# MySQL 구조, 설정
MySQL 구조, 설정
MySQL 몇가지 특성
- Nested Loop Join 만 가능
- HASH 나 이런건 플러그인을 설치하든 외부에서 작성된것을 Import
- 이 조인만 가능하다는 것은 외부 테이블 건수에 따라서 처리해야할 대상이 많아짐, 적절한 드라이빙 테이블 대상을 선정해야함
(선행 테이블 사이즈 * 후행 테이블 접근횟수) - 두테이블에 조인컬럼에 인덱스를 무조건 고려해야함
- "대량 데이터 처리에 적합한 JOIN 은아님"
- 단일 코어에서 쿼리 처리
- CPU 코어 개수를 늘리는 튜닝보다, 작업을 병렬처리가 아닌 직렬로 하기때문에, 코어를 강력한것으로 쓰는게 좋음
- 엔진을 선택할 수 있음
- MySQL 스토리지 엔진이 구분되어 원하는 특성에 맞게 엔진 사용이 가능
- 비교적 손쉬운 비동기 이중화가 가능하기 때문에 스케일아웃에 적합함
- MVCC
- 목적은 잠금을 사용하지 않는 일관된 읽기를 하는 데 있다.
- 동시성 처리를 위해 잠금을 걸지 않고, Undo 로그에 기록되어있는 데이터값을 그대로 읽어온다. 이것이 여러버전이면, 일관성, 동시성이 보장됨
MySQL 엔진 + 스토리지 엔진
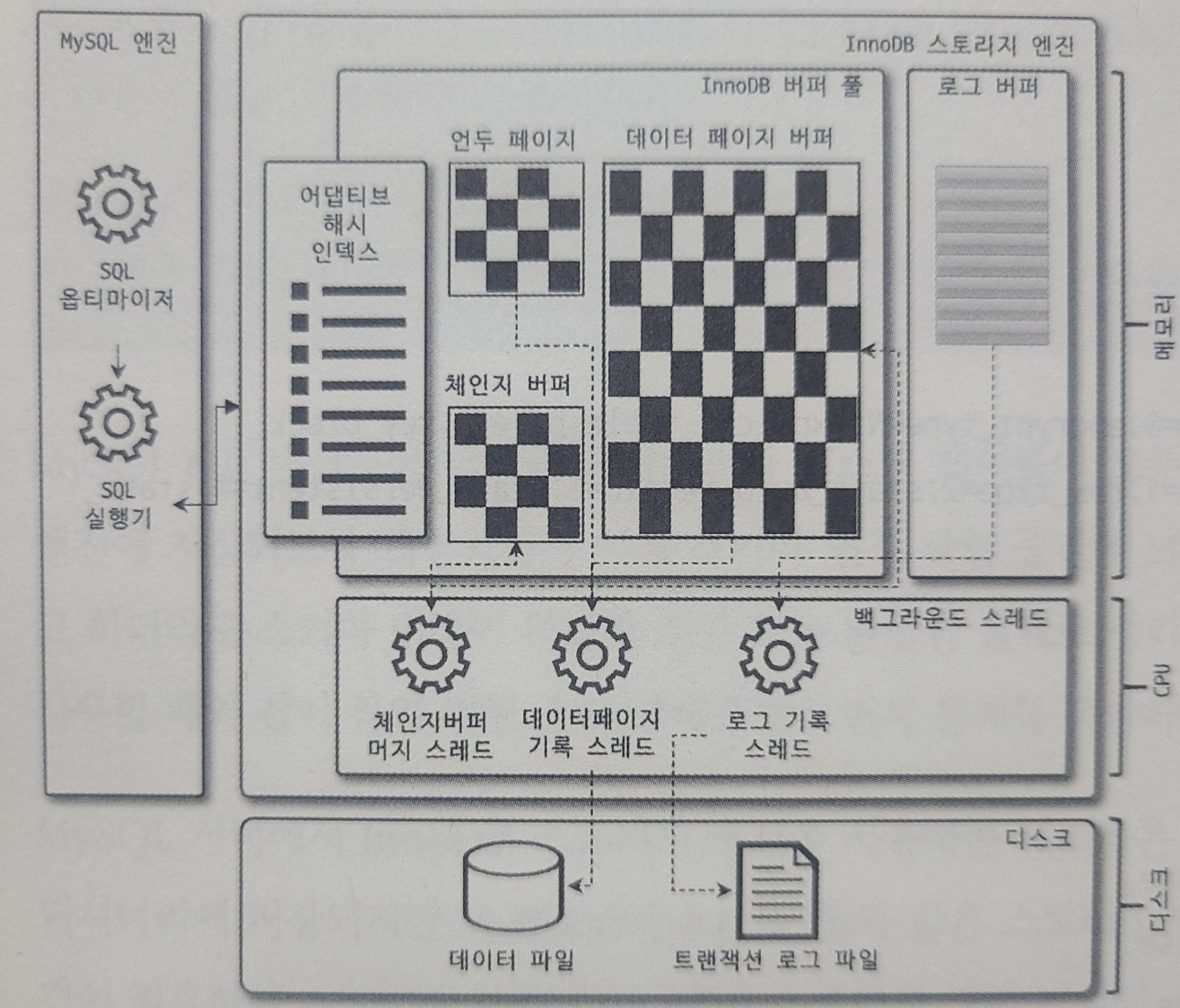
- 포어그라운드 스레드(주로 사용자 데이터 처리)
쿼리를 요청하면 MySQL 엔진에서 커넥션 핸들러가 커넥션과 인증처리
--> SQL 인터페이스를 통해 처리 방식을 제공받고
--> "SQL Parser"를 통해 문법오류 파악하고 그것이 문제가 없으면(syntax)
내부에서 처리하기 좋게 트리(토큰) 형식으로 변경
--> 전 처리기가 파서 트리를 보고 구조적(메타정보 확인, 컬럼 유무,권한 유무)
문제가 있는지 파악
--> SQL 옵티마이저가 통계를 참고하여 수행계획을 세움
--> 수행 계획대로 접근하여 스토리지 엔진을 통해 데이터를 가져옴 - 백그라운드 스레드(그 밖의 유지보수 작업)
--> change buffer/ log buffer / deadlock monitor / dirty memory buffer를 쓰고 지우거나
메모리 & 파일 구조
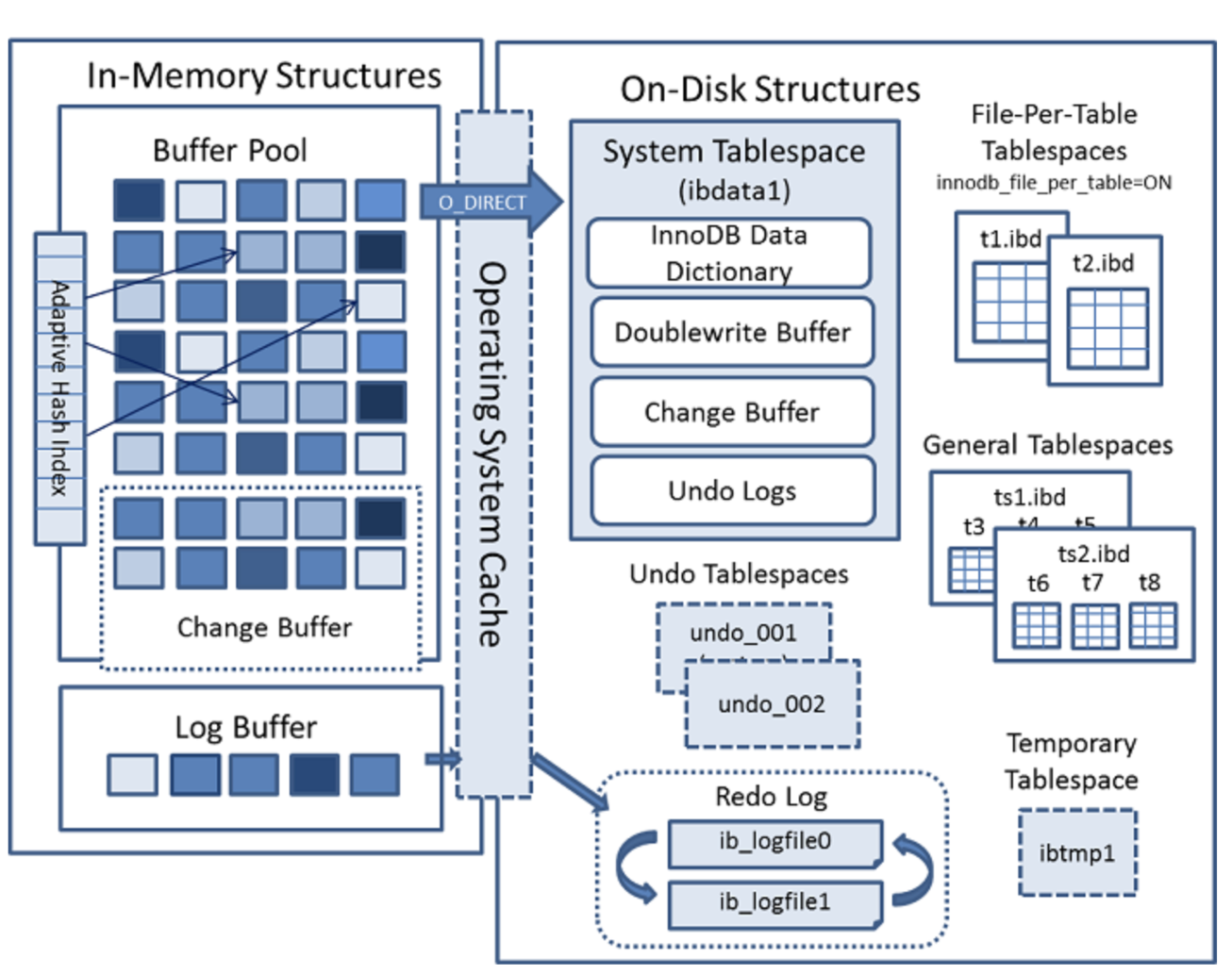
-
Adaptive_Hash_Index
B-Tree의 탐색 비효율(보조 인덱스를 수행할때 어차피 키를 찾고 다시 서칭해야하는
이슈나 밸런스가 깨져서 효율적인 탐색이 불가한 상태에서의 검색)
을 극복하기 위해, 인덱스에 자주 사용되는 데이터를 해쉬로 가지고있음
이것은 MySQL이 판단해서 해시로 가지고 있는 값이고 어떤 것을 태울지 모름, 탈때는 수행속도가 아주 빠르고 효율적임 옵션으로 제어 가능.테이블 DROP 시 해당 인덱스도 삭제되기때문에이슈 발생(성능 영향) 여지 있음
-
Change Buffer==Insert Buffer
보조 인덱스의 변경에 고비용에 대비한 영역, "데이터 버퍼에서 해당 인덱스에 데이터가 없으면"
디스크로 가는것이 아닌 버퍼를 활용하여 비용을 줄임 -
Redo Log
변경된 페이지의 트랜잭션 내용이 메모리에 상존하다가 갑자기 서버가 크래시나 다운이 되어
디스크에 채 쓰지 못하는 상황이 발생할때, 대비하도록 Redo Log가 설정값으로 주기적으로 기록(log buffer 내 redo buffer에 선 기록 후 디스크로) 딱 FLUSH 직전 변경분만 가지고있음 -
Undo Log
데이터의 변경 직전 데이터를 보관하는데, MVCC 사용을 위한 장치
동시성을 향상시키나 변경시 버퍼 내 메모리 리소스를 사용하고 파일에 작성하므로
트랜잭션 지연(롱 트랜잭션)이나, 대용량일 경우 문제(메모리 경합)가 더욱 커질수 있음
메모리에 의존하여 계속해서 사용량을 증가시키거나 리소스를 사용하므로 때문에,
등장한것이 5.7에 Undo 테이블 스페이스 역시 log buffer 내 undo log buffer 를 먼저 쓰고
파일을 씀 -
Double Write Buffer
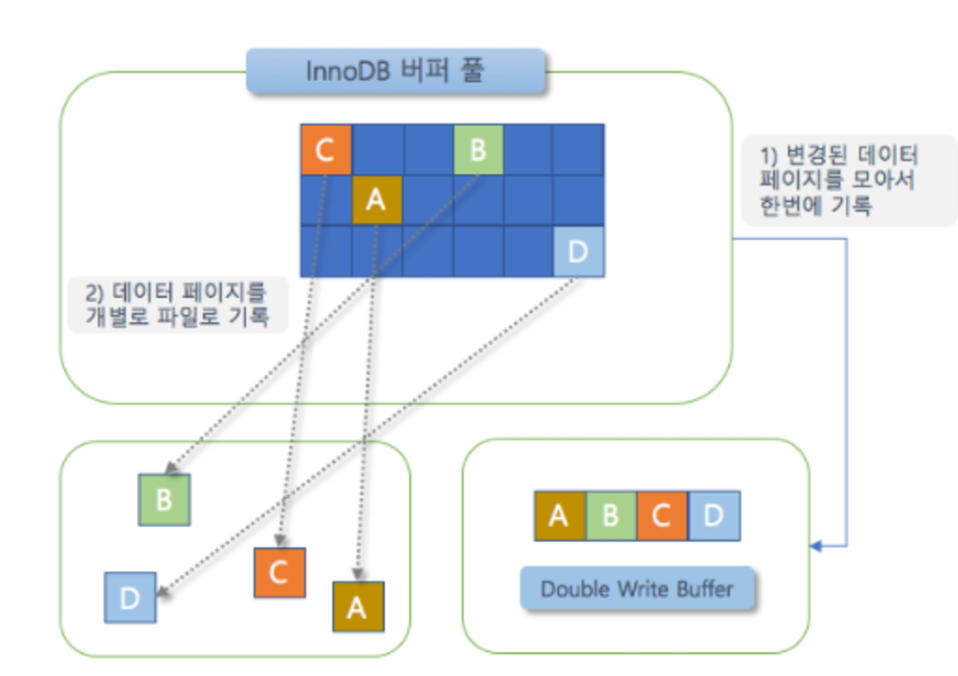
5%~10% 성능 손해를 감수하고 메모리에서 FLUSH 된 "데이터"를
이곳에도 저장하여, OS에 디스크 쓰기 단위가 달라 발생하는 충돌이나 장애 발생하여 "디스크에 변경이력을 저장하지 못했을때" 이곳에서 대조해서 복구
InnoDB 특징
- Key 기반의 Clustering
- Row-level 기반 잠금
- ACID 트랜잭션 처리를 위한 고안(Commit/Rollback, 제약조건, 잠금)
- 동시성 향상을 위한 잠금이 필요없는 일관된 읽기(MVCC)
- 데드락 모니터링
- 데이터가 복원하기 좋게 영구적으로 보관되므로 포랜식에 가치가 있음
