
왜 DB 테이블이 들어올 때 인덱스로 들어와야 할까요?
사실 그저 어그로성 제목이었고 필요에 따라 인덱스를 적용해야합니다.
그럼 여러분은 인덱스를 잘 아시나요?
여러분이 만약에 책에서 특정 내용을 찾을 때 생각해봅시다. 바로 책 목차부터 보지 않으시나요? 그거와 똑같습니다.
결국 데이터를 빠르게 조회하기 위해서 인덱스(책의 목차)를 통해 데이터를 조회한다고 생각하면 됩니다.
그럼 함께 알아가봅시다 🙌🏻
인덱스
B-Tree
아주 흔히들 아는 그 인덱스 맞습니다. B 트리 인덱스는 균형 잡힌 트리구조(Balanced Tree)를 사용해서 데이터를 저장하는 게 특징입니다.
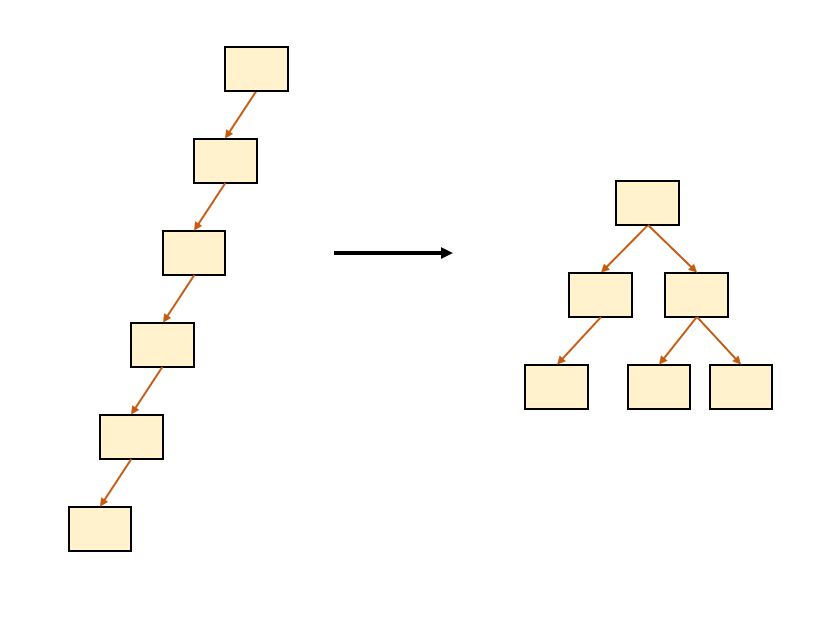
이 그림만 봐도 데이터를 탐색할 때 우측 트리 구조를 활용한다면 데이터를 찾을 때 탐색해야 하는 데이터 범위가 줄어들겠죠? 좌측이라면 O(N)의 시간이 걸렸지만 트리 구조를 활용한다면 O(logN)의 시간이 보장됩니다.
충분히 좋아보이죠?
하지만 B-Tree 안씁니다.
B-Tree 왜 안 쓰는데?
B-Tree는 균형 트리입니다.

자꾸 데이터가 INSERT되고 UPDATE되고.. DELETE 되다보니 계속 데이터를 가진 트리 구조가 점점 균형을 잃게 됩니다.
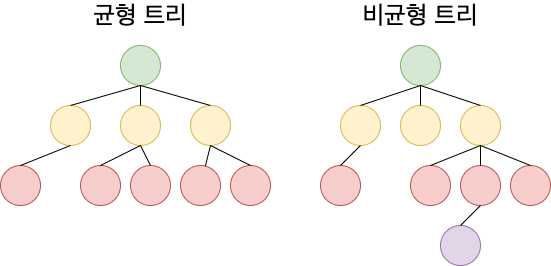
균형 트리란 루트로부터 리프까지의 거리가 일정한 트리 구조를 뜻하는 건데.. 우측처럼 깨지면 무슨 소용입니까.
O(logN)의 시간이 걸려서 좋았던 건데 점점 O(N)에 가까워지게 됩니다.
뭐 어느 정도 균형을 회복할 수야 있지만 품이 너무 많이 드는 거죠. 그 돈이면 읍읍이 되는 겁니다
거기에 B-Tree는 모든 노드에 데이터가 들어갑니다. 테이블에 데이터가 1-100을 가진다고 하면 11-18까지 범위 탐색을 한다고 했을 때, B-Tree는 해당 범위에 속하는 노드들을 하나씩 찾아야 하므로 탐색 범위가 넓어집니다.

???: 그럼 대체 뭐 쓰는데요?
아니 이 b트리들이, 미안하지만 b+ 트리들이
B+Tree 씁니다. 사실 B+Tree는 B Tree 확장 개념입니다. ~깔깔~ 어쨌든 다른 건 맞잖아요?
B+Tree
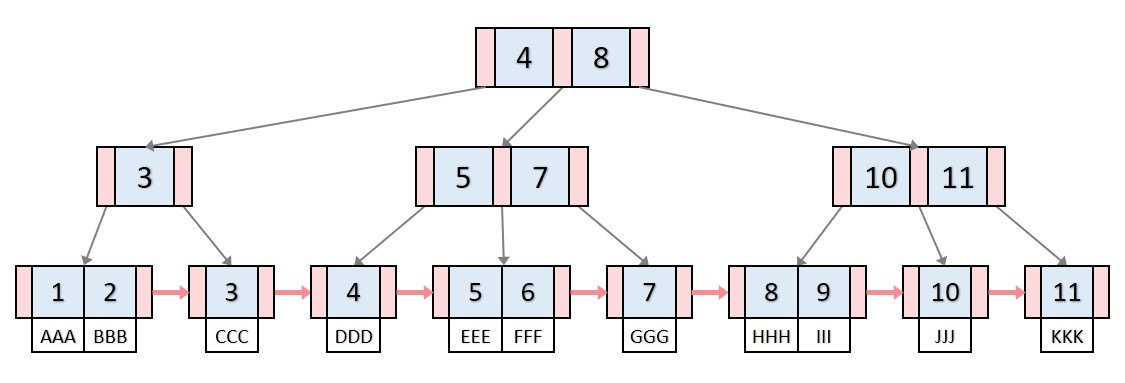
B+Tree는 가장 큰 특징은 가장 밑에 존재하는 노드인 리프노드에만 실데이터가 위치하게 됩니다.
앞서 말한 B-Tree는 범위 탐색에서 성능 저하가 일어난다고 했죠? 여긴 훨씬 뛰어난 성능을 보여줍니다.
왜냐면, 특정 범위(e.g. 11-18)의 데이터를 탐색할 때 시작 리프 노드를 찾은 후, 링크드 리스트처럼 연결된 리프 노드만 따라가면 되기 때문에 효율적입니다.
좀 더 깊게 들어가자면, 데이터베이스는 최종적으로 하드디스크에 데이터를 적재하고자 합니다.
여기서 하드디스크에 데이터를 저장할 때 디스크 페이지 단위로 읽고 쓰는데 리프 노드가 이 디스크 페이지와 일대일로 매칭되도록 설계할 수 있습니다. 즉, 리프 노드에 필요한 데이터가 가득 채워져 디스크 페이지 크기와 맞아떨어지게 하면, 한 번에 필요한 데이터를 블록 단위로 불러올 수 있습니다.
결국, 디스크 파편화까지 줄일 수 있다는 사실!

앗! B+트리 B트리보다 싸다!
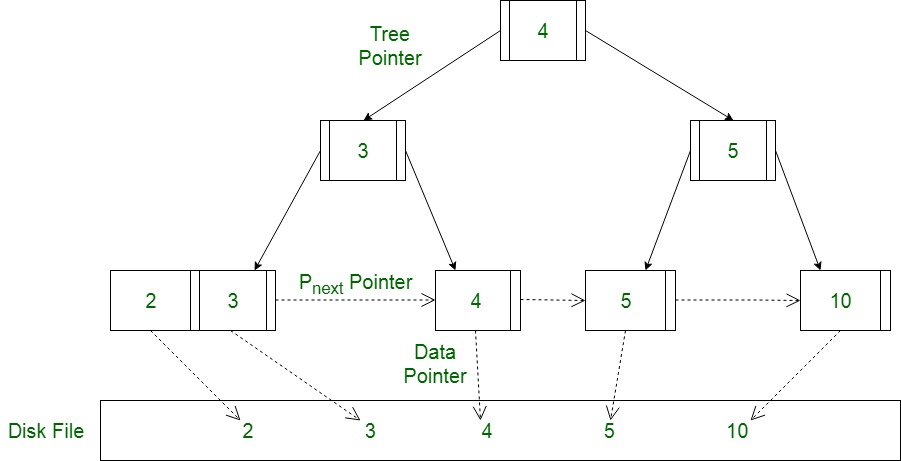
또한, B+Tree를 사용하면 리프 노드 간에 데이터가 연속적이므로 순차 접근을 통해 디스크 페이지의 데이터를 순서대로 빠르게 읽어들일 수 있습니다. 데이터베이스가 데이터를 검색할 때 필요한 디스크 페이지가 죄다 미리 정렬된 상태로 존재하므로, 디스크에서 불필요하게 탐색할 일이 줄어드는 것이죠. (짧게 말하면, ‘낮은 랜덤 I/O 비용 ‘라고 정도로 줄일 수 있겠군요.)
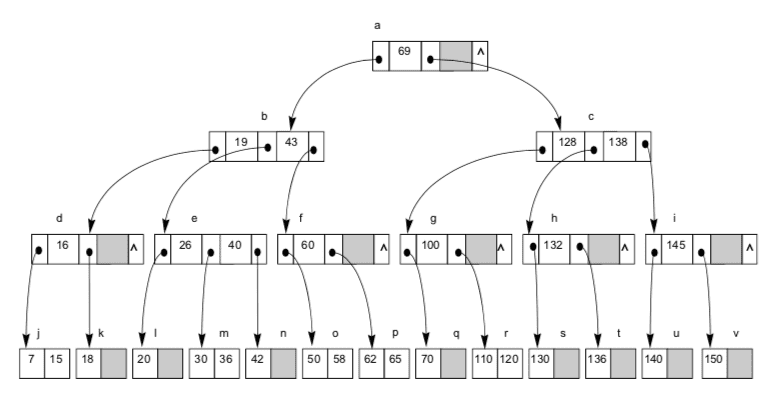
거기에 B+Tree는 트리의 균형을 유지하기 위해 규칙이 존재합니다. 간단하게만 짚고 넘어가자면, 데이터가 삽입되면 각 노드에 최대 차수에 맞게 데이터를 저장합니다. 만약 노드의 데이터가 최대치를 초과하면, 해당 노드는 분할되어 균형을 유지합니다.
따라서, 데이터가 어느 리프 노드에 위치하더라도 트리의 높이가 일정합니다. 트리의 깊이 제한 덕분에 데이터베이스 캐시를 효과적으로 사용하여 캐시 적중률을 높이고, 전체 검색 속도를 더욱 빠르게 만들 수 있다는 사실까지 알고 가면 좋겠습니다.
Hash
해시는 다들 잘 알고 계실거라 예상하지만, 인덱스로는 어떻게 사용되고 있을 지 모를 것 같아 들고 왔습니다.
시간복잡도가 무려 O(1)인 인덱스인데도 B+Tree보다 자주 사용되는 해시는 아닙니다. 왜 그럴까요?
바로 정확히 일치하는 검색에만 효율적이기 때문입니다.
그래서 보통 조회를 할 때 범위 조건으로 검색할 때가 많은데 해시 인덱스로 한다면…

그래도 해시인덱스 쓰는 곳은 분명 있으니 어떻게 구조를 이루고 있는지 한번 봅시다.
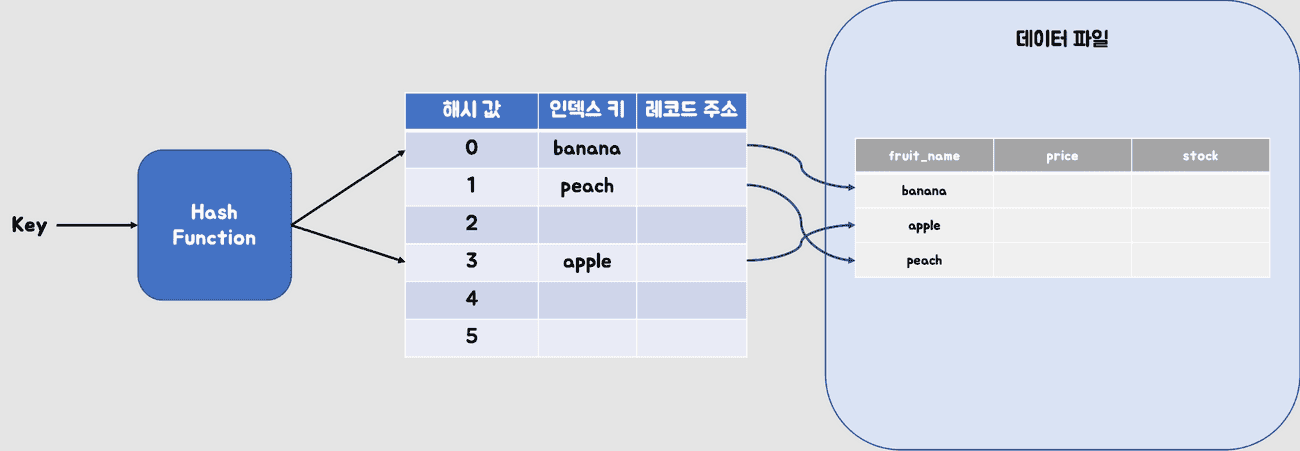
해시 테이블 자료구조로 컬럼 값과 메모리 주소를 관리합니다. 그래서 특정 컬럼에 대해 해시 인덱스를 설정할 경우, 해당 컬럼의 값에 해시 함수를 적용하여 해쉬 값을 얻고, 이 해쉬 값에 해당하는 위치에 컬럼 값 원본과 해당 데이터가 저장된 위치 정보가 저장됩니다.
이또한 해시를 활용하는 인덱스이다 보니 해시 충돌을 피할 순 없습니다. 그래서 해시 테이블에서도 존재하는 문제점은 똑같이 가지고 있는 인덱스입니다.
거기에 각 데이터는 정렬이 되어 있지 않기에 범위 조건에서 더 취약하고 데이터 저장 방식 또한 B+Tree에 비해서 비효율적입니다. 왜냐면 디스크 페이지로 관리하기가 어렵기 때문에 그렇습니다.
단점만 말해서 아무곳에서도 안쓰는 거 아니야? 싶겠지만 모든 건 다 쓸모가 있습니다.
MySQL InnoDB에서는 이걸 아주 야무지게 사용하고 있습니다.
어탭티브 해시 인덱스
자주 사용되는 칼럼을 해시로 정의하여, B-Tree 를 타지 않고 바로 데이터에 접근할 수 있는 기능입니다.
그래서 모든 값들이 해시로 생성이 되는 것이 아니라, 자주 사용되는 데이터 값만 내부적으로 판단하여 상황에 맞게 해시 값을 생성합니다.
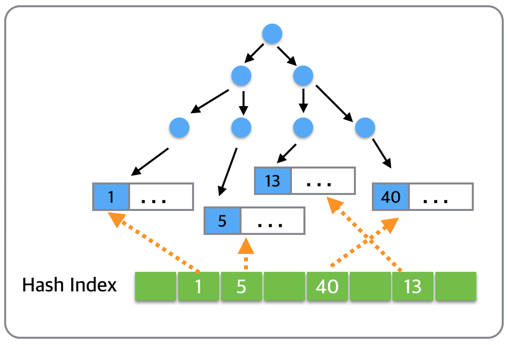
InnoDB는 특정 쿼리가 반복적으로 실행되면서 B-Tree 인덱스에서 특정 페이지에 대한 접근이 자주 발생하는 것을 감지하면, 해당 페이지를 해시 인덱스로 캐싱하여 빠르게 접근할 수 있도록 합니다. 이 과정을 자동으로 수행하여 자주 사용되는 데이터에 대해 해시 인덱스를 생성하고, 해시 기반의 탐색을 통해 검색 속도를 크게 향상시킵니다.
B-Tree의 한계를 보완할 수 있는 좋은 인덱스라고 요약할 수 있습니다.
클러스터링 인덱스
보통 Primary Key에서 적용되는 인덱스입니다. MySQL InnoDB에서 사용하고 있죠.
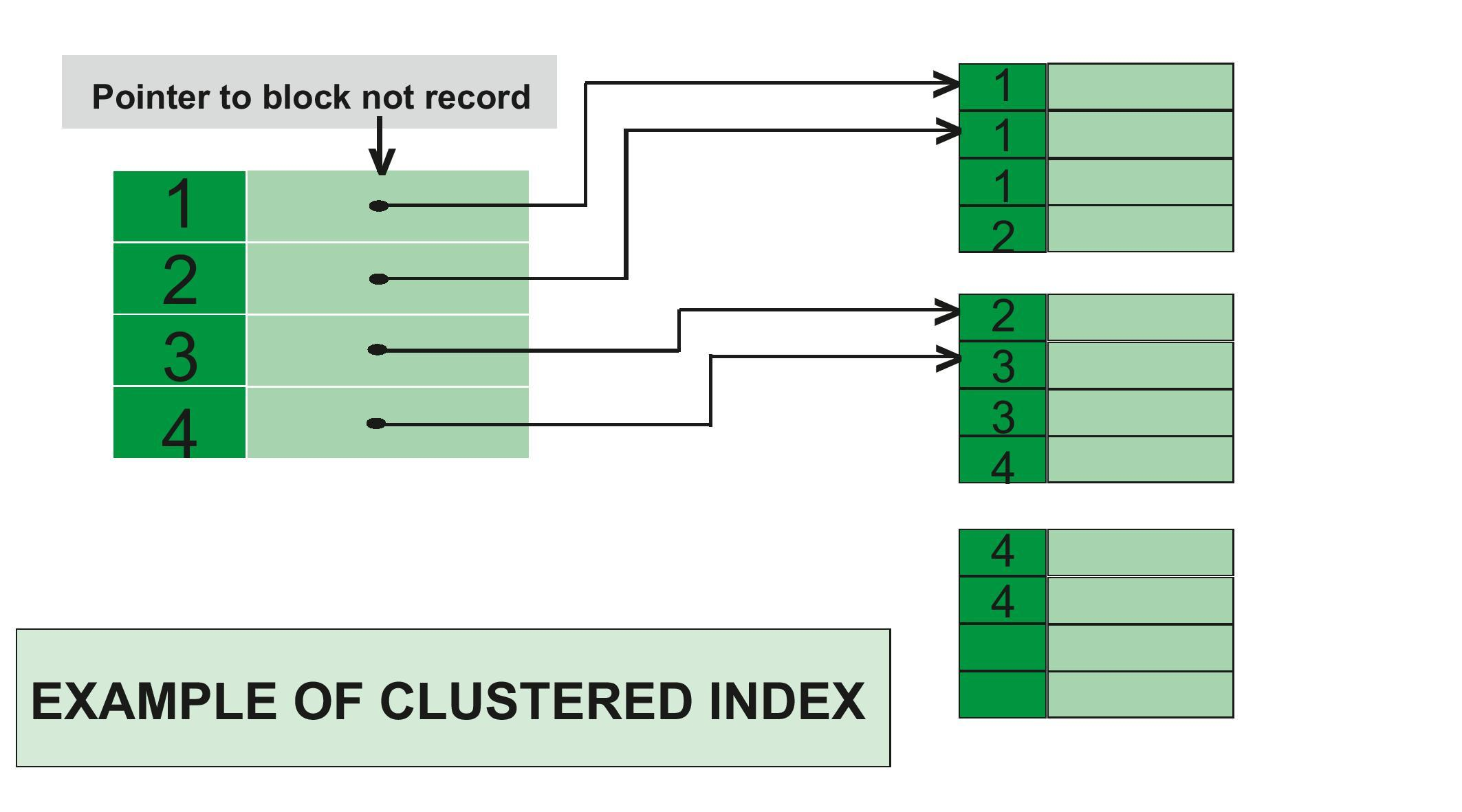
클러스터링 인덱스는 기본 키 값이 비슷한 레코드들을 물리적으로 인접한 위치에 묶어서 저장하는 것을 의미합니다. 그래서 기본 키 값에 따라 레코드의 저장 위치가 결정되므로, 기본 키 값이 변경될 경우 물리적인 저장 위치 또한 변경되어야 합니다.
그렇기에 당연히 기본 키 값 기반의 검색이 매우 빠르다는 장점이 있죠.
대신 삽입, 업데이트, 삭제에 대해선 느립니다. 조회에 몰빵한 인덱스라고 볼 수 있습니다.
하지만 레코드의 삽입이나 기본 키 값 변경이 자주 발생하면, 클러스터링 인덱스를 사용하지 않는 다른 스토리지 엔진에 비해 쓰기 성능이 상대적으로 느려질 수 있습니다. 왜냐하면 레코드가 삽입되면 물리적으로 위치를 옮겨버리니 불편하지 않을 수가 없습니다. ???: 야 방 빼, 방 빼!
그러나 AUTO_INCREMENT 설정처럼 기본 키를 순차적으로 삽입될 수록 한다면 이 문제는 해결됩니다.
AUTO_INCREMENT 는 PK가 1, 2, 3,… 처럼 증가하는 구조로 기본 키가 설정됩니다. 그렇다보면 보안상의 문제가 발생할 수 있습니다. 기본 키가 예측이 되기 때문입니다. 따라서 SQL 인젝션에 대해 잠재적인 위험이 도사리게 되죠. (물론, 서비스마다 특정 비밀 키를 두고 해싱이나 토큰 형태로 제공한다면 문제없긴 합니다.)
그래서 PK를 종종 UUID로 두는 경우를 볼 수 있습니다. 근데 MySQL InnoDB에서는 그러면 안됩니다.
UUID는 랜덤한 값이기 때문에 데이터 삽입 위치가 무작위로 삽입되기 때문에 물리적으로 정렬이 되지도 않고 페이지 분할이 발생할 가능성이 높아집니다. 그래서 AUTO_INCREMENT 기본 키를 사용하고 UUID 키를 보조 인덱스로 추가하는 편이 나을 겁니다..
근데 만약 PostgreSQL 라면? 이건 또 말이 다릅니다.
PostgreSQL의 기본 키는 클러스터링 인덱스로 자동으로 설정되지 않습니다. 그저 B-Tree 인덱스로 관리될 뿐입니다. 그렇다보니 테이블의 물리적 정렬에 영향을 주지 않기 때문에 UUID로 PK를 설정해도 문제가 없습니다.
관련해서 궁금하시면 한번 보시고 https://news.hada.io/topic?id=15713&utm_source=oneoneone
기본 키를 ‘무조건 UUID로 둬야한다’ 라는 생각보단 인덱싱 측면에서 이런 일이 있을 수 있다 정도로 생각하고 넘어간다면 아주 굿입니다. 굿.




너무 좋은 글 ^^... 잘 읽었습니다... :>