
서론
예전에 면접 준비하면서 보게 된 코딩테스트 내용이다. 참고 링크
멀티스레드를 가볍게 다뤄보기 좋을 듯 싶어 한번 구현해보게 되었다.
구현 요구사항은 다음과 같다.
멀티 스레드 그랩
용감한 쿠키는 평소 사용하는 파일 내 문자열 검색 툴 grep보다 더 빠른 속도를 자랑하는 ack나 ag같은 다양한 툴들이 있다는 것을 들었다.
자신만의 dgrep을 만들어 널리 세상을 이롭게 하고 싶다고 생각하게 된 용감한 쿠키는 그 첫 단계로 멀티스레드로 동작하는 grep을 직접 만들어보기로 결심하였다.
원하는 스펙에 맞는 파일 내 문자열 검색 툴을 만들어보자.
입력 형식
- dgrep {keyword} {relative path}
출력 형식
- 파일의 각 line에 keyword가 있는 경우, 해당 파일과 줄 번호를 출력한다.
조건
1. relative path가 디렉토리인 경우 디렉토리 내 모든 파일에 대해 검사를 진행한다.
2. relative path 내에 또 다른 디렉토리가 존재하는 경우, 각 디렉토리 내 모든 파일에 대한 검사 또한 진행한다.
3. 멀티 스레드를 이용하여 최대한 빠르게 작업을 완료하도록 작성한다.
4. 동일한 파일에 대한 검사 결과는 한 번에 출력되어야 한다.
5. Directory 내 symlink는 없다고 가정한다.
6. 파일들은 모두 UTF8 인코딩으로 작성된 Text파일이라고 가정한다.요구사항 분석
일단 1차적으로 요구사항을 분석해봤다.
문자 검색 툴
- Input/Output
- Input
dgrep {keyword} {relative path}
- Output
- ex)
File:/Users/choeseyeon/Documents/practice/test/pg2680.txt/ Line: 205
- ex)
- Input
- 문자 검색을 어떤 방식을 할지
- 알고리즘 이용
- 기본 라이브러리 이용
- path는 디렉토리/파일이 있다.
- 파일의 경우, 해당 파일에서만 조회한다.
- 디렉토리의 경우, 해당 디렉토리 내 모든 파일/디렉토리에서 검색한다.
- 멀티 스레드를 이용하여야 한다.
정도로 정리할 수 있을 것 같다.
일단 먼저 멀티스레드(고루틴, 채널)을 쓰지 않고 구현해보겠다.
멀티스레드 없이 구현하기
구현을 시작하기 전에 중요한 포인트는 path의 유형은 파일과 디렉토리가 있다는 점이다.
그래서 먼저 파일인지 경로인지 파악을 해야한다. 쉽게 경로에서 .을 포함하고 있는지 여부로 파악하도록 했다.
func isFileOrDirectory(path string) string {
if strings.Contains(path, ".") {
return "file"
} else {
return "directory"
}
}그 후 주어진 경로가 텍스트 파일인지 확인하고 주어진 경로 내의 모든 파일 경로를 읽도록 한다.
// 주어진 경로 내의 모든 파일 경로를 읽습니다.
func readFilesPath(path string) ([]string, error) {
var filesPath []string
err := filepath.Walk(path, func(path string, info os.FileInfo, err error) error {
if err != nil {
fmt.Printf(err.Error())
}
if !info.IsDir() {
if textFileCheck(path) {
filesPath = append(filesPath, path)
}
}
return nil
})
if err != nil {
return nil, err
}
return filesPath, nil
}
// 주어진 경로가 텍스트 파일인지 확인합니다.
func textFileCheck(path string) bool {
if strings.Contains(path, ".txt") {
return true
} else {
return false
}
}문자 검색에서 어떤 방법을 사용할지 고민해보았는데 따로 알고리즘을 쓰기보다 요구사항에서 요구하는 것은 멀티스레드를 사용하는 것이기 때문에 내부 함수를 활용하기로 결정했다.
// 주어진 파일에서 키워드를 찾습니다.
func readFile(path string, keyword string) []string {
file, err := os.Open(path)
if err != nil {
fmt.Printf("%s 파일을 읽는데 실패했습니다.\n", path)
return nil // 에러 발생 시 빈 슬라이스 반환
}
defer file.Close()
scanner := bufio.NewScanner(file)
lineNumber := 1
keywordLog := make([]string, 0)
for scanner.Scan() {
line := scanner.Text()
if strings.Contains(line, keyword) {
keywordLog = append(keywordLog, "File:"+path+"/ Line: "+strconv.Itoa(lineNumber))
}
lineNumber++
}
return keywordLog
}그 다음 요청한 경로가 파일인지 디렉토리인지 isFileOrDirectory 함수를 통해 구별하고 이에 맞춰서 readFile , readFiles 함수를 통해 해당 경로에 포함되는 파일 전부를 읽어오도록 구현했다.
// 주어진 경로에서 키워드를 찾습니다.
func FindKeyword(path string, keyword string) {
if isFileOrDirectory(path) == "file" {
readFile(path, keyword)
} else {
readFiles(path, keyword)
}
}
// 주어진 디렉토리 내의 모든 파일에서 키워드를 찾습니다.
func readFiles(path string, keyword string) {
paths, _ := readFilesPath(path)
for _, path := range paths {
content := readFile(path, keyword)
for _, str := range content {
fmt.Println(str)
}
}
}
// 주어진 파일에서 키워드를 찾습니다.
func readFile(path string, keyword string) []string {
file, err := os.Open(path)
if err != nil {
fmt.Printf("%s 파일을 읽는데 실패했습니다.\n", path)
return nil // 에러 발생 시 빈 슬라이스 반환
}
defer file.Close()
scanner := bufio.NewScanner(file)
lineNumber := 1
keywordLog := make([]string, 0)
for scanner.Scan() {
line := scanner.Text()
if strings.Contains(line, keyword) {
keywordLog = append(keywordLog, "File:"+path+"/ Line: "+strconv.Itoa(lineNumber))
}
lineNumber++
}
return keywordLog
}구현 중 중간에 데드락이 발생하는 지점이 몇가지 있었다. 아래가 처음 구현한 코드이다.
func readFiles(path string, keyword string) {
paths, _ := readFilesPath(path)
results := make(chan []string, len(paths))
for _, path := range paths {
content := readFile(path, keyword)
results <- content
}
for content := range results {
for _, str := range content {
fmt.Println(str)
}
}
}
func readFile(path string, keyword string) []string {
file, err := os.Open(path)
if err != nil {
fmt.Printf("%s 파일을 읽는데 실패했습니다.\n", path)
}
defer file.Close()
scanner := bufio.NewScanner(file)
lineNumber := 1
keywordLog := make([]string, 0)
for scanner.Scan() {
line := scanner.Text()
if strings.Contains(line, keyword) {
keywordLog = append(keywordLog, "File:"+path+"/ Line: "+strconv.Itoa(lineNumber))
}
lineNumber++
}
return keywordLog
}그 이유는 첫번째로 채널에 대한 쓰기와 읽기 작업이 비동기 되어 있다.readFiles 함수는 paths 슬라이스의 각 경로에 대해 readFile 함수를 호출하고, 각 호출의 결과를 results 채널에 보내는데 쓰기 작업은 비동기적으로 처리되지 않는다. 이말은 즉 모든 readFile 호출이 완료되고 결과가 채널에 쓰여진 후에야 결과를 읽기 시작한다.
두번째로 채널에서 값 읽기의 종료 조건 부재이다. for content := range results 루프는 results 채널이 닫힐 때까지 계속 값을 읽는다. 하지만 이 코드에서는 채널을 명시적으로 닫는 부분이 없어 채널에서 더 이상 값을 읽을 수 없게 되어도 루프가 종료되지 않아 데드락 상태에 빠지게 된다.
그래서 아래처럼 따로 채널을 통해 모든 내용을 취합해서 읽지 않고 readFile 결과값이 리턴될 때마다 순차적으로 출력되도록 구현하게 되었다. 이렇게 되면 굳이 채널로 인한 데드락 상태가 빠질 지 생각을 하지 않아도 괜찮다.
// 주어진 디렉토리 내의 모든 파일에서 키워드를 찾습니다.
func readFiles(path string, keyword string) {
paths, _ := readFilesPath(path)
for _, path := range paths {
content := readFile(path, keyword)
for _, str := range content {
fmt.Println(str)
}
}
}위와 같은 코드로 dgrep test ./test 명령어로 test 디렉토리 내부에 있는 각 1MB 이상의 .txt 파일을 읽도록 구현하였다. 멀티스레드 유무에 따라 달라지는 속도를 체크하기 위해 종료시간 - 시작시간 을 하게 되었다.
func main() {
commend := InputCommend()
start := time.Now()
FindKeyword(commend.path, commend.keyword)
end := time.Now()
fmt.Println("실행 시간:", end.Sub(start))
}그 결과, 약 35.9705ms 시간이 걸리게 되었다.
...
File:/Users/choeseyeon/Documents/practice/test/pg2800.txt/ Line: 25045
File:/Users/choeseyeon/Documents/practice/test/pg2800.txt/ Line: 26400
File:/Users/choeseyeon/Documents/practice/test/pg2800.txt/ Line: 26530
File:/Users/choeseyeon/Documents/practice/test/pg2800.txt/ Line: 26638
File:/Users/choeseyeon/Documents/practice/test/pg2800.txt/ Line: 26643
File:/Users/choeseyeon/Documents/practice/test/pg2800.txt/ Line: 26798
File:/Users/choeseyeon/Documents/practice/test/sample1.txt/ Line: 2
File:/Users/choeseyeon/Documents/practice/test/sample2.txt/ Line: 4
File:/Users/choeseyeon/Documents/practice/test/sample3.txt/ Line: 4
File:/Users/choeseyeon/Documents/practice/test/sample3.txt/ Line: 7
File:/Users/choeseyeon/Documents/practice/test/sample3.txt/ Line: 10
실행 시간: 35.9705ms멀티스레드를 사용해 구현하기
먼저 구현한 부분에서 멀티스레드를 적용시킬 수 있는 부분을 찾아보았다.
path 유형 중에 파일과 디렉토리가 존재한다는 것을 알고 있을 것이다. 만약 파일이라면 단 한개의 파일만 조회하기 때문에 시간 측면에서도 많은 시간이 들지 않을 것이라 판단했다. 또한 같은 파일을 여러개의 스레드(고루틴)가 키워드를 찾는다고 해도 구역을 나누고 찾은 내용을 기록하는 과정 속에서 데드락이 발생할 것이라 판단했기 때문에 디렉토리인 경우에만 멀티스레드를 적용하도록 하였다.
그래서 각 파일에 고루틴을 한개씩 할당하고 키워드를 찾아야 하는 파일들을 동시에 처리하도록 구현하였다.
func readFiles_multi(path string, keyword string) {
paths, err := readFilesPath(path)
if err != nil {
fmt.Println("파일 경로를 읽는 도중 에러 발생:", err)
return
}
var wg sync.WaitGroup
for _, filePath := range paths {
wg.Add(1)
go func(p string) {
defer wg.Done()
content := readFile(p, keyword)
for _, str := range content {
fmt.Println(str)
}
}(filePath)
}
wg.Wait()
}그 결과, 약 16.298666ms 시간이 걸리게 되었다.
...
File: /Users/choeseyeon/Documents/practice/test/pg17.txt / Line: 33069
File: /Users/choeseyeon/Documents/practice/test/pg17.txt / Line: 33567
File: /Users/choeseyeon/Documents/practice/test/pg17.txt / Line: 33974
File: /Users/choeseyeon/Documents/practice/test/pg17.txt / Line: 33993
File: /Users/choeseyeon/Documents/practice/test/pg17.txt / Line: 35460
File: /Users/choeseyeon/Documents/practice/test/pg17.txt / Line: 37142
File: /Users/choeseyeon/Documents/practice/test/pg17.txt / Line: 37145
File: /Users/choeseyeon/Documents/practice/test/pg17.txt / Line: 38084
File: /Users/choeseyeon/Documents/practice/test/pg17.txt / Line: 38362
File: /Users/choeseyeon/Documents/practice/test/pg17.txt / Line: 39304
File: /Users/choeseyeon/Documents/practice/test/pg17.txt / Line: 39390
실행 시간: 16.298666ms멀티스레드 적용 비교
쉽게 비교하기 위해서 라인 출력은 생략하고 키워드 탐색만 하도록 구현한 후에 테스트를 진행하였다.
라인 출력 결과값이 없다보니 상대적으로 앞서 봤던 결과값보다 더 적은 수치를 보여주지만, 확실한 건 멀티스레드가 적용이 되기 전과 후 차이가 약 50% 정도 나는 것을 확인할 수가 있다.
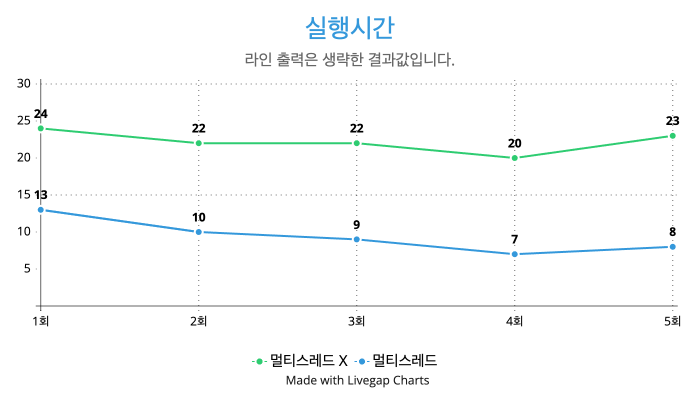
결론
멀티스레드 적용 전과 후의 비교를 통해, 멀티스레드를 활용한 병렬 처리가 프로그램의 실행 시간에 미치는 영향을 명확하게 확인할 수 있었다. 멀티스레드를 적용하지 않았을 때와 비교해 멀티스레드를 적용한 경우 실행 시간이 약 50% 가량 단축되었다는 결과는 멀티스레드 프로그래밍이 I/O 바운드 작업(예: 파일 시스템에서의 데이터 읽기/쓰기)에서 성능 향상을 가져올 수 있음을 보여준다.
멀티스레드를 활용함으로써 각 스레드가 파일 시스템의 다른 부분에서 동시에 작업을 수행할 수 있게 되어, 단일 스레드로 작업을 순차적으로 처리하는 것에 비해 훨씬 더 많은 작업을 동시에 처리할 수 있게 된다. 위 글에서는 테스트한 파일 용량이 작고 개수가 많지가 않아 고작 10ms 성능을 향상시킨 게 다지만 대용량 파일이나 많은 수의 파일을 처리해야 하는 작업에서 큰 성능 향상을 가져올 수 있다.
하지만 멀티스레드 프로그래밍은 동시성에 관련된 복잡성과 디버깅의 어려움, 그리고 race condition 와 같은 문제들을 동반할 수 있다. 따라서 멀티스레드를 적용할 때는 이러한 문제들을 주의 깊게 관리하고, 적절한 동기화 기법을 사용하여 데이터 일관성을 유지하고 데드락을 방지해야 한다.
구현 링크
구현 링크 [https://github.com/barabobBOB/Multi-Thead-in-Go]
