📌 The Traditional Processing Pipeline of Computer Vision
계층적 처리
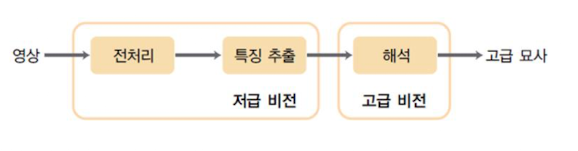
- 전처리(preprocessing): 주로 영상처리
✔️ 카메라로 획득한 원래 영상을 입력 받아 사용목적에 맞게 적절하게 처리하여 보다 개선된 영상으로 만들어주는 과정
✔️ ex) 잡음 개선, 초점이 흐린 영상 개선, 스케일링 등 - 특징 추출(feature extraction)
✔️ 에지, 선분, 원, 코너, 텍스처 등의 특징
✔️ 해당 영상만이 가지고 있는 특징을 찾아내는 것
✔️ ex) 유사 하르(Haar-like): 얼굴 인식, HoG(Histogram of Gradient): 사람 탐지, 지역 특징: 해리스코너, SIFT 등 - 해석(analysis): 응용에 따라 다양한 형태
✔️ 얼굴인식: 분류
✔️ 의료분야: 의사가 세밀하게 들여다봐야 할 의심스러운 곳 출력
✔️ 자율주행 자동차: 신호 표지판 내용, 차량의 주행 방향 등
다양한 성능 향상 방법
✔️ 응용 현장에서 수집한 지식을 담은 지식 베이스 사용
✔️ 많은 샘플영상을 수집하여 DB를 구성한 다음, 분류기 학습
✔️ 문맥 정보를 이용하는 후처리 단계 추가 (아직 걸음마 단계)
➡️ 문맥을 제대로 활용하려면 지식 표현과 추론이라는 인공지능 문제가 해결되어야 함
➡️ 의미 문맥 ex) 책상과 의자는 같은 영상에 있을 확률이 높지만, 코끼리와 침대는 같은 영상에 있을 확률이 낮음
➡️ 공간 문맥 ex) 키보드는 모니터 아래에 위치함
➡️ 자세 문맥 ex) 의자는 책상쪽을 향할 가능성이 높음
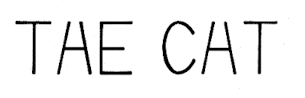
✔️ 이 경우도 우리는 THE CAT이라고 읽을 수 있지만, 컴퓨터는 THE CHT or TAE CAT이라고 읽을 수 있음 (H,A를 동일한 문자로 인식)
📌 예시
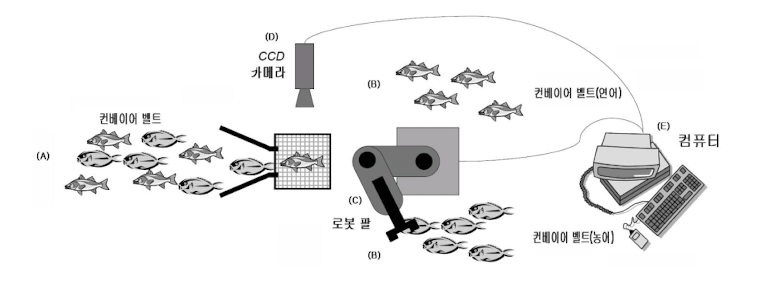
자동 어류 분류 시스템
A: 고기를 나르는 컨베이어 벨트
B: 분류된 고기를 나르는 2개의 컨베이어 벨트
C: 고기를 집을 수 있는 로봇 팔
D: CCD 카메라가 장착된 Vision 시스템
E: 영상을 분석하고 팔을 제어하기 위한 컴퓨터
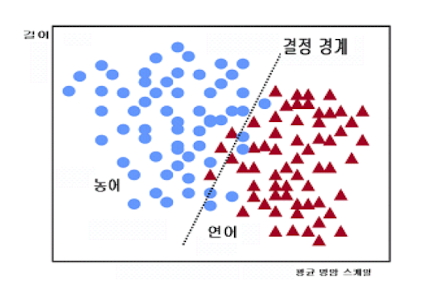
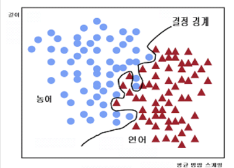
2가지 부류로 분류
연어와 농어

일반적인 Classification 과정
📌 misclassification을 최소화 시키는 것이 중요
1. 센서에서 신호를 입력 받음
2. 입력받은 신호에서 특징 추출 (구분 가능한 특성이 좋음)
3. Classifier에 특징을 질의
4. 분류된 class 얻음
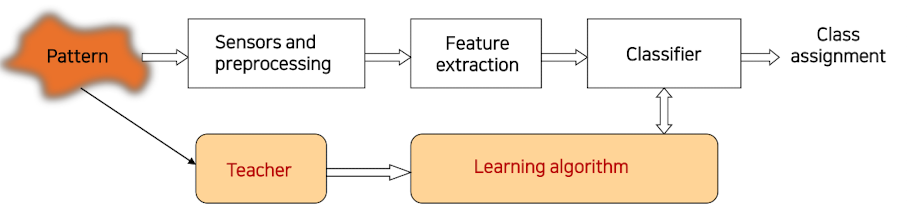
(Teacher - 지도학습이라는 의미)
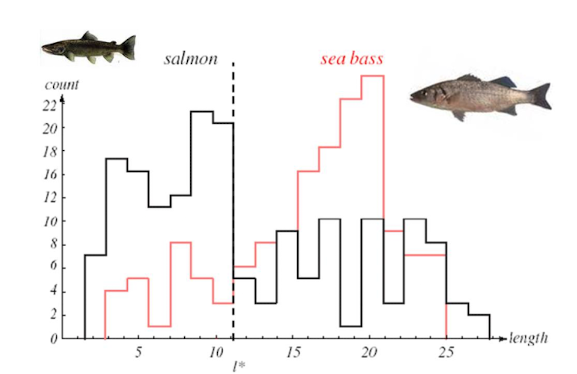
물고기의 길이만을 특징으로 사용하는 경우
✔️ 분류 오류를 최소화하는 결정 경계의 임계값 설정 (점선부분)
✔️ 분류율: 60%
물고기의 평균 명암 스케일만을 특징으로 사용한 경우
✔️ 물론 이 방법도 오분류가 있긴 하지만, 길이만을 특징으로 사용하는 경우보다 정확함
✔️ 이 경우는 명암으로 특징을 잡는 것이 더 좋음!

길이와 평균 명암 스케일을 조합하여 특징으로 사용한 경우
✔️ 분류율: 95.7%
비용과 분류율
✔️ 설계된 어류 분류기는 전체 오인식률을 최소화하도록 설계됨
✔️ 하지만 여전히 2가지 가능한 분류 오류가 존재
➡️ 농어를 연어로 잘못 인식
➡️ 연어를 농어로 잘못 인식
✔️ 어떠한 오류가 더 중요한가?
(가로- 예측값, 세로- 실제값)
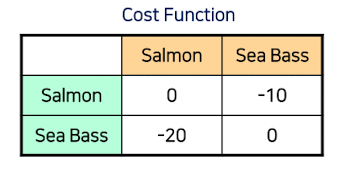
비용함수(손실함수)
✔️ 실제로 Salmon인데 모델이 Salmon이라고 예측
→ 비용: 0 (정답이니까!)
✔️ 실제로 Salmon인데 모델이 Sea Bass라고 예측
→ 비용: -10 (오답, 그리고 약간의 패널티)
✔️ 실제로 Sea Bass인데 모델이 Salmon이라고 예측
→ 비용: -20 (오답, 더 큰 패널티!)
✔️ 실제로 Sea Bass인데 모델이 Sea Bass라고 예측
→ 비용: 0 (정답!)
비용함수를 최소화하기 위하여 결정경계를 조정해야 함
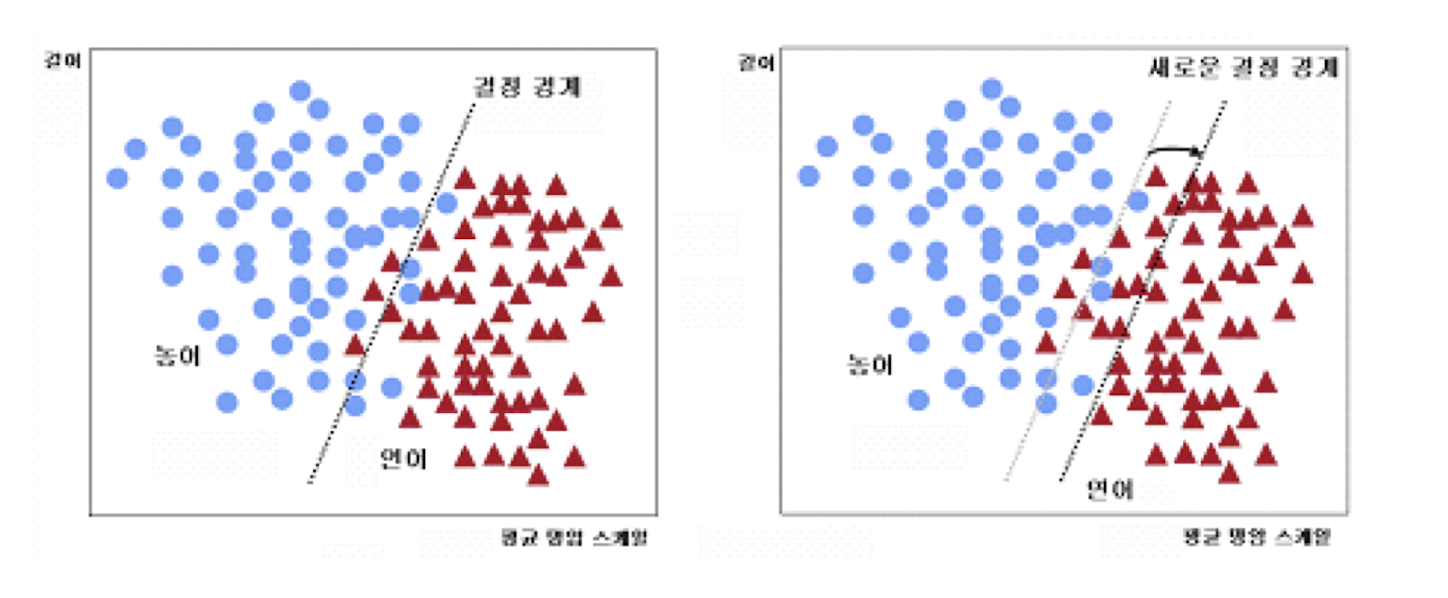
✔️ 해당 예시에서는 농어를 연어로 오분류하는 것이 연어를 농어로 오분류하는 것보다 손실이 큼
-> 정확히 나누지 못할거 농어를 연어로 오분류하는 것보다 연어를 농어로 오분류하는 것이 더 나음
✔️ 따라서 농어를 연어로 오분류하는 경우가 없도록 결정 경계를 조정
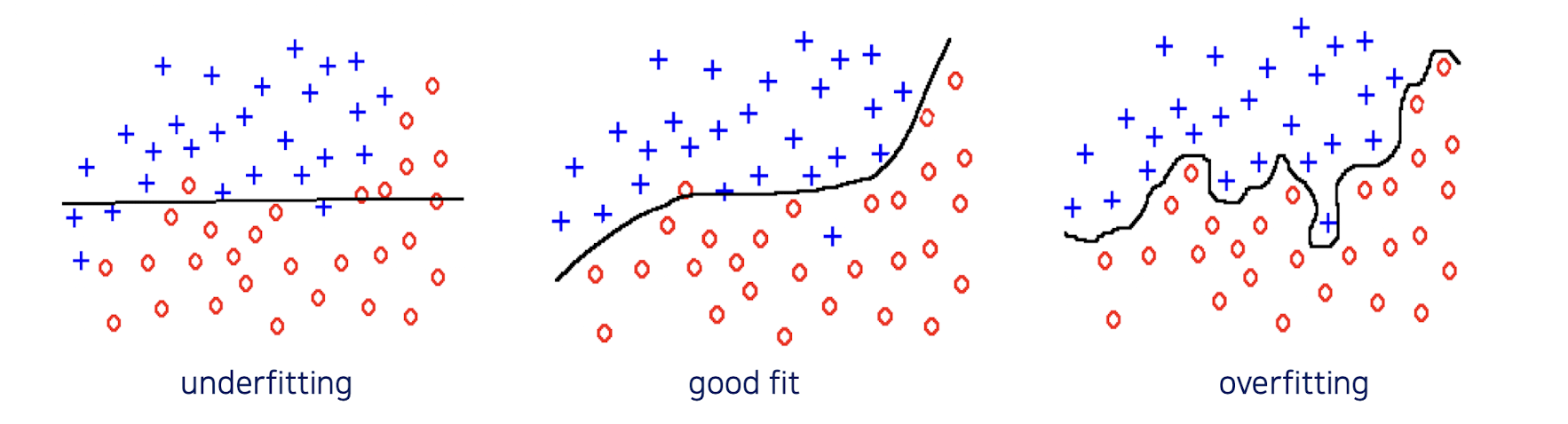
일반화의 문제
✔️ 패턴 인식기의 테스트 집합(한번도 본적 없는 샘플)에 대한 성능
✔️ 과적합 피하기
✔️ 쓸데없이 복잡하게 만들지 말고 최대한 단순하게
✔️ 과적합: 학습 데이터에 너무 과하게 맞춰져버린 상태 (처음보는 데이터셋에 대해서는 성능이 떨어질 수 있음)
비선형 결정 경계
✔️ 분류율 99.99975%
📌 분류하기 좋은, 나쁜 특징
좋은 특징
클래스간 분포가 명확하여 분류하기 쉬움
나쁜 특징
클래스가 섞여 있어 분류하기 어려움

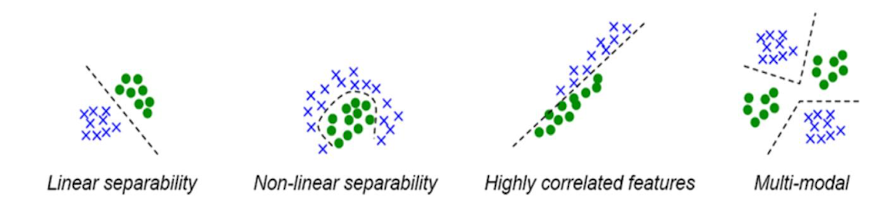
📌 특징과 분리성
선형 분리
직선 하나로 분리 가능함
ex) SVM, 로지스틱 회귀 등 선형 분류기로 쉽게 학습 가능
비선형 분리
직선으로 분리 불가
ex) 커널 SVM, 신경망 등 비선형 모델 필요
Highly correlated features
두 특성이 강하게 연관되어 있음
Multi-modal
하나의 클래스가 여러 군데에 흩어져 있음
클러스터링, 고급 분류기 필요
📌 Training/Validation/test Dataset
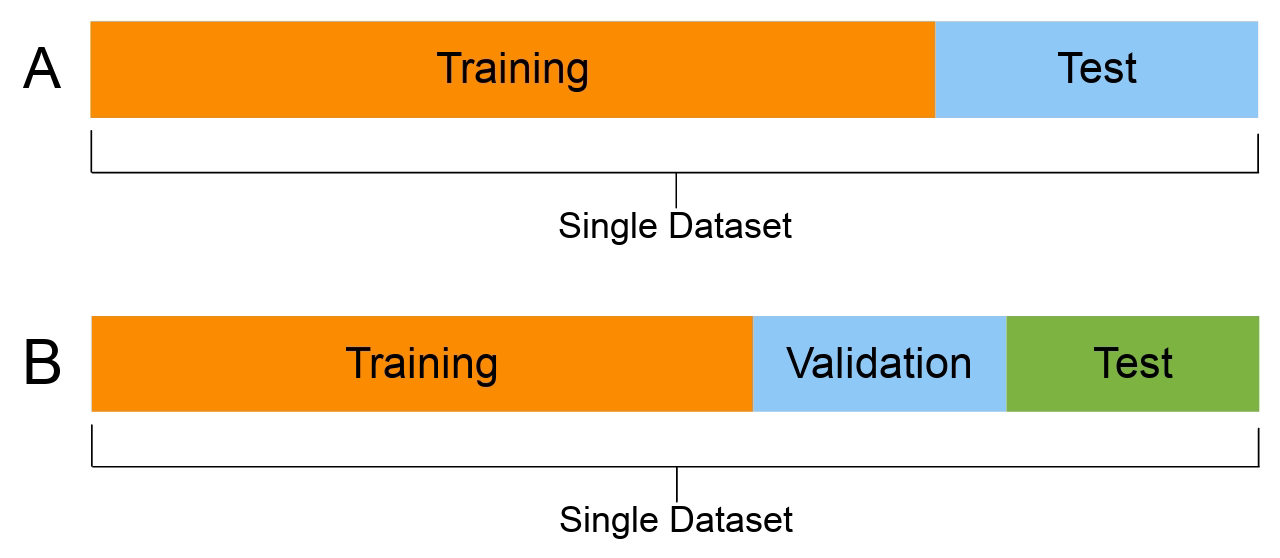
Training Set: 모델 학습
✔️ 모델을 학습하는데 사용
✔️ 이 데이터를 통해 학습하고 가중치를 최적화 함
✔️ 모델의 성능을 개선하기 이해 매번 훈련에 사용됨
✔️ 훈련 세트가 많을수록 모델이 더 많은 패턴을 학습할 수 있지만, 너무 많으면 학습 시간이 길어질 수 있음
Validation Set: 모델 튜닝 및 하이퍼파라미터 조정
✔️ 모델 학습 중에 모델의 성능을 평가하고 하이퍼파라미터(학습률, 배치 크기, 네트워크 깊이 등)를 튜닝하는데 사용
✔️ 모델이 훈련 중 과적합 되지 않도록 방지하는 역할
✔️ 훈련 세트와 테스트 세트의 중간 역할
✔️ 보통 training set에서 일부 빼서 사용함
Test Set: 모델의 최종 성능 평가
✔️ 모델 훈련이 끝난 후 모델의 성능을 최종적으로 평가하는데 사용
✔️ 모델이 실제로 얼마나 잘 일반화되는지 측정
데이터셋 분할 방법
✔️ 데이터가 많은 경우(10만 이상)
훈련: 80
검증: 10
테스트: 10
✔️ 보통 크기(1만~10만)
훈련: 70~80
검증: 10~15
테스트: 10~15
✔️ 데이터가 적음(1만 이하)
훈련: 60~70
검증: 15~20
테스트: 15~20
📌 Hyperparameters
하이퍼파라미터
✔️ 학습 과정에서 모델이 직접 학습하지 않고 사용자가 미리 설정해야 하는 값
모델 관련 하이퍼파라미터 (네트워크 구조)
✔️ 층(layers) 개수
✔️ 뉴런 개수
✔️ 활성 함수(ReLU, Sigmoid 등)
✔️ Dropout 비율 (학습 시 무작위로 몇개의 뉴런을 비활성화하는 과적합을 막기 위한 정규화 기법)
학습 관련 하이퍼파라미터 (학습 속도 조절)
✔️ 학습률
✔️ 배치 크기
✔️ 옵티마이저 종류 (SGD, Adam 등)
✔️ 가중치 초기화 방법
📌 Cross-Validation
교차 검증
📍 데이터가 부족한 경우, 모델의 성능을 더 정확하게 평가하기 위한 기법
✔️ 과적합 방지, 일반화 능력을 평가하는데 유용
✔️ 과적합을 피하는 것이 곧 일반화를 잘 하는 것
✔️ 일반적인 데이터 분할 방법(훈련, 검증, 테스트)을 사용하는 대신, 데이터를 여러 부분으로 나누어 여러번 학습하고 평가
✔️ 학습 데이터와 테스트 데이터는 구분 해놓고, 학습 데이터 내부에서 학습할 때마다 학습 데이터와 검증 데이터를 다르게 나눠서 학습을 진행함
기본 개념
✔️ 데이터를 여러 개의 fold로 나누고, 각 fold가 한 번씩 검증 세트로 사용되고, 나머지 fold들은 훈련 세트로 사용됨
✔️ 모델의 성능은 각 fold에 대해 평가된 성능들의 평균을 계산하여 측정
➡️ 데이터가 적을 때, 모델 평가의 신뢰성을 높이고, 각 데이터 포인트가 훈련과 평가에 여러 번 사용되므로 더 적확한 성능 평가 가능
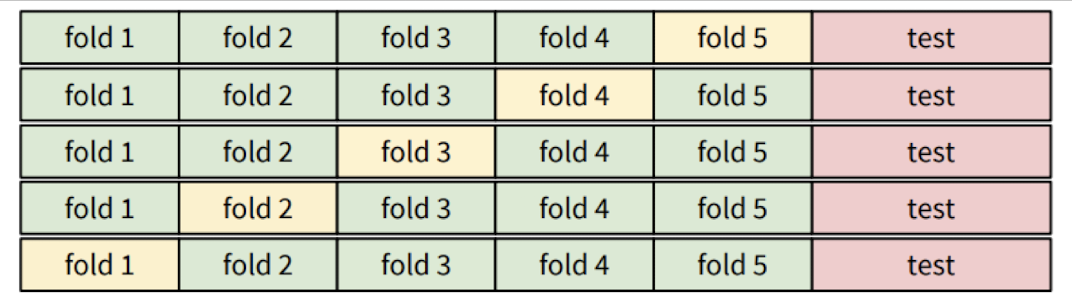
K-fold Cross-Validation
✔️ 데이터를 K개의 fold로 나눔 (하나의 fold에 (100/K)%씩)
✔️ 모델 학습 및 평가
1. 첫 번째 fold를 검증 세트로 하고, 나머지 4개는 학습셋으로 사용하여 모델 학습
2. 학습이 끝나면 첫 번째 fold에서 모델 평가
3. 이 후 두 번째 fold를 검증셋으로 하고, 나머지는 학습셋으로 사용하여 모델을 학습하고 평가
4. 해당 과정을 K번 반복하여 각 fold에 대한 성능 평가 진행
5. K번의 평가 결과의 평균을 구하여 모델의 최종 성능 계산
Why is Computer Vision diffcult?
컴퓨터 비전이 어려운 이유는 명확
✔️ 환경(낮/밤, 날씨 등) 변화
✔️ 보는 위치와 방향의 변화 등
✔️ 영상 -> 숫자로 구성된 2차원 배열
✔️ 지식 표현, 추론, 계획, 학습이 유기적으로 동작할 때만 강한 인공지능이 될 수 있음

문제와 도전 과제
✔️ 컴퓨터는 영상을 숫자 배열로 볼 수 있음
✔️ 보는 위치와 방향의 다야함
✔️ 그림자 (명암 차이)
✔️ 배경의 어수선함 (배경과 객체가 비슷할 경우)
✔️ 객체가 가려져있음
✔️ 다양한 모양 (같은 고양이라도 자세에 따라 다름)
✔️ 변형
✔️ 같은 객체 다른 생김새
✔️ 문맥 (강아지가 그림자때문에 호랑이처럼 보임)
✔️ 크기 (확대하면 해상도 문제로 영상이 깨짐, 사람은 전체적인 맥락을 보고 인식 가능하지만 컴퓨터는 아님)
📌 Building a Computer Vision System
1. 문제 이해
📍 주어진 문제에 대한 직관적이나 철저한 이해가 중요
✔️ 합리적 제약 조건 수립 필요
ex) 얼굴 인식기
크기가 일정한 정면 얼굴 vs 자연 영상 속 얼굴
➡️ 전자는 제작은 쉽지만 응용 분야가 제한됨 (보안 장치 활용 가능, 사진 분류 응용 불가)
2. 데이터베이스
✔️ 질적/양적으로 우수해야 고성능 시스템 제작 가능
✔️ 데이터베이스 : 학습+검증+테스트 집합
✔️ 여러가지 용도의 데이터 베이스
➡️ ground truth : 컴퓨터 비전 시스템이 알아야할 정답
✔️ 수집 방법
➡️ 직접 수집: 많은 비용 부담해야 하지만 개발자의 자산이 됨
➡️ 인터넷 다운로드: 고품질 데이터베이스 풍부함
3. 알고리즘 설계와 구현
✔️ 알고리즘 선택의 중요성과 어려움
✔️ 새로운 알고리즘 개발 또는 기존 알고리즈므 중에 주어진 문제에 적합한 것 선택
선택방법
✔️ 데이터베이스를 이용해 성능 실험 (설계자의 경험과 직관이 중요)
➡️ 휴리스틱 방식 사용: 보통 적잘한 알고리즘을 찾을 때까지 다양한 알고리즘을 적용
✔️ 성능 비교 분석 논문을 참조하여 이들이 제시한 성능 비교 결과 참조
고전 컴퓨터 비전과 딥러닝 컴퓨터 비전
✔️ 대략 2010년을 기점으로 방법론의 대전환
✔️ 둘 다 이해하는 것이 좋음
📍 고전 방법론
✔️ 규칙 기반 방법론
➡️ 규칙 기반은 사람이 영상을 보고 규칙을 도출하고 프로그래밍 함
➡️ 분명한 한계가 존재함
📍 딥러닝 방법론
✔️ 데이터 중심
➡️ 데이터에 따라 최적 필터를 설계해야 하지 않을까?
➡️ 데이터 기반 학습을 통해 문제 해결
딥러닝 개발 환경
✔️ Python
✔️ 컴퓨터 비전을 지원하는 OpenCV 라이브러리
✔️ 딥러닝을 지원하는 Tensorflow, Pytorch 라이브러리
✔️ 고성능 GPU : 구글 코랩
OpenCV
✔️ 인텔이 주도하여 개발한 컴퓨터 비전 관련 오픈소스 라이브러리
(학술, 상업용 목적을 불문하고 무료로 사용 가능)
✔️ 대부분 알고리즘이 다 구현되어 함수 형태로 제공
✔️ 기계학습, GPU 관련 함수 등 지원
✔️ 다양한 문서, 샘플 코드 제공
📍 지원 플랫폼
✔️ 윈도우, 리눅스, macOS, iOS, 안드로이드
✔️ Tensorflow, Pytorch 등 딥러닝 프레임워크 지원
📍 프로그래밍 언어
✔️ 클래스와 함수는 C,C++로 개발
✔️ 인텔 프로세서에 최적화
✔️ 전체 코드 180만 라인 이상
✔️ 실시간 연산이 가능하도록 연산의 효율성을 최대한 고려하여 설계됨
✔️ 인터페이스 언어는 C, C++, 자바, 자바스크립트, 파이썬 지원
📍 성능 향상을 위해
✔️ CUDA 기반의 GPU 프로그래밍, 인텔의 TBB DLL 지원
Pytorch
✔️ 페이스북의 AI 연구팀이 개발한 딥러닝 라이브러리
✔️ 일반 파이썬 코드처럼 동작해서 배우기 쉽고, 코드 실행 중에 네트워크 구조를 바꿀 수도 있고, 디버깅이 쉬움
➡️ 유연성이 높고 복잡한 모델을 만들 때 강력
✔️ 연구화 실험에 강점
Tensorflow
✔️ 구글의 브레인 팀이 개발한 딥러닝 라이브러리
✔️ Keras가 공식 고수준 API로 통합되어 초보자가 쉽게 딥러닝 모델 구축 가능
✔️ 기존의 많은 코드가 Tensorflow 기반
➡️ 관련 예제 코드가 많고, 다양한 기능을 제공함
✔️ Tensorflow 2.x 이후 좀 더 유연하고 직관적인 방식으로 개발을 지원
✔️ 산업 및 프로덕션 환경(서비스 배포)에 강점

(좌 - 파이토치, 우 - 텐서플로우)
Jupyter Notebook
✔️ 데이터 분석, 머신러닝, 과학 계산, 문서 작성 등을 쉽게 할 수 있도록 만든 인터랙티브 개발 환경
✔️ 파이썬 코드를 실행하면서 시각화된 결과를 즉시 확인 가능
📍 특징
✔️ 웹 기반
✔️ 코드를 서버로 전달해서 실행하고, 그 결과를 웹 화면으로 보여줌
✔️ 작업 페이지 내에 그림도 보여주고, 문서 작성도 가능
✔️ 작업 결과를 파일로 저장 가능 (.ipynb 파일)
4. 성능 평가
✔️ 성능 측정 방법의 다양성: 문제 및 요구사항에 따라 다양
✔️ 위험 기준에 따라 시스템 설계
➡️ 암 환자를 정상이라 오분류하는 것의 위험 > 정상인을 암환자로 오분류
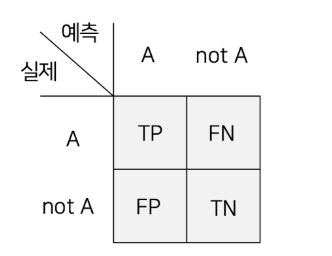
혼동 행렬 (confusion matrix)
✔️ 모델이 예측한 값과 실제 값이 어떻게 일치하는가를 2D 행렬 형태로 보여줌
✔️ 오류 경향을 세밀히 분석하는데 사용
📍 True Positive : TP
모델이 긍정 클래스로 예측하고 실제로도 긍정 클래스일 때
📍 False Positive : FP
모델이 긍정 클래스로 예측했지만 실제로는 부정 클래스일 때 (잘못 예측)
📍 True Negative : TN
모델이 부정 클래스로 예측했지만 실제로는 긍정 클래스일 때(잘못 예측)
📍 False Negative : FN
모델이 부정 클래스로 예측하고 실제로도 부정 클래스일 때
혼동 행렬 예시
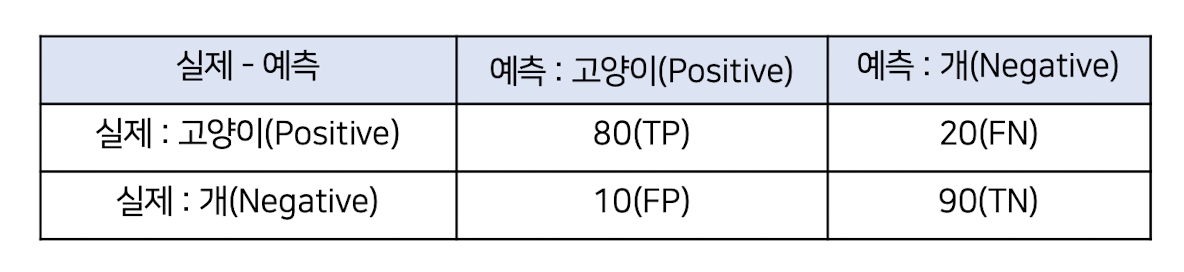
✔️ 혼동 행렬에서 유용한 지표
📍 모델이 잘못 예측한 부분과 잘 예측한 부분을 구체적으로 분석하는데 유용
(해당 값이 높을수록 좋음!)

객체 탐지에서 혼동 행렬과 평가 지표
✔️ 일반적인 이즌 분류에서의 TP,FP,FN 외에도 Bounding box의 정확성을 같이 고려
✔️ 객체 탐지에서는 위치 예측의 정확성이 중요하기 때문에, IoU 기준을 활용하여 혼동 행렬을 만드는 것이 핵심
📍 TP: 예측된 Bounding box가 실제 객체의 Bounding box와 충분히 겹치는 경우
📍 FP: 예측된 Bounding box가 실제 객체와 겹치지 않는 경우
📍 FN: 실제 객체가 존재하는데 모델이 이를 예측하지 못하는 경우
📍 Intersection over Union (IoU): 예측된 Bounding box와 실제 Bounding box가 겹치는 정도


객체 탐지에서 혼동 행렬 구성 예시
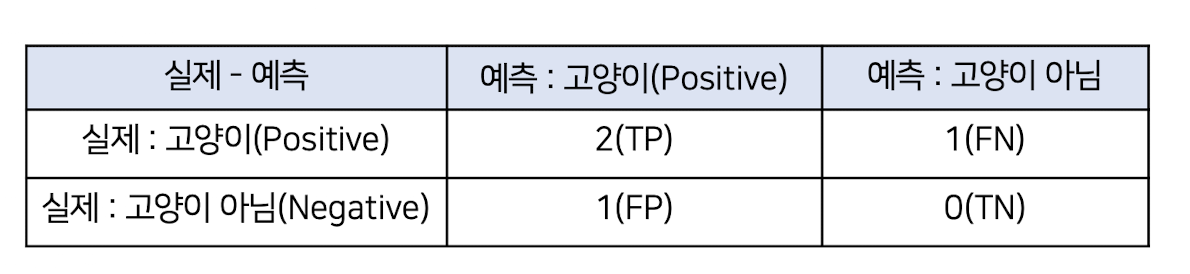
✔️ 예시 상황
고양이를 탐지하는 객체 탐지 모델
이미지에 3개의 실제 고양이 존재
탐지 결과: 3개의 고양이 중 2개를 정확히 찾아내고, 1개는 놓쳤으며(예측 못함), 1개의 잘못된 예측을 함 (고양이가 아닌데 고양이라고 예측함)
✔️ 객체 탐지 결과 분석
실제 고양이(ground truth): 3개
고양이1(실제 객체) / 고양이2(실제 객체) / 고양이3(실제 객체)
✔️ 모델의 예측
예측 고양이1 : IoU>0.5로 실제 고양이 1과 겹침 TP
예측 고양이2 : IoU>0.5로 실제 고양이 2과 겹침 TP
예측 고양이3 : IoU<0.5로 실제 고양이 3과 겹치지 않음 FP(잘못된 예측)
실제 고양이3 : 예측되지 않음 FN
TN: 실제로 고양이가 없고, 고양이가 없다고 예측하는 경우인데, 해당 예시에서는 고양이가 반드시 한마리 이상 있어야 하기 때문에 TN이 없음
