논문을 다 읽고 쓴 것은 아님. 추후에 정독 후 보충할 생각.
REST란?
“Representational State Transfer” (REST) is the name that Fielding gave to his description of the Web’s architectural style, which is composed of the constraints outlined above. - from REST API Design Rulebook
초기의 인터넷은 따라야할 설계나 구조가 존재하지 않았다. 그래서 인터넷의 규모를 키우는데 한계를 만나게 된다. 이런 문제를 해결하기 위해 나온 것이 바로 REST 구조이다. REST는 REpresentational State Transfer를 뜻한다.
즉, REST란 로이 필딩이 Web architecture style을 정의하고 거기에 붙인 이름이다.
왜 REST는 중요한가?
초창기 인터넷을 폭발적으로 사용자의 수가 증가했다. 그래서 구조적으로 이러한 확장을 감당하지 못했다. 이러던 와중에 로이 필딩이란 선구자가 인터넷이 계속해서 규모를 키우기 위해선 충족시켜야 할 조건(제약)들을 알아냈다. 그리고 이것을 자신의 박사 논문에 발표하기에 이른다. 덧붙여 이러한 조건들을 만족하는 시스템 아키텍처를 REST Architecture라고 부른다. 이때 로이필딩이 제시한 조건들은 아래와 같다.
- Client-Server
- Uniform Interface
- Identification of Resources
- Manipulation of resources through representation
- Self-descriptive message
- Hypermedia as the Engine of Application State(HATEOAS)
- Layered System
- Cache
- Stateless
- Code-on-demand
REST API란?
REST API는 REST 아키텍처에 적합하도록 설계된 API를 뜻한다.
무엇이 REST API인지 알기 위해선 그 판단 척도가 필요하다. 이러한 척도를 제공한 모델이 있으니 마로 Richardson Maturity Model이다. 이 모델은 3개의 단계를 통해서 RESTful함을 측정할 수 있도록 하였다.
Level 1: URI
Level 2: HTTP
Level 3: Hypermedia
그리고 많은 시간 동안 개발자들은 REST API를 개발하기 위해서 노력해왔다. 이런 과정을 거쳐 생겨난 Best Practice가 Richardson Maturity Model이라고도 할 수 있다.
0. 들어가기 전에
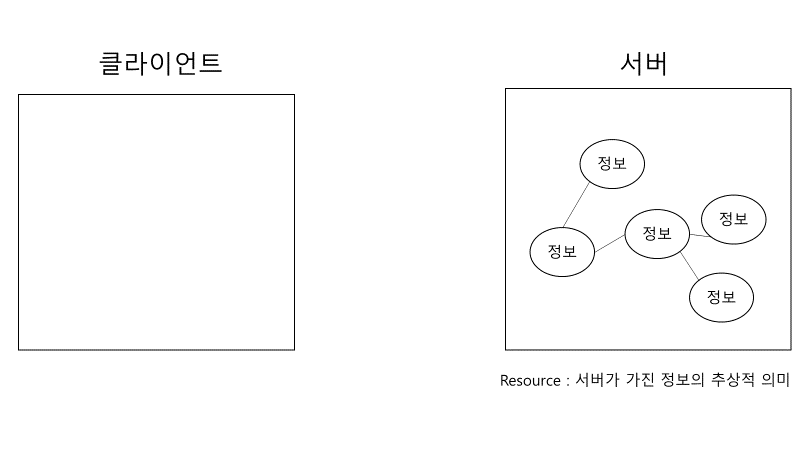
우리는 REST 구조를 알기 위해 이것의 창시자인 Roy Fielding이 저술한 “Architectural Styles and the Design of Network-based Software Architectures”이란 논문을 부분적으로 살펴볼 것이다. 그러기 위해선 먼저 해당 논문에서 resource란 단어를 어떻게 정의했는지 알 필요가 있다.
Definition of a resource
Any information that can be named can be a resource - 논문 p.88
로이 필딩은 웹을 아주 추상적인 관점에서 바라보았다. 그래서 개발자라면 가질만한 물리적인 편견을 모두 버려야만 한다. 예를 든다면 서버에게 ‘사용자의 개인 정보를 불러와’라고 요청했다면 그것이 아주 당연하게도 json 포맷일 거라는 편견 말이다. 로이 필딩의 웹에서는 사용자의 개인 정보는 단지 추상적인 의미(semantic)일 뿐이다. 그리고 이처럼 서버에 저장된 추상적인 의미를 resource라고 한다.

1. Client-Server
Separation of concerns is the principle behind the client-server constraints. - 논문 p.78
A proper separation of functionality should simplify the server component in order to improve scalability. - 논문 p.46
The separation also allows the two types of components to evolve independently, provided that the interface doesn’t change. - 논문 p.46
웹은 클라이언트와 서버 구조로 이루어져야 한다. 이러한 구조를 지니도록 하는 이유는 관심사를 분리시키기 위해서이다. 즉, 서버는 서버의 일만 하도록 하고, 클라이언트는 클라이언트의 일만 하도록 한다. 이러한 분리를 통해서 결합도(coupling)을 낮출 수 있다. 그래서 클라이언트는 서버가 무슨 일을 하는지 전혀 몰라도 된다.
관심사의 분리는 컴퓨터 과학에서 사용하는 설계 원칙이기도 하다.
덧붙여 클라이언트-서버 구조 또한 로이 필딩의 관점에 맞게 추상적으로 이해할 필요가 있다.
2. Uniform Interface
The WorldWideWeb (W3) is a wide-area hypermedia
information retrieval initiative aiming to give universal access to a large universe of documents. - by Tim berners Lee
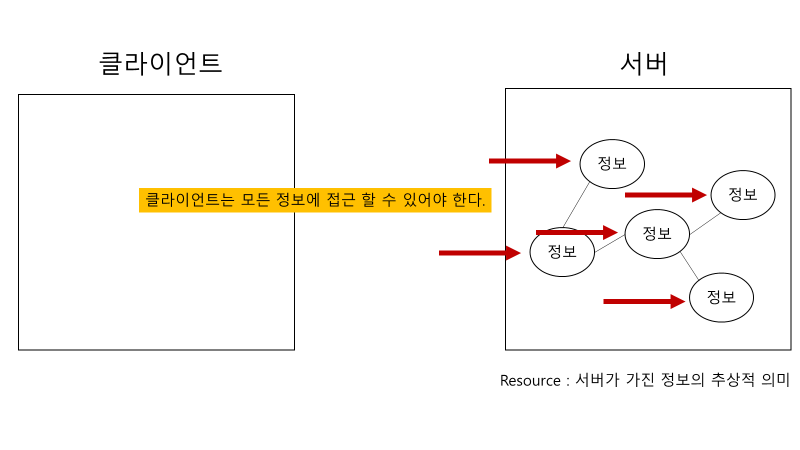
인터넷 상의 모든 resource는 unique identifier에 의해서 접근 가능해야 한다.
그리고 이것을 충족시키기 위한 조건이 바로 Uniform Interface이다.
Uniform Interface를 충족하기 위한 세부 조건(제약)은 다음과 같다.
- Identification of Resources
- Manipulation of resources through representation
- Self-descriptive messages
- Hypermedia as the Engine of Application State (HATEOAS)
a. Identification of Resources
REST uses a resource identifier to identify the particular resource involved in an interaction between components. - 논문 p.90
Axiom 0: Universality 1
Any resource anywhere can be given a URI
웹의 창시자인 Tim Berner’s Lee는 Axioms of Web Architecture에서 모든 resource는 URI를 가져야 한다고 명시하고 있다.
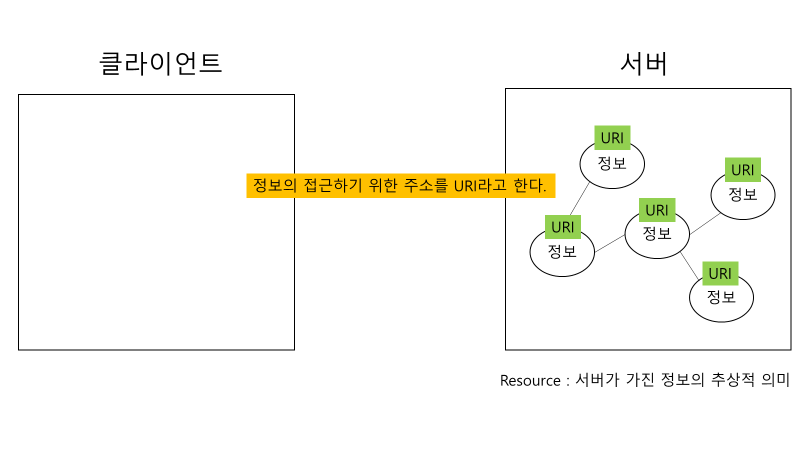
Uniform Interface란 조건을 만족하기 위한 첫 번째 세부 조건은 바로 Identification of Resources이다. 다시 말해, 모든 정보들은 자신만의 고유한 주소를 가지고 있어야 한다. 그리고 이러한 주소를 URI(Uniform Resource Identifier)라고 한다.
b. Manipulation of resources through representation
REST components communicate by transferring a representation of a resource in a format matching one of an evolving set of standard data types, selected dynamically based on the capabilities or desires of the recipient and the nature of the resource. - 논문 p.87
The definition of resource in REST is based on a simple premise: identifiers should change as infrequently as possible. Because the Web uses embedded identifiers rather than link servers, authors need an identifier that closely matches the semantics they intend by a hypermedia reference, allowing the reference to remain static even though the result of
accessing that reference may change over time. - 논문 p.110
개인적으로는 이 항목을 이해하는데 제일 힘이 많이 들었다. 왜냐하면 이 부분은 resource와 representation, state 모두를 알고 있어야 하기 때문이다.
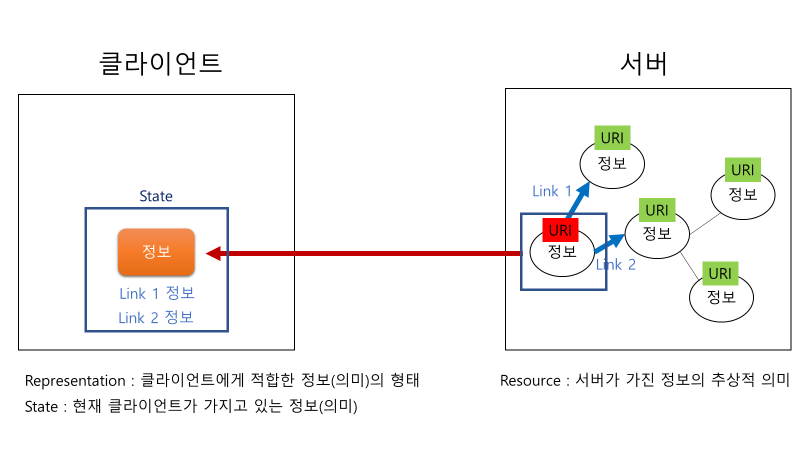
서버에 저장되어 있던 추상적인 정보는 클라이언트에게 전달이 되고 나서야 약간의 구체적인 모습을 가진다. 이때 구체적인 모습을 바로 representation에 해당된다. 또한 클라이언트가 현재 지니고 있는 정보를 state라고 한다. 그래서 REST를 이렇게 형태(REpresentational)를 지닌 정보(의미, State)를 전달하는 구조라고 말할 수 있다.
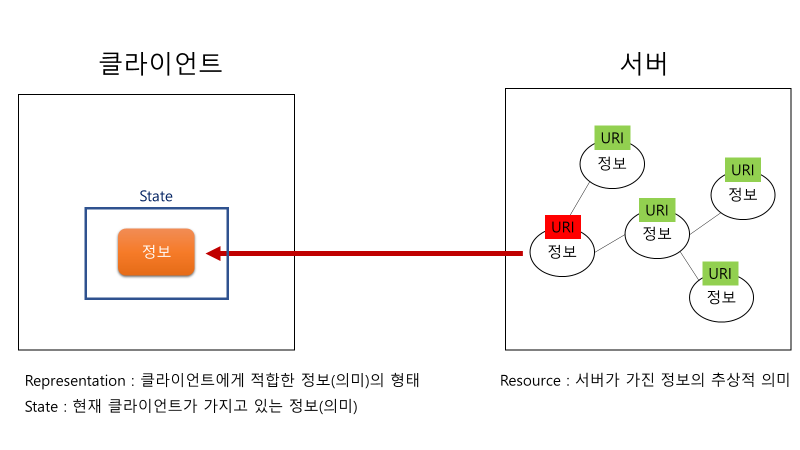
보다 더 구체적인 예시를 들어본다.
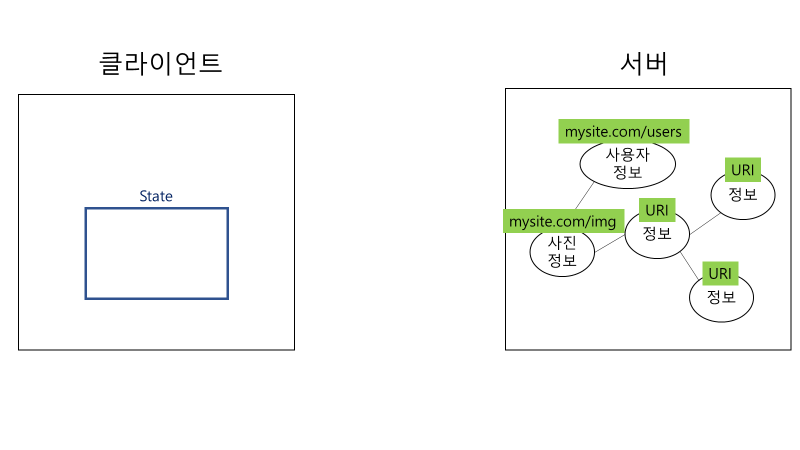
위와 같이 추상적인 사용자 정보와 사진 정보가 서버에 저장되어 있다. 이 정보들을 클라이언트는 URI를 통해 특정하여 요청한다.
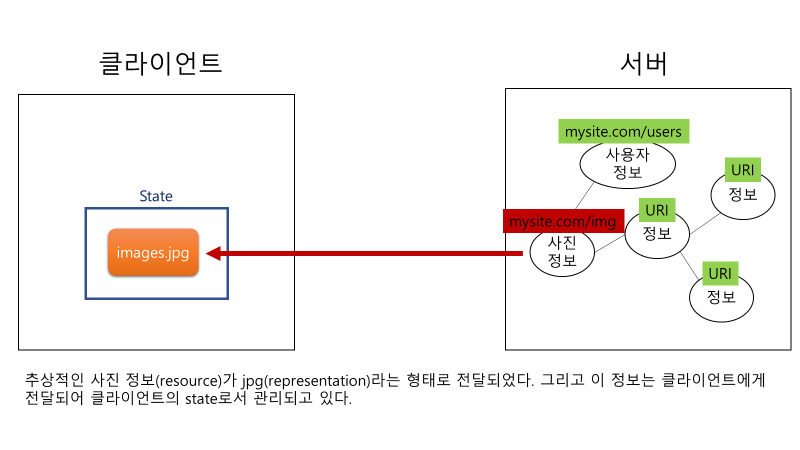
이때 추상적인 사진 정보는 클라이언트에게 적합한 형태로 구체화 되어서 전달된다. 지금은 JPG 형태로 클라이언트에게 전달된 모습이다.

이번에는 추상적인 사용자 정보를 URI로 특정하여 클라이언트가 서버에게 요청하였다. 그런데 같은 정보를 요청하였음에도 클라이언트에 따라서 XML, JSON 형태로 제공되었다. 이렇듯 하나의 정보의 추상적 의미는 고정적이다. 그러나 이것이 제공될 때 클라이언트마다 그 형태가 달라질 수 있다.
이렇게 클라이언트에게 적합하도록 형태를 조작하는 것이 바로 Manipulation of resource as representation이라고 할 수 있다.
c. Self-descriptive messages
REST constrains messages between components to be self-descriptive in order to support intermediate processing of interactions. - 논문 p.121
message 하나에는 정보 요청 시에 필요한 모든 정보가 들어가 있어야 한다. 즉, 필요한 모든게 다 담겨 있는 메세지를 서버에게 보내야 한다. 이러한 조건이 지켜지면, 아래에서도 서술하겠지만 stateless란 조건도 충족할 수 있게 된다.
HTTP 1.1 명세를 보면 HTTP Method에 해당하는 것들이 있다. 이것은 클라이언트와 서버 간 주고받는 메세지의 유형을 나타내는 정보이다. 이때 이 유형을 통해 서버는 클라이언트가 요청한 행동을 수행할 수도 있다.
그리고 메세지는 헤더와 바디로 이루어져 있는데, 헤더는 메타 데이터가 들어가 있으며 바디에는 메세지의 데이터 그 자체가 들어있다.
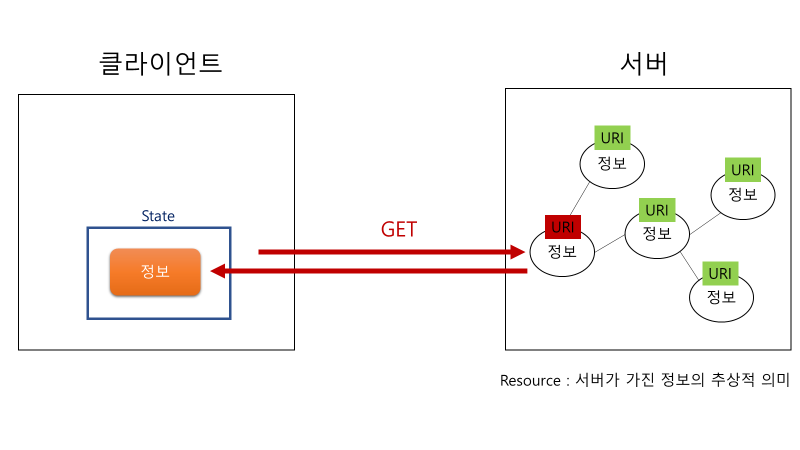
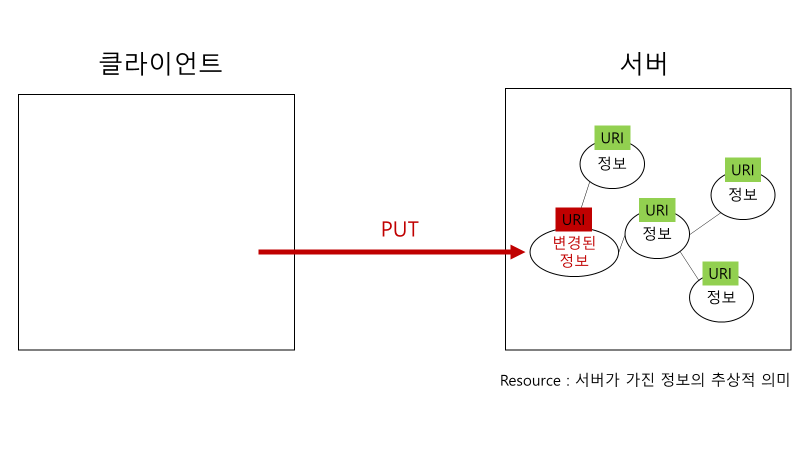
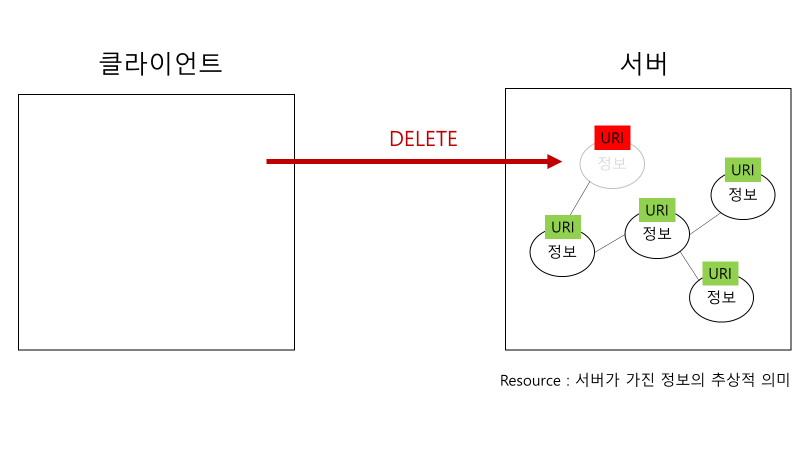

d. Hypermedia as the Engine of Application State (HATEOAS)
A resource’s state representation includes links to related resources. Links are the threads that weave the Web together by allowing users to traverse information and applications in a meaningful and directed manner. - from REST API Design Rulebook
팀 버너스 리는 웹이란 시스템을 통해서 모든 Resource에 클라이언트가 접근하길 바랬다. 그러나 클라이언트는 주어진 resource들 간의 관계 또는 적절한 접근 방법에 대해서 알지 못한다. 그래서 클라이언트가 resource들을 보고자 할 때 사용할 수 있는 이정표로서 Hypermedia가 사용된다. 그래서 이렇게 사용되는 Hypermedia는 현재 application(client)가 갖고 있는 resource인 state를 계속해서 변경 가능케 해주는 역할(Engine)을 한다. 왜냐면 그 Hypermedia는 Hyperlink의 역할도 수행하기에 다음으로 불러올 적절한 resource를 명시해주는 역할을 하기 때문이다. 이처럼 계속해서 resource들을 이동하면서 application의 state를 변경해주기에 Hypermedia as the Engine of Application State라고 부르는 것이다.
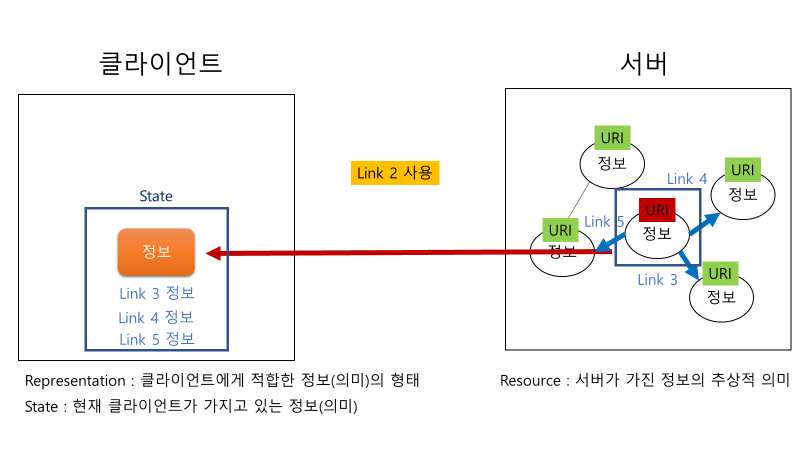
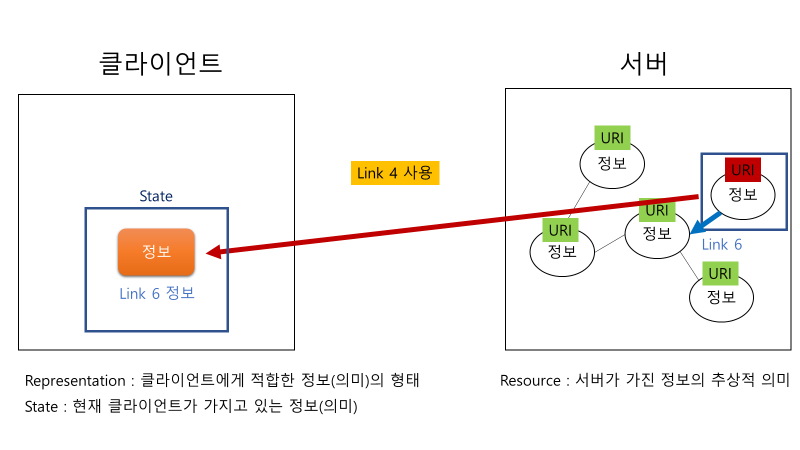
3. Layered System
In order to further improve behavior for Internet-scale requirements, we add layered system constraints - 논문 p.82
By restricting knowledge of the system to a single layer, we place a
bound on the overall system complexity and promote substrate independence. - 논문 p.83
Intermediaries can also be used to improve system scalability by enabling
load balancing of services across multiple networks and processors. - 논문 p.83
The primary disadvantage of layered systems is that they add overhead and latency to the processing of data, reducing user-perceived performance [32]. For a network-based system that supports cache constraints, this can be offset by the benefits of shared caching at intermediaries. Placing shared caches at the boundaries of an organizational domain can result in significant performance benefits. - 논문 p.83
Although REST interaction is two-way, the large-grain data flows of hypermedia interaction can each be processed like a data-flow network, with filter components selectively applied to the data stream in order to transform the content as it passes. Within REST, intermediary components can actively transform the content of messages because the messages are self-descriptive and their semantics are visible to intermediaries. - 논문 p.84
Layered systems reduce coupling across multiple layers by hiding the inner layers from all except the adjacent outer layer, thus improving evolvability and reusability. - 논문 p.46
중요하다고 생각된 부분들만 인용해왔다.
먼저 Layer를 시스템 도입하면 시스템의 스케일을 키우는데 도움이 된다. 개인적으로 생각하기에는 클라이언트-서버 구조에서 사용되었던 설계 원칙인 관심사의 분리를 반복 적용하는 것이라 생각한다. 그래서 각각의 레이어들은 자신이 처리해야할 문제(관심사)가 제한된다. 그렇기에 하나의 전체 시스템의 복잡성을 낮출 수 있다고 생각한다.
그러나 이렇게 Layer를 시스템에 도입하면, Layer끼리 통신을 할 때 latency가 발생해서 전체 시스템에 Performance를 낮추게 되는 문제점이 발생한다. 이러한 문제점은 Layer 사이마다 공유 캐시를 도입함으로써 해결할 수 있다.
또한 Layer로 구성된 시스템은 마치 data flow를 통제하는 것처럼 hypermedia interaction도 전달되는 data stream을 선택 적용하여 전달되는 내용을 변경시킬 수도 있다. 또한 이렇게 변경될 수 있는 이유는 보내는 메세지가 self-descriptive하기 때문에 변경에 필요한 모든 내용이 포함되어 있기 때문이다.
또한 Layer를 도입하면서 Layer 간의 Coupling을 줄일 수 있다.
4. Cache
A cache acts as a mediator between client and server in which the responses to prior requests can, if they are considered cacheable, be reused in response to later requests that are equivalent and likely to result in a response identical to that in the cache if the request were to be forwarded to the server. - 논문 p.48
The advantage of adding cache constraints is that they have the potential to partially or completely eliminate some interactions, improving efficiency, scalability, and userperceived performance by reducing the average latency of a series of interactions. - 논문 p.80
Cache를 Web에 도입하게 되면 네트워크 비용을 줄일 수 있는 이점이 있다.
위에서도 언급했듯이 Layered System을 웹에 도입하게 되면, Layer마다 요청을 발생시켜야 하기 때문에 네트워크 비용이 높아진다. 이런 부분에서 공유 캐시를 이용하여 요청의 수를 줄여 네트워크 비용을 낮출 수 있다.
5. Stateless
The client-stateless-server style derives from client-server with the additional constraint that no session state is allowed on the server component. Each request from client to server must contain all of the information necessary to understand the request, and cannot take advantage of any stored context on the server. Session state is kept entirely on the client. - 논문 p.47
This constraint induces the properties of visibility, reliability, and scalability. Visibility is improved because a monitoring system does not have to look beyond a single request datum in order to determine the full nature of the request. Reliability is improved because it eases the task of recovering from partial failures [133]. Scalability is improved because not having to store state between requests allows the server component to quickly free resources, and further simplifies implementation because the server doesn’t have to manage resource usage across requests. 논문 p.47
Stateless는 서버가 클라이언트와 관련된 정보를 저장하지 않는 구조를 말한다.
이 구조를 통해서 얻을 수 있는 이 점은 visibility, reliability, scalability 세 가지이다.
Visibility는 서버는 클라이언트의 요청을 해석하기 위해서 단 하나의 메세지만을 보면 된다는 특성이다 즉, 바라봐야 하는 범위가 메세지 한 개로 제한되기 때문에 가시성이 향샹된다고 말할 수 있다.
Reliability는 서버가 단 하나의 메세지만 보기 때문에 요청을 실패하더라도 단 하나의 메세지만 실패를 하게 된다. 그래서 시스템 장애의 크기도 작아지기 때문에 안정성이 향상된다는 특징이다.
Scalability는 서버가 클라이언트의 정보를 저장하지 않기 때문에 여러 클라이언트를 다룰 수 있다는 특징이다. 그래서 시스템의 크기를 키울 수 있다.
6. Code-on-Demand
In the code-on-demand style [50], a client component has access to a set of resources, but not the know-how on how to process them. It sends a request to a remote server for the code representing that know-how, receives that code, and executes it locally. - 논문 p.53
The advantages of code-on-demand include the ability to add features to a deployed client, which provides for improved extensibility and configurability, and better userperceived performance and efficiency when the code can adapt its actions to the client’s environment and interact with the user locally rather than through remote interactions. - 논문 p.53
code-on-demand란 실행 가능한 프로그램을 서버에게 요청할 수 있는 특징이다. 이 특징은 클라이언트에게 더 특화된 기능을 제공할 수 있다. 그러나 이 특징은 선택 사항이다.
참고자료
- https://medium.com/future-vision/what-are-the-constraints-of-rest-and-how-they-saved-the-internet-6fb8503138ab
- https://ko.wikipedia.org/wiki/REST
- http://info.cern.ch/hypertext/WWW/TheProject.html
- https://www.w3.org/DesignIssues/Axioms.html#opaque
- https://shoark7.github.io/programming/knowledge/what-is-rest
- "Architectural Styles and the Design of Network-based Software Architectures" - by Roy Fielding
- REST API Design Rulebook - PUBLISHED BY: O'Reilly Media, Inc.
