
Relational Data Model
Relational Data Model (관계형 데이터 모델) 은 1970년 E. F. Codd 가 제안한 논리적 데이터 모델로,
관계 데이터베이스 시스템에 직점 구현될 수 있도록 데이터베이스 구조를 정의하는 방법을 제공한다.
Relational Data Model 은 Relational Algebra (관계 대수) 의 지원을 받아 탄탄한 수학적 기초를 가지면서도 사용자에게 단순성을 제공한다.
Concept of Relational Model
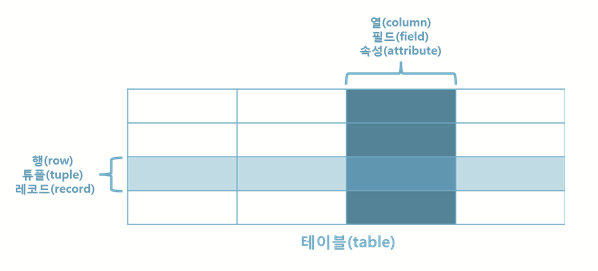
Relation
Relational Data Model 에서 정보를 구분하여 저장하는 기본 단위로, 데이터를 2차원 테이블의 구조로 저장
2차원 테이블 ? 🤔
행 (Row) == 튜플 (Tuple) == 레코드 (Record)
열 (Column) == 필드 (Field) == 속성 (Attribute)
📌 Relation is a set of tuples
📌 Database is a set of relations
SQL로 relation "Movie" 을 정의
아래와 같은 코드를 이용해 Relation 을 생성할 수 있다.
create table Movie (
movieId varchar(10) primary key,
title varchar(100) unique,
genre varchar(32),
length int);Relation Schema
Relation Schema는 Relation의 논리적 구조를 정의한 것으로, Relation intension 이라고도 한다.
Relation Schema에는 Attribute의 이름, 각 Attribute가 가질 수 있는 값의 집합인 Domain,
각 Tuple 에서 Attribute 의 값이 저장될 수 있는 개수인 Degree가 포함된다.
Relation Schema는 R(A1:D1, A2:D2, ..., An:Dn) 과 같은 방식으로 표기된다.
R : Name of Relation
A1, A2, ..., An : Attributes
D1, D2, ..., Dn : Domain
example)
Movie(movieId:varchar(10), title:varchar(100), genre:varchar(32), length:int)
-> Name of Relation : Movie
Attributes : movieId, title, genre, length
Domain : varchar(10), varchar(100), varchar(32), int
Degree : 4Relation Instance
Relation Instance는 Relation에 있는 실제 데이터 레코드를 의미하며, Relation extension 이라고도 한다.
즉, Relation Instance는 Relation에 저장된 Tuples의 집합이다.
Relation Instance는 Relation에 저장된 실제 데이터를 나타내므로,
Relation의 각 Row에 포함된 데이터를 나열해 표기한다.
example)
movieId title genre length
1 The Shawshank Redemption Drama 142
2 The Godfather Crime 175
3 The Dark Knight Action 152
4 Pulp Fiction Crime 154Creation of Relation Schema with SQL
SQL의 Create Table 명령을 이용하여 Relation Schema를 생성할 수 있다.
Table의 이름과 Attributes를 지정하여야 하며, 각 Attributes는 이름과 Data Type을 가진다.
example)
create table Movie (
movieId varchar(10), // 가변 길이의 텍스트 필드
title varchar(100), // 가변 길이의 텍스트 필드
genre varchar(32), // 가변 길이의 텍스트 필드
length int); // 정수형Attribute가 가질 수 있는 Data Type은 다음과 같다 :
-
산술형
정수형 : integer, int, smallint, long
부동 소수점형 : float, real, double precision
형식 정의형 : deciaml(i, j), dec(i, j) -
문자형
고정 길이 : char(n), character(n)
가변 길이 : varchar(n), char varying(n), character varying(n) -
비트형
고정 길이 : bit(n)
가변 길이 : bit varying(n) -
날짜 관련 타입
date, time, datetime, timestamp, time with time zone, interval
-
대용량 데이터 타입
문자열 : long varchar(n), clob(character large object), text
바이너리 : blob(binary large object)
Constraints of Relational Data Model
Relational Data Model에는 Data의 무결성을 유지하기 위해 정해진
Integrity Constraints(무결성 제약 조건) 이 존재한다.
DOMAIN Constraint
Domain Constraint의 정의는 다음과 같다.
각각의 Attributes의 값이 반드시 해당 Attributes의 Domain에 속하는 원자값이어야 하며, Attribute가 가질 수 있는 값의 범위나 조건을 정의할 수 있다.
SQL에서는 CHECK 절 등의 문법을 이용하여 Domain Constraint를 명시할 수 있으며,
이를 통해 Attribute나 Domain의 값을 제한할 수 있다.
( 어떤 Data Type의 전체 혹은 일부 범위를 지정하거나, 가능한 값을 나열하는 등의 작업 가능 )
example)
create table Movie (
movieId varchar(10),
title varchar(100),
genre varchar(32) CHECK (rating IN ('Action', 'Crime', 'Drama', 'SF')), // Domain Constraint
length int);NULL Constraint
Domain Consraint의 일부로, Attribute의 값이 NULL 값을 허용하는지 여부를 정의하는 것이다.
NULL 값의 의미
- Not Applicable (적용되지 않음)
해당 Attribute를 적용할 수 없으므로 값을 가지지 않음
(예 : 결혼하지 않은 사람의 배우자 Attribute)
- Missing (기록되지 않음)
애트리뷰트 값이 존재하지만 지정되지 않음❗
(예 : 어떤 사람의 몸무게 Attribute)
- Unknown (알 수 없음)
애트리뷰트 값이 없거나 혹은 적용할 수 없음
(예 : 전화번호 Attribute - 전화가 없거나 전화번호를 기록하지 않음)
SQL에서는 NULL 또는 NOT NULL keyword를 이용해 Null Constraint를 명시할 수 있다.
( CODE 참고 : default keywork를 이용해 기본값을 지정할 수 있다. )
example)
create table Movie (
movieId varchar(10) NOT NULL default '000-00-000', // NOT NULL Constraint
title varchar(100) NOT NULL, // NOT NULL Constraint
genre varchar(32) CHECK (rating IN ('Action', 'Crime', 'Drama', 'SF')),
length int);KEY Constraint
KEY Constraint를 설정하여 Attribute의 값을 제한할 수 있다.
📌 key에 대한 설명은 다음을 참조 : Database Ch.2-1 - About keys
SQL에서는 Key를 명시하여 KEY Constraint를 설정할 수 있다.
example : Primary Key 설정하기
create table Movie (
movieId varchar(10) NOT NULL default '000-00-000',
title varchar(100) NOT NULL,
genre varchar(32) CHECK (rating IN ('Action', 'Crime', 'Drama', 'SF')),
length int,
PRIMARY KEY (movieId) // Primary Key 설정
UNIQUE (title) // Candidate Key 설정
);위 코드에서 보인 것처럼 Primary Key, UNIQUE 키워드를 이용하여 key를 명시할 수 있다.
※ UNIQUE (Attribute1, Attribute2)와 같이 Composite Key를 명시할 수도 있다.
example : Foreign Key 설정하기
CREATE TABLE StudentInfo (
Student_ID varchar(10) PRIMARY KEY, // Primary Key 설정
Student_Name varchar(50) NOT NULL,
Student_Major varchar(50) NOT NULL,
Course_Code varchar(10) NOT NULL,
FOREIGN KEY (Course_Code) References CourseInfo(Course_Code) // Foreign Key 설정
on DELETE cascade // Foreign Key에 대한 옵션
on UPDATE cascade
);
CREATE TABLE CourseInfo (
Course_Code varchar(10) PRIMARY KEY, // Primary Key 설정
Course_Name varchar(50) NOT NULL,
Course_Credit int NOT NULL
);
위 SQL 코드에서, Foreign Key에 대한 옵션에 대한 의미는 다음과 같다.
on DELETE cascade :
부모 Relation의 Tuple이 삭제될 때, 업데이트 된 value에 대응되는 모든 Tuples도 함께 삭제하는 옵션
on UPDATE cascade :
부모 Relation의 Tuple이 업데이트 될 때, 업데이트 된 value에 대응되는 모든 Tuples도 함께 업데이트하는 옵션
위 옵션 외에도 cascade 키워드 대신 set null이나 set default도 명세할 수 있다.
set null : 삭제/업데이트가 아닌 NULL 값으로 지정
set default : 기본 값으로 지정
단, set null이나 set default를 사용할 경우에는
Entity Integrity Constraint나 KEY Constraint에 위배될 수 있으므로 주의해서 사용해야 한다.
Entity Integrity Constraint
Entity Integrity Constraint란,
Primary Key를 구성하는 어떤 Attribute의 value도 NULL값을 가질 수 없다는 것이다.
이에 대한 설명은 위 Key에 대한 포스트에서 다루었다.
Referential Integrity Constraint
Referential Integrity Constraint란,
Foreign Key는 참조할 수 없는 값을 가질 수 없다는 것을 의미한다.
즉 어떤 Relation A에서 Foreign Key를 이용해 Relation B와 링크되었는데,
A의 Foreign Key로 지정된 Attribute의 value들은 B에 존재해야 한다는 것이다.
만약 A의 Foreign Key로 지정된 Attribute의 한 value가 B에 존재하지 않는 값이라면,
해당 value를 통해 B의 Tuple을 특정할 수 없기 때문이다.
Example)
Relation StudentInfo
--------------------------
- Attributes -
Student_ID Student_Name Student_Major Course_Code (FK?)
1001 Lucas Architectural Engineering ARCH301
1002 Haley Computer Software Engineering CSE101
1003 Jenna Neuroscience NEUR301
1004 Harry Chemistry CHEM201
1005 Anna Computer Software Engineering CSE101
Relation CourseInfo
--------------------------
Course_Code Course_Name Course_Credit
CSE101 Introduction to Computer Science 3
CHEM201 Organic Chemistry I 4
ARCH301 Architectural Design Studio III 5
NEUR101 Introduction to Neuroscience 3위 DataBase에서, Relation StudentInfo의 'Course_Code'에 존재하는 "NEUR301" 값은
Relation CourseInfo 에 존재하지 않는다.
따라서 StudentInfo의 "NEUR301"를 통해 CourseInfo의 Tuple을 특정할 수 없으므로,
Referential Integrity Constraint에 의해 Course_Code는 Foreign Key가 될 수 없다.
Change Schema using DDL of SQL
DROP Statement
DROP 절을 통해 Relation, Domain, Constraint와 같은 Schema 요소를 제거할 수 있다.
example)
DROP CourseInfo Cascade;Cascade는 Relation 제거 시 해당 Relation이 참조하는 Relations와, Relation을 참조하는 Constraint과 같은 요소들도 함께 제거하는 옵션이다.
Cascade를 사용할 때에는 신중하게 사용해야 하며, data의 손실이 일어나지 않게 주의해야 한다.
Cascade 대신 Restrict를 옵션으로 제시하면,
해당 Relation이 삭제되기 전 Relation을 참조하는 다른 Object가 있는지 확인한 뒤,
만약 있다면 에러 메세지를 출력하고 DROP 문이 실패한다.
ALTER Statement
ALTER 절을 통해 Schema 요소들의 정의를 변경할 수 있다.
example)
// Phone_Number Attribute 추가
ALTER TABLE StudentInfo add Phone_Number varchar(15);
// Student_Major Attribute 제거
ALTER TABLE StudentInfo drop Student_Major cascade;
// movieID Attribute의 default 절 제거
ALTER TABLE Movie alter movieID drop default;
// Student_ID Attribute의 새로운 default 절 정의
ALTER TABLE StudentInfo alter Student_ID set default "0000" 