
데이터전문가포럼 카페에서 두노니님 자료 참조하여 작성하였습니다😊
문제 풀이 진행하면서 내용 업데이트 예정입니다
📝 과목1 - 데이터 모델링의 이해
1장 데이터 모델링의 이해
🔽 데이터 모델의 이해
1. 모델링: 현실세계를 단순화하여 표현하는 것
🔻 특징
- 추상화: 일정한 형식에 맞춰 표현함
- 단순화: 제한된 표기법이나 언어로 표현함
- 명확성: 이해가 쉽게 표현함
🔻 관점
- 데이터 관점: 업무와 데이터 및 데이터 사이의 관계
- 프로세스 관점: 진행되고 있거나 진행되어야 하는 업무
- 상관 관점: 데이터에 대한 업무 처리 방식의 영향
2. 데이터 모델링: 정보 시스템 구축을 위한 데이터 관점의 업무 분석 기법
🔻 목적
- 정보에 대한 표기법을 통일하여 업무 내용 분석 정확도 증대
- 데이터 모델을 기초로 DB 생성
🔻 기능
1) 가시화
2) 명세화
3) 구조화된 틀 제공
4) 문서화
5) 다양한 관점 제공
6) 구체화
🔻 중요성
- 파급효과(Leverage)
- 간결한 표현(Conciseness): 정보 요구사항과 한계를 간결하게 표현하는 도구
- 데이터 품질: 유일성(데이터 중복 저장 방지), 유연성(데이터 정의와 데이터 사용 프로세스 분리), 일관성
- 이해관계자: 1) 개발자 2) DBA 3) 모델러 4) 현업업무전문가, 완성된 모델을 정확히 해석할 수 있어야 함
3. 데이터 모델링 3단계
개념적 모델링: 엔터티와 속성을 도출하고 ERD를 작성함, 업무 중심적이고 포괄적인 수준의 모델링논리적 모델링: 식별자를 도출하고 속성과 관계 등을 정의함, 정규화를 수행하여 데이터 모델의 독립성과 재사용성 확보, 논리 데이터 모델은 데이터 모델링 완료 상태물리적 모델링: DB를 구축함, 성능 및 보안 등 물리적인 성격 고려
➕ 프로젝트 생명주기(Life Cycle)
- 계획 > 분석 > 설계 > 개발 > 테스트 > 전환/이행 단계로 구성
- 1) 계획과 분석 단계는
개념적 모델링, 2) 분석 단계는논리적 모델링, 3) 설계 단계는물리적 모델링에 해당
4. DB의 3단계 구조: 데이터 독립성 확보를 목표로 함
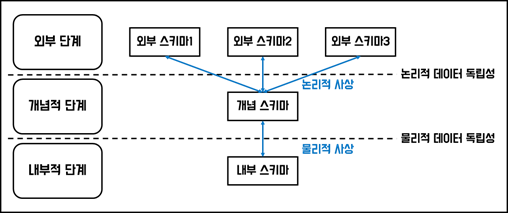
🔻 DB 독립성의 필요성
: 데이터의 중복성과 데이터 복잡도 증가로 인한 1) 유지보수 비용 증가, 2) 요구사항 대응 저하
🔻 3층 스키마(3-level Schema)
외부 스키마: 각 사용자 단계의 개인적 DB 스키마, 사용자 관점, 응용 프로그램이 접근하는 DB를 정의함개념 스키마: 조직 전체의 통합된 DB 스키마, 설계자 관점 데이터 모델링의 지향점내부 스키마: 물리적으로 데이터가 저장되는 방법을 표현하는 스키마, 개발자 관점, 물리적 저장 구조임
🔻 데이터 독립성
- 논리적 독립성: 외부 스키마가 개념 스키마의 변화에 무관함, 논리적 사상 없음
- 물리적 독립성: 개념 스키마가 내부 스키마의 변화에 무관함, 물리적 사상 없음
5. 데이터 모델링 3요소: 엔터티, 관계, 속성
6. ERD(Entity Relationship Diagram)
: 1) 엔터티는 사각형 2) 관계는 마름모 3) 속성은 타원형으로 표현, 현실의 데이터 모두 표현 가능
① 엔터티 도출
② 엔터티 배치
③ 엔터티 간 관계 설정
④ 관계명 기술
⑤ 관계차수 표현: 1:1, 1:N, M:N
⑥ 관계선택사양 표현: 필수, 선택
7. 좋은 모델링의 요건:
1) 완전성
2) 중복 배제
3) 업무 규칙
4) 데이터 재사용
5) 의사소통
6) 통합성
🔽 엔티티
- 정의: 업무에서 관리해야 하는 데이터의 집합, 명사형, 인스턴스의 집합
- 특징:
1) 업무에서 필요로 함,2) 유일한 식별자를 가짐,3) 2개 이상의 인스턴스를 포함함,4) 업무 프로세스에 이용됨,5) 속성을 가짐,6) 관계를 가짐 - 종류
🔻 유무형에 따른 분류
- 유형 엔티티: 물리적 형태가 있고 지속적으로 활용되는 엔티티
- 개념 엔티티: 물리적 형태가 없는 엔티티
🔻 발생시점에 따른 분류
- 기본 엔티티(Key Entity): 독립적으로 생성되는 엔티티
- 중심 엔티티(Main Entity): 기본 엔티티와 행위 엔티티의 중간에 존재하는 엔티티
- 행위 엔티티(Active Entity, 사건 엔티티): 2개 이상의 부모 엔티티로부터 발생함, 비즈니스 프로세스를 실행하면서 생성되는 엔티티, 지속적으로 정보가 추가되고 변경되어 데이터양이 가장 많음
- 명명 규칙:
1) 현업업무에서 사용하는 용어,2) 약어 지양,3) 단수 명사,4) 유일성 보장,5) 명확성
🔽 속성
-
정의: 엔티티가 가지는 최소 의미 단위, 인스턴스의 구성요소
-
엔티티와 인스턴스 및 속성과 속성값 간의 관계

-
속성 표기법:
IE 표기법,Barker 표기법 -
특징:
1) 업무에서 필요하고 관리하고자 하는 정보
2) 주식별자에 함수적으로 종속됨
3) 속성값 하나만 가짐 (하나 이상의 속성값이면 정규화 필요) -
종류
🔻 특성에 따른 분류
- 기본 속성: 비즈니스 프로세스에서 도출되는 본래의 속성
- 설계 속성: 데이터 모델링 과정에서 업무 규칙화를 위해 발생하는 속성
- 파생 속성: 다른 속성에 의해 만들어지는 속성 (↔ 저장 속성은 유도 속성을 생성하는 데 사용되는 속성)
🔻 분해 가능 여부에 따른 분류
- 단일 속성: 하나의 의미
- 복합 속성: 여러 의미, 단일 속성으로 분해 가능
ex) 주소 - 단일값 속성: 하나의 값
- 다중값 속성: 여러 값, 엔터티로 분해 가능
🔻 엔터티 구성방식에 따른 분류
- 기본키 속성: 엔터티를 식별할 수 있는 속성
- 외래키 속성: 다른 엔터티와의 관계에서 포함된 속성
- 일반 속성: 엔터티에 포함되고 PK나 FK 속성이 아닌 속성
- 도메인: 속성이 가질 수 있는 값의 범위
🔽 관계
- 정의: 엔터티 간의 논리적인 관련성, 동사형
- 관계의 페어링: 인스턴스 간 개별적 관계
- 관계 표기법: 1) 관계명 2) 관계차수 3) 관계선택사양
🔻 관계차수(Cardinality)
: 관계 내 튜플의 전체 개수, 1은 직선 多는 삼발로 표시
- M:N 관계: 관계형 DB에서 M:N 관계의 조인은 카테시안 곱 발생
🔻 관계선택사양(Optionality)
: 필수는 I 선택은 O로 표시
- 종류
🔻 ERD 기준: 표기구분 안함
- 존재 관계: 엔터티 간의 상태
- 행위 관계: 엔터티 간에 발생하는 행위
🔻 UML(Unified Modeling Language) 기준
- 연관 관계(Association): 실선 표기
- 의존 관계(Dependency): 점선 표기
🔻 식별자에 따른 분류
- 식별 관계: 부모 엔터티의 식별자를 자식 엔터티에서 주식별자로 사용
➕ 약한 엔터티: 부모 엔터티에 종속되어 존재 (↔ 강한 엔터티는 독립적으로 존재함) - 비식별 관계: 부모 엔터티의 식별자를 자식 엔터티에서 일반 컬럼으로 참조 사용, 약한 종속 관계
➕ 식별 관계만으로 연결되면 주식별자 수가 많아질 수밖에 없으므로1) 관계 강약 분석,2) 자식 엔터티의 독립 PK 필요성,3) SQL 복잡성과 개발 생산성 고려 필요
- 관계 읽기: 각각의/하나의 > 기준 엔터티 > 관계차수 > 대상 엔터티 > 관계선택사양 > 관계명
🔽 식별자
- 정의: 엔터티를 대표할 수 있는 유일성을 만족하는 속성
- 특징:
1) 유일성,2) 최소성,3) 불변성,4) 존재성 - 종류
🔻 대표성 여부에 따른 분류
- 주식별자: 대표성을 만족하는 식별자
- 보조 식별자: 유일성과 최소성만 만족하는 식별자, 참조 관계 연결에 사용할 수 없음
➕ DB 키의 종류
‒ 기본키(PK; Primary Key): 엔터티를 대표하는 키, 후보키 중 선정됨
‒ 후보키: 유일성과 최소성을 만족하는 키
‒ 슈퍼키: 유일성만 만족하는 키
‒ 대체키: 기본키를 제외한 나머지 후보키
‒ 외래키(FK; Foreign Key): 여러 테이블의 기본 키 필드, 참조 무결성(Referential Integrity)을 확인하기 위해 사용됨 (허용된 데이터 값만 저장하기 위함)
🔻 생성 여부에 따른 분류
- 내부 식별자: 자연스럽게 존재하는 식별자 (~ 본질식별자)
- 외부 식별자: 다른 엔터티와의 관계를 통해 생성되는 식별자
🔻 속성 수에 따른 분류
- 단일 식별자: 하나의 속성
- 복합 식별자: 여러 속성
🔻 대체 여부에 따른 분류
- 본질 식별자: 대체될 수 없는 식별자
- 인조 식별자: 인위적으로 만들어지는 대체가능한 식별자 (순서번호(Sequence Number)를 사용하여 생성된 식별자),
1) 후보 식별자 중 주식별자로 선정할 것이 없거나,2) 주식별자가 너무 많은 칼럼으로 구성되어 있을 때사용
- 주식별자 도출 기준: 업무에서 자주 이용되는 속성, 이름 명명 지양, 복합 식별자 지양
