Ensemble
Model Averaging(voting)
- 서로 다른 모델이 일반적으로 같은 error를 발생시키는 경우가 없다는 가정하에 model averaging이 잘 동작할 것을 추측
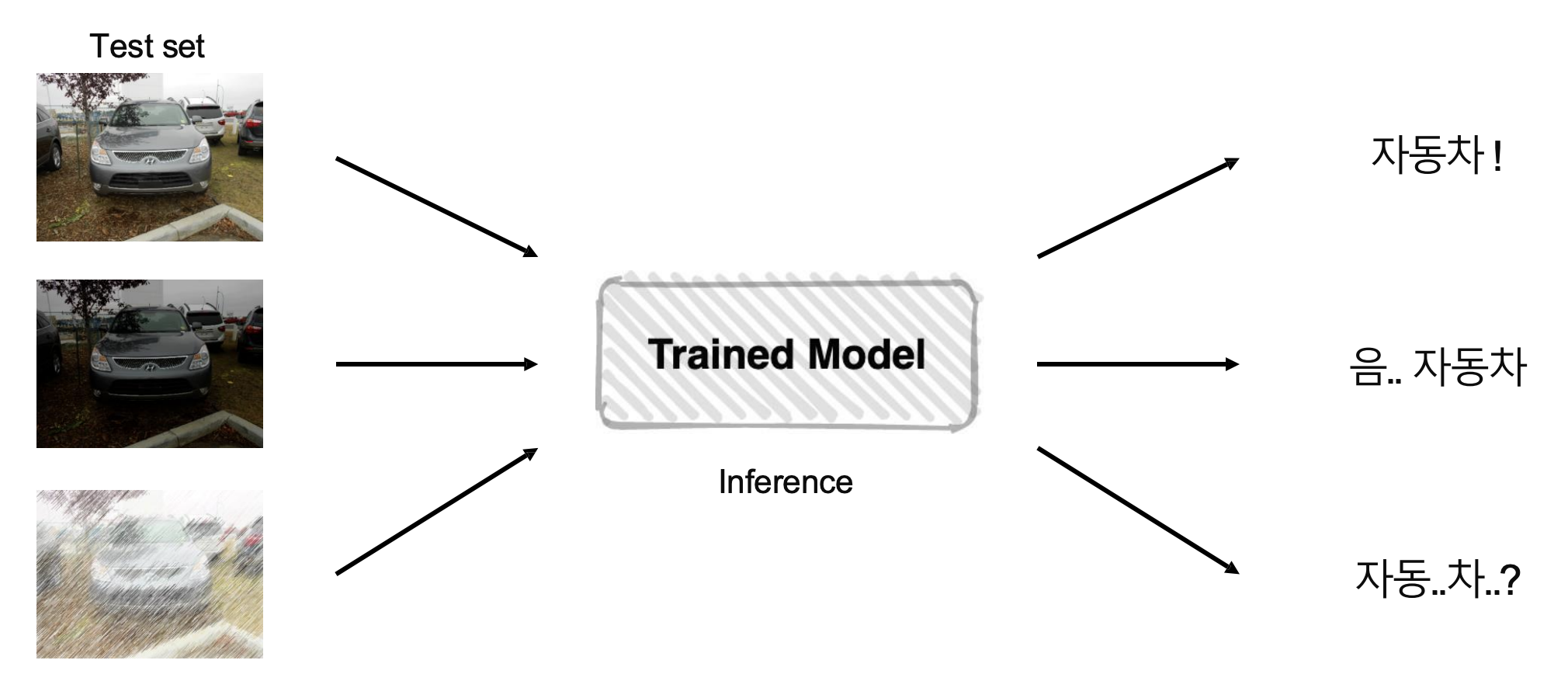
hard voting
- 다수결로 결정

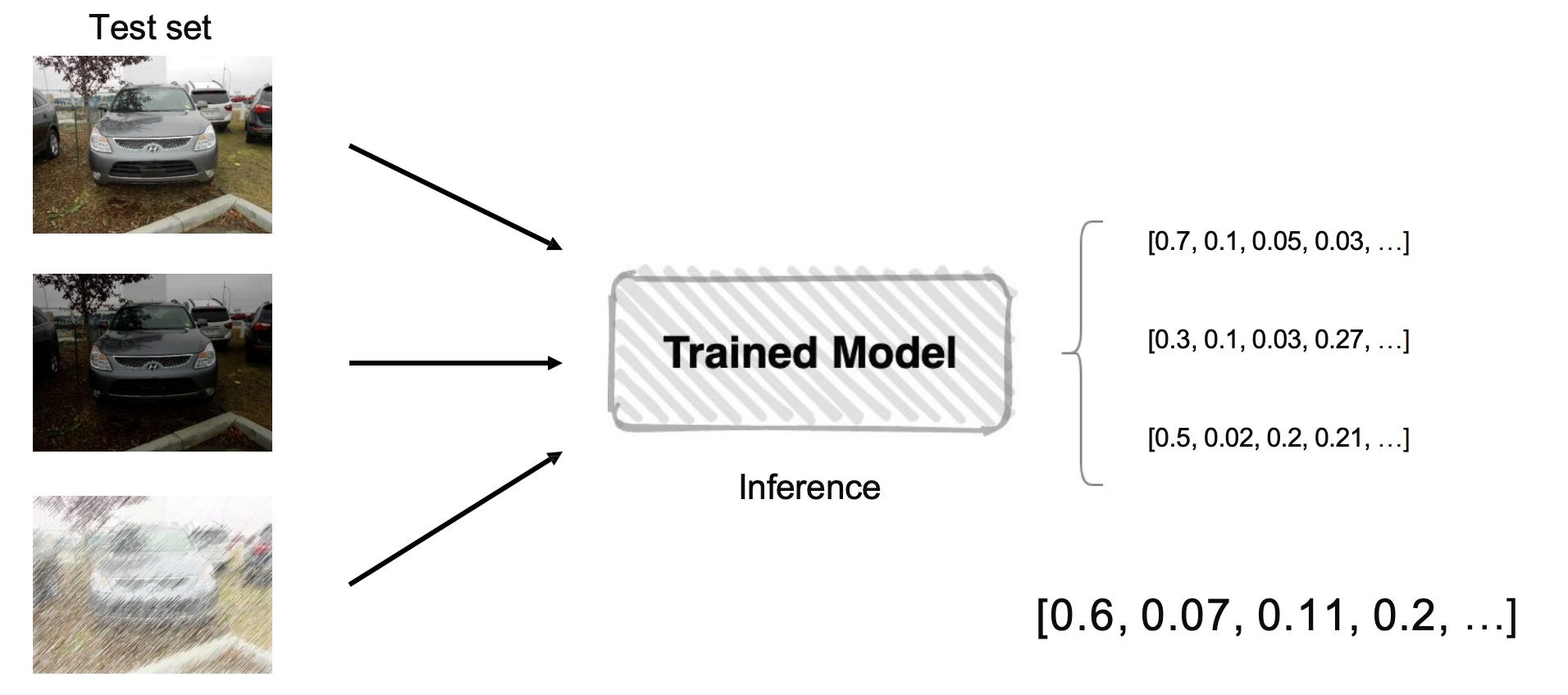
soft voting
- 각각의 모델이 추측한 각각의 index별 확률을 확인하고 결정

Cross Validation
- train set이 작을 때, 검증하기 위해 나눈 validation set의 데이터를 훈련에 사용하지 못해 아쉬울 수 있다. 이때 사용하는 것이 cross validation으로, 다른 index의 validation set으로 각각 훈련 시킨 뒤, 앙상블 하는 것이다.
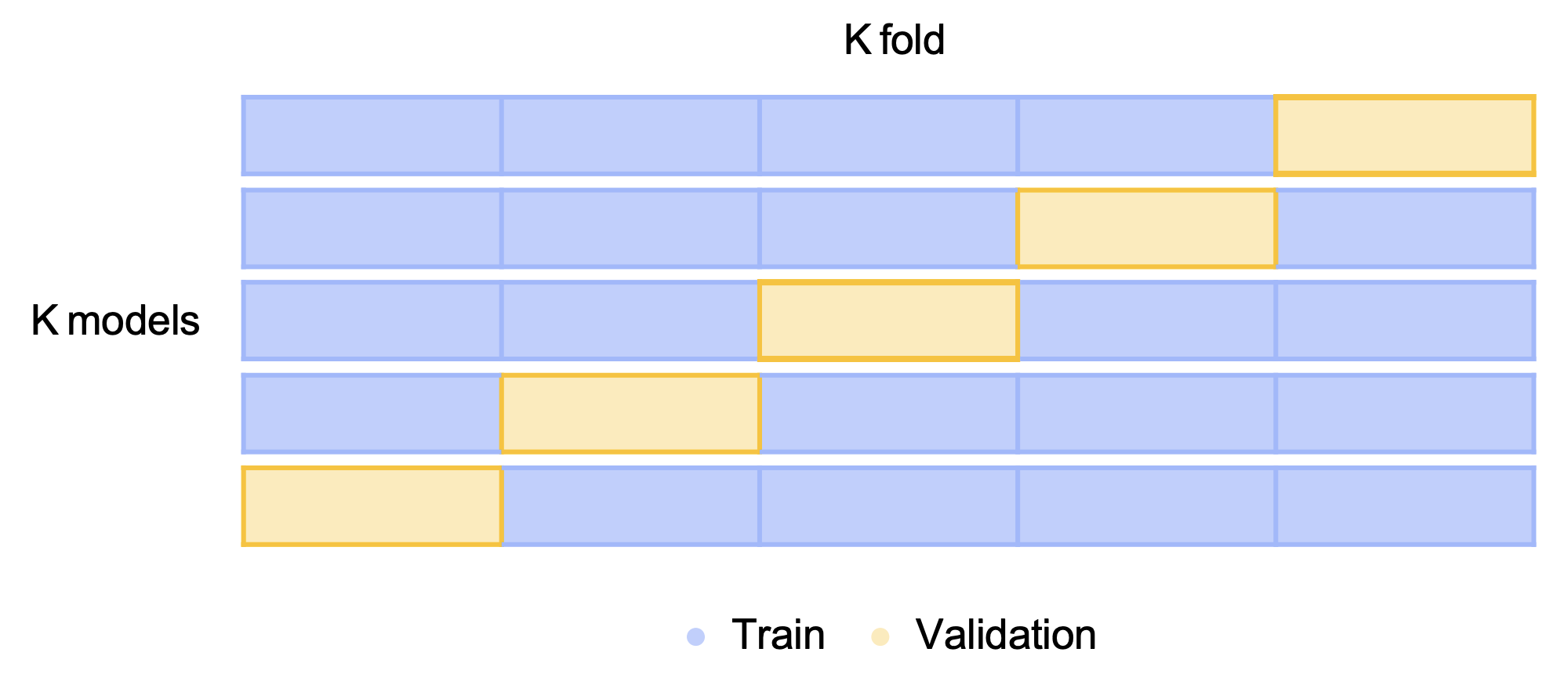
k-Fold Cross Validation
- validation이 나올 수 있는 경우의 수를 모두 앙상블 하는 것. 가능한 경우를 모두 고려하고, split시에 class의 분포까지 고려한다.
- 일반화가 잘 되는 장점이 있다.
-> k는 5정도를 일반적으로 사용한다. 너무 적게 나누게 된다면(예를들어 k가 3이라면), train dataset이 66%, validation set이 33%로 train 시킬 수 있는 데이터셋이 너무 적어지게 되어 일반화 성능이 떨어지게 된다. - 시간이 오래걸리는 단점이 있다.(k값을 크게 할 수록 더욱 많은 시간이 걸린다.)
TTA ( Test Time Augmentation)
- Train을 마치고, Test 할 때 augmentation을 하는 것.
- 테스트 이미지를 augmentation한 후에 모델을 test해서 출력된 여러가지 결과를 앙상블하는 것.
앙상블의 장단점
- 장점 : 일반화 성능이 잘 나온다.(시간이 중요하지 않는 대회의 경우 앙상블이 잘 쓰인다.)
- 단점 : 추론하는 시간이 배로 소모된다.(각각의 모델별로 test하고 앙상블을 계속 해야 되므로 현업에서는 앙상블이 잘 쓰이지 않는다.)
