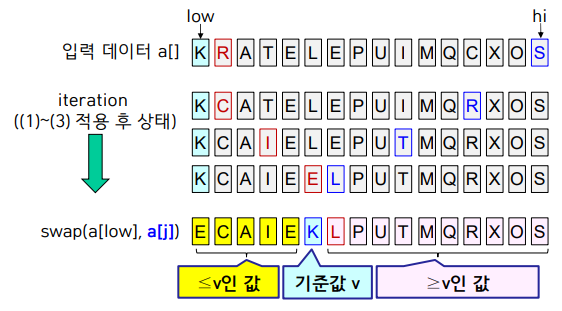
Quick Sort : 정렬할 원소 중 하나를 기준값 v로 정한 후, <=v인 원소를 v 왼쪽에, >=v인 원소를 v 오른쪽에 두는 분할(partition)을 반복 적용하는 방법
-배열 a[low~hi]에 담긴 값을 오름차순으로 정렬해야 한다고 가정
-첫 원소 a[low]를 기준값 v로 정함.
-기준값을 제외한 배열의 양 끝에 포인터를 하나씩 둠. (i=low+1, j=hi)
-j<=i가 될 때까지 (1)~(3) 과정 반복
(1) v보다 큰 a[i]가 나올 때까지 i를 1씩 증가시킴
(2) v보다 작은 a[j]가 나올 때까지 j를 1씩 감소시킴
(3) a[i]와 a[j]를 swap
-최종적으로 j<=i가 되면, v를 두 partition 경계에 있는 값과 swap
-
Partition 후 기준값 v 좌우의 조각에 다시 partition 적용
-Partition 했을 때 기준값은 정렬된 위치에 있게 되며, N=2개의 원소를 partition하면 정렬이 완료되므로, 좌우 조각을 계속 partition하다 보면 모든 원소가 정렬됨.

-
N개 원소에 partition을 수행해 기준값 v를 중심으로 두 조각으로 분할하면, 기준값 v는 정렬된 위치에 오게 되며, 나머지 원소는 자신이 속한 조각 내에서 다시 정렬해야 함.
-
정렬할 배열의 크기가 2라면 이를 partition만으로 정렬 가능함. 둘 중 한 원소를 기준으로 다른 원소의 위치를 정렬 순서에 맞게 이동시키기 때문. ex) [E,A]에 partition 적용하면 [A,E]로 정렬된 상태가 됨.
-
Partition 코드
# Partition a[lo~hi] using a[lo] as the partitioning item
def partition(a, lo, hi):
i, j = lo+1, hi #기준값 a[lo]를 제외한 배열 양 끝에 포인터 i, j를 둠
while True:
while i <= hi and a[i] < a[lo]: #기준값보다 큰 a[i]가 나올 때까지 i를 1씩 증가
i = i+1
while j >= lo+1 and a[j] > a[lo]: #기준값보다 작은 a[j]가 나올 때까지 j를 1씩 감소
j = j-1
if (j <= i): #포인터가 교차하면,
break
a[i], a[j] = a[j], a[i] #swap을 통해 기준값 보다 작은 원소는 왼쪽, 기준값 보다 큰 원소는 오른쪽에 오도록 함
i, j = i+1, j-1
a[lo], a[j] = a[j], a[lo] #분할 끝났으므로, 기준값을 두 partition 경계에 있는 값과 swap
return j #기준값의 index 반환하여 두 partition의 경계가 어딘지 알 수 있도록 함- Quick Sort 코드
partition한 조각을 크기가 1이 될 때까지 다시 작은 조각들로 partition하는 코드
# Partition a[lo~hi] and continue to partition each half recursively
def divideNPartition(a, lo, hi):
if (hi <= lo):
return
j = partition(a, lo, hi)
divideNPartition(a, lo, j-1)
divideNPartition(a, j+1, hi)
def quickSort(a):
# Randomly shuffle a, so that the partitioning item is chosen randomly
random.shuffle(a)
divideNPartition(a, 0, len(a)-1)-
Quick Sort의 성능 (best case) : ~Nlog2(N)
-N개 값 partition 위해 N에 비례한 횟수의 비교/메모리 접근 수행
-N개 원소를 크기 1이 될 때까지 정확히 반으로 나눠간다면,
N->N/2->N/4->...->2->1 : ~log2(N)
-비교/메모리 접근 : ~Nlog2(N) -
Quick Sort의 성능 (worst case) : ~N^2/2
-크기 N인 조각을 partition 했을 때 크기 N-1인 조각 나오는 경우
-N+(N-1)+...+1 = ~N^2/2 회 작업 수행
ex) 기준값 보다 큰 원소만 존재하거나, 기준값보다 작은 원소만 존재하는 경우
이러한 worst case가 발생할 가능성을 줄이기 위해 입력 데이터를 random shuffle함.
Q. merge() 함수의 코드를 보면 6개의 index를 볼 수 있다. (lo, mid, hi, i, j, k) 이들에 대한 설명으로 잘못된 것은?
1. lo는 첫 번째 조각이 시작하는 위치를, hi는 두 번째 조각이 끝나는 위치를 가리킨다. (O)
2. mid는 두 번째 조각이 시작하는 위치를 가리킨다. (X)
-> mid는 첫 번째 조각이 끝나느 위치, mid+1은 두 번째 조각이 시작하는 위치임.
3. i, j는 두 조각에서 이동시킬 값의 위치를 가리킨다. (O)
4. k는 정렬한 결과를 저장할 위치를 가리킨다. (O)
Q. Merge Sort를 Insertion/Selection/Shell Sort와 비교해 보자. 추가로 필요한 공간에 대한 설명으로 올바른 것은?
1. Insertion/Selection?Shell Sort도 Merge Sort와 마찬가지로 입력 데이터를 그대로 보존하면서 정렬한 결과를 다른 곳에 저장해야 하기에 ~N의 추가 공간이 필요하다.
2. Insertion/Selection/Shell Sort는 Merge Sort와 달리 swap을 사용하므로 ~N의 추가 공간이 필요하지 않다.
A. 2번. Insertion/Selection/Shell Sort는 별도의 추가 공간이 필요하지 않는 'in-place' 알고리즘이다.
Q. 다음 중 Quick Sort를 사용했을 때 worst case를 보이는 경우는?
1. 입력이 거의 정렬된 상태로 들어오며, random shuffling을 하지 않고 첫 번째 원소를 기준값으로 선택
2. 입력이 거의 같은 값으로 들어오며, random shuffling을 하고 첫 번째 원소를 기준값으로 선택
A. 1번
