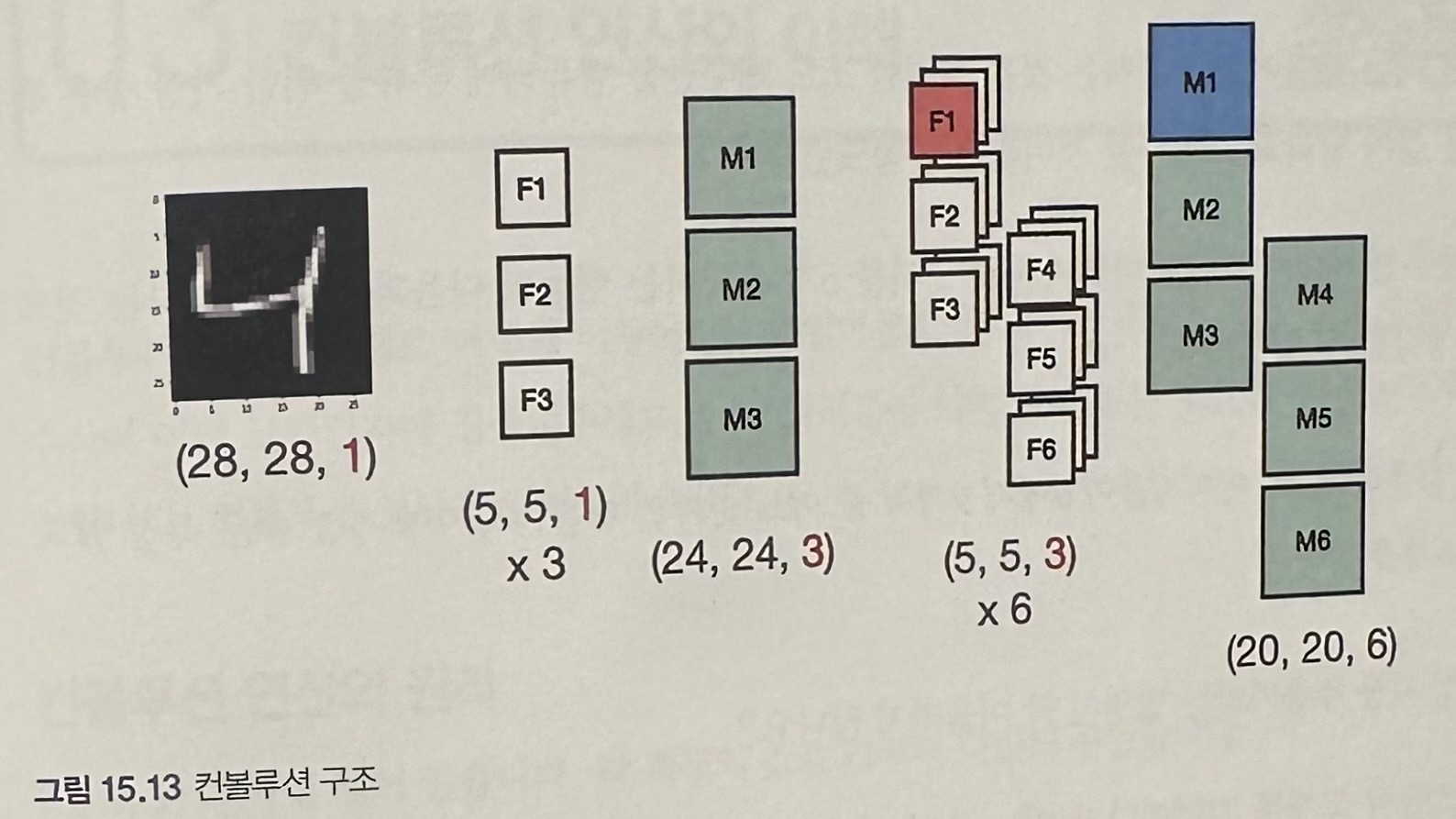
- 필터셋은 3차원 형태로 된 가중치의 모음이다. 컨볼루션 구조에서 컴퓨터가 학습하는 건 바로 필터이다.
- 필터셋 하나는 앞선 레이어의 결과인 피처맵 전체를 본다. 전체를 보고 필터셋 하나가 피처맵 하나를 만든다.
- 필터셋 하나가 피처맵 하나를 만드니, 필터셋 개수만큼 피처맵을 만들게 된다.
Conv2D(3, kernal_size=5, activation='swish')
Conv2D(6, kernal_size=5, activation='swish')첫번째 레이어는 필터셋이 3개, 두번째 레이어는 필터셋 6개이다.
그리고 각 필터는 (5,5)사이즈이고, 3차원 형태로 된 가중치의 모음이라고 했다.
3차원의 필터셋이라고 하는 것은 개별 필터셋 하나가 3차원 형태라는 뜻이다. 즉, (5,5) 사이즈의 필터가 여러 채널 존재하는 것이다.
입력이 흑백인 경우 채널이 하나이므로 필터셋의 형태는 (5,5,1)이다. 입력이 컬러이미지라면 채널이 3개이므로 필터셋의 형태도 (5,5,3)이 된다.
또한, 필터셋의 전체 모양은 다음과 같이 4차원 형태가 되는 것이다. 필터셋이 3개이니까 (3,5,5,?)이고, 물음표는 앞선 채널의 개수와 동일하다는 의미이다.
필터셋은 (5,5)의 필터가 채널 수만큼 겹쳐진 형태를 말한다.
딥러닝 모형으로 이해
Conv2D(3, kernal_size=5, activation='swish')
Conv2D(6, kernal_size=5, activation='swish')입력이미지가 있다. (28,28)에 흑백이라 채널이 1개이다.
(5,5,1) 필터셋이 3개 준비되었고 필터셋 하나는 한장의 피처맵을 생성하므로 이 필터셋에 의하여 피처맵 3장, 3채널의 피처맵이 생성된다.
사이즈가 28에서 24로 4만큼 줄게되는데, 그 이유는 필터사이즈가 5이기 때문이다. 사이즈에서 1을 뺀 수만큼 사이즈가 감소한다. 필터가 (5,5)면 4만큼 줄어들고 (3,3)이면 2만큼 줄어든다.
두번째 컨볼루션 레이어에서는 6장의 필터셋을 준비했다. 필터셋의 채널 수가 앞선 레이어의 결과인 피처맵 채널수와 같은 3으로 되어있다.
필터셋이 6개이니 6채널의 피처맵이 생성된다.
피처맵 하나를 만들 대 필터셋 하나는 앞의 피처맵 전체를 보고 새로운 피처맵 하나를 만드는 것이다.
이전에 표의 특징을 학습한 패턴 모델을 레이어와 노드로 표현한 그림이다. 하나의 특징을 만들 때 앞선 레이어의 노드 전체를 사용하여 학습한다고 했다. 앞선 피처맵 전체를 보고 새로운 피처맵하나를 만든다는 것과 같은 의미이다. 또한 이 노드의 84개의 특징은 컴퓨터가 가중치들을 학습해서 스스로 찾아낸 특징이고, 그래서 딥러닝에는 특징 자동 추출기라는 별명이 붙어있다고 설명했다.
컨볼루션 레이어에서는 컨볼루션 필터들을 뜯어보면 가중치들로 이루어져있고 컴퓨터는 피처맵을 만들어내는 이 컨볼루션 필터를 학습한다.
앞서 히든 레이어를 추가하는 것은 지정한 노드 개수만큼 컴퓨터에 분류를 위한 가장 좋은 특징을 찾아 달라고 요청하는 것이라고 했는데, 컨볼루션 레이어에서도 마찬가지로 필터를 6개 추가하는것은 "이 이미지들이 0에서 9까지 중 어느 숫자인지 판단하기에 가장 좋은 특징맵 6개를 찾아줘'라고 하는 것과 같다.
