
오늘은 실전 스프링 부트 후기를 적어보고자 한다, 약 한 달만에 적게되는 글인데 저번과 동일하게 책은 이미 4주 전에 다 읽고 정리를 한 상태다, 현재는 자바 ORM 표준 JPA 프로그래밍 을 약 절반가량 읽고 있는 상태다, 지금까지 4.5권 분량을 읽고 정리를 했는데, 신기하게도 책을 읽을 수록 과거 인문학을 읽었을 시절과 비슷하게 생각이 깊어지고 있는 거 같다.. 좋은건가?
쉬어가는 시간
이번 실전 스프링 부트 후기를 읽으면서 가장 처음 드는 생각은, 이전에 읽은 토비의 스프링 이 정말 완독하기 어려운 책이라는걸 역체감할 수 있었다, 그렇다고 해서 실전 스프링 부트가 쉬운 책이라는 얘기는 아니다, 단지 토비의 스프링은 내가 알아서 찾아야하는 느낌이라면 실전 스프링 부트는 책을 지은 저자가 마지막에 따로 정리를 해놓아서 입에 떠 넣어주는 느낌이었다,
우선, 이번 실전 스프링 부트의 경우 약 3.2만자 가량 정리를 할 수 있었고 토비의 스프링은 어떤걸 정리 하는게 좋을지 고민되서 1.8만자 가량 더 적었지만 실질적인 현재 내 서비스에서 리팩토링 해야하는 부분은 실전 스프링 부트가 압도적으로 많았다,
좀 많이 세부적으로 나누었긴 했지만, 체크 리스트를 작성하다보니 백엔드 부분만 약 150개 정도의 확인 해야하는 항목이 생겼고, 이러한 체크 리스트 중에서 같은 문제라고 판단 되는 부분들은 엮어서 내가 어떤식으로 해결 했는지 개략적으로 적어놓았다,
(솔직히 정리 된 거 보다 정리 안 된게 더 많아서 나중에 서비스를 다 완성하면 제대로 되돌아보는 시간을 무조건 가지는게 맞는 거 같다)
여튼, 다시 본론으로 돌아와서 소제목과 같이 이번 실전 스프링 부트는 여태까지 쉬지 않고 약 2천 페이지 되는 분량의 3권을 읽어오고 최대한 정리를 해온 나에게, 조금은 숨통이 트일 수 있도록 흥미로운 얘기와 더불어 당장 고쳐야할 문제점들을 되돌아볼 수 있었다,
그리고 토비의 스프링을 나름 괜찮게 읽었다고 느껴진게, 이전에 토비의 스프링을 읽었을 때는 배경지식이 부족해서 책을 읽다가 따로 서칭하고 정리해야하는 시간이 필요했었는데,실전 스프링 부트의 경우 토비의 스프링 덕분에 굳이 검색하지 않고 내가 가진 배경지식만으로도 바로 이해가 된다는 사실이 신기했다.
후기
요약
이번에도 잡설이 많았다, 솔직히 책 후기를 자세히 적는 거 보다 느낀점을 이정도로만 요약하고 내 얘기를 더 하고 싶지만, 포스팅을 하면서 다시 한번 되돌아봤을 때 얻는거를 절대 무시할 순 없는 거 같다, 이번 실전 스프링 부트를 요약하면 아래와 같다
실무에서 바로 적용할 수 있는 다양한 사례와 모범 사례를 제시하는 실용적인 가이드
매번 느끼는거지만, 개발 서적의 소제목들은 책을 다 읽고 난 이후에 공감을 할 수 밖에 없는 거 같다, 간혹 다른 책의 경우 표지에 있는 내용이 정말 조금 나오는 경우도 있었는데, 여태까지 읽은 개발 서적의 소제목은 이 책을 한 문장으로 완벽하게 요약했다고 생각하게 된다,
말 그대로, 이번 실전 스프링 부트는 실무에서 생각해볼만한 문제들을 계속해서 알려주는 느낌이었다, 아직 실무를 경험해보지는 않았지만 최소한 이정도는 알아야 하지 않을까? 라는 생각이 들었고, 전체적으로 배경지식이 한 레벨 더 넓어진 느낌이었다.
Chapter 1. 스프링 부트 시작하기
어떤 개발 서적이든 1~2챕터까지는 해당 기술을 배우기 전에 이 기술의 개념이 무엇인지, 초기 세팅을 어떻게 하는지, 여러 설정 방법에 대해서 다루는 거 같다, 실전 스프링 부트 역시 챕터 1는 스프링에 대한 내용을 주로 다룬다, 이 챕터에서 내가 중요하다 생각한 부분들은 아래와 같다.
- 스프링 부트 개념
- 스프링 부트 이벤트
- JAR 파일 구조
스프링 부트 개념
스프링 부트가 무엇인지는 지난 토비의 스프링에서 정말 지겹도록 다루었던 내용이다, 스프링 부트는 자바 엔터프라이즈 개발을 편하게 해주는 오픈소스 경랑급 애플리케이션 프레임워크 이다, 엔터프라이즈 개발에서 발생하는 복잡성을 줄일 수 있으며, 자동 구성 기능을 통하여 개발자는 최소한의 설정만으로도 복잡한 애플리케이션을 쉽게 구축할 수 있고 덕분에 개발자는 비즈니스 로직에만 집중할 수 있다, 특히 보일러 플레이트 코드를 줄이는데 탁월한 효과를 발휘한다.
보일러 플레이트 : 컴퓨터 프로그래밍에서 보일러플레이트 또는
보일러플레이트 코드라고 부르는 것은 최소한의 변경으로 여러곳에서 재사용되며,
반복적으로 비슷한 형태를 띄는 코드를 말한다.즉, 스프링부트는 개발자 관점에서는 스프링 부트, 개발자와 스프링 프레임워크 사이에 위치한다. 개발자가 사용하는 스프링 컴포넌트를 스프링 부트가 자동으로 설정해준다

스프링 부트 이벤트
스프링 부트 이벤트는 애플리케이션의 특정 상태나 동작을 모니터랑하고 관리할 수 있도록하는 이벤트 관리 체계를 의미한다, 이벤트 발행자와 이베트 구독자의 분리를 통하여 특정 작업이나 상태 변화에 대하여 유연하게 대처할 수 있다,
예를 들어, 사용자 등록 이후에 자동으로 알림을 보내거나 로그를 기록하는 등의 작업을 쉽게 구현할 수 있다, 즉 스프링 프레임워크의 이벤트 관리 체계는 이벤트 발행자(publisher)와 이벤트 구독자(subscrib) 분리를 강조하며, 이벤트를 구독하고 이벤트 발행이 감지되면 작업이 실행되도록 함으로써 편리하게 문제를 처리 가능하다
- 로직이 복잡한 경우 유용하게 쓸 수 있다 (ex, 유저 삭제 기능, 알림 기능 등등)
JAR 파일 구조
스프링 부트는 JAR 파일로 패키징 되어 독립적으로 실행할 수 있다, JAR 파일 구조는 META-INF, BOOT-INF/classes 등의 디렉토리로 구성되며, 이를 통하여 외부 의존성 없이 쉽게 배포하고 실행할 수 있다.
또한 JAR 파일 구조의 경우 크게 네 가지로 나눌 수 있다.
- META-INF
: 이 디렉토리에는 실행할 JAR 파일에 대한 핵심 정보를 담고 있는 MANIFEST.MF 파일이 들어있으며, 이 파일안에는 두 가지 주요 파라미터인 main-class와 start-class가 들어있다 - 스프링부트 로더 컴포넌트
: 스프링부트 로더에는 실행 가능한 파일을 로딩하는 데 사용하는 여러 가지 로더 구현체가 있다 - BOOT-INF/classes
: 컴파일된 모든 애플리케이션 클래스가 들어있다 - BOOT-INF/lib
: 의존 관계로 지정한 라이브러리들이 들어있다
start-class는 애플리케이션을 시작할 클래스를 가리키며
main-class는 start-class를 사용해서 애플리케이션을 시작하는 Launcher 클래스 이름이 지정되어 있다
Chapter 2. 스프링 부트 공통 작업
두 번쨰 챕터인 스프링 부트 공통 작업의 경우 스프링 설정 및 커스텀화를 중점으로 다루고 있다, 참고로 이전 토비의 스프링 Vol.2에서 언급했던 내용이지만 스프링 프레임워크를 잘 사용하기 위해서는 현재 프로젝트에 최적화된 스프링 프레임워크를 만들어야한다, 그리고 이번 챕터는 이에 대해서 어느정도 다루는 내용이다, 중요한 부분은 아래와 같다.
- 스프링 설정
- 커스텀 빈 밸리데이션
- CommandLineRunner와 애플리케이션 초기화
스프링 설정
스프링 부트 애플리케이션 설정은 주로 application.properties 또는 application.yml 파일을 통해 관리된다, 이 파일들은 애플리케이션의 환경 설정을 중앙에서 관리할 수 있게하며 덕분에 필요에 따라 프로필을 사용해서 환경에 맞는 설정을 적용할 수 있다,
또한, @PropertySource 애노테이션을 사용해서 외부 프로퍼티 파일을 읽어보는 방식도 지원한다, 나 역시 이 챕터를 읽으면서 여태까지 미루고 있었던 운영환경 분리에 대한 문제를 해결했다

커스텀 빈 밸리데이션
스프링 부트 빈 밸리데이션을 통하여 애플리케이션의 입력값을 검증할 수 있다, 그리고 빈 밸리데이션을 통해 에러가 발견되면 에러 핸들러를 통해서 처리가 가능하도록 하면 비즈니스 로직에서 에러에 대한 처리 메시지를 매번 담아서 보내는 문제를 해결 가능하다,
빈 밸리데이션은 자바 세계에서 사용되는 사실상의 표준 밸리데이션이다, 빈 밸리데이션 명세를 사용하면 다양한 Validation을 간단한 애노테이션으로 쉽게 구현 가능하다, 게다가 개발자가 직접 커스텀 밸리데이터를 만들어서 사용할 수 있다,
아래는 빈 밸리데이션과 관련된 어노테이션들이다
@Target
: @Password 애노테이션을 적용할 대상 타입을 지정한다, 예제에 사용된(78page) @Password 애노테이션은 메서드와 필드에 지정할 수 있다@Retention
: @Password 애노테이션이 언제까지 효력을 유지하고 살아남는지를 지정한다 예제와 같이 RUNTIME을 지정하면 런타임까지 살아남아 효력을 유지한다@Constraint
: @Password 애노테이션이 빈 밸리데이션 제약 사항을 포함하는 애노테이션임을 의미하며, ValidateBy 속성을 사용해서 제약 사항이 구현된 클래스를 지정할 수 있다message()
: 유효성 검증에 실패할 때 표시해야하는 문자열을 지정한다class<?>[] groups{}
: 이 메서드를 사용해서 그룹을 지정하면 밸리데이션을 그룹별로 적용할 수 있다class<? extends PayLoad>[] payload()
: 밸리데이션 클라이언트가 사용하는 메타데이터를 정렬하기 위해서 사용한다, 예제에서는 아무런 페이로드도 지정하지 않는다
ConstraintValidator 인터페이스를 구현하는 경우 제약조건을 검증하며, 커스텀 검증 로직을 구현 가능하다, isValid() 메서드안에서 비즈니스 정책 준수 여부를 판별해서 윻성 검증하는 로직을 구현해야한다.
CommandLineRunner와 애플리케이션 초기화
스프링 부트 애플리케이션 시작시 CommandLineRunner를 이용해서 초기화 코드를 실행 가능하다, ComnnadLineRunner를 이용하면 다음 여러가지 방법으로 사용할 수 있다
- 스프링 부트 메인 클래스가 CommandLineRunner 인터페이스를 구현하게 만든다
- CommandLineRunner 구현체에 @Bean을 붙여서 빈으로 정의한다
- CommandLineRunner 구현체에 @Component를 붙여서 스프링 컴포넌트로 정의한다
여기서 @Bean과 @Component는 어떤 차이가 있을까?
- 두 애노테이션 모두 스프링에 의해 빈으로 등록된다는 공통점이 있지만 사용법은 조금 다르다,
- 빈으로 등록하고자 하는 클래스의 소스 코드에 직접 접근할 수 없을 때는 해당 클래스의 인스턴스를 반환하는 메서드를 작성하고 이 메서드에 @Bean 애노테이션을 붙여서 빈으로 등록하게 한다,
- 반대로 빈으로 등록하고자 하는 클래스의 소스 코드에 직접 접근할 수 있을 경우에는 이 클래스에 직접 @Component 애노테이션을 붙여서 빈으로 등록한다.
CommandLineRunner를 사용하는 3가지 방법
- 스프링부트 메인 클래스가 CommandLineRunner 인터페이스를 구현하게 하고 run() 메소드 안에 구현 내용 추가
- CommandLineRunner를 반환하는 메서드에 @Bean 애노테이션 추가
- CommandLineRunner를 구현하는 클래스에 @Component 애노테이션 추가
Chapter 3. 스프링 데이터를 사용한 데이터베이스 접근
이번 챕터는 스프링 데이터와 관련된 내용을 다루는 챕터이다, 스프링 데이터는 스프링 프레임워크를 통해 서로 다른 종류의 데이터를 친숙한 프로그래밍 모델을 사용해서 쉽고 일관성 있게 다룰 수 있게 해준다, 그리고 내가 생각했을 때 이번 챕터에서 중요하다 생각되는 부분은 아래와 같다
- 스프링 데이터 JPA
- CRUD 리포지토리와 엔티티 관리
- 히카리 커넥션 풀
스프링 데이터 JPA
스프링 데이터는 스프링 프레임워크를 통해 서로 다른 종류의 데이터를 친숙한 프로그래밍 모델을 사용해서 쉽고 일관성 있게 다룰 수 있게 해준다고 위해서 얘기했다,
- 특정 DB를 대상으로 하는 여러가지 하위 프로젝트를 포함하고 있는 상위 프로젝트다
- 스프링 데이터 JPA 모듈은 H2, MySQL, PostgreSQL 같은 관계형 DB를 대상으로하고
스프링 데이터 몽고 DB는 몽고 DB를 대상으로 한다
스프링 데이터의 핵심 목표는 여러 데이터 소스의 데이터를 다룰 때 일관성 있는 프로그램 모델을 제공하는 것이다
- 그래서 데이터 소스에 저장해야 하는 도메인 객체의 메타데이터를 편리하게 지정할 수 있는 API를 제공하여 비즈니스 도메인 객체가 특정 데이터 스토어에 저장될 수 있도록 한다
- 관계형 데이터베이스와 스프링 데이터 JPA를 사용해서 비즈니스 관계를 관리할 수 있다
CRUD 리포지토리와 엔티티 관리
Repository 인터페이스는 메서드나 상수를 포함하고 있지 않고, 오직 객체의 런타임 타입 정보만을 알려주는 마커 인터페이스로서 도메인 클래스와 도메인 클래스의 식별자 타입 정보를 포함하고 있다
- 그리고 CrudRepository는 이러한 Repository 인터페이스를 상속받은 하위 인터페이스다
- CRUD 연산을 포함하고 있다
그리고 아래는 엔티티 관리와 관련된 애노테이션들이다
@Entity
: 애노테이션은 이 클래스가 JPA로 관리되는 엔티티 클래스라는 것을 알려준다@Table
: 애노테이션은 이 엔티티가 저장될 테이블에 대한 정보를 알려준다@Column
: 애노테이션은 자바의 필드 정보와 테이블의 컬럼 정보를 매핑해준다@Id
: 애노테이션이 붙어 있는 필드는 테이블에서 기본 키(Primary Key)로 사용된다@Generated-Value
: 애노테이션은 식별자로 사용되는 id 값이 자동 생성됨을 알려준다, id는 JPA에 의해서 자동 생성되므로 생성자에는 id 필드가 포함되어 있지 않다
참고로 뜬금없는 얘기지만, 토비의 스프링을 읽을 당시, 항상 인터페이스로 감싸는게 좋다고 생각해서 "Repository도 인터페이스로 감싸야하는거 아닌가?" 라는 생각을 잠시 가진적이 있었는데, Repository 자체가 이미 인터페이스였다는 해프닝이 있다, 그래서 몇개월 차이가 안 나지만 이해도가 확실히 달라진 거 같다...
히카리 커넥션 풀
스프링 부트는 자동 구성을 통해 히카리 커넥션 풀을 사용한다,
- 데이터베이스 커넥션 풀은 한 개 이상의 데이터베이스 연결을 포함하고 있으며, 일반적으로 애플리케이션이 시작될 때 커넥션 풀이 구성된다,
- 여러 개의 데이터베이스 연결을 애플리케이션이 시작될 때 미리 생성해서 풀에 넣고 필요할 때 꺼내어 사용하고 사용 후 다시 풀에 반납하므로 쿼리를 실행할 때 마다 데이터베이스 연결을 생성할 필요가 없어진다, 사용 후에도 삭제할 필요가 없어짐
- 스프링 부트는 히카리 커넥션 풀을 기본 데이터베이스 커넥션 풀으로 사용한다
<히카리 커넥션 풀 의존관계>
Spring-boot-Starter-data-JPA → Spring-boot-Starter-Jdbc → HikariConnectionPool
Chapter 4. 스프링 자동 구성과 액추에이터
4장에서는 스프링 부트 자동 구성(autoConfiguration)과 스프링 부트 액추에이터(Actuator)를 알아보았다, 스프링 부트 자동구성은 애플리케이션에 사용된 수 많은 컴포넌트에 대한 설정을 자동으로 구성해줘서 애플리케이션 개발을 더 쉽게 가능하며 스프링 부트 액추에이터는 스프링 부트 애플리케이션을 모니터랑하고 상호작용할 수 있는 인프라스트럭처를 제공한다, 아래는 주요 키워드 세가지다
- 스프링 부트 개발자 도구
- 스프링 부트 액추에이터
- HealthIndicator와 커스텀 모니터링
스프링 부트 개발자 도구
스프링 부트는 개발과정에서 필요한 기능을 담은 도구 세트도 제공한다, 애플리케이션 개발 경험을 더 개선할 수 있고 생산성도 높일 수 있다.
-
프로퍼티 기본값
: 스프링 부트와 스프링 부트를 구성하는 라이브러리 중 일부는 성능 향상을 위해 캐시를 지원한다, 예를 들어 타임리프 템플릿 엔진은 한 번 호출되면 HTML을 캐시하고 이후 호출될 때는 파싱하지 않고 캐시에 저장된 HTML을 사용한다. -
자동 재시작
: 일반적으로 개발 환경을 구성한 후 소스코드를 변경하고 변경 내용을 확인하려면 애플리케이션을 재시작해야한다, 스프링 부트 개발자 도구를 사용하면 클래스 패스에 변경 사항이 생길 떄마다 자동으로 애플리케이션을 재시작 해준다,- 스프링 부트는 두 개의 클래스 로더를 사용해서 자동 재시작 기능을 구현한다
- 하나는 기본 클래스 로더라고 불리우며, 서드파티 라이브러리 처럼 변경되는 일이 별로 없는 클래스를 로딩한다
- 둘은 리스타트 클래스 로더라고 불리우며 개발자가 작성하는 변경이 잦은 클래스를 로딩한다
- 스프링 부트는 두 개의 클래스 로더를 사용해서 자동 재시작 기능을 구현한다
-
라이브 리로드
: 스프링 부트 개발자 도구에는 웹 페이지를 구성하는 리소스가 변경됐을떄 브라우저 새로고침을 유발하는 내장된 라이브 리로드 서버가 포함되어 있다
스프링 부트 액추에이터
스프링 부트 액추에이터는 스프링 부트 애플리케이션 모니터링과 관리에 필요한 기능을 제공한다
주요 장점 중 하나는 애플리케이션 운영에 필요한 광범위한 기능을 직접 구현할 필요없이 쉽게 사용할 수 있다는 점
스프링 부트 액추에이터 엔드포인트를 통해 애플리케이션 대한 정보를 확인해야한다
스프링부트가 제공하는 Info 엔드포인트를 통해서 애플리케이션 관련 정보를 확인할 수 있다,
info 엔드포인트는 기본적으로 아무 정보도 제공하지 않지만 커스텀마이징을 통해 원하는 정보를 출력할 수 있다
HealthIndicator와 커스텀 모니터링
Management, endpoint, health, show, details 프로퍼티에는 다음과 같이 세 가지 값을 지정할 수 있다.
always
: 상태 상세 정보를 항상 표시한다never
: 기본값이며 상태 상세 정보를 표시하지 않는다when-authorized
: 애플리케이션에서 인증되고applicaiton.properties 파일의 management, endPoint, Health, roles로 지정한 역할을 가지고 있는 사용자가 접근할 때만 상태 상세 정보를 표시한다
health 엔드포인트가 반환하는 JSON의 루트에 있는 Status 필드는 애플리케이션의 상태 정보를 집약해서 다음과 같이 기본적으로 네가지 값 중 하나로 표시된다
- Down : 컴포넌트를 정상적으로 사용할 수 없는 상태
- Out-of-Serivce : 컴포넌트가 일시적으로 동작하지 않는 상태
- Up : 컴포넌트가 의도한대로 동작하는 상태
- UnKnown : 컴포넌트 상태를 알 수 없는 상태
스프링 부트에 내장된 HealthIndicator는 애플리케이션에 특화된 컴포넌트에 대한 상태 정보를 보여주지 않는다, 하지만 스프링 부트는 HealthIndicator 인터페이스를 통해 health 엔드 포인트 기능을 확장할 수 있도록 열어두었다, 스프링 부트는 개발자가 구현한 HealthIndicator 구현체도 스프링 컴포넌트로 간주하여 스프링 부트 컴포넌트 스캐닝 시 감지할 수 있고 자동으로 health 엔드포인트에 연동해준다.
Chapter 5. 스프링 부트 애플리케이션 보안
스프링 부트 애플리케이션 보안은 챕터 제목부터 상당히 많은 궁금증을 만들어냈다, 첫 서비스를 만들 때부터 항상 들었던 고민 중 하나가 바로 보안이었다, 내가 아무리 좋은 아이디어로 서비스로 만든다고 한들, 보안이 취약한 서비스라면 금방 사용쟈가 떠날 것이고, 나는 걱정이 많은 성격이기에 보안적으로 취약해서 발생한 문제는 당연히 신경이 쓰일 수 밖에 없었다, 그래서 해당 챕터는 조금 더 신경을 기울이며 읽은 기억이 있다, 이 챕터에서 중요한 내용은 아래와 같다
- 스프링 시큐리티 개념
- 사용자 인증과 인가
- Oauth2.0과 소셜 로그인
스프링 시큐리티 개념
스프링 시큐리티의 여러가지 보안 기능을 알아보자, 제공해주는 기본적인 보안기능들이다.
1. 애플리케이션 사용자 인증
2. 별도의 로그인 페이지가 없을 때 사용 할 수 있는 기본적인 로그인 페이지
3. 폼기반 로그인에 사용할 수 있는 기본 계정
4. 패스워드 암호화에 사용할 수 있는 여러가지 인코더
5. 사용자 인증 성공 후 세션 ID를 교체해서 세션 고정 공격 방지
6. HTTP 응답 코드에 랜덤 문자열 토큰을 포함해서 사이트칸 요청 위조 Cross-site request-forgery (CSRF 공격) 방지
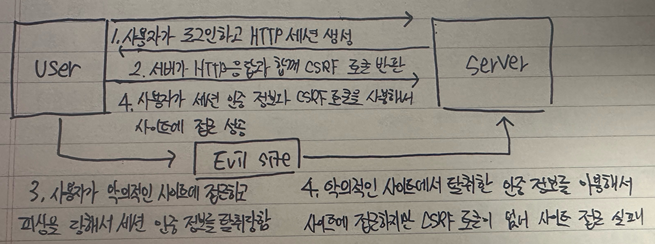
스프링부트 애플리케이션을 보호하는데 사용되는 헤더와 그 역할은 아래와 같다
Cache-Control
: 브라우저 캐시를 완전하게 비활성화X-Content-Type-Options
: 브라우저의 콘텐트 타입 추측을 비활성화 하고 Content-Type 헤더로 지정된 콘텐트 타입으로만 사용하도록 강제Strict-TransPort-Security
: 응답 헤더에 포함되면 이후 해당 도메인에 대해서는 브라우저가 자동으로 HTTPS를 통해 연결되도록 강제하는 HSTS(Http Strict TransPort Security) 활성화X-Frame-options
: 값을 Deny로 설정하면 웹 페이지 콘텐트가 Frame, iframe, emved 에서 표시 되지 않도록 강제해서 클릭 재킹 공격 방지X-XSS-Protection
: 값을 1; mode = block으로 설정하면 브라우저의 XSS(Cross Site Scriping) 필터링을 활성화하고 XSS 공격이 감지되면 해당 웹피이지를 로딩하지 않도록 강제한다
사용자 인증과 인가
- 인증 (Authentication)
: 인증은 사용자가 스스로 인증하는 과정이다, 인증은 사용자의 아이디와 비밀번호, 인증서, 생체 정보 등 사용자를 식별할 수 있는 정보를 확인하는 과정을 통해 진행된다 - 인가 (Authorization)
: 인가는 인증된 사용자가 할 수 있는 행위를 정의한다, 인증을 통해 애플리케이션에 들어와 있기는 하지만 애플리케이션에서 모든 행동을 다 할 수 있는 것은 아니며 인가된 행동만 할 수 있다
일반적인 자바 웹 애플리케이션에서 클라이언트는 HTTP나 HTTPS 프로토콜을 사용해서 서버자원에 접근한다
- 클라이언트의 요청은 서버의 서블릿에서 처리된다
- 서블릿은 HTTP 요청을 받아 처리한 후 HTTP 응답을 클라이언트에게 반환한다
- 스프링 웹 애플리케이션에서는 DisPatcherServlet이 서블릿의 역할을 담당하고 들어오는 모든 요청을 처리한다
서블릿 명세에 있는 요청 - 응답 처리과정에서 중심축을 담당하느 주요한 컴포넌트는 '필터'다
- 서블릿의 앞 단에 위치해서 요청 - 응답을 가로채서 변경할 수 있다
- 한 개 이상의 필터는 필터 체인으로 구성하여 모든 필터는 요청 - 응답 객체를 가로채서 변경할 수 있다
(클라이언트) <-- Http 요청/응답 --> [ (필터) -- (서블릿) ] <- 서버스프링 웹 애플리케이션으로 들어오는 모든 요청을 하나의 특별한 서블릿인 DS 혼자서 처리하는 것과 마찬가지로 스프링 시큐리티는 하나의 특별한 필터인 DelegatingFilterProxy에 의해 활성화 된다
- DelegatingFilterProxy 필터는 스프링 부트의 자동 구성으로 서블릿 컨테이너에 등록되고 들어오는 모든 요청을 가로챈다
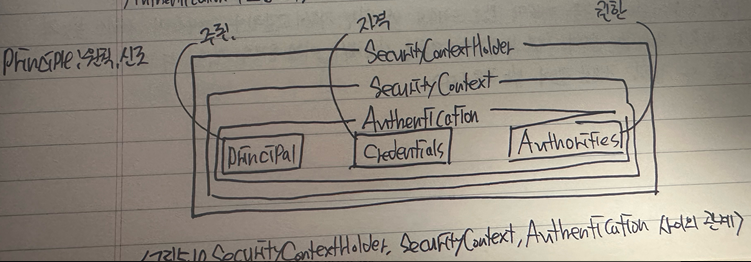
- SecurityContextHolder
→ SecurityContext 인스턴스를 현재 실행 중인 스레드에 연동한다
→ SecurityContext 인스턴스에는 사용자 이름이나 권한 등 사용자 식별에 필요한 상세 정보가 담겨져 있다
→ SecurityContextPersistenceFilter가 SecurityContext 인스턴스를 관리한다
→ SecurityContextPersistenceFilter는 SecurityContextRepository를 통해 SecurityContext를 인스턴스를 획득한다
→ 웹 애플리케이션에서는 HttpSessionSecurityContextRepository 구현체가 Http 세션에 담긴 정보를 SecurityContext에 로딩한다
→ 인증 전에는 비어 있는 SecurityContext가 SecurityContextHodler에 추가된다
정리하면 SecurityContextHolder에 SecurityContext가 포함되고, SecurityContext에 Authentication이 포함된다
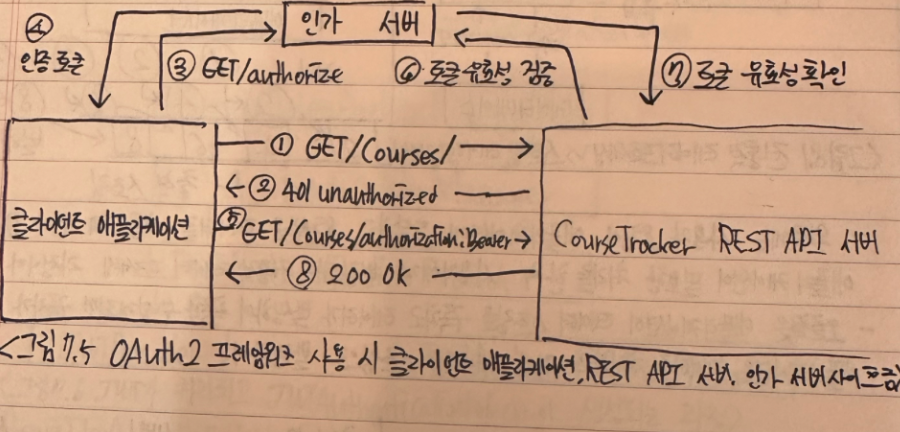
OAuth 2.0과 소설 로그인

- 구글 Oauth2.0 인증과정
- 사용자가 구글 게정으로 로그인 버튼을 클릭한다
- 애플리케이션은 사용자를 구글 로그인 페이지로 리다이렉트한다, URL에는 Client_Id 값이포함된다
- 구글 로그인 페이지에서 구글 계정 정보를 입력하고 로그인한다
- 구글은 CourseTracker 애플리케이션을 구글에 등록할 떄 입력한 스코프에 해당하는 정보가 무엇인지 사용자에게 보여주고, 애플리케이션이 해당 사용자 정보에 접근하려 한다는 사실을 사용자에게 알려주고 허가 요청을 받는다
- 사용자가 허가하면 구글은 애플리케이션에게 사용자 정보에 접근할 수 있는 권한을 부여한다
- 구글은 인가 코드를 사용자의 브라우저에 반환한다
- 브라우저는 인가 코드를 애플리케이션에 전달한다
- 애플리케이션은 전달받은 인가 코드를 구글에 보내고 구글은 인가 코드를 검증한다
- 검증 결과가 올바르면 구글은 접근 토큰(AccessToken)을 애플리케이션에게 발급한다
- 애플리케이션은 접근 토큰을 사용해서 사용자 정보를 조회할 수 있다
- 애플리케이션은 사용자를 인덱스 페이지로 리다이렉트 한다
Chapter 6. 스프링 시큐리티 응용
챕터 6은 전체적으로 보안과 관련해서 한 번쯤 체크해볼만한 부분들을 점검해주는 느낌이었다, 가장 이 책의 모토와 일치하는 느낌이었다, 처음 이 책을 선택한 이유부터 어떤 하나의 영역에 대해서 깊게 공부하는 느낌보다, 스프링 실무에서 내가 "모르는 거 조차 모르는 정보가 없는지", 즉 더 많은 배경지식을 쌓기 위한 목적이었고, 그 목적을 가장 만족하는 챕터였다, 중요 내용은 아래와 같다
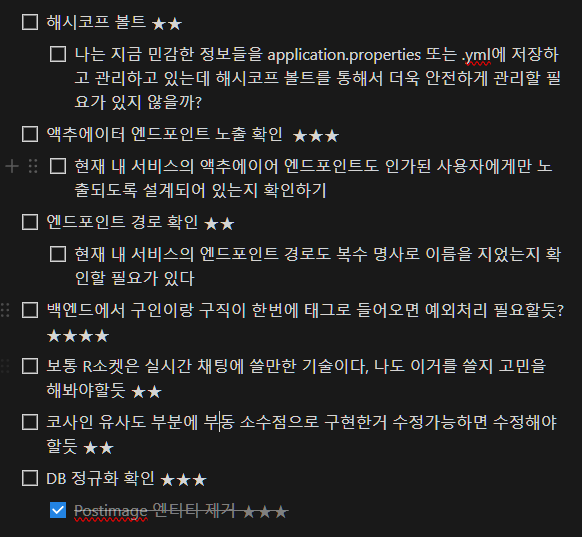
- 비밀정보 관리와 해시코프 볼트
- 로그인 시도 제한 및 보안 강화
- 리멤버 미 기능
비밀정보 관리와 해시코프 볼트
- 비밀정보관리
- 스프링 부트에서는 application.properties에 이런 비밀 정보를 기록해두기도 하는데 이 방식은 노출 위험이 크다, 스프링 클라우드 볼트를 사용해서 더 안전하게 관리할 수 있다
- 해시코프의 볼트를 통해 비밀 정보를 관리할 수 있다,
- 볼트는 사용 시 비밀 정보를 안전하고 편리하게 관리할 수 있다
- 해시코프 볼트
- 해시코프 볼트는 저장 공간, 클라우드 연동, 동적 비밀 정보 생성 등 다양한 기능 설정 가능
사용자 -- 애플리케이션 접근 --> 스프링부트 애플리케이션 -- 키스토어 비밀번호 요청 --> 볼트- 예제에서는 Vault, Operator, Init 명령으로 생성한 초기 루트 토큰을 생성하고 application.propoerties 파일에 저장했었다
- 실제 서비스 환경에서는 초기루트 토큰 값을 환경 변수나 다른 방법으로 공급받도록 구성해야한다
- 예제에서 사용한 HTTP 프로토콜도 실제 서비스에서는 HTTPS로 변경해야한다
로그인 시도 제한 및 보안 강화
- 리캡차 활성화
- 인터넷 봇들 때문에 많은 트래픽이 발생하면 자원이 쉽게 고갈됨, 때문에 서브시 불능 또는 엄청난 비용이 발생하는 문제가 발생할 수 있음, 그래서 리캡차를 이용하면 이런공격을 막을 수 있다
- 캡차(CAPTCHA)는 Completely Automated Public Turning Test To Tell Compters and Humans Apart의 약자로서 컴퓨터와 사람을 구분할 수 있는 컴퓨터 프로그램이나 애플리케이션을 의마한다
- 스팸을 유발하는 봇을 구분할 수 있어서 자원 낭비를 줄일 수 있는 기술이다
- 로그인 시도 횟수에 제한이 없을 경우에는 악의적인 공격자가 브루트 포스 공격으로 애플리케이션 접근 권한을 얻는 문제가 발생할 수 있다
- 브루트 포스 공격은 가능한 모든 조합을 무작위로 시도해 비밀번호를 찾아내는 방식이다.
- 시간이 오래 걸리지만 반드시 성공할 수 있다. 딕셔너리 어택은 미리 준비된 비밀번호 목록을 사용해 자주 사용되는 비밀번호를 빠르게 추측하는 방식이다.
- 간단한 비밀번호에 효과적이지만 복잡한 비밀번호에는 한계가 있다.
리멤버 미 기능
- 리멤버 미
- 신뢰할 수 있는 기기로부터 로그인하는 사용자를 기억해두면 사용자가 반복적으로 로그인할 필요가 없어진다, 스프링 시큐리티에 내장된 리멤버 미 기능을 사용하면된다
- 사용자 경험과 보안 사이에서 구현을 잡는 것은 중요하다
- 예시로 많은 애플리케이션에서 사용자의 연결 세션 사이에 사용자 정보를 공유해서 인증 정보 입력 빈도를 줄여주는 리멤버 미 기능을 제공한다
- 스프링 시큐리티도 로그인 이후 서버로 보내지는 모든 요청에 포함된 브라우저 쿠키를 사용해서 리멤버 미 기능을 지원한다, 세션 쿠키가 만료되면 스프링은 remeber-me 쿠키를 사용해서 인증한다
- 스프링 시큐리티는 두 가지 방식으로 리멤버 미 기능 구현을 지원한다
- 해시 기반 토큰 방식은 사용자 정보를 안전성이 높지 않은 브라우저 쿠키에 저장한다
- 퍼시스턴트 토큰 방식은 사용자 정보를 데이터베이스에 저장한다
Chapter 7. 스프링 부트 RESTful 웹 서비스 개발
챕터 7은 웹 개발을 해봤다면 한 번쯤은 들어보고 사용해봤을 RESTful에 대한 내용을 다룬다, 이 챕터에서는 현재 내가 기억하고 있는 정보들이 맞는지 다시 한번 검증해볼 수 있는 시간이었다, 중요 키워드는 아래와 같다.
- RESTful API 설계와 모범 사례
- API 예외처리와 전역 오류 핸들링
- API 보안과 OAuth2.0
RESTful API 설계와 모범 사례
RESTful API는 REST 아키텍처 스타일을 따르는 애플리케이션 프로그래밍 인터페이스다
- REST는 REpresentational State Transfer의 약자이며, 로이 필딩이 창안한 개념이다
- REST API 에서는 클라이언트가 서버에 이쓴 자원을 요청하면 서버는 요청된 자원의 상태를 규격에 맞게 표현한 정보를 클아이언트에게 반환한다
- 이 상태 정보는 JSON, 단순 문자열, HTML 등 여러가지 형식으로 전달할 수 있다
RESTful API의 모범 사례
- REST API에서 요청 본문을 JSON으로 받고, 응답 본문을 JSON으로 받는 것이 좋다
스프링부트 JSON과 자바 POJO 객체를 자동으로 매핑해주는 기능을 제공한다 - 엔드포인트 경로에는 명사를 빼는게 좋다 Courses, Persons, Vehicles, 같은 복수형 명사를 쓰면 더 좋다
- 만약 경로에 동사를 쓰면 경로가 길어지고 일관성을 유지하기 힘들어진다

- API 클라이언트가 Rest 엔드포인트를 호출하며 요청을 보내면 Rest 컨트롤러가 요청을 접수한다
- 컨트롤러는 서비스 계층을 사용해서 요청을 처리한다
- 서비스 계층은 리포지토리를 통해 데이터베이스와 통신한다
- 리포지토리가 DB로부터 받는 응답은 서비스 계층에 반환되어 처리되고, 컨트롤러로 전달된다
- 컨트롤러도 필요한 로직을 처리한 후 최종 응답을 생성해서 API 클라이언트에게 반환한다
API 예외처리와 전역 오류 핸들링
- @ControllerAdvice 애노테이션이 붙어 있는 클래스에 정의된 예외처리로직은 기본적으로 모든 컨트롤러에서 발생한 예외에 적용한다,
- 따라서 전역적으로 적용되는 예외처리로직을 구현할 때 편리하게 사용할 수 있다,
- @ControllerAdivce 애노테이션은 @Component 애노테이션의 특별한 타입이며, 스프링 빈으로서 등록된다
- ResponseEntityExceptionHandler 클래스는 @ControllerAdvice 애노테이션이 붙은 클래스가 상속받는 기본 클래스다,
- @RequestMapping이 붙어있는 모든 메서드에서 발생한 예외를 @ExceptionHandler가 붙어 있는 메서드에서 처리할 수 있도록 중앙화된 예외처리 기능을 제공한다
API 보안과 OAuth2.0
실제 운영하는 서비스에서 HTTP 기본 인증을 사용하면 안되는 이유
- HTTP 기본 인증에 사용되는 아이디와 비밀번호는 Base64로 인코딩된 일반 문자열을 사용한다
- Base64 인코딩은 암호화가 아니며, 인코딩된 값을 알면 쉽게 비밀번호를 알아낼 수 있다
- 그래서 HTTPS와 함께 사용되지 않는다면 비밀번호가 쉽게 유출될 수 있다
- 또한 HTTP 기본 인증을 사용하면 인증과 인가를 수행하기 위해 클라이언트 애플리케이션과 서버 애플리케이션 모두 비밀번호를 관리해야한다
- 두 곳에서 관리하면 비밀번호가 누출될 위험도 그만큼 높아진다
Chapter 8. 리액티브 스프링 부트 애플리케이션 개발
챕터 8은 리액티브 프로그래밍에 대해서 다루었으며, 애프릴케이션 개발에 있어서 필수적으로 필요한 부분들은 아니지만, 만약 개발하고자 하는 서비스에 적절한 기술일 경우에는 참고하면 좋은 것들이다, 주요 키워들은 아래와 같다.
- 리액티브 프로그래밍 개념과 장점
- 프로젝트 리액터와 스프링 웹 플럭스
- R소켓과 실시간 통신
리액티브 프로그래밍 개념과 장점
리액티브 프로그래밍은 비동기 데이터 스트림을 사용하는 프로그래밍 패러다임이다
- 데이터 스트림은 데이터가 일정 시간 간격 안에서 한 데이터 포인트씩 차례로 방출되는 데이터 스트림을 의미한다
- 비동기는 요청에 대한 응답이 올 때까지 스레드가 기다리지 않고 응답이 준비 됐을 때 스레드가 받아서 처리하는 방식을 의미한다
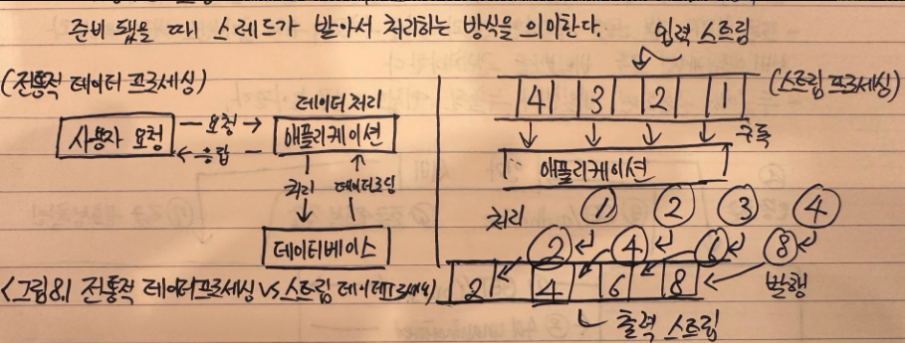
- 왼쪽에는 사용자 요청이 애플리케이션에 도달하고, 요청 받은 데이터를 애플리케이션이 DB에서 조회하고, 애플리케이션이 필요한 처리를 한 후 사용자에게 반환되는 전통적인 데이터 프로세싱 과정이다
- 오른쪽은 애플리케이션이 데이터 스트림을 구독하고 데이터가 발생하여 획득할 수 있게 될 경우 구독자가 데이터를 받는다, 애플리케이션은 데이터를 처리하고 결과 데이터를 스트림으로 발행한다
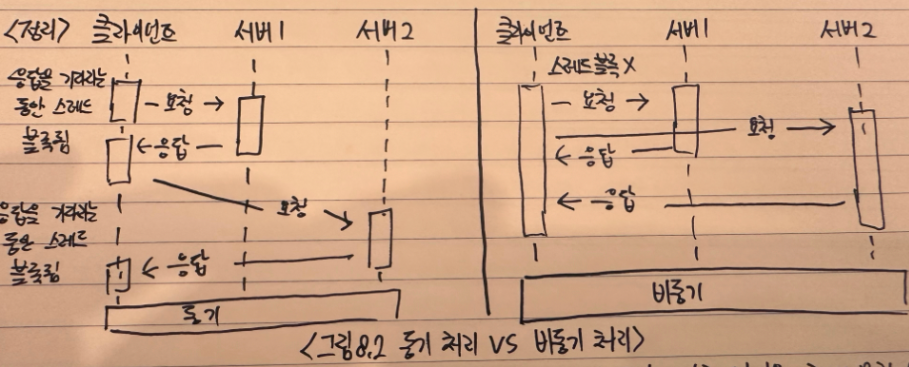
- 동기 방식에서는 호출하는 스레드가 서버로부터 응답을 기다리는 동안 다른 작업을 처리하지 못한다
- 비동기 방식에서는 호출하는 스레드가 서버로부터 응답을 기다리지 않고 호출 직후부터 다른 작업을 처리할 수 있으며 서버는 반환할 데이터가 준비되면 응답을 보낸다
프로젝트 리액터와 스프링 웹 플럭스
리액터는 JVM에서 사용되는 완전한 논 블로킹 리액티브 프로그래밍 모델이다
- 리액터는 스트림 지향 라이브러리 표준이자 명세인 리액티브 스트림에 바탕을 두고 있다
- 리액터를 사용하면 시퀀스에 있는 무한한 수의 요소를 처리할 수 있다
- 논 블로킹 백 프레셔를 사용해서 연산자 사이에 요소를 비동기적으로 전달할 수 있다
리액터와 관련된 4개의 주요 인터페이스
- 발행자
: 잠재적으로 무한한 수의 요소를 만들어 낼 수 있고 구독자가 요청하는 만큼만 발행한다, Publisher 인터페이스의 Sbuscribe() 메서드를 통해 구독자가 발행자를 구독할 수 있다 - 구독자
: 언제, 얼마 만큼의 요소를 처리할 수 있을지 결정하고 구독한다, 구독자는 onSubscribe() 메서드의 파라미터로 구독을 전달 받아서 구독에 데이터를 요청하고 반환받은 데이터를 OnNext()로 처리한다 - 구독
: 구독자와 발행자의 관계를 나타낸다, request()는 요청, Cancel()은 구독 취소이다 - 프로세서
: 프로세서는 처리 단계를 나타내며 발행자 인터페이스와 구독자 인터페이스를 상속 받는다
스프링 프래임워크 5.0에서 리액티브 웹 애플리케이션 개발을 지원하는 새로운 스프링 웹 플럭스가 도입 됐다, 웹 플럭스는 프로젝트 리액터 기반의 완전한 논 블로킹 라이브러리다,
- 스프링 웹 플럭스는 애노테이션 컨트롤러와 함수형 엔드포인트라는 두 가지 프로그래밍 모델을 가지고 있다
- 애노테이션 컨트롤러 모델은 스프링 MVC 프레임워크와 호환되며, 스프링 MVC의 애노테이션 사용도 가능하다
- 함수형 엔드포인트 모델은 람다식 기반의 가벼운 함수형 프로그래밍 모델을 제공한다, 함수형 엔드포인트는 HTTP 요청 처리와 라우팅에 사용할 수 있는 작은 라이브러리를 제공한다
- 리액티브 프로그래밍은 지연 방식으로 동작하기에 subscribe() 메서드를 호출하기 전 까지는 아무 일도 발생하지 않으므로 이 점을 잊지 말자
R소켓과 실시간 통신
R소켓은 TCP, 웹 소켓, 애런같은 프로토콜 위에서 멀티플렉싱, 듀플렉싱을 지원하는 애플리케이션 프로토콜이다, R 소켓은 4가지 통신 모델을 지원한다.

- 실행 후 망각
: 클라이언트가 메시지 한 개를 전송하고 서버로부터 응답을 기대하지 않는 방식이다 - 요청-응답
: 클라이언트가 한 개의 메시지를 전송하고 서버로부터 한 개의 메시지를 돌려받는다 - 요청-스트림
: 클라이언트가 한 개의 메시지를 전송하고 서버로부터 여러 메시지를 스트림으로 돌려받는다 - 채널
: 클라이언트와 서버가 서로 스트림을 주고 받는다
R소켓에서는 클라이언트와 서버 사이의 초기 핸드셰이크가 완료된 이후에도 클라이언트와 서버가 독립적으로 상호작용을 시작할 수 있으므로 클라이언트와 서버라는 구별이 사라진다.
R소켓 프로토콜에서 중요한 몇 가지 키워드와 장점이다
- 리액티브 스트림에서 강조하는 스트리밍과 백프레셔
: 요청-스트림 패턴과 채널 패턴에서 스트리밍 처리를 지원하고 네 가지 패턴 모두에서 백 프레셔를 사용할 수 있다 이를 통해 요청하는 쪽에서는 응답이 들어오는 속도를 조절할 수도 있고, 네트워크 계층 혼잡 제어나 네트워크 수준 버퍼링에 대한 의존도를 낮출 수 있다 - 요청 스로틀링(Throttling)
: LEASE프레임을 전송하면 특정 시점에 상대방 쪽에서 수용할 수 있는 요청의 총 개수를 제한할 수 있다 - 대용량 메시지의 분할 및 재조립
- 생존신호 메시지를 통한 keepalive 유지
끝으로
이번 내 책 후기 포스팅을 적으면서 계속해서 불만이 생겼다,
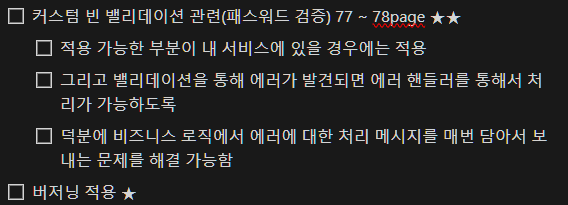
이런식으로 내가 어떤걸 점검해야하는지 알고 있음에도 불구하고, 이걸 해결한 과정을 포스팅에 담기에는 제대로 된 기록을 하지 않았다는 점과 현재 다른 작업을 하느라 이 문제를 해결하지 않았다는 점이다, 그래서 전체적인 내용이 책을 읽고 점검해야할 거 같은 부분들을 정리한걸 그대로 적은 느낌이라 상당히 아쉬운 느낌이다,
하지만 현재 읽고있는 JPA 서적의 경우 지금 당장 점검해야하는 부분이 많기에 이번 포스팅에서 아쉬웠던 점들을 아래 과정을 통하여 더 자세히 적어보고자 한다,
서적을 읽고 정리 → 현재 내 서비스를 점검 → 문제 확인 → 문제를 해결하는 과정에서 느낀 점 기록 → 포스팅에 활용
감사합니다.
