
현재, 사용자 위치에 따른 관광지에서 채팅과 게시글(낙서)를 남길 수 있는 서비스를 제작 중이다.
그래서 geolocation를 통해 받아온 현재 위치의 위도, 경도 데이터를 통해 위치한 관광지에 따라 서비스가 실행되어야 한다.
구현 해야 하는 기능
현재 위치의 위도, 경도를 바탕으로 반경 1km내 있는 장소를 조회
첫번째 방법
PostgreSQL의 추가 모듈 earthdistance 이용해보기
earthdistance 모듈은 두 점 사이의 거리를 계산하는 데 사용된다.
PostgreSQL에서 공식적으로 지원하고 추가 설치만 하면 바로 이용할 수 있다.
하지만, 가장 큰 단점으로는 지구가 타원형이 아닌 완벽한 구 형태로 가정하기에 정확도가 조금 떨어진다.
earthdistance 모듈의 종류는 아래 두가지가 있다.
cube모듈을 이용한Cube-Based- cube 모듈을 이용
- 인덱싱을 지원
- 복잡한 쿼리나 대량의 데이터를 처리할 때
Point-Based에 비해 높은 성능 제공
point데이터 타입을 이용한Point-Based- 내장 point 데이터타입을 이용
- 간단하게 구현이 가능하나, 복잡한 쿼리나 대량의 데이터에 대해 성능이 떨어짐
현재 관광지 데이터가 약 3만 8천건이고 앞으로 추가될 가능성이 있기에 대량의 데이터 처리에 용이한 Cube-Based 를 이용하여 구현하였다.
먼저, 모듈을 설치해준다.
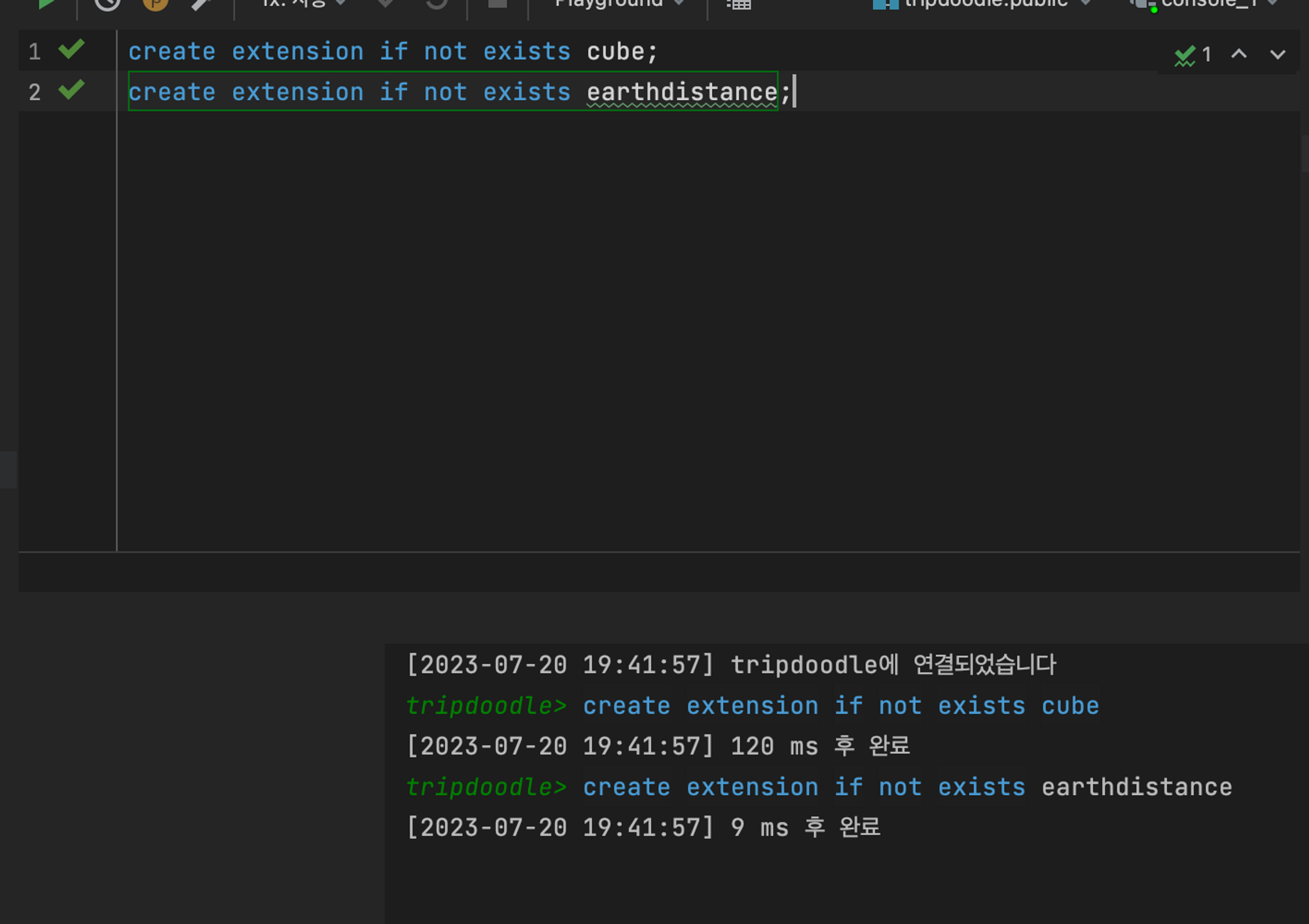
create extension cube;
create extension earthdistance;설치 완료했으니 쿼리를 한번 짜볼까?
SELECT
*
FROM
sights
WHERE
earth_box(ll_to_earth(<경도>, <위도>), 1000) @> ll_to_earth(longitude, latitude)
AND
is_deleted = false간단하게 설명하자면, 특정 지점에서 1km 이내에 위치한 'sights' 테이블의 모든 열을 선택한다.
또한, is_deleted 열이 false인 행만 데이터를 받아오도록 한다.
각 함수들의 자세한 설명은 다음과 같다.
ll_to_earth(<경도>, <위도>)- 주어진 경도와 위도를 사용하여 earth 데이터 유형으로 변환
- 이 earth 데이터 유형은 주어진 지점의 3차원 좌표를 나타냄
earth_box(ll_to_earth(<경도>, <위도>), 1000)- 주어진 지점 주변에 크기가 1000m인 'box'를 만듬
- 이 'box'는 주어진 지점에서 1km 이내에 있는 모든 점을 포함
earth_box(ll_to_earth(<경도>, <위도>), 1000) @> ll_to_earth(longitude, latitude)- 이 'box' 내에 있는 점을 선택하는 조건
@>는 PostgreSQL에서 'contains' 연산자를 나타냄sights테이블의 각 행에 대해 그 행의 경도와 위도가 나타내는 지점이 'box' 내에 있는지를 확인
테스트를 위해 집 좌표, 집에서 800m 떨어진 좌표, 집에서 1.2km 떨어진 좌표를 추가하고 쿼리를 실행했다.
- 우리집에서 반경 1km내에 위치한 장소
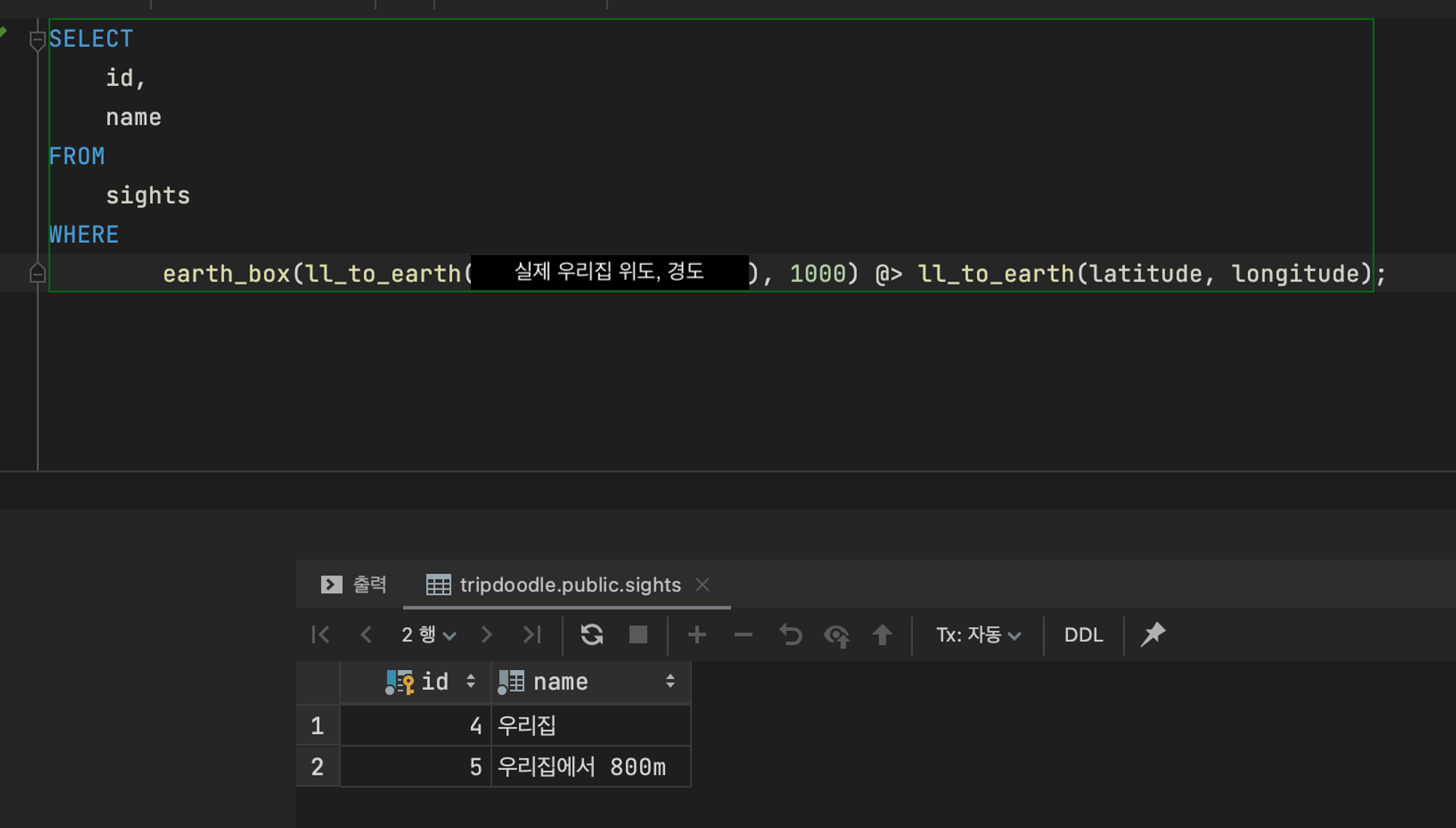
- 우리집에서 반경 1.5km 내에 위치한 장소

이정도 수치에서는 문제없이 동작 하긴 하지만, 1.3km 내로 설정했을 땐 정확하게 나오진 않았다.
추가로 앞으로 기능 확장에 따라 좀 더 정확한 위치계산이 필요하다 느껴져 다음 방법으로 바꾸게 되었다.
두번째 방법
PostgreSQL의 확장 프로그램인 PostGIS 활용하기
현재 DB를 PostgreSQL를 사용하기에 쉽게 적용할 수 있을 거라 생각했다.
또한, 기존에 사용하던 라이브러리보다 정확도가 높고 지원하는 기능도 많아 선택하게 되었다.
추가로 Uber의 H3나 Google의 S2와 같은 라이브러리로 고려해봤지만 Uber의 H3의 경우, 분산 시스템, 대규모 데이터를 다루고 분석 및 시각화에 특화되있고 Google의 S2도 큰 규모의 지리적 데이터를 처리하는 데 특화되있어 현재 한국 관광지로만 제한되어 있기에 적합하지 않다고 생각했다. 추후 확장되는 기능에 맞춰 적용하면 될 거라고 판단했다.
PostGIS은 GiST 기반 R-Tree 공간 인덱스를 지원, GIS 객체의 분석 및 공간 처리를 위한 기능을 포함하고 있다.
장/단점은 아래와 같다.
장점
- 풍부한 기능
- 다양한 공간 데이터 형식과 공간 쿼리를 지원
- 거리 및 영역 계산, 데이터 오버레이, 데이터 내부/외부 찾기 등 복잡한 공간 분석을 수행
- 통합성
- PostgreSQL 데이터베이스의 확장
- PostgreSQL의 모든 기능을 그대로 활용가능
- 트랜잭션, 인덱싱, 복제 등의 기능을 PostGIS 공간 데이터에도 적용 가능
단점
- 높은 러닝커브
- PostGIS의 공간 함수와 쿼리는 복잡함
- 성능 이슈
- 대용량 데이터의 경우, 일부 복잡한 공간 쿼리는 실행 시간이 길 수 있음
- 따라서 이러한 작업에는 고도의 최적화가 필요
- 인덱싱
- R-tree와 같은 공간 인덱싱은 PostGIS에서 지원되지만, 일부 특정 유스케이스(예: 대규모 지리적 데이터 처리)에서는 다른 공간 데이터베이스 라이브러리(예: Google의 S2 라이브러리, Uber의 H3)가 더 효율적일 수 있음
- R-tree와 같은 공간 인덱싱은 PostGIS에서 지원되지만, 일부 특정 유스케이스(예: 대규모 지리적 데이터 처리)에서는 다른 공간 데이터베이스 라이브러리(예: Google의 S2 라이브러리, Uber의 H3)가 더 효율적일 수 있음
아래는 메뉴얼 링크이다.
https://postgis.net/docs/manual-3.0/postgis-ko_KR.html
한번 사용해보자.
먼저 나는 Docker 컨테이너를 띄워 PostgreSQL을 사용하기에 image를 postgres 이미지를postgis/postgis로 변경했다.
참고 링크: https://registry.hub.docker.com/r/postgis/postgis
version: '3'
services:
DB:
image: postgis/postgis
restart: always
environment:
POSTGRES_USER: root
POSTGRES_PASSWORD: 1234
ports:
- 5433:5432
volumes:
- ./db/data:/var/lib/postgresql/data그리고 PostGIS을 설치해주자.
create extension postgis;추가로 나는 관광지 별 위도, 경도 데이터가 필요했기에 국내 지역별 관광명소데이터를 미리 INSERT 해두었다.
이제 쿼리를 짜볼까?

데이터는 약 3만 8천건이며 입력한 위도, 경도를 기준으로 반경 1km 내에 있는 관광지를 조회할 예정이다.
SELECT
*
FROM
sights
WHERE
ST_DWithin(
geography(ST_SetSRID(ST_Point(longitude, latitude), 4326)),
geography(ST_SetSRID(ST_Point(<경도>, <위도>), 4326)),
1000
)
AND
is_deleted = false;간단하게 설명하면, ST_DWithin 함수를 사용하여 특정 위치에서 1km(1000m) 이내에 있는 관광 명소를 찾는데 사용한다.추가로 AND is_deleted = false;를 이용해 삭제되지 않은 관광지만을 선택한다.
각 함수들의 자세한 설명은 다음과 같다.
ST_DWithin- 첫 번째 지리 공간 값과 두 번째 지리 공간 값 사이의 거리가 지정된 값(여기서는 1000m) 이내인지 확인
geography(ST_SetSRID(ST_Point(longitude, latitude), 4326))ST_Point함수는 지정된 경도와 위도를 사용하여 Point를 만듬ST_SetSRID함수는 이 포인트에 공간 참조 ID(SRID)를 설정- SRID 4326는 WGS 84 좌표 시스템(GPS에서 사용하는 좌표 시스템)을 나타냄
geography함수는 geography 데이터 타입으로 변환geography타입은 지구상의 2차원 점을 표현하는 데 사용되며, 위도와 경도를 사용하여 점의 위치를 정의
geography(ST_SetSRID(ST_Point(<경도>, <위도>), 4326))- 사용자의 위치를 나타내는 Point를 생성

데이터는 문제없이 잘 불러와졌는데 진짜 문제는
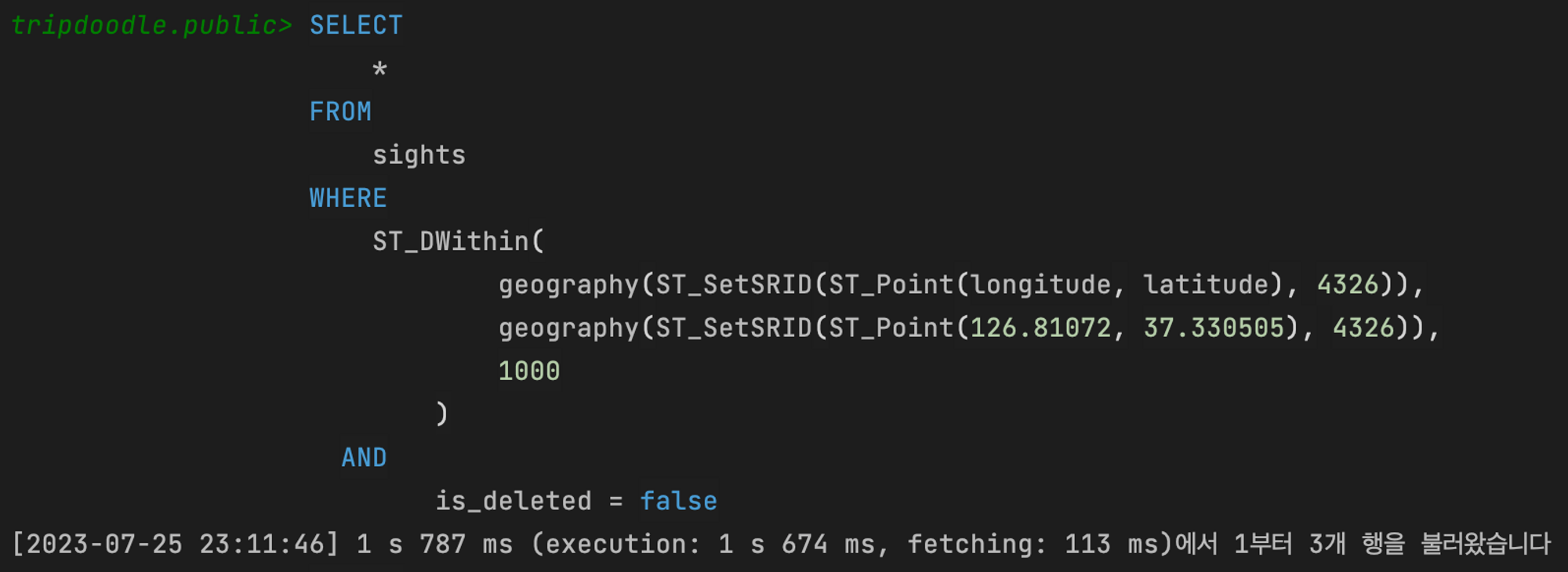
시간이….. 1초가 넘었고……. (거의 2초임)

API로 요청하니 3초가 넘어버렸다.

EXPLAIN 결과를 보니 어떻게든 풀 스캔을 하지 않도록 고쳐야겠다는 생각이 들었다.
공간 인덱싱 적용해 쿼리튜닝
관광지 데이터는 추가나 수정이 자주 이뤄지지 않기에, 인덱스를 적용하는 것이 좋다고 생각했다.
PostGIS의 경우, 공간 인덱싱를 제공하기에 위도, 경도 칼럼을 바탕으로 인덱스 설정이 가능하다.
인덱싱 방법도 여러가지 있는데 그 중 가장 일반적으로 사용되는 인덱싱 방법은 GiST (Generalized Search Tree)와 SP-GiST (Space-Partitioned Generalized Search Tree)이다.
- GiST (Generalized Search Tree)
- 트리 기반의 인덱싱 방식
- 다양한 데이터 유형에 대해 고도로 구성 가능한 방식으로 인덱싱을 제공
- 주로 공간 데이터에 대한 인덱싱에 사용
- B-Tree와 유사한 방식으로 작동하지만, 범위 쿼리와 다차원 데이터에 더 적합하도록 설계
- SP-GiST (Space-Partitioned Generalized Search Tree)
- 공간 분할에 기반한 인덱싱 방식
- 공간을 여러 영역으로 분할하고, 각각의 영역을 별도의 트리로 관리
- 복잡한 공간 쿼리를 더 효율적으로 처리
- BRIN (Block Range INdex)
- 범위를 기반으로 하여, 해당 범위 내의 모든 값에 대한 최소값과 최대값만을 저장
- 공간 데이터에 대한 쿼리에서 효율적이지 못할 수 있지만, 특정 조건하에서 유용
- R-Tree
- 공간 인덱싱에 특화된 자료구조
- 모든 공간 데이터를 최소 경계 사각형(Minimum Bounding Rectangle, MBR)으로 감싸고 이를 트리로 구성
- PostgreSQL/PostGIS에서는 GiST나 SP-GiST가 R-Tree의 역할을 대체 중
그래서 나는 지리적 거리 계산에 있어서 최적화되어 있는 GiST (Generalized Search Tree) 방법을 사용해 인덱싱하기로 결정했다.
한번 해보자.
GiST 인덱스를 사용해 longitude와 latitude 컬럼에 대한 인덱스를 생성할 예정이다.
쿼리는 다음과 같다.
CREATE INDEX index_name ON table_name USING gist (geography(ST_SetSRID(ST_Point(longitude, latitude), 4326)));자세한 설명은 다음과 같다.
CREATE INDEX index_name ON table_nametable_name라는 테이블에index_name이라는 이름으로 인덱스를 생성
USING gist- 인덱스 유형을 GiST (Generalized Search Tree)를 사용하라는 의미
geography(ST_SetSRID(ST_Point(longitude, latitude), 4326))- 인덱스를 생성할 데이터를 정의하는 부분
ST_Point(longitude, latitude)- 주어진 경도(longitude)와 위도(latitude)로 2차원의 점을 생성
ST_SetSRID(ST_Point(longitude, latitude), 4326)- 생성된 점에 대한 공간 참조 시스템을 설정
4326은 WGS 84(GPS에서 사용하는 좌표 체계, 위도와 경도를 나타내는 데 주로 사용)라는 좌표 체계를 나타냄
geography(ST_SetSRID(ST_Point(longitude, latitude), 4326))- 생성된 점을 PostGIS의
geography타입으로 변환 geography타입은 지구상의 2차원 점을 표현하는 데 사용되며, 위도와 경도를 사용하여 점의 위치를 정의
- 생성된 점을 PostGIS의


적용을 마쳤다.
전과 같은 쿼리를 보냈을 때,
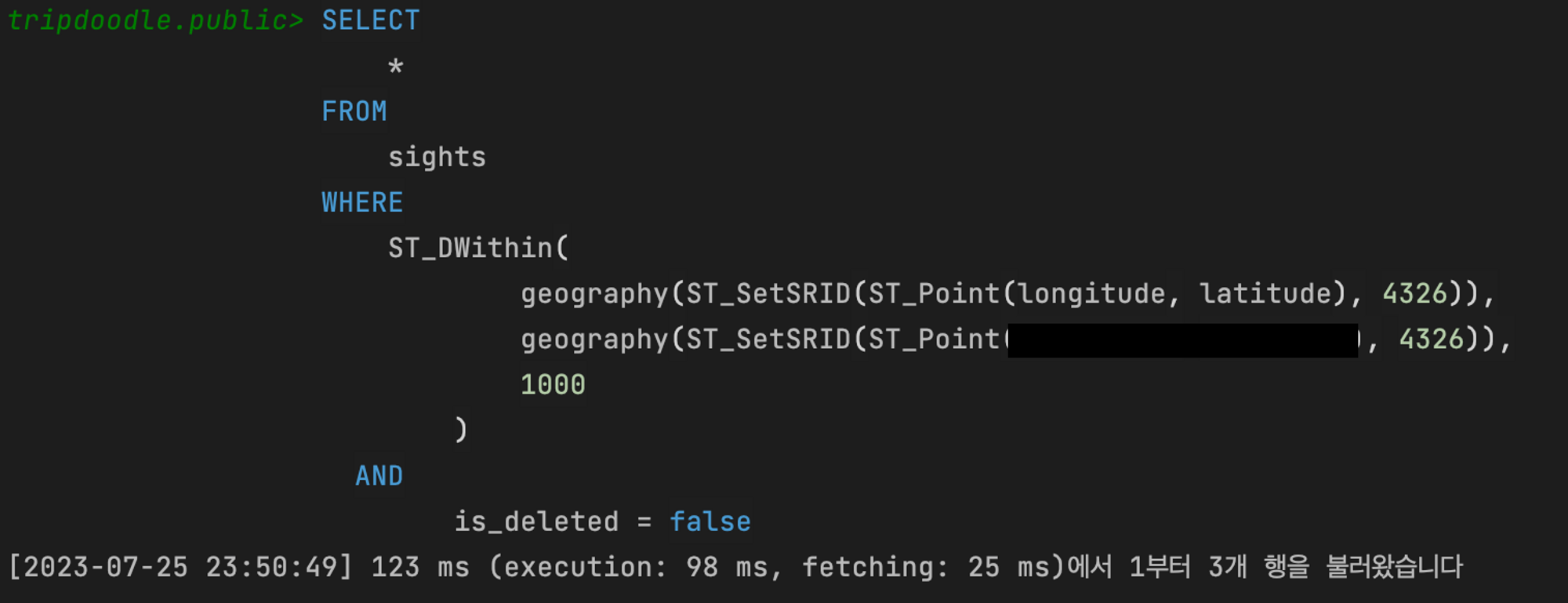
1s 787ms 에서 123ms로 시간이 줄어든 걸 확인할 수가 있다..!
Index Scan using sights_geo_index on sights (cost=0.40..121.01 rows=4 width=120) (actual time=4.000..4.024 rows=0 loops=1)
" Index Cond: (geography(st_setsrid(st_point((longitude)::double precision, (latitude)::double precision), 4326)) && _st_expand('0101000020E6100000925CFE43FA955F40B21188D7F5AB4240'::geography, '1000'::double precision))"
" Filter: ((NOT is_deleted) AND st_dwithin(geography(st_setsrid(st_point((longitude)::double precision, (latitude)::double precision), 4326)), '0101000020E6100000925CFE43FA955F40B21188D7F5AB4240'::geography, '1000'::double precision, true))"
Planning Time: 6.027 ms
Execution Time: 5.003 msEXPLAIN 을 찍어봤는데 인덱스를 잘 타고 있다는 걸 알 수 있다. (시간만 봐도 알 거 같다.)

API로 요청시에는 154ms가 나왔다. 기존에는 3s 이상 걸려 정말 쓸 수 없는 정도였는데 많이 줄었다.
추가적으로 여러 곳을 임의로 테스트해보니 50ms ~ 300ms 사이로 응답이 온다.
더 개선할 방법이 없을까?
첫번째, SELECT * 이 아닌 필요한 칼럼만 조회하자.
불필요한 I/O, 자원 등을 줄일 수 있기 때문에 필요한 칼럼만 SELECT 하도록 바꾸었다.
SELECT
id,
name
FROM
sights
WHERE
ST_DWithin(
geography(ST_SetSRID(ST_Point(longitude, latitude), 4326)),
geography(ST_SetSRID(ST_Point(<경도>, <위도>), 4326)),
1000
)
AND
is_deleted = false;기존에 조회되는 필드나 컬럼이 많지 않아 성능적으로 큰 차이는 없지만, 불필요하게 모든 컬럼을 가져오는 것보다 낫다고 판단했다.
두번째, 추가 인덱스를 구성해보자.
is_deleted 컬럼을 같이 고려한 멀티 컬럼 인덱스를 추가해볼까?
불가능하다.
is_deleted Boolean 타입이라 btree와 같은 알고리즘을 이용해야 하고 longitude, latitude 의 경우, gist와 같은 공간 인덱싱 방법을 이용해야 하기에 멀티 컬럼 인덱스 적용은 불가능하다.
is_deleted 컬럼에 대한 인덱스를 추가해볼까?
그 전에, 지금 is_deleted 값 전체가 false 이기에 전체 데이터의 약 10%를 true 로 변경한다.
UPDATE sights
SET is_deleted = true
WHERE id IN (
SELECT id
FROM sights
ORDER BY RANDOM()
LIMIT (SELECT COUNT(*) FROM sights) / 10
);이제 is_deleted 컬럼에 대한 인덱스를 추가하자.
CREATE INDEX idx_sights_is_deleted ON sights(is_deleted);이렇게 기본 PK 인덱스를 제외하고 2개의 인덱스가 추가된 모습을 확인할 수 있다.
SELECT
indexname,
indexdef
FROM
pg_indexes
WHERE
tablename = 'sights';
이제 쿼리를 실행해보자 !
Index Scan using sights_geo_index on sights (cost=0.40..121.01 rows=4 width=19) (actual time=0.812..2.234 rows=1 loops=1)
" Index Cond: (geography(st_setsrid(st_point((longitude)::double precision, (latitude)::double precision), 4326)) && _st_expand('0101000020E61000001D5A643BDF9B5F40717500C45D9B4140'::geography, '1000'::double precision))"
" Filter: ((NOT is_deleted) AND st_dwithin(geography(st_setsrid(st_point((longitude)::double precision, (latitude)::double precision), 4326)), '0101000020E61000001D5A643BDF9B5F40717500C45D9B4140'::geography, '1000'::double precision, true))"
Rows Removed by Filter: 1
Planning Time: 26.685 ms
Execution Time: 2.512 msEXPLAIN 찍어봤더니 idx_sights_is_deleted 인덱스를 사용하지 않았다.
대부분의 행이 is_deleted = false 이기에 굳이 해당 인덱스를 사용하지 않는 것으로 보인다.
게다가 TRUE, FALSE 값이 2개 뿐이라 카디널리티가 굉장히 낮기에 무의미한 결과를 보여준다.
따라서, 카디널리티가 낮은 컬럼에 굳이 인덱싱을 할 이유가 없다.


글 잘 봤습니다.