지난번에 Monolithic과 MSA이에 대해 알아보았다.이번에는 MSA를 사용할 때 필요한 기술에 대해 공부해볼 예정이다.
(해당 글을 작성하면서 느낀건 MSA 정말 적용하기가 어려운 것 같고...일단은 정말 간단하게 어떤 기술이 필요한지 작성되어 있기 때문에 해보면서 더 정확하게 파악해야겠다는 생각이 든다..😭)
MSA를 사용하기 위해서는 무슨 역량이 필요해?
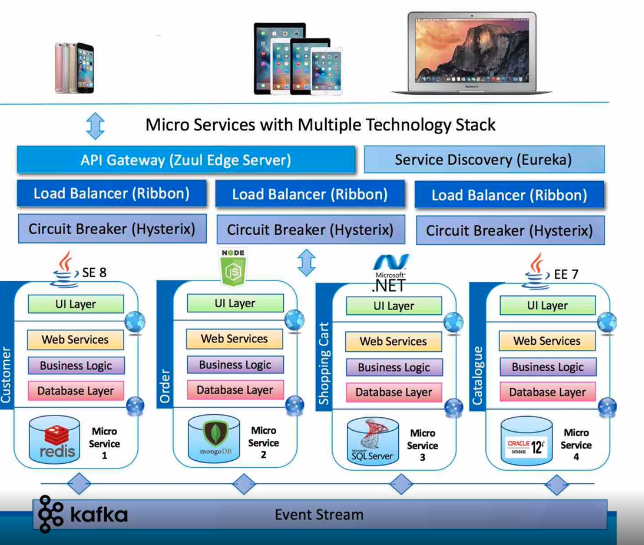
Service Discovery
MSA를 도입하게 되면 서비스 개수 및 인스턴스 개수가 급증한다. 한 서비스에서 다른 서비스 호출 시 물리적인 정보를 유지하는 것이 비효율적이다.
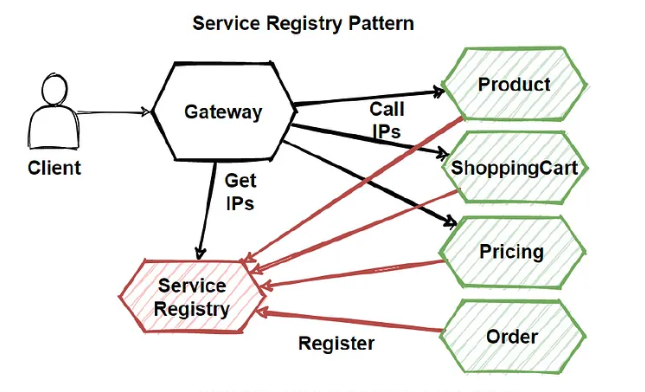
따라서 중앙에서 시스템의 모든 서비스에 대한 정보를 유지하고, 새로운 인스턴스가 생성되면 중앙 에이전트에게 자신의 정보를 등록한다. (자동으로 등록)
서비스 간에는 다른 서비스의 물리적인 주소를 유지하지 않기에 유연하게 인스턴스 및 서비스를 추가 삭제 가능하게 한다.
Config Server
기존에는 설정 정보를 자체 설정 파일이나 OS 환경 변수로 관리를 했는데 MSA 도입 시 설정 관리가 굉장히 복잡해진다. 환경마다 매번 새롭게 빌드/패키징을 해야 하고, 인스턴스마다 재배포가 필요하다.
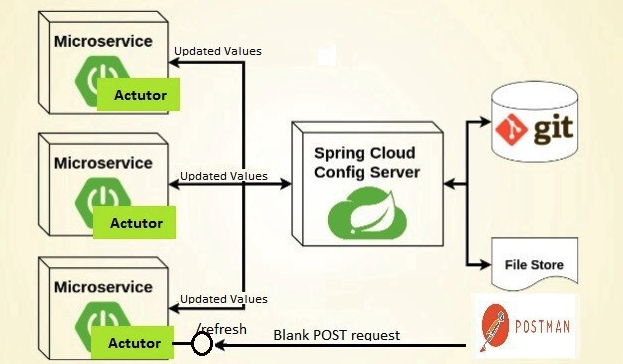
따라서 설정 정보를 중앙 Config Server에서 관리하고 저장 Backend로는 Git, DBMS 등을 사용한다. 서비스는 Application이 기동될 때 중앙 서버에서 Config 정보를 Fetch해서 사용한다.
Service Gateway
다양한 서비스에 대한 단일 진입 점이 된다.공통적인 로직을 Service Gateway에서 처리하고 라우팅을 통해준다. 서비스에 문제가 발생 시 요청을 차단하거나 대안 경로를 변경하는 등의 기능을 수행한다.
SW Defined Load Balancer
MSA에서는 인프라 토폴로지가 매우 복잡하다. 따라서 전통적인 로드밸런서를 사용하는 것은 비효율 적이다.(전통적인 로드 밸런서는 뒷단의 인스턴스의 IP를 모두 등록하고 사용하기 때문)
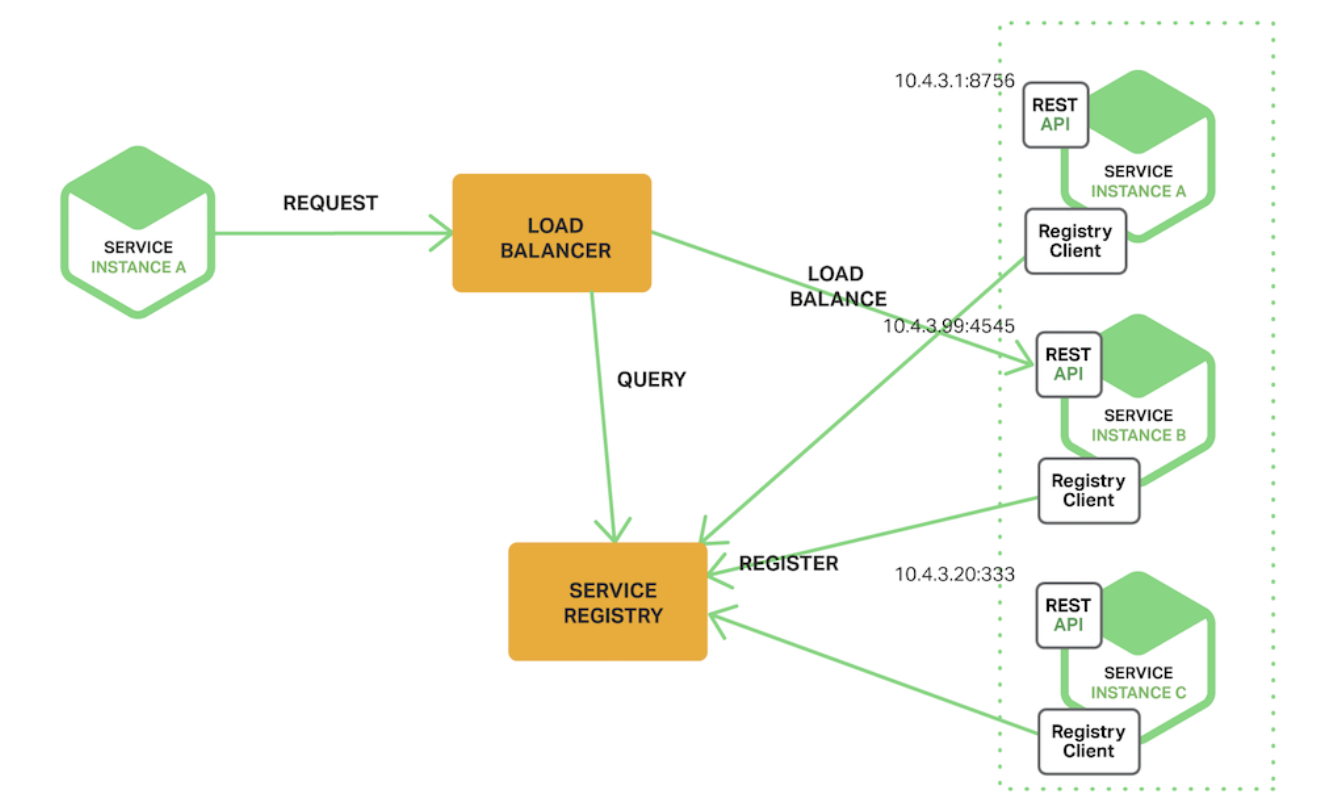
서비스를 호출하는 클라이언트에서 SW로 Load Balancing을 수행한다.
Service Registry를 활용해서 SW Load Balancer가 로드밸런싱을 수행한다.
Circuit Breaker
서비스의 장애는 언제든 발생이 가능하고 MSA에서 한 서비스의 장애는 다른 서비스들에게 전파되어 결국 전체 시스템 장애로 이어질 수 있다.
따라서 특정 서비스의 장애는 그 서비스 만의 장애로 격리시켜야 한다.
-> 서비스 간의 Circuit Breaker라는 컴포넌트가 삽입되어 특정 서비스의 장애가 발생했다고 판단되면 Circuit 차단시켜버린다.
Distributed Tracing
하나의 API 호출이 다양한 서비스에 분산되므로 에러 추적이 어렵다. 장애 발생 시 어떤 서비스에서 장애가 시작되었는지 판단이 어렵기 때문이다.
따라서 서비스 간 모든 호출에 추적 ID를 삽입하고, 추적 ID를 key로 하여 단일 API 트랜잭션의 활동을 파악하도록 한다.
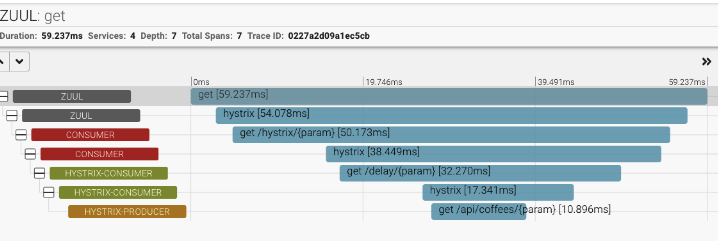
Zipkin을 사용한 예시이다.
Data Lake
MSA에서는 데이터 파편화 가능성이 존재한다.
따라서 비정형 원시 데이터를 그대로 저장한다(?) 데이터를 분석할 시점에 데이터 가공에 대해 고민한다. 전통적인 ETL이 아닌 실시간 Data Ingestion 도구를 사용한다.
Flume, Kafka, Logstash등이 있다.
Messaging
MSA는 메시징을 이용한 서비스간 협력 설계 방식을 권고한다.(동기식 방식 보다는 비동기식)
메시징 주도 설계는 서비스 간 결합도를 낮출수 있기 때문이다.
RabbitMQ, ActiveMQ, Kafka, AWS Kinesis 등이 있다.
참고
마이크로서비스 아키텍처의 핵심개념과 핵심 기술 및 아키텍처 패턴, MSA(MicroService Architecture)
