
1. RAG(Retrieval Augmented Generation)
기존의 LLM 한계?
-
기존의 LLM은 자신의 학습 데이터에 없는 최신 정보, 특정 도메인 지식에 대해서는 답변하기 어렵다는 한계가 존재함
-
아래 예시에서 보는 것처럼 최신 정보의 부재로 인해 LLM의 환각 현상으로 부정확한 답변을 내놓는 것을 볼 수 있음
-
예시
-
10월 23일 기준 삼성전자 주가에 대해 ChatGPT에 물어본 결과
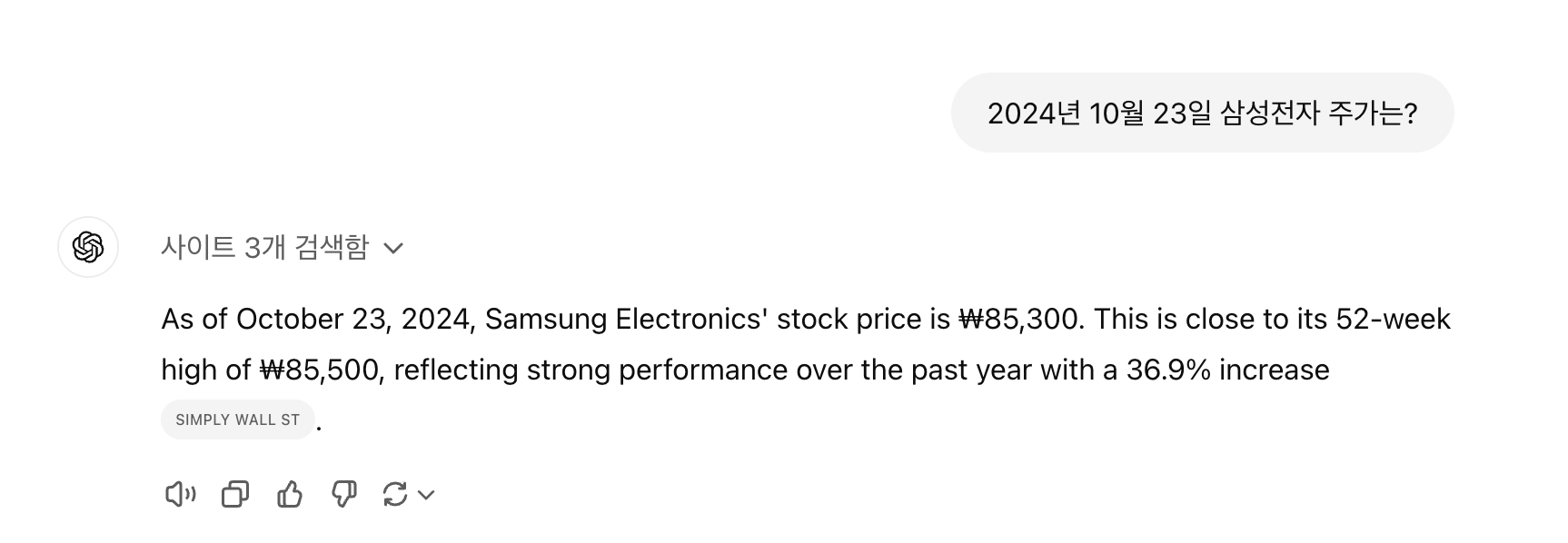
-
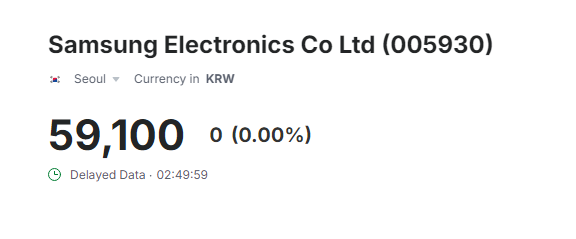
실제 가격(종가 기준)
-
RAG의 정의
- 대규모 언어 모델(LLM)의 한계를 극복하기 위해 제안된 새로운 자연어 처리 기술
- LLM의 단점 중 1) 사실 관계 오류 가능성’과 2)맥락 이해의 한계 를 개선하는 데 초점을 맞춘 방법
- RAG는 LLM에 외부 지식 베이스를 연결하여 모델의 생성 능력과 사실 관계 파악 능력을 향상시키는 기술
RAG의 과정
RAG의 주요 구성 요소
- 질의 인코더(Query Encoder): 사용자의 질문을 이해하기 위한 언어 모델이며 주어진 질문을 벡터 형태로 인코딩
- 지식 검색기(Knowledge Retriever): 인코딩된 질문을 바탕으로 외부 지식 베이스에서 관련 정보를 검색예를 들어 Wikipedia, 뉴스 기사, 전문 서적 등 방대한 문서 집합에서 질문과 연관된 문단이나 구절을 찾아냄
- 지식 증강 생성기(Knowledge-Augmented Generator): 검색된 지식을 활용하여 질문에 대한 답변을 생성하는 언어 모델. 기존의 LLM과 유사하지만, 검색된 지식을 추가 입력으로 받아 보다 정확하고 풍부한 답변을 생성 가능
RAG의 동작 과정 요약
- 사용자의 질문이 주어지면 질의 인코더가 이를 이해하기 쉬운 형태로 변환
- 지식 검색기가 인코딩된 질문을 바탕으로 외부 지식 베이스에서 관련 정보를 검색
- 검색된 지식은 지식 증강 생성기의 입력으로 전달
- 지식 증강 생성기는 검색된 지식을 활용하여 사용자 질문에 대한 답변을 생성
- 프로젝트 기간에 진행한 경제 뉴스 챗봇
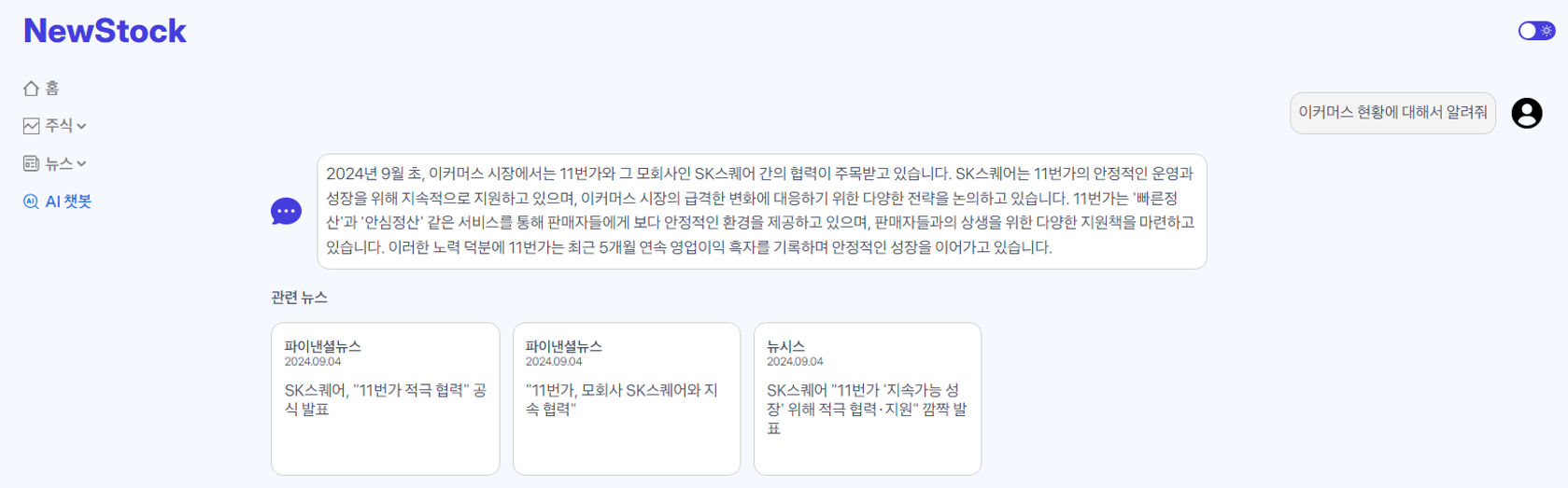
-
해당 프로젝트 챗봇의 동작 과정
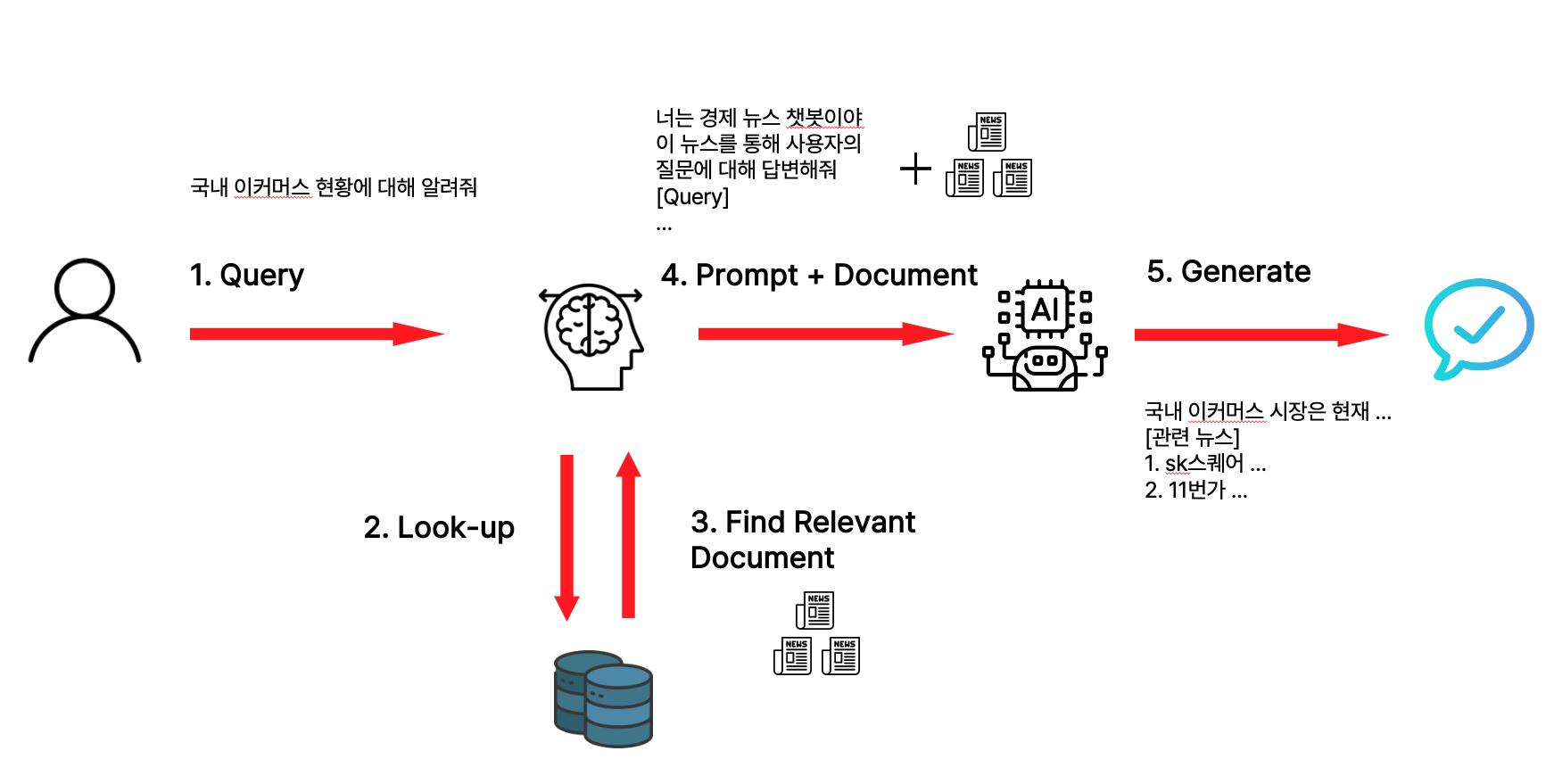
- 본 프로젝트에서는 외부 지식 베이스로 ElasticSearch를 Vector Database로 활용함
- OpenAI GPT-4를 지식 증강 생성기로 사용함
2. RAG 성능 향상 기법
데이터의 품질과 더불어 Retriever은 RAG 시스템의 핵심
- 기본적으로 RAG 시스템을 구축하는 것은 쉽지만, 실제 Product 단계의 챗봇을 출시하기 위해서는 고도화가 필요
- 특히 Retriever의 경우 사용자 질문의 의도를 파악하여 좋은 품질의 답변을 내놓는 것이 중요
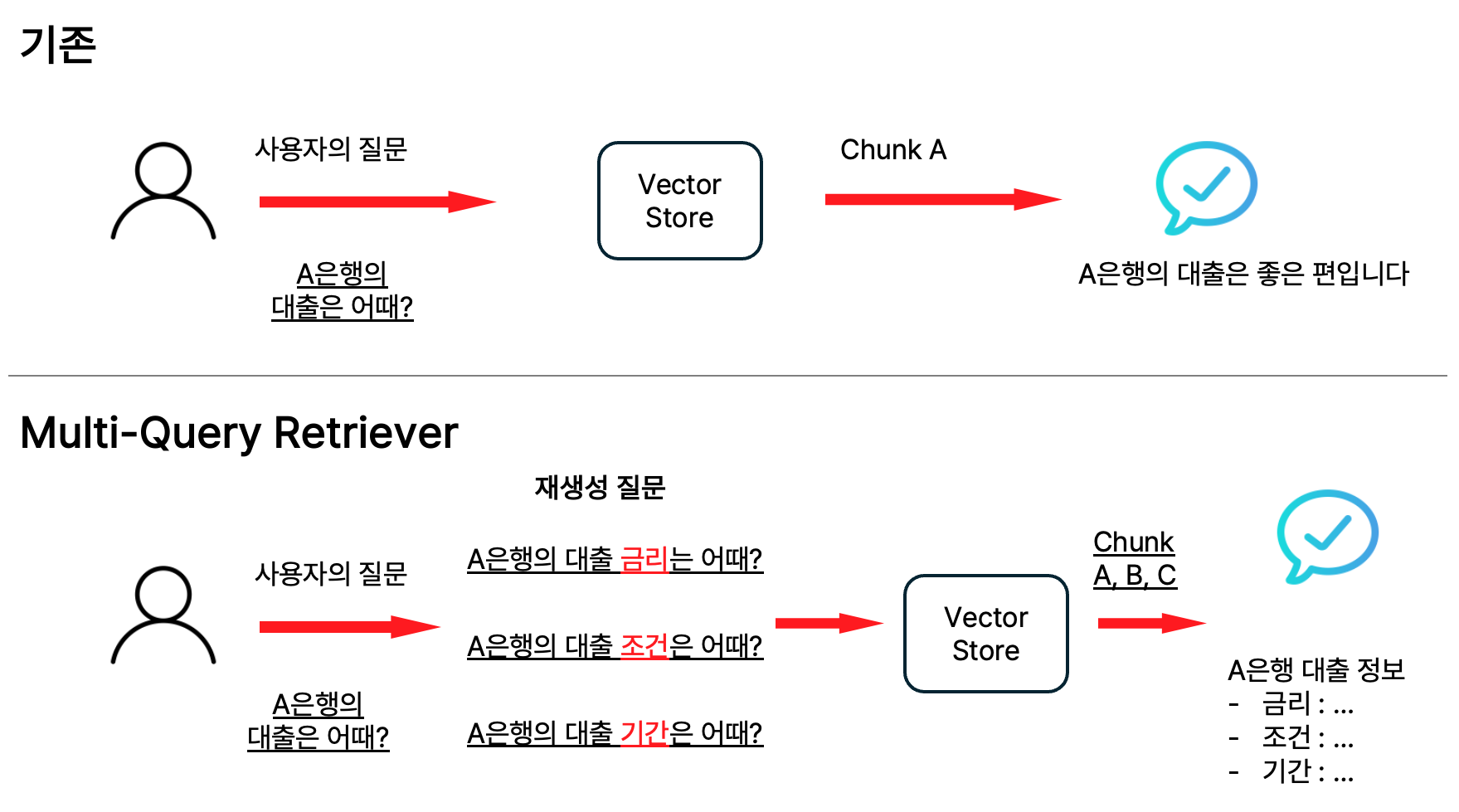
1. Multi-Query Retriever
대충 질문해도 좋은 답변을 원한다면
- 사용자의 질문을 여러개의 유사 질문으로 재생성하여 다양한 검색 결과를 얻는 방법
- 질문을 재생성할 때, 모델을 사용하거나 자연어처리 기법을 활용하여 쿼리 확장
- 단일 쿼리로는 놓칠 수 있는 문서나 정보를 보다 풍부하게 검색할 수 있는 등 검색 성능 향상
과정
-
쿼리 확장: 원본 쿼리를 다르게 표현하는 여러 변형된 쿼리를 생성. 이를 위해 시놉시스, 패러프레이징(paraphrasing), 또는 질의 변환(semantic transformation) 기술을 사용 가능
-
병렬 검색: 생성된 여러 쿼리를 각각 실행하여 검색 엔진에서 문서를 가져옴
-
결과 통합: 다수의 쿼리에서 얻은 결과를 통합하거나 reranking 기법을 통해 최종적으로 가장 관련성이 높은 문서를 선택
2. Parent-Document Retriever
앞뒤 문맥을 잘 담아야 한다면
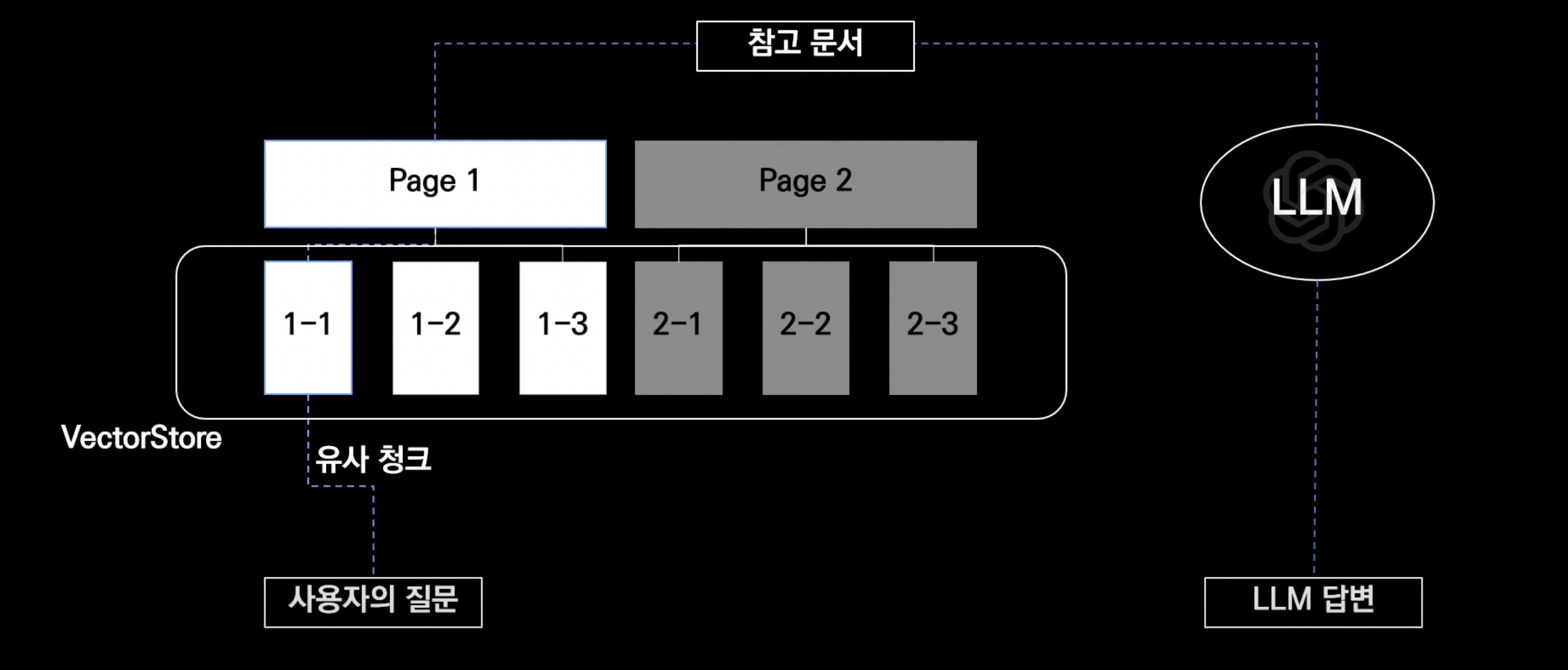
- 기존 RAG는 단일 문서에 대해 유사도가 높다고 판별했다면 해당 문서에 대해서만 참고하도록 하였음
- 유사 문서의 상위 문서(Parent Document)를 참고하므로 조금 더 맥락(context)을 담아 LLM에게 제공 가능
- 예를 들어 아래 사진에서 사용자의 쿼리가 1-1의 문서와 가장 유사하다고 판별
- 하지만 알고 보니 핵심적인 내용은 1-2에 들어있다면 => 충분한 답변 제공 불가
- 따라서 해당 문서의 부모 문서를 참고함으로써 맥락이나 배경 정보를 얻을 수 있음
- 이 과정을 통해 더욱 정확한 검색 결과, 문서의 맥락 제공, 답변의 일관성, 정보의 포괄성을 제공할 수 있다는 장점이 있다.
과정
-
문서의 계층 구조 인식: 문서들이 상위 문서와 하위 문서의 관계로 구성되어 있는 구조를 파악. 이 관계는 주로 데이터셋이나 문서의 메타데이터에 기반하여 정의
-
하위 문서에서 상위 문서로 확장된 검색: 사용자가 입력한 쿼리와 관련된 하위 문서가 검색되면, 이 하위 문서의 상위 문서(Parent Document)도 함께 검색. 이렇게 하면 보다 포괄적인 맥락을 확보 가능
-
상위 문서에서 유사성 평가: 상위 문서의 정보가 하위 문서와 얼마나 관련성이 있는지를 평가한 후, 적합한 정보로 판단되는 부분을 추출해 최종적으로 검색된 결과에 통합
-
다양한 계층에서 정보 수집: Parent-Document Retriever는 하위 문서에서 직접적으로 검색된 정보뿐만 아니라, 상위 문서에서 더 풍부한 맥락을 제공받아 답변을 생성할 수 있음
3. Self-Query Retriever
Semantic 검색(의미 검색) 말고 쿼리가 필요하다면
- 시멘틱 검색의 단점 : 사용자가 질문의 답변을 조금만 달라지게 해도 retrieve되는 문서가 달라질 수 있어 답변 품질이 차이가 날 수 있다.
- ex) "삼성전자 요즘 호재인 뉴스가 있어?" "요즘 삼성전자 주가에 긍정적인 뉴스가 있어?"
- 또한 사용자의 쿼리에 대해 필터링 작업을 해야 할 때가 있다.
- ex) "평점이 9점 이상인 영화 추천해줘"(rating >= 9)
"종로구에 있는 피자집 추천해줘" (district == "종로구" && "type" == "피자")
- ex) "평점이 9점 이상인 영화 추천해줘"(rating >= 9)
- Self-Query retriever는 이러한 단점을 보완하기 위해 자체적으로 질문을 하는 능력을 갖추었다. 이때 구조화된 쿼리를 작성하기 위해 쿼리를 작성하는 LLM체인을 사용하고 Vector Store을 검색할 때 사용한다.
- 저장된 문서를 검색할 때 유사도 검색 뿐만 아니라 metadata에 대한 필터를 구축한다.
- python 기반 self-query retriever을 사용하려면
lark패키지를 사용해야 함

4. Time-weighed vector Retriever
오래된 자료를 덜 참고했으면
- 최근에 추가, 사용된 데이터일수록 더 중요한 데이터인 분야가 있다.
- 이때 가장 최근에 이용된 문서를 기준으로 먼저 참고하도록 하여 답변의 신선성(Freshness)를 유지 가능
- ex)
- 사용자의 질문 : 평점이 9점 이상인 영화 중 SF영화를 추천해줄래?
- 사용자의 속마음 : "최신 영화 중" + 평점 9점 이상 + SF영화
=> Document 중에서 최근 이용된 영화 위주로 추천해주는 방식
=> 시간이 지난 만큼 패널티를 주는 방식을 활용
Reference
