
오늘은 오랜만에 책 후기를 작성해보고자 한다, 토비의 스프링 Vol.1와 관련된 글을 포스팅한 지 한 달이 넘은 시점이지만, 사실 토비의 스프링 Vol.2는 3주전에 완독을 한 상태이고 현재는 실전 스프링 부트를 절반 넘게 읽고 정리를 한 상황이다,
늦은 이유
배경지식
각 챕터별로 후기를 적기전에 이번에도 토비의 스프링을 읽으면서 많은 점들을 느낄 수 있었고, 그 중에서 가장 감명 깊게 느낀점은 내가 왜 책을 읽는지에 대한 궁극적인 이유를 다시 한번 정립할 수 있었다, 책을 통하여 검색해서 나오지 않는 지식을 쌓을 수 있는 기회였고, 더 정확하게는 배경지식이 부족하여 어떤걸 검색해야 하는지 조차 모르는 상황을 방지할 수 있다라고 하는게 더 맞을 거 같다,
즉, 이전에 읽었던 Vol.1은 내가 알던 지식을 깊게 알 수 있는 기회였다면, Vol.2는 굳이 이런거 까지 알아야 돼? 라는 느낌이 들 정도로 스프링과 관련해서 많은 배경지식들을 얻을 수 있는 기회였다,
때문에 책을 읽으면서 고질적인 문제가 발생했는데, 어떤걸 내가 기억해야하고 어떤걸 적당히 기억해야할지 고민에 빠졌다, 왜냐하면 내 눈에는 중요해 보이는 부분들 많이 있었고, 조금 더 솔직하게 이야기 하자면 책을 읽으면서 최대한 많은 걸 얻고 싶었기에 놓치고 싶지 않았던 거 같다, 때문에 Vol.1에서 약 2.5만자를 필기 했었는데 Vol.2는 거기에 두배인 약 5만자 가량을 필기할 수 있었다.

그리고 어쩌다보니 노트 한 권을 꽉 채울 수 있었다.

페이지 외주?
그리고 책을 다 읽은 시기쯤에, 과거 편집을 했었던 곳에서 사이트를 만들어 달라는 연락이 왔었다,
근데 말 그대로 간단한 사이트라서 외주? 라고 부르기엔 그렇고 백엔드를 주로 공부하고 있는 나로써는 평소에는 잘 접하지 못하는, 웹 퍼블리싱 작업을 오랜만에 다시 한번 경험할 수 있었다, 덕분에 더 정형화된 느낌 그리고 규칙적으로 만들어 볼 수 있는 시간이었다.
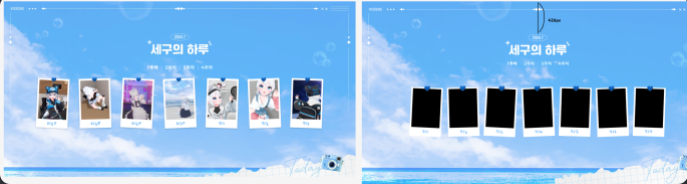
(대략 이런 느낌의 정적 사이트다)
그리고 한 번만 사용하고 끝날 정적 페이지였기에 별 다른 애정없이 작업을 했었고, 트래픽도 구글 애널리틱스로 적당히 몇명 들어왔는지만 확인하는 용도로 연결시켜 놓은 상태였다.
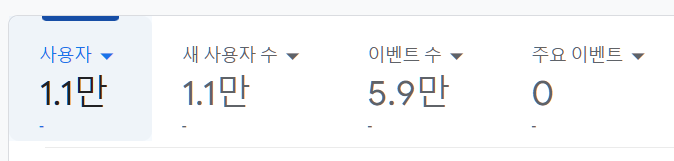
사이트 오픈날 생각보다 많은 분들이 방문 해주셔서 놀랐고 덕분에 보람찼던 거 같다
여튼 이런 이유 때문에 1~2주 정도 시간이 더 걸렸고 여름 휴가철이 겹치면서 조금은 쉬엄쉬엄 했던 거 같다.

후기
저번 후기에서 앞으로 후기 작성을 할 시 잡담없이 후기를 남긴다고 말했지만, 이번에도 잘 지키진 못했는 거 같다, 그러므로 이제 군말없이 후기를 작성해보도록 하겠다.
요약
우선, 토비의 스프링 Vol.2를 요약하자면
기술과 선택
이라는 단어로 정립할 수 있을 거 같다, 토비의 스프링 Vol.1의 소제목이 이해와 원리였는데 Vol.2의 소제목은 기술과 선택 이었다, 두 버전의 책을 완독하고 느끼는 거지만 정말 잘 지은 소제목이라고 생각한다, Vol.2에서 기존에 내가 알던 것들에 대해서 더 자세하게 알 수 있는 시간도 분명 있었지만, 그것보다는 스프링 프레임워크를 어떻게 해야지 잘 쓸 수 있는지를 더 초점을 맞추었던 느낌이다,
책안에 있었던 내용 중에 "스프링 MVC 프레임워크를 이미 완성된 고정적인 프레임워크로 보지 말고, 진행하려는 프로젝트의 특성에 맞게 빠르고 편리한 개발이 가능하도록 자신만의 웹 프레임워크를 만드는 데 쓸 수 있는 도구라고 생각할 필요가 있다" 라는 내용이 있다, 그리고 이를 이해하는 것이 스프링이 제공하는 가치를 누리면서 스프링을 잘 사용할 수 있는 비결이다,
그리고, 이러한 부분을 강조하면서 Vol.2를 읽으면서 내가 느꼈던 흐름은 대략 이러했다,
이러한 기술이 있다
→ 여기서 파생되거나 발전된 기술들은 이런게 있다
→ 그리고 이러한 기술들을 같이 사용할 수 있다
→ 근데 이때 여러가지 문제가 발생할 수 있으므로 참고해라
→ 그리고 이 문제를 해결하기 위해서는 이거를 써야한다
→ 즉, 기술을 선택하는 과정에서 발생하는 트레이드 오프를 알아서 판단하고 선택해라사실 챕터마다 포스팅을 나누어서 작성하고 싶지만, Velog에 남기는 거 보다는 올해안에 나만의 블로그를 만들 예정이다, 그래서 새로 만든 블로그에 더욱 자세하게 정리하고 싶기에 일단은
각 챕터별로 중점되는 내용들만 정리할 예정이다,
지금부터 알아보자.
Chapter 1. IoC 컨테이너와 DI
스프링만큼 유연하고 강력한 기능을 가진 IoC 컨테이너와 DI 기술을 제공하는 건 없을거다, 스프링의 DI설정 방식과 IoC 컨테이너의 활용 방법은 매우 다양하다, 1장에서는 이러한 스프링이 제공하는 DI 설정 메타데이터를 다루는 여러가지 방법을 살펴보고 상황에 맞게 어떤 설정 방식과 응용 기술을 선택할지를 알 수 있는 챕터였다
내가 생각했을 때 이 챕터에서 중요한 부분들은 아래와 같다.
- IoC 컨테이너와 DI
- 빈 설정 메타정보와 스코프
- IoC 컨테이너의 계층
IoC 컨테이너와 DI?
IoC(제어의 역전) 컨테이너는 오브젝트의 생성, 초기화, 소멸 등 생명 주기를 관리하는 역할을 한다, 이를 통해서 개발자는 객체 생성과 의존성 관리에 신경 쓸 필요가 없이 비즈니스 로직에 집중할 수 있다고 Vol.1에 이미 한번 언급한 적이 있다,
그리고 이번 Vol.2의 챕터 1에서는 여기서 더 연장하여 애플리케이션 컨텍스트가 무엇이고 POJO 클래스의 역할은 어떤건지 더 자세하게 알 수 있었다, 애플리케이션 컨텍스트는 빈 팩토리보다 확장된 형태로, 빈 팩토리에 엔터프라이즈 개발을 위한 다양한 기능을 추가한 버전이라고 생각하면 이해하기 쉽다, 그래서 빈 팩토리와 애플리케이션 컨텍스트는 같은 의미로 언급될 수 있다,
그리고 POJO(Plain Old Java Object) 클래스는 스프링의 핵심 개념 중 하나로, 독립적이고 결합도가 낮은 클래스이다, POJO 클래스는 인터페이스를 통하여 구현체와 연동될 수 있으며, DI를 통해 유연하게 오브젝트를 주입받아 사용할 수 있다.
빈 설정 메타정보와 스코프
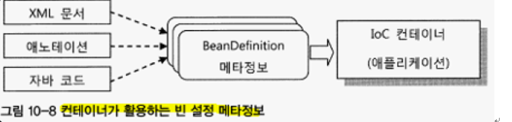
IoC 컨테이너가 빈을 생성하고 동작하기 위해서는 빈 설정 메타정보가 필요하다, 빈 설정 메타정보는 BeanDefinition 인터페이스로 표현되며, 빈의 아이디, 클래스, 스코프, 생성자 파라미터 값, 초기화 및 소멸 메소드 등의 정보를 포함하고 있다,
그럼 빈의 생명 주기를 정의하기 위해선 어떻게 해야할까?
빈의 생명 주기를 정의하는 개념은 빈의 스코프이다, 대표적으로는 싱글톤과 프로토타입 스코프가 있는데, 싱글톤의 경우 우리에게 친숙한 스코프이지만 프로토타입 스코프의 경우 어떻게 동작하는지 다소 거리감이 있다, 그리고 Vol.2에서는 이런 프로토타입에 대해서 자세히 알아본다,
IoC의 기본 개념은 핵심 오브젝트를 코드가 아닌 컨테이너가 관리하는 것이다, 하지만 프로토타입 빈은 이러한 IoC의 기본 원칙을 따르지 않는다, 컨테이너가 일단 빈을 제공하고 나면 더 이상 빈을 관리하지 않으며, 오브젝트를 가져간 코드나 DI로 주입 받은 다른 빈이 오브젝트를 관리하게 된다, 예를 들어서 프로토타입 빈을 주입 받은 빈이 싱글톤이라면, 프로토타입 빈의 생명주기는 싱글톤의 생명주기를 따라서 컨테이너가 종료될 때까지 유지된다, 이는 주입 받은 빈이 프로토타입보다 생명주기가 짧아도 동일하게 적용된다.
IoC 컨테이너의 계층 구조
IoC 컨테이너는 트리 모양의 계층 구조를 가질 수 있다, 자식 컨텍스트에서 빈을 찾지 못하면 부모 컨텍스트를 탐색하여 빈을 찾는다, 즉, 애플리케이션 안에서 성격이 다른 설정을 분리해서 두 개 이상의 컨텍스트로 구성하면서, 각 컨텍스트가 공유하고 싶은게 있을 경우에는 계층 구조를 활용할 수 있다, 하지만 이러한 계층구조를 사용하는건 많은 주의가 필요하다, 예상치 못한 방식으로 동작할 수 있기 때문이다.
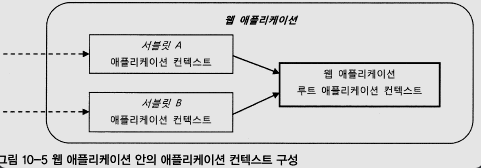
그리고 웹 애플리케이션의 컨텍스트 구성 방법은 크게 세 가지로 나뉜다, 컨텍스트 계층 구조를 만드는 방법과 컨텍스트 계층 구조를 만들지 않고 하나만 사용하는 방법이다, 이 중에서 컨텍스트 계층 구조를 만드는 방법은 가장 많이 사용하는 방법으로 보통 개발을 하면 웹 애플리케이션에서는 Servlet 컨텍스트와 Spring 컨텍스트로 나누어서 관리하게 된다, DispatcherServlet을 통해 HTTP 요청마다 적절한 빈을 찾아 실행하며 이를 통하여 스프링은 다양한 웹 환경에서도 유연하고 확장 가능한 애플리케이션을 개발할 수 있다.
Chapter 2. 데이터 액세스
2장에서는 스프링 데이터 액세스 기술에 관한 기본 개념을 다시 정리한다, 스프링이 지원하는 핵심 데이터 액세스 기술의 구체적인 사용 방법과 선택할 수 있는 옵션을 확인했다, 아래는 해당 챕터의 주요한 내용들이다
- DAO와 스프링 데이터 액세스 기술
- JDBC와 스프링의 접근 방법
- 트랜잭션 관리와 스프링의 트랜잭션 서비스
DAO와 스프링 데이터 액세스 기술
DAO의 가장 중요한 장점은 DAO를 이용하는 서비스 계층의 코드를 기술이나 환경에 종속되지 않는 순수한 POJO로 개발할 수 있다는 점이다, 또한 습관적으로 DAO 클래스의 모든 메서드를 Public으로 추가 해서는 안된다, 서비스 영역에 제공하는 메소드만 Public으로 지정한다, 그리고 특정 액세스 기술에서만 의미있는 형태로 DAO 메소드 이름을 지어서는 안된다,
데이터 액세스 중에 발생하는 예외는 대부분 복구할 수 없다, 따라서 런타임 에러를 통해서 문제를 해결해야 한다, 그러나 때때로 의미있는 DAO가 던지는 예외를 잡아서 비즈니스 로직에 적용하는 경우도 있다, 중복키 예외나 낙관적인 락킹이 대표적인 예시이다.
스프링의 DI의 응용 패턴인 템플릿/콜백 패턴을 이용하여 반복적인 데이터 액세스 작업을 단순화하고 예외 변환과 트랜잭션 동기화 기능을 사용할 수 있다, 템플릿은 미리 정의된 작업 흐름을 제공하여 필요한 내용만 담을 수 있게 해야한다, 그러나 데이터 액세스 기술의 API 대신 템플릿이 제공하는 API를 사용해야 한다는 단점이 있다, 그래서 스프링은 일부 데이터 액세스 기술을 템플릿 대신 해당 기술의 API로 사용하게 해주기도 한다,
지금까지 책에서 사용한 단순한 DataSource는 운영환경에서는 절대 사용해서는 안된다, 설정파일(개발, 테스트, 운영)을 따로 만들어서 적용하는게 좋다, 스프링에서 주요 DataSource로는 SimpleDriverDataSource와 SingleConnectionDataSource가 있다,
SimpleDriverDataSource는 가장 단순한 DataSource 구현 클래스로, getConnection() 호출 시, 매번 DB 커넥션을 새로 만들고 따로 풀을 관리하지 않아서, 실전에서는 절대 사용하지 않아야 하며, 오직 테스트에서만 사용해야한다, SingleConnectionDataSource는 하나의 물리적인 DB 커넥션만 만들어두고 이를 계속 사용하는 DataSource이다 통합 테스트에서는 사용 가능하지만, 동시에 두 개 이상의 스레드가 동작하는 경우에는 하나의 커넥션을 공유하게 되므로 위험하다.
JDBC와 스프링의 접근 방법
JDBC는 자바의 데이터 액세스 기술의 기본이 되는 로우레벨 API이다, JDBC는 표준 인터페이스를 제공하고, DB 벤더와 개발팀에서 인터페이스를 구현한 드라이버를 제공하는 방식으로 사용한다, 덕분에 SQL 호환성만 유지한다면 JDBC로 개발한 코드는 DB가 변경 되어도 그대로 재사용이 가능하다, 아래는 DB가 해주는 작업들이다
- Connection 열기와 닫기
: 필요한 시점에 알아서 진행한다 - Statement 준비와 닫기
: 대부분 JDBC가 해결, 단 파라미터 바인딩에 사용할 정보가 담긴 맵이나 오브젝트를 미리 준비하는건 개발자 책임 - Statement 실행
: 실행 결과를 다양한 형태로 가져올 수 있다 - ResultSet 루프
: ResultSet의 루프를 만들어 반복 해결 - 예외처리와 변환
: JDBC 작업 중 발생하는 모든 예외는 스프링 JDBC의 예외 변환기가 처리 - 트랜잭션 처리
: 스프링 JDBC는 트랜잭션 동기화 기법을 이용해 선언적 트랜잭션과 맞물려서 돌아감
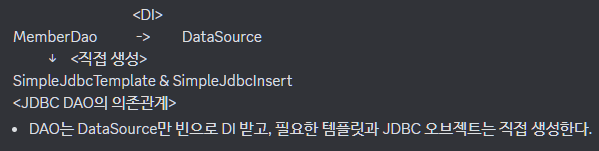
가장 권장되는 DAO 작성 방법은 DAO는 DataSource에만 의존하게 만들고 스프링 JDBC 오브젝트는 코드를 이용해 직접 생성하거나 초기화해서 DAO의 인스턴스 변수에 저장해두고 사용하는 것이다.
별개로 책을 읽다가 생긴 의문점인데, JPA의 구현체가 필요한 이유가 뭘까?
JPA는 데이터베이스와 상호작용하기 위한 표준 인터페이스이다, 그래서 인터페이스만으로는 아무런 일도 하지 않기 때문에 실제로 데이터베이스와의 상호작용하는 코드를 구현한 구현체가 필요하다, 그리고 덕분에 여러 DB를 지원할 수 있어서 특정 벤더에 종속되지 않는다, 끝으로 성능 최적화 같은 추가 기능을 제공하여 더 나은 성능을 낼 수 있다.
또한 ORM과 관련한 내용이 나온김에, 하이버네이트는 가장 크게 성공한 오픈소스 ORM 프레임워크이다, 스프링과 거의 동시대에 등장해서 복잡한 엔티티빈 대신 평범한 POJO로 SQL을 직접 사용하는 전용적인 방식에 못지않게 강력하고 빠르면서도 편리한 ORM 방식의 개발이 가능함을 보여준게 하이버네이트이다, 하이버네이트는 그 자체로 독립적인 API와 기능을 가진 ORM 제품이면서 동시에 JPA의 핵심구현제품이기도 하다
트랜잭션 관리와 스프링의 트랜잭션 서비스
하이버네이트는 핵심 엔진 역할을 하는 SessionFactory가 있고, 스프링에서는 두 가지 팩토리 빈을 제공한다<JPA 엔티티 매니저 팩토리와 유사하다>
세션 팩토리를 통해 하이버네이트 DAO를 만들 때 스프링의 트랜잭션 경계설정 기능을 적용하려면 스프링이 제공하는 트랜잭션 매니저를 이용해야한다, 이때 하이버네이트에 적용할 수 있는 트랜잭션 매니저로는 두 가지가 있다
- HibernateTransactionManger
: 단일 DB를 사용하고 JTA를 이용할 필요가 없다면 간단하게 HibernateTransactionManger 빈을 추가해주면 된다, 하이버네이트 DAO와 JDBC DAO를 같은 트랜잭션에서 묶어서 동작이 가능하다 - JtaTransactionManger
: 여러 개의 DB에 대한 작업을 하나의 트랜잭션으로 묶으려면 JTA를 통해서 서버가 제공하는 글로벌 트랜잭션 기능을 이용해야한다, 하이버네이트로 당연히 JTA 트랜잭션을 이용할 수 있다.
그러면 JDBC, JPA, 하이버네이트 같은 기술들은 기본적으로 Template를 제공하고 이를 통하여 예외변환 기능 같은 여러 기능을 제공하는데 나는 왜 실제로 이걸 쓸 일이 없는걸까, 서비스 추상화 때문인가?
- 직접 템플릿을 사용할 필요가 없는 이유는 서비스 추상화, 프레임워크의 편의 기능, 팀의 개발 표준, 그리고 프로젝트의 특성 등 여러 가지 요인에 의해 결정된다, 이러한 이유로 인해 템플릿의 직접 사용보다는 더 고수준의 추상화된 방식으로 데이터 접근을 구현하게 되는 경우가 많다.
EJB가 제공했던 엔터프라이즈 서비스에서 가장 매력적인 것은 바로 선언적 트랜잭션이다.
- 코드 내에서 직접 트랜잭션을 관리하고 트랜잭션 정보를 파라미터로 넘겨서 사용안 해도 된다.
- 트랜잭션 스크립트 방식의 코드 탈피
- 트랜잭션 스크립트란 하나의 트랜잭션 안에서 동작 코드를 한 군데에 모은 방법이다, 즉 작업 단위별로 스크립트(또는 메소드)로 작성하는건데, 간단한 애플리케이션이거나 비즈니스 로직이 비교적 단순한 경우에 사용할 수 있다
- 트랜잭션 스크립트는 자주 사용되는 DB 액세스 로직이 존재해서 중복이 자주 발생한다
- 하지만 선언적 트랜잭션이 경계설정이 이 문제를 모두 해결가능하다
- 시작되고 종료되는 지점은 별도의 설정을 통하여 결정된다, 작은 단위로 분리되어 있는 데이터 액세스 로직과, 비즈니스 로직 컴포넌트와 메소드를 조합하여 하나의 트랜잭션에서 동작도 간단하다.
- 이 모든건, 선언적 트랜잭션에서 제공하는 트랜잭션 전파 떄문이다.
- A-B 구성의 경우 A에서 B 코드를 호출하게 하고 각각의 트랜잭션 전파 속성도 트랜잭션 필요(REQUIRE)로 해주면 된다, 이렇게하면 A에서 시작된 트랜잭션이 B의 코드가 자동으로 참여하게 된다.
- EJB의 이런 선언적 트랜잭션 기능을 복잡한 환경이나 구현조건없이 평범한 POJO로 만든 코드에 적용하게 해주는 것이 "스프링"이다 그래서 스프링의 선언적 트랜잭션은 매우 매력적인 기술이다.
- JavaEE에서 동작하는 엔티티 빈, JPA로 만든 컴포넌트에 JTA를 이용한 글로벌 트랜잭션을 적용해야하지만 가능했던 고급 기능을 간단한 톰캣 서버에서 동작하는 가벼운 애플리케이션에서도 적용해주기 때문에, 그 만큼 엔터프라이즈 계열에 효과적인 기능이다.
트랜잭션 격리수준은 동시에 여러 트랜잭션이 진행될 때에 트랜잭션의 작업 결과를 여타 트랜잭션에게 어떻게 노출할 것인지를 결정하는 기준이다, 스프링은 다음 다섯 가지 격리수준 속성을 지원하고 있다
Default
: 사용하는 데이터 액세스 기술 또는 DB 드라이버의 디폴트 설정을 따른다, 보통 드라이버의 격리수준은 DB의 격리수준을 따르는게 일반적이며, 대부분의 DB는 Read_commited가 기본 격리수준이다Read_UnCommited
: 가장 낮은 격리수준이다 하나의 트랜잭션이 커밋되기 전에 그 변화가 다른 트랜잭션에 그대로 노출되는 문제가 있다, 하지만 가장 빠르다 ,데이터의 일관성이 떨어지더라도 성능 극대화를 위해서 사용된다Read_Commited
: 실제로 가장 많이 사용하는 격리수준이다, 스프링에서 Default로 설정해두면 DB 격리수준을 따라서 Read_Commited가 적용되는게 일반적이며, 명시적이 설정이 필요없다, Read_UnCommited와 달리 다른 트랜잭션이 커밋하지 않은 정보를 읽을 수 없다, 대신 하나의 트랜잭션이 읽는 로우를 다른 트랜잭션이 수정할 수 있다, 때문에 처음 트랜잭션이 같은 로우를 다시 읽을 경우 다른 내용이 발견될 수 있다Repetable_Read
: 하나의 트랜잭션이 읽은 로우를 다른 트랜잭션이 수정하는걸 막아준다, 새로운 로우를 추가하는 것은 제한하지 않는다, 때문에 Select로 조건에 맞는 로우를 가져오는 경우 트랜잭션이 끝나기 전에 추가된 로우가 있을 수 있다Serializable
: 가장 강력한 트랜잭션 격리수준이다, 이름 그대로 트랜잭션을 순차적으로 진행시켜준다, 때문에 여러 트랜잭션이 동시에 같은 테이블의 정보를 접근하지 못한다, 가장 안전한 격리수준이지만, 가장 성능이 떨어지기 때문에 극단적으로 안전한 작업에만 사용하는걸 권한다.
Chapter 3. 스프링 웹 기술과 스프링 MVC
3장에서는 먼저 스프링의 웹 계층과 설계 기술의 선정에 관한 기본 원칙을 알아보고 스프링 웹 기술의 다양한 전략을 살펴본다, 아래는 3장에서 주요한 내용을 담은 키워드들이다
- 스프링 웹 기술과 MVC
- DispatcherServlet과 컨트롤러
- 뷰, 뷰 리졸버, 핸들러 예외 리졸버
스프링 웹 기술과 MVC
엔터프라이즈 애플리케이션의 가장 앞단에서 사용자 또는 클라이언트 시스템과 연동하는 책임을 맡고 있는 것이 바로 웹프레젠테이션 계층이다, 자바의 데이터 액세스 기술도 종류가 많고 다양하지만 웹 기술의 다양성에는 비할 수가 없다, 자바의 웹 기술은, 각 기술이 배타적으로 사용되지 않고 여러가지 방식으로 조합될 수 있어서 최종적인 선택의 폭은 정말 넓다, 나쁘게 말하면 선택의 고민과 부담이 커진다,
그래서 스프링은 기본적으로 기술의 변화가 잦은 웹 계층과 여타 다른 계층이 깔끔하게 분리되어 개발하는 아키텍처 모델을 지지한다, 덕분에 스프링 애플리케이션 웹 계층은 어떤 기술로 대체하더라도 아무런 문제가 없어야하며, 스프링 자신도 최고의 웹 기술과 프레임워크를 제공한다.
스프링이 직접 제공하는 서블릿 기반의 MVC 프레임워크로, 스프링 서블릿 또는 MVC 라고 부른다, 프론트 컨트롤러 역할을 하는 DispathcerServlet을 핵심 엔진으로 사용한다, 다양한 종류의 컨트롤러를 동시에 사용할 수 있게 설계되어있다, 스프링답게 MVC 프레임워크의 많은 기능을 자유롭게 확장할 수 있다, 제공해주는 공통 서비스와 전략들을 기반으로 새로운 종류의 MVC 프레임워크로 만드는게 쉽다, 애노테이션 설정과 유연한 핸들러 메소드를 지원하는 스프링 @MVC가 가장 대표적인 서블릿 기반 기술이다.
아래는 스프링 서블릿 기반 웹 프레임워크들을 간략히 정리한 거다.
- Spring Web Flow
: 상태 유지 스타일이 웹 애플리케이션을 작성해주는 프레임워크다 - Spring JavaScript
: 스프링 서블릿과 스프링 웹 플로우에 연동해서 손쉽게 Ajax 기능을 만들 수 있음 - Spring faces
: 스프링 MVC와 스프링 SFW의 뷰로 JSF를 손쉽게 사용할 수 있게 해준다 - Spring Web Service
: 스프링 MVC 와 유사한 방식으로 SOAP 기반의 웹 서비스 개발을 가능하다- SOAP(Simple Object Access Protocol)
: HTTP, HTTPS, SMTP 등을 통해 XML 기반의 메시지를 컴퓨너 네트워크 상에서 교환하는 프로토콜이다, REST는 프로토콜이 아닌 것과 차이점이 있다 - 프로토콜(Protocol)
: 컴퓨터 사이에서 데이터의 교환 방식을 정의하는 규칙 체계이다
- SOAP(Simple Object Access Protocol)
- Spring BlazeDS Integration
: 어도비 플렉스의 BlazeDS와 스프링을 통합해서 빠르고 쉽게 플렉스를 지원하는 스프링 애플리케이션을 개발할 수 있도록 하는 연동 프레임워크다
프레임워크 기술은 두 가지 방향으로 발전하고 있다,
하나는 스프링과 같이 유연성과 확장성에 중점을 두고 어떤 종류의 시스템 개발 또는 환경, 요구조건에도 잘 들어맞도록 재구성할 수 있는 범용적 프레임워크다, 각 계층과 기술 사이의 독립성을 중요하게 생각한다, 따라서 각 계층과 기술이 서로의 내부를 잘 알고 강하게 결합되는걸 극도로 꺼려한다, 즉 환경에 종속적인 로우레벨의 기술과 상위 레벨의 코드는 서비스 추상화 같은 방식을 통해서 최대한 느슨하게 의존성을 연결해주어야 한다, 유연한 아키텍처로 장기적으로 많은 인원이 큰 규모의 시스템을 개발할 때 적절하다,
두 번째는 루비 기반의 ROR(Ruby On Rails)을 필두로 하는 일체형 고속개발 프레임워크다, 기술에 대한 자기주장이 강하고 기술 선호도가 분명하다, 제한적인 기술을 쓰도록 강제한다, 대신 특정 기술의 장점을 극대화 해주며 계층구조가 단순해서 빠른 개발이 가능하다.
그래서 스프링을 잘 사용하는 비결을 유연함과 확장성을 최대한 활용해서 두 번째 스타일을 적용해야한다. "항상 프레임워크 기반의 접근 방법을 사용해야한다", 완성된 고정적인 프레임워크로 보지 말고 스프링이 제공하는 확장성과 유연성을 이용해서 각 프로젝트에 맞는 최적화된 구조를 만들어내고 관례에 따라 빠른 개발이 가능한 스프링 기반의 프레임워크를 "만들어서 사용해야한다는 애기다", 그래서 이런 원리를 스프링 웹 기술에도 동일하게 적용 가능하다,
스프링 MVC 프레임워크를 고정적인 완성된 프레임워크로 보지말고 프로젝트 특성에 맞게 빠르고 편리한 개발이 가능한 자신만의 웹 프레임워크를 만들 수 있는 도구라고 생각하고 사용할 필요가 있다.
스프링 웹 기술의 기반이자 핵심은 DispatcherServlet 이다, DispatcherServlet는 웹 기술을 구성하는 다양한 전략을 DI로 구성해서 확장하도록 만들어진 스프링 서블릿/MVC의 엔진과 같은 역할을 한다.
DispatcherServlet과 컨트롤러
아래는 DispatcherServelt이 프론트 컨트롤러로 MVC 컴포넌트들과 동작하는 기본 구조이다.
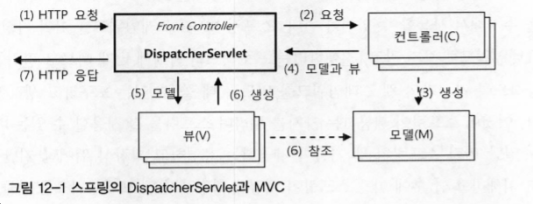
(1) DispatcherServelt의 HTTP 요청
HTTP 프로토콜을 통해서 요청이 들어옴
→ 요청이 스프링의 DispatcherServelt에 할당됨
→ 자바 서버의 서블릿 컨테이너는 HTTP 요청 정보를 DS에 전달함
→ 이때 DS는 모든 요청에 대한 공통적인 전처리 작업이 있을 경우 이를 수행함 (보안, 파라미터 조작, 한글 디코딩 등)(2) DispatcherServlet에서 컨트롤러로 HTTP 요청 위임
DS는 URL이나 파라미터 정보, HTTP 명령 등을 참고해서 컨트롤러에게 작업을 위임
→ 이때 핸들러 매핑 전략과 어댑터를 이용해서 DS는 일정한 방식으로 컨트롤러를 호출하고 결과를 받음(3) 컨트롤러의 모델 생성과 정보 등록
MVC 패턴의 장점은 정보를 담고있는 모델과 정보를 어떻게 뿌릴지 알고 있는 뷰와 분리가 된다는 점이다
컨트롤러의 작업은 먼저 사용자 요청을 해석하는 것이다
→ 그에 따라 실제 비즈니스 로직을 수행하도록 서비스 계층 오브젝트에게 작업을 위임한다
→ 결과를 받아서 모델을 생성한다
→ 어떤 뷰를 사용할지 결정을 한다
즉, 모델을 생성하고 모델에 정보를 넣어주는게 컨트롤러가 해야 할 마지막이며, 중요한 두가지 작업 중 하나이다, 컨트롤러가 어떤식으로든 DS에 돌려줘야 하는 두 가지 정보는 모델과 뷰이다
모델은 보통 맵이 담긴 정보라고 생각하면 된다.(4) 컨트롤러의 결과 리턴 : 모델과 뷰
모델이 준비되면 뷰를 결정해야한다, 뷰도 하나의 오브젝트이며, 컨트롤러가 직접 뷰 오브젝트를 리턴할 수도 있지만, 보통은 뷰 리졸버를 이용해서 뷰 오브젝트를 생성한다, 대표적인 뷰로는 JSP/JSTL 뷰가 있다(5) DispathcerServlet의 뷰 호출과 (6) 모델 참조
DS가 컨트롤러로부터 모델과 뷰를 받은 이후에 작업은 뷰 오브젝트에게 모델을 전달해주고 클라이언트에게 돌려줄 최종 결과물을 생성해 달라고 요청하는 것이다
모델의 내용을 참고해서 뷰가 작업한 최종 결과는 위와 같다, 동적으로 생성되는걸 모델을 참조해서 만들어낸다,<div> 이름 : ${name} </div> -> <div> 이름 : Spring </div>
기술적으로 보자면 뷰 작업을 통한 최종 결과물은 HTTPServletResponse 오브젝트 안에 담긴다(7) HTTP 응답 돌려주기
뷰생성까지 모든 작업을 완료
→ DS에 등록된 후처리기가 있으면 후속 작업을 진행한다
→ 뷰가 만들어준 HttpServletResponse에 담긴 최종결과를 서블릿 컨테이너에 돌려준다
→ 서블릿 컨테이너는 HttpServletResponse에 담긴 정보를 HTTP 응답으로 만들어준다
→ 그거를 사용자의 브라우저나 클라이언트에게 전송하고 작업을 종료한다.
뷰, 뷰 리졸버, 핸들러 예외 리졸버
뷰 리졸버는 핸들러 매핑이 URL로부터 컨트롤러를 찾아주는 것처럼 뷰 이름으로부터 사용할 뷰 오브젝트를 찾아준다, 뷰 리졸버는 ViewResolver 인터페이스를 구현해서 만들어진다, 뷰 리졸버를 빈으로 등록하지 않을 경우, DispatcherServlet의 디폴트 뷰 리졸버인 InternalResourceViewResolver를 사용한다, 핸들러 매핑과 마찬가지로 뷰 리졸버로 하나 이상을 빈으로 등록해서 사용할 수 있다, 이때는 Order 프로퍼티를 이용해서 뷰 리졸버의 적용 순서를 지정해주는게 좋다
InternalResourceViewResolver는 뷰 리졸버를 지정하지 않은 경우에 자동등록되는 디폴트 뷰 리졸버다, 주로 JSP를 뷰로 사용하고자 할 때 쓰이는데, 디폴트로 등록된 기본 상태 그대로 사용하는 일은 피해야한다, 디폴트 상태일 경우 /WEB-INF/View/Hello.jsp를 뷰로 이용할 경우 전체 경로를 다 적어야한다, prefix(접두사)와 suffix(접미사) 프로퍼티를 이용해서 앞뒤에 붙는 내용을 생략해서 해결가능하다
HandlerExceptionReoslver는 컨트롤러의 작업 중에 발생하는 예외를 어떻게 처리할지 결정하는 전략이다
스프링은 총 네 가지의 HandlerExceptionResolver 구현 전략을 가지고 있다
- AnnotationMethodHandlerExceptionResolver (디폴트)
- ResponseStatusExceptionResolver
- DefaultHandlerExceptionResolver
- SimpleMappingExceptionResolver
자세한 동작 흐름은 내용이 길어지는 관게로 생략한다, 일단 이런게 있다는 사실만 알아두고 나중에 필요할 때 추가로 학습하더라도 큰 문제는 없어보인다.
Chapter 4. 스프링 @MVC
@MVC는 스프링 3.0에서 기존에 가장 많이 사용되던 Controller 타입의 기반 클래스들을 대부분 대체하게 되었다, 따라서 최신 스프링 웹 기술의 핵심은 @MVC 라고 볼 수 있다, 그리고 4장에서는 이러한 @MVC의 상세한 기능과 활용 전략을 살펴볼 예정이다, 아래는 핵심들이다
- @MVC의 주요 특징과 장점
- 컨트롤러 메소드 파라미터 및 모델 바인딩
- 스프링 3.1의 새로운 @MVC
@MVC의 주요 특징과 장점
MVC의 가장 큰 특징은 핸들러 매핑과 핸들러 어댑터의 대상이 오브젝트가 아닌 메소드라는 점이다
- @MVC가 등장하기 전의 컨트롤러는 타입을 비교해서 컨트롤러를 선택하고 타입에 정의된 메소드를 통해 실행하였다
- 하지만 @MVC는 기존에 컨트롤러 인터페이스와 같은 타입을 이용해서 하던 일을 애노테이션으로 대체해버렸다
- 애노테이션은 대상의 타입이나 코드에는 영향을 주지 않는 메타정보이기에 훨씬 유연한 방법으로 컨트롤러를 구성한다
- @MVC의 핸들러 매핑을 위해서는 DefaultAnnotationHandlerMapping이 필요하며, 디폴트 전략이기 떄문에 다른 핸들러 매핑 빈을 등록했을 경우에는 DefaultAnnotationHandlerMapping도 무조건 함께 빈으로 등록해주어야 한다
- DefaultAnnotationHandlerMapping의 핵심은 매핑정보로 @RequestMapping 애노테이션을 활용한다는 점이다,
- 그런데 @RequestMapping은 타입 레벨 뿐만이 아니라 메소드 레벨에도 붙일 수 있다
만약 @ReuqestMapping이 적용된 클래스를 상속해서 컨트롤러로 사용하는 경우 슈퍼클래스의 매핑정보는 어떻게 될까?
@ReqeustMapping정보는 상속된다, 단 서브클래스에서 @RequestMapping을 재정의하면 슈퍼클래스의 정보는 무시된다- 클래스나 메소드의 상속과는 성격이 다르지만, @RequestMapping의 경우는 서브클래스에서 재정의하지 않는한 상속을 통해서 유지된다
- 하지만 @RequestMapping을 남발해서 적용하면 이해하고 관리하기 매우 힘든 코드를 만들 수 있다
그러므로, 반드시 강력한 표준 정책을 만드는 것을 권장한다
자바 5 이상의 타입 파라미터를 이용한 제네릭스를 활용해서 상위 타입에는 타입 파라미터와 메소드 레벨의 공통 매핑정보를 지정해놓고 이를 상속해서 받는 개별 컨트롤러에는 구체적인 타입과 클래스 레벨의 기준 매핑정보를 지정해주는 기법을 사용할 수 있다.
컨트롤러 메소드 파라미터 및 모델 바인딩
주요 애노테이션은 아래와 같다,
@PathVariable
: @RequestMapping의 URL에 {}로 들어가는 패스 변수를 받는다, 요청 파라미터를 URL의 쿼리 스트링으로 보내는 대신 URL 패스로 풀어서 쓰는 방식을 쓰는 경우 매우 유용하다@RequestParam
: 단일 Http 요청 파라미터를 메소드 파라미터에 넣어주는 애노테이션이다
하나 이상의 파라미터에 적용할 수 있으며, 스프링의 내장 변환기가 다룰 시 있는 모든 타입을 지원한다
@RequestParam을 사용했다면 해당 파라미터가 반드시 있어야 하며 없다면 400에러가 발생한다, 만약 파라미터가 필수가 아닌 선택적으로 제공된다면 required 엘리먼트를 false로 설정해주면 된다@ReuqestBody
: 이 애노테이션이 붙은 파라미터에는 Http 요청의 본문 부분이 그대로 전달된다, 일반적인 GET/POST의 요청 파라미터라면 @RequestBody를 사용할 일이 없을 것이다, 반면 XML이나 JSON 기반의 메시지를 사용하는 요청의 경우에는 이 방법이 매우 유용하다@Valid
: JSR-303의 빈 검증기를 이용해서 모델 오브젝트를 검증하도록 지시하는 지시자다
모델 오브젝트의 검증 방법을 지정하는데 사용하는 애노테이션이다
스프링에서 바인딩이라고 말할 때는 오브젝트의 프로퍼티에 값을 넣는거를 의미한다, 스프링에서는 크게 두 가지 바인딩을 지원한다,
- 첫 번째는 XML 설정파일을 사용해서 빈을 정의하면서
<Property>태그로 값을 주입하도록 설정하는 것이다, - 두 번째는 Http를 통해 전달되는 클라이언트의 요청을 모델 오브젝트 등으로 변환할 경우이다,
프로퍼티 바인딩은 프로퍼티의 타입에 맞게 주어진 값을 적절히 변환하고, 실제 프로퍼티의 수정자 메소드를 호출해서 값을 넣는 두 가지 작업이 필요하다.
또한 프로퍼티 바인딩과 관련해서 리플렉션 이라는 용어가 나오는데, Reflection은 구체적인 클래스 타입을 알지 못해도 그 클래스의 메소드, 타입, 변수들에 접근할 수 있도록 하는 자바의 API이다.
스프링 3.1의 새로운 @MVC 전략
스프링 3.1의 애노테이션을 이용하는 MVC 기술은 스프링 3.0과 크게 다르진 않다, 가장 큰 변화는 @RequestMapping을 담당하는 핸들러 매핑 전략, 핸들러 어댑터 전략, 예외처리 전략이새로운 방식으로 모두 대체된 것이다, 스프링 3.0에서는 @RequestMappin 컨트롤러를 지원했던 3개의 DispatcherServlet 전략 클래스가 새로운 클래스로 대체되었다,

스프링 3.1의 새로운 전략 클래스의 이름은 각 전략이 지원하는 애노테이션 이름으로 시작한다, RequestMappingHanderMapping과 RequestMappingHanderAdapter는 @RequestMapping을
ExceptionHandlerExceptionResolver는 @ExceptionHandler를 지원하는 전략 클래스이다
그런데 컨트롤러 코드에서 볼 때는 애노테이션의 종류가 달라지지도 않았고, 사용 방법이 변한 것도 없다 스프링 3.1에서는 스프링 3.0과 동일하게 @RequestMapping과 @ExceptionHandler를 사용해서 컨트롤러를 작성한다, 따라서 스프링 @MVC가 제공하는 디폴트 전략 구성과 기본 기능만 사용할 경우 내부의 변화에 관심을 가질 이유가 없고, 스프링 3.0에서 작성된 @MVC 코드는 스프링 3.1에서 그대로 사용가능하다.
하지만 DS의 전략 클래스와 같은 인프라 빈을 DI 관점으로 보고, 필요에 따라 기본 기능을 확장하거나 설정을 바꾸고 싶다면 전략 클래스의 변화에 관심을 가질 필요가 없다, 스프링 3.1 @MVC 변화의 가장 큰 특징은 DispatcherServlet 전략이 아주 유연한 확장성을 가질 수 있도록 아키텍처가 개선되었다는 점이다
스프링 3.1의 @MVC 전략이 이전보다 더 유연하게 확장 가능해졌다는건 바꿔 말하면 이전에는 확장성이 좋지 않았다는 뜻인데 @RequestMapping을 지원하는 전략이 왜 예전에는 확장성이 떨어졌을까?
- @RequestMapping을 담당하는 DefaultAnnotationHandlerMapping 같은 전략 클래스가 DispatcherServlet 전략의 설계 의도와 맞지 않는 부분이 있었기 때문이다.
- HandlerMapping을 구현한 핸들러 매핑 전략의 목적은 Http 요청을 처리할 핸들러 오브젝트를 찾아주는데 있다
- 핸들러 매핑 전략은 URL 같은 요청 정보를 기준으로 요청을 처리할 핸들러를 매핑해준다
- 이 핸들러는 결국 스프링 컨테이너가 관리하는 컨트롤러 빈 오브젝트이다
- 핸들러 매핑 전략에서 요청을 처리할 핸들러 오브젝트가 결정된 후 이를 실행하는 책임은 HandlerAdpater를 구현한 핸들러 어댑터 전략이 맡게됐다
매핑 전략과 실행 전략을 깔끔하게 분리해서 다양한 방식으로 매핑할 수 있었고, 다양한 핸들러 종류를 추가할 수 있도록 유연하게 설계된 것이다, 그리고 그 중심에는 핸들러 매핑을 통해 선정된 핸들러 오브젝트, 즉 컨트롤러 오브젝트다
- 그런데 @RequestMapping을 지원하면서부터 이런 전략 구조가 매끄럽지 않아졌다
- 컨트롤러 오브젝트가 아닌 특정 메소드에 매핑되도록 설계
- 웹 요청의 개수가 급격히 증가
- 컨트롤러 클래스의 수가 증가하여 요청 처리 단위를 클래스에서 메소드로 축소하여 하나의 클래스가 여러 개의 요청을 처리
- 하지만 메소드가 독립적인 요청을 담당할 수 있게 되면서 핸들러 매핑 전략을 구현하기가 애매해졌다
- 때문에 자바의 메소드는 오브젝트로 취급하지 않았기 때문에 빈이 될 수 없었다
- 그래서 메소드 레벨의 핸들로 직접 매핑할 방법이 없다는 문제가 발생했다
스프링 3.1은 메소드를 핸들러 오브젝터로 매핑할 수 없었던 기존 핸들러 매핑의 한계를 어떻게 극복한걸까?
- 예전처럼 컨트롤러 오브젝트를 쓰는 것이 아닌 HandlerMethod라는 새로운 타입의 오브젝트를 핸들러로 넘겨준다
- HandlerMethod는 @ReuqestMapping이 붙은 메소드의 정보를 추상화한 오브젝트 타입이다
- 컨트롤러 오브젝트 대신 추상화된 메소드 정보를 담은 오브젝트를 핸들러 매핑의 결과로 돌려준다
- 핸들러 어댑터는 HandlerMethod 오브젝트의 정보를 이용해서 메소드를 실행한다.
HandlerMethod에 담긴 핵심정보는 다음 다섯가지다, 메소드 코드에 존재하는 메타정보를 대부분 갖고있다.
- 빈 오브젝트
- 메소드 메타 정보
- 메소드 파라미터 메타정보
- 메소드 애노테이션 메타정보
- 메소드 리턴 메타정보
Chapter 5. AOP와 LTW
AOP는 모듈화된 부가기능(어드바이스)과 적용 대상(포인트 컷)의 조합을 통해 여러 오브젝트에 산재해서 나타나는 공통적인 기능을 손쉽게 개발하고 관리하는 기술이다, 아래는 주요한 내용들이다.
- AOP와 프록시
- @AspectJ를 이용한 AOP 개발
- AspectJ와 @AspectJ의 차이점
AOP와 프록시
스프링 AOP를 사용한다면 어떤 개발 방식을 적용하든 모두 프록시 방식의 AOP이다, 스프링의 프록시 개념은 데코레이터 패턴에서 나온 것이고 동작 원리는 JDK 다이내믹 프록시와 DI를 이용한다, 이에 대한 워리와 적용 방법은 Vol.1에서 설명했었다, 이번에는 프록시를 만드는 방법에 따라 등록되는 빈의 종류와 사용 방법을 알아보는 것이 목적이다

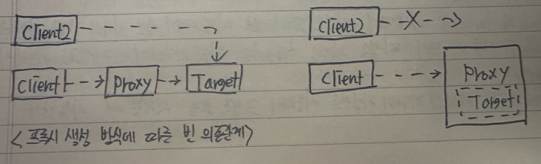
- 스프링의 자동 프록시 생성기에 의해서 만들어지는 프록시는 proxy 빈처럼 수동으로 등록한 프록시와는 다른 점이 있다
- 자동 프록시 생성기는 프록시 빈을 별도로 추가하고 DI 설정만 바꿔주는게 아니라 프록시를 적용할 대상 자체를 아예 자신이 포장해서 마치 그 빈처럼 동작한다는 점이다
- 따라서 자동 프록시 생성기가 만들어주는 프록시는 새로운 빈으로 추가되는 것이 아니라 AOP 대상 타깃 빈을 대체한다 자동 프록시 생성기 방식에서는 Target 오브젝트가 빈으로 직접 노출되지 않는다
자동 프록시 생성기에는 두 가지 특징이 있다
-
AOP 적용은 @Autowired의 타입에 의한 의존관계 설정에 문제를 일으키지 않는다
- 직접 타깃 오브젝트의 인터페이스를 구현한 프록시를 적용할 경우엔 클라이언트가 @Autowired를 사용할 수 없었다
-
AOP 적용은 다른 빈들이 Target 오브젝트에 직접 의존하지 못하게 한다
- Target 오브젝트가 proxy 빈 안에 숨어버림, 더 이상 Target 이라는 타입의 빈이 존재하지 않기 때문에
@AspectJ를 이용한 AOP 개발
@Aspect 클래스에는 포인트 컷과 어드바이스를 정의하기 위한 메소드 이외에도 일반 필드나 단순한 메소드도 포함할 수 있다, 상속과 인터페이스 구현 또는 DI를 통한 다른 빈의 참조도 가능하다
- 즉, 평범한 POJO 클래스처럼 만들면 된다
- 이런점이 @ApsectJ 방식을 이용하는 AOP 개발의 장점이다
- Execution()
: 가장 대표적이고 가장 강력한 포인트 컷 지시자다, 접근 제한자, 리턴 타입, 타입, 메소드, 파라미터 타입, 여러 타입 조건을 조합해서 메소드 단위까지 선택 가능한 가장 정교한 포인트 컷이다 - Within()
: 타입 패턴만을 이용해서 조인 포인트 메소드를 선택하낟, 계층별 포인트 컷에 유용하게 쓰일 수 있다 - this. target
:this와 target은 여러 개의 타입을 고를 수 있는 타입 패턴이 아닌 하나의 타입을 지정하는 방식이다
this는 빈 오브젝트의 타입을 확인하며 target은 타깃 오브젝트의 타입과 비교한다 - args
: args는 지시자는 메소드의 파라미터 타입만을 이용해서 포인트 컷을 설정할 때 사용한다 - @Target, @Within
: @Target 지시자는 타깃 오브젝트에 특정 애노테이션이 부여도니 것을 선정한다
ex) @Target(org.springframework, sterotype.controller) - @args
: @args는 args와 유사하게 파라미터를 이용해서 선정한다, 파라미터 오브젝트에 지정된 애노테이션이 부여되어 있는 경우 선정대상이 된다
ex) @args(com.epril.myproejct.annotation.DomainObejct) - @annotation
: @annotation 은 조인 포인트에 메소드에 특정 애노테이션이 있는 것만 선정하는 지시자다 - bean
: bean은 빈 이름 또는 아이디를 이용해서 선정하는 지시자로 와일드 카드(*)을 사용할 수 있다
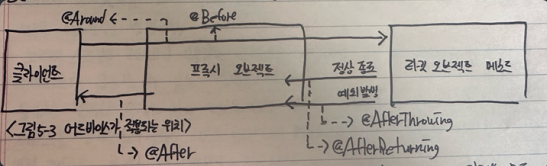
- @Around
: @Around는 프록시를 통해서 타깃 오브젝트의 메소드가 호출되는 전 과정을 모두 담을 수 있는 어드바이스다, 어떤 작업이든 가능하기에 매우 강력한 어드바이저다,
@Around는 나머지 어드바이스를 먼저 검토해서 어드바이스 로직을 적용할 수 있는지 확인하고, 적용 가능한 어드바이스가 없을 때만 최후의 선택으로 남겨두는 것이 바람직하다 - @Before
: @Before는 이름 그대로 타깃 오브젝트의 메소드가 실행되기전에 사용되는 어드바이스다,
타깃 오브젝트 메소드를 호출하는 방식을 제어할 순 없다, @Before를 적용해도 타깃 오브젝트 메소드 호출은 정상적으로 일어난다 - @AfterReturning
: 타깃 오브젝트의 메소드가 실행을 마친 뒤에 실행되는 어드바이스다, 단 예외가 발생하지 않고 정상적으로 종료한 경우에만 해당된다 - @AfterThrowing
: 타깃 오브젝트의 메소드를 호출했을 때 예외가 발생하면 실행되는 어드바이스다, @AfterThrowing 애노테이션의 Throwing 엘리먼트를 이용해서 예외를 전달받을 메소드 파라미터 이름을 지정할 수 있다 - @After
: 메소드 실행이 정상 종료 됐을 때와 예외가 발생했을 떄 모두 실행되는 어드바이스다, 코드에서 finally를 사용했을 때와 비슷한 용도라고 생각하면 된다
AspectJ와 @AspectJ의 차이점
AspectJ와 @AspectJ의 차이점은 무엇이고 다른 개념인가?
- 서로 관련은 있지만 다른 개념이다
- AspectJ
: 더 강력하고 정교한 AOP 기능을 제공하며, 컴파틸 타입과 로드타임 위빙을 지원하는 완전한 AOP 프레임워크다, 자체적인 문법을 가지고 있으며 AspectJ 컴파일러를 사용하여 코드를 처리한다 - @AspectJ
: AspectJ스타일의 애노테이션을 사용해서 "SPring AOP"에서 AOP를 구현하는 방법으로 설정이 간단하고 Spring 프레임워크와의 통합이 용이하다, 99%의 AOP 관련 문제는 이걸로 해결가능하다- 표준 자바 애노테이션(@Aspect, @PointCut, @Before, @Around 등을) 사용하여 AOP를 정의한다
Spring 컨텍스트에서 동작하면 런타임에 프록시를 기반으로 AOP를 적용한다
컴파일 타임 위빙을 지원하지 않지만 주로 런타임 위빙을 지원한다
- 표준 자바 애노테이션(@Aspect, @PointCut, @Before, @Around 등을) 사용하여 AOP를 정의한다
Chapter 6. 테스트 컨텍스트 프레임워크
스프링의 POJO와 DI를 이용한 프로그래밍 모델이 가져온 가장 큰 혜택 중 하나는 바로 테스트이다, POJO 프로그래밍 모델은 단위테스트를 손 쉽게 작성할 수 있고 기술에 종속적이지 않은 코드를 작성하여 스프링 컨테이너만으로 DB까지 참여하는 이상적인 통합테스트가 가능하다, 6장에서는 스프링이 지원하는 통합 테스트 방식인 컨텍스트 테스트의 특징을 자세히 살펴보고, 컨텍스트 테스트를 최적화된 방식으로 가능하게 해주는 컨텍스트 테스트 프레임워크의 사용방법을 살펴볼 예정이다, 주요 내용은 아래이다.
- 테스트 컨텍스트 프레임워크
- 테스트 클래스 설정
테스트 컨텍스트 프레임워크
스프링은 테스트에 사용되는 애플리케이션 컨텍스트를 생성하고 관리하고 테스트에 적용해주는 기능을 가진 테스트 프레임워크를 제공한다, 이를 테스트 컨텍스트 프레임워크라고 부른다.
테스트가 독립적이라고 해서 매번 스프링 컨텍스트, 즉 컨테이너를 마드는건 매우 비효율적인 방법이다
- 그래서 스프링은 테스트가 사용하는 컨텍스트를 캐싱해서 여러 테스트에서 하나의 컨텍스트를 공유할 수 있는 방법을 제공한다
- 동일한 컨텍스트 구성을 갖는 테스트끼리는 같은 컨텍스트를 공유하는 것이다
- 테스트용 컨텍스트의 공유는 테스트 클래스 내의 메소드 사이에서만 가능한게 아니라 여러 테스트 클래스 사이에서도 가능하다
- 덕분에 모든 테스트가 동일한 테스트용 컨텍스트 구성을 갖는다면 테스트가 수천개라고 하더라도 단 하나의 애플리케이션 컨텍스트만 만들어서 사용할 수 있다, 따라서 테스트가 매우 빨라진다
테스트 클래스 설정

테스트에 테스트 컨텍스트 프레임워크를 적용하기 위해서는 테스트 클래스에 두 가지 애노테이션을 부여해주어야 한다
- @RunWith 애노테이션을 이용해서 junit 테스트를 실행하는 러너를 스프링이 제공해주는 것으로 변경해야한다
- 컨텍스트 설정 파일을 지정해야한다, 애노테이션을 이용해서 지정해주는 설정파일을 일치시켜야한다
마무리
오늘은 토비의 스프링 Vol.2를 통해서 알게된 내용 중 주요한 내용만 정리하였다, 참고로 7장도 있는데 보너스 챕터인 거 같아서 생략했다, 책을 읽어본 사람이라면 알겠지만 오늘 내가 정리한 내용들의 대부분은 챕터 마지막 쯤에 나오는 '정리' 부분에 나오는 질문들을 기준으로 작성하였다, 그리고 저번 토비의 스프링 Vol.1에서 만든 책 정리 규칙 중에서 <의문>, <생각>, <문제> 부분들도 중요하다 느껴져서 몇 가지 넣었다.
솔직하게 말하자면, 포스팅 하면서 "그냥 챕터 별로 나눠서 포스팅 할까..?" 라는 고민을 했다, 내가 한 가지 실수한 점이 있다면 이미 요약한 걸 한 번 더 요약하자니 더 이상 요약하기엔 어떤 내용을 뺄지 또 고민이 되었고, 덕분에 각 챕터별로 어떤 내용이 중점되었는지 책을 읽은지 약 한 달이 지난 시점에서 다시 되돌아볼 수 있었다,
여튼, 계속해서 책을 읽을 예정인데 후회는 없을 거 같다 책을 읽다보면 당연히 중복되는 내용도 나오지만, 중복되는 내용이 많아질 수록 내가 어떤 객관적인 지표가 없더라도 나 자신을 믿을 수 있는 요소들이 되어가는 거 같다, 좀 뜬금없지만 책을 3.5권까지 읽은 시점에서 책의 순기능은 아래 세 가지라고 생각한다,
- 검색해서 나오지 않는 내용이 나온다
1-1. 아예 모르면 검색 자체를 안 한다 ex) POJO가 POJO인 이유- 배경지식이 넓어진다
2-1. 실전 스프링 부트를 지금 읽고 있는데 확실히 <문제> 부분이 많이 나오는 중이다- 주관이 뚜렷해진다
3-1. 과거 인문서적을 읽을 때와 동일하게 개발에 관해서 내 주관이 뚜렷해지고 있다
3-2. 하지만 항상 오픈 마인드이기에 이 정보가 절대적이라고는 생각 안 하고 있다
3-3. 개발의 정답은 웬만해서는 유동적인 거 같다..!

감사합니다.
