💡 오늘도 javascript가 안된다고 했다
최근에 드로잉 관련한 기능 하나를 개발하고 있던 도중, 에러가 발생했는데 이것을 제대로 캐치하지 않아서 앱이 터지는 상황이 벌어졌었다.
사실 IndexedDB라는 것을 처음 사용하다보니, 이 녀석이 가지고 있는 onError 콜백 핸들러가 당연히 에러를 잡아줄거라고 생각했던 것이 바보였다.
const saveTransaction = (tableName: string, data: any, type: 'put' | 'add' = 'add') => {
if (database === null) {
throw new Error('no database');
}
const transaction = database.transaction(tableName, 'readwrite');
const table = transaction.objectStore(tableName);
const request = type === 'add' ? table.add(data) : table.put(data);
request.onsuccess = () => console.log('save success');
request.onerror = (e) => {
console.error('no suffient space to save data');
setMemoImpossible();
};
}위 코드는 드로잉했던 내용을 Save하는 로직이 담겨있는 핸들러이다.
IndexedDB는 간단히 설명하면 웹에서 사용할 수 있는 데이터 스토리지로, 다음과 같은 장점이 있다.
- 로컬 스토리지와 다르게 저장 공간이 브라우저별로 상이하지만 매우 크고 직렬화 불가능한 값들을 제외한 거의 모든 값들을 저장할 수 있다.
- Key-Value로 이루어진 B-tree 자료구조의 Database형태를 띄고 있고, transaction 개념을 통해 안전하게 데이터를 CRUD 하는 것이 가능하다.
- 거의 영속적으로 데이터가 저장되어 클라이언트별로 각자 독립적인 데이터를 유지할 수 있다.
IndexedDB에 대한 더 자세한 설명은 구글 성님의 웹 스토리지들에 대한 설명 을 참조하면 좋다
여기서 문제점은 위 코드에서 보이는 "database.transaction(tableName, 'readwrite');" 와 같은 코드들에 있다.
위에서도 언급했듯이, IndexedDB는 Transaction을 기반으로 데이터를 관리하는 시스템이다.
Transaction이란 항상 성공하거나, 항상 실패해야 하는 로직들의 단위 모음이다.
(예를 들어, 결제하기를 실행한다면 "데이터조회 => 잔액 확인 => 결제 확인 => 결제 결과 저장" 처럼 모든 프로세스가 하나라도 실패할 경우 전부 실패로 여겨져서 롤백되어야 하는 것과 같이 하나의 단위로 로직들이 연결되어 처리되는 구조를 뜻한다)
그런데 우연하게 인자로 잘못된 값이 들어가도 onError가 잡아주는지 확인해보고 싶어서
database.transaction('none', 'readwrite') // 없는 테이블 네임으로 트렌잭션 인스턴스 초기화해봄.위의 방식으로 코드를 짜서 save 를 호출해봤더니 웬걸?
시원하게 터져버리는 것이었다.
💡 너무나 당연한 소리긴 했지만
애초에 잘못된 인자가 들어갔을 때 함수가 호출을 실패해서 throw를 던져질 것임을 인식했어야 했던 것을, onError 콜백 핸들러가 있으니 알아서 해주겠지 뭐(후비적) 하고 안일하게 생각했던 내가 바보였다.
그런데 이를 해결하려고 보니, 조금 문제점이 발생하였다.
단순하게 try~catch를 사용하려고 보니, 코드가 너무 지저분하고 난잡해져서 읽기가 점점 어려워지는 상황이 벌어지는 것이다.

예전에 Backend 결제시스템 관련 라우터를 작성할때도 느꼈던 것이지만, 각 로직별로 try~catch 가 존재해버리면 블록 스코프의 한계점으로 인해 스코프 바깥에서 해당 값을 읽어들이기 위해서는 저렇게 비효율적인 변수 선언이 반복되야 하는 상황이 발생했다.
저기 저 위에 let들의 더미들이 보이는가... 저게 과연 한두개가 아니라 수십개가 되는 순간이 오면? 생각만해도 끔찍하다.
그래서, 이런 식으로 각 에러가 발생할 지점을 관리하는 것이 너무 불만족스러웠던 터라 아예 함수블록 하나에 Try~catch를 두고, 모든 catch문에서 에러를 통합관리하자는 이야기가 있었었다.
그런데, 그것 역시 너무 지저분하기 그지없다.
사실 내가 판단할 수 있는 에러 외에도 너무나 많은 에러가 존재하고, 이것을 처리할 로직을 다 catch에 때려박고 있으니 점점 확인이 어려워져가는 문제점이 발생하는 것이었다.

includes의 빨간줄은 살짝 눈감고 지나가주시길... 현재 프로젝트 폴더에 모듈 설치를 안해놓은 상태라서 그렇다.
여튼, 위의 사진에서 보면 알 수 있지만 생각해야 할 에러가 많아지면 많아질수록 catch블록 역시 점점 지저분해지기 시작한다.
정작 내가 하고 싶은 건, 각 에러가 예상되는 지점의 로직별로 제각각의 에러 핸들링을 하도록 만들고 외부 로직과 에러 핸들링에 대한 관심사를 분리하는 것이 목표였던 것이다.
💡 모든 경험은 개발의 아하모먼트가 된다
그러면 어떤 식으로 에러를 핸들링하는 게 가장 깔끔한 로직이 될 것인가.. 에 대하여 고민하던 도중,최근에 원티드 프리온보딩 with Next.js를 신청해서 들었던 강의내용 중 떠오른게 있었다.
내용 중 과제로 SPA router 직접구현하는 커리큘럼이 있었다.
root.render(
<Router>
<Routes>
<Route path="/" component={<Root />} />
<Route path="/about" component={<About />} />
</Routes>
</Router>
);해당 구현을 하면서 염두해둬야 했던 핵심은 아래와 같았다.
1. Route는 props로 자신의 경로에 대한 path 값과, 리턴해줄 컴포넌트를 건네받는 컴포넌트이다. (순수함수, 딱 그 역할만 한다.)
2. Routes는 현재 Path를 보고 어떤 자식을 랜더링해야 할 지를 담당한다.
3. Router은 경로변경을 감지하고 이를 window API를 활용하여 브라우저의 path를 변경하고 이 값을 자식들에게 전파하는 역할을 한다.
이 과제를 하기 전까지는, 관심사분리 라는 개념에 대해서 머릿속에 넣어두기만 하고
"응 그래 관심사 분리해야지 허허허허" 라는 느낌처럼 개발을 해왔다가,
이 경험을 토대로 진짜 역량이 부족해서 티끌만큼이었지만 그래도 관심사 분리가 얼마나 중요한 것인지를 깨닫는 "아하 모먼트"를 겪게 되었다.
실제 라우팅 시스템은 나중에 추가되게 되는 SSR의 환경에서도 사용될 수 있어야 하기 때문에 더욱 관심사가 분리되어야 작성되어가고, 그 덕택에 확장이 가능하다는 설명을 듣고 나서 더욱 더 그러하였다.
그리고 나서 이 경험이 갑자기 머릿속에 떠올라서 에러 핸들링도 이렇게 관심사가 분리되어서 작성되면 되지 않을까 하는 생각이 들게 되었다.
즉, 애초부터 실제 로직 부분에서는 에러 핸들링과 관련한 로직들이 try~catch로 노출되어 있을 필요성이 굳이 있을까... 하는 생각이 든 것이다.
그럴 필요가 없다면, 각 로직의 에러 핸들링에 대한 담당 부분은 마치 은닉화처럼 내부 로직으로 스며들어 있고, 실제 개발자가 관심을 가져야 하는 것은 외부로 노출되는 로직만 남겨져있으면 된다는 생각이 들었다.
💡 거두절미하고 구현은 아래와 같다
📦 src
├── 📂 Error
│ ├── 📄 index.ts
│ └── 📄 indexedDB.ts
// index.ts
export type BaseErrorCase<T> = (err: Error & { name: T }) => Error; // 호출당시가 아닌, 할당 내용에 타입정의이므로 할당하는 장소에서 타입 정의해야 함 (generic T 위치가 좌측). 공적사용을 위해 index.ts에서 export함
export type Closure = <T extends (...args: any) => any>(targetFunc: T) => ReturnType<T>; // 호출 당시 타입이 인자에 의해 정해지므로, T를 extends할 때 일반화 타입으로 확장함. (generic T 위치가 우측)
export class CustomError extends Error { //커스텀 에러 객체를 만드는 클래스
constructor(readonly message: string, public name: string) {
super(message);
this.name = name;
}
}
export const customErrHandlerGenerator = (targetErrName: string, message: string = '') =>
((targetFunc) => {
// customErrWrapperGenerator은 CustomError을 생성해 내보내는 관심사를 담당한다.
try {
return targetFunc();
} catch (err) {
throw new CustomError(message, targetErrName); // 받아오는 에러객체가 아닌, 커스텀 에러객체를 throw
}
}) as Closure;
export const customErrorBoundaryGenerator =
(errorCase: (err: Error) => void) => (customErrHandler: ReturnType<typeof customErrHandlerGenerator>) =>
((targetFunc) => {
// customErrorBoundaryGenerator는 customError의 분기를 처리하는 관심사를 담당한다.
try {
return customErrHandler(targetFunc);
} catch (err) {
errorCase(err);
}
}) as Closure;
🕹 <index.ts>
index.ts에는 공통 에러를 만들어주는 로직들을 장착하였다.
CustomError 클래스는 단순하게 message와 name을 받아서 "내가 관리하고자 마음먹은 name을 가진 에러객체" 를 생성하는 관심을 담당한다.
커스텀 에러 객체와 관련한 내용은 커스텀 에러 만들어보기 를 읽어보다가 힌트를 얻었다.
customErrHandlerGenerator 함수와 customErrorBoundaryGenerator 함수는 커링 함수와 관련된 내용을 읽어보다가 힌트를 얻었다.
두 함수가 갖는 관심사는 아래와 같았다.
- customErrHandlerGenerator의 관심사 : CustomError 클래스를 참조하여 스코프 체인으로 가지고 있다가, 호출되는 시점에서 해당 작업이 실패할 경우 커스텀 에러를 생성하여 throw하는 클로져를 리턴한다.
- customErrorBoundaryGenerator의 관심사 : 인자로 받을 errorCase를 참조하여 스코프 체인으로 가지고 있다가, 호출되는 시점에서 헬퍼 함수로 받게 되는 customErrHandler가 실패할 경우 가지고 있던 errorCase 함수를 호출해서 적절한 처리를 하는 클로져를 리턴한다.
결국은,
- 커스텀 에러를 만들어서 이것을 throw하는 로직과 (마치 Route처럼)
- 전파되는 에러 객체를 캐치하여 처리하는 로직 (마치 Routes처럼)
위에 적어놓고 보니 무슨 소린가 싶은데, 이것들을 모듈로 가져와 확장하는 측(indexedDB.ts)을 보면 더 이해가기가 쉽다.
참고로 커링함수로 작성한 이유도 외부 컨텍스트에 존재하는 내용을 갖고 있다가 모듈로서 import되어 사용될 때 참조될 수 있도록 하려고 해서 만들어진 형태이다.
🕹 <indexedDB.ts>
import { BaseErrorCase, customErrHandlerGenerator, customErrorBoundaryGenerator } from 'Error';
type ErrorName = (typeof errorNameEnum)[keyof typeof errorNameEnum];
type ErrorCase = BaseErrorCase<ErrorName>;
const errorNameEnum = {
transactionError: 'transactionError',
objectStoreError: 'objectStoreError',
} as const;
const errorCase: ErrorCase = (err) => {
if (err.name === 'transactionError') {
console.error(`${err.name} 이 발생했습니다`, err);
}
if (err.name === 'objectStoreError') {
console.error(`${err.name} 이 발생했습니다`, err);
}
throw err; //무조건 err를 다시 던지게 하여, 부모 로직에서 이 함수 호출 이후의 로직을 하지 않도록 block한다.
};
const customErrorBoundary = customErrorBoundaryGenerator(errorCase); // errorCase는 공통분모인 분기점이므로, 한번만 스코프 환경에 등록하고 이후는 리턴되는 함수를 재활용한다.
export const handleTransactionErr = customErrorBoundary(customErrHandlerGenerator(errorNameEnum.transactionError));
export const handleObjectStoreErr = customErrorBoundary(customErrHandlerGenerator(errorNameEnum.objectStoreError));
각 파일에는 어떤 에러들을 내가 직접 타겟팅하여 관리할 것인지에 대한 내용이 작성되어 있다.
위에 작성했던 것처럼, customErrorBoundaryGenerator은 인자로 에러케이스를 받아서 이것을 컨텍스트적으로 가지고 있는다.
리턴되는 함수는
// 외부 스코프 환경에는 errorCase 함수가 참조되고 있음.
const customErrorBoundary = (customErrHandler: ReturnType<typeof customErrHandlerGenerator>) =>
((targetFunc) => {
try {
return customErrHandler(targetFunc);
} catch (err) {
errorCase(err);
}
}) as Closure;가 된다. 이제 해당 함수로 래핑할 경우, 리턴되는 함수는 자식으로부터 throw하여 전파되는 커스텀 에러객체를 errorCase로 처리가 가능한 클로저가 된다.
그리고 래핑한 내용들이 바로
export const handleTransactionErr = customErrorBoundary(customErrHandlerGenerator(errorNameEnum.transactionError));
export const handleObjectStoreErr = customErrorBoundary(customErrHandlerGenerator(errorNameEnum.objectStoreError));가 되는 것이다.
이제 이 함수를 모듈로 export하여 내가 직접 타겟팅하여 관리하길 원하는 로직에 감싸주면 된다.
사용되는 측에서는 더이상 불필요한 try~catch 로직을 볼 필요가 없어졌다.
래핑하는 함수가 그 관심사를 처리해주는 것이다!
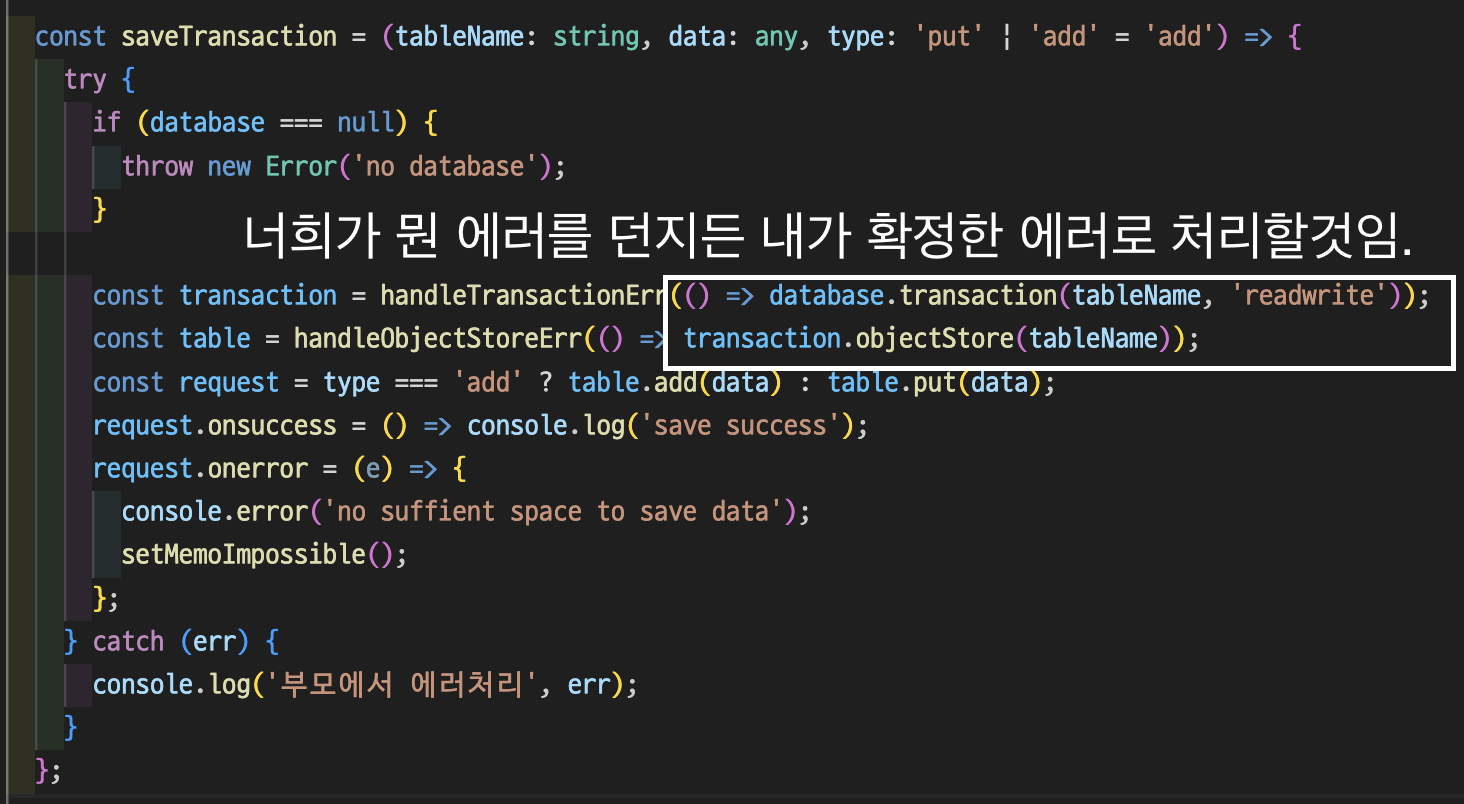
이렇게 에러를 처리했을 경우 가장 큰 장점은 역시 개인적으로 불필요한 관심사가 노출되지 않는다는 장점도 있지만 더 큰 것은, 내가 어떤 에러를 알아야 하는지를 알 필요가 없어진다는 점이다.
애초에 저 database.transaction이 실패했을 때 만들어지는 err객체의 타입이 무엇인지 나는 신경쓸 필요가없다. 왜냐면 걔가 뭘 던지든 말든 나는
// customErrHandlerGenerator
try {
return targetFunc();
} catch (err) { //너가 뭘 던지든간에...
throw new CustomError(message, targetErrName); // 받아오는 에러객체가 아닌, 커스텀 에러객체를 throw
}이러기 때문이다. 예전 백엔드 로직때 하나하나 케이스를 다 확인하면서 분기처리했던 고통을 다시금 기억하며, 현재 로직에 아주 뿌듯함을 느낀다.
💡 맺음글
아직 보완점이 많은 로직이지만, 그래도 필요한 목적을 달성한 것 같아서 너무 마음에 든다.
그리고 이렇게 정리하고 보니까 느끼는 것이지만, 개발자로서 어떤 공부를 하든 어떤 로직을 작성하게 되든 그것은 다 발전의 양분으로 쓰이게 된다는 사실을 다시금 깨닫게 된다.
오랜만에 개발새싹에 물을 주게 되는 시간이었다.


뛰어난 글이네요, 감사합니다.