
ETL 패턴
데이터 분석, 데이터 사이언스 및 데이터 제품을 위해 구축된 데이터 파이프라인에 이상적인 설계
ETL 패턴의 처음 두 단계인 데이터 추출과 로드를 데이터 수집
전체 또는 증분 MySQL 테이블 추출
MySQL 테이블에서 전체 또는 일부 열을 데이터 웨어하우스 또는 데이터 레이크로 수집해야 하는 경우
전체 추출 또는 증분 추출을 사용하여 수집할 수 있다.
- 전체 추출
- 추출 작업을 실행할 때마다 테이블의 모든 레코드가 추출된다.
- 대용량 테이블의 경우 실행하는 데 오랜 시간이 걸린 수 있다.
- 증분 추출
- 추출 작업의 마지막 실행 이후 변경되거나 추가된 원본 테이블의 레코드만 추출된다.
- 마지막 추출의 타임스탬프는 데이터 웨어하우스의 추출 작업 로그 테이블에 저장하거나 웨어하우스의 대상 테이블에서 마지막 업데이트 열의 최대 타임스탬프를 쿼리하여 검색할 수 있다.
- 단점
- 삭제된 행은 캡처되지 않는다.
- 원본 테이블에는 마지막으로 업데이트된 시간에 대한 신뢰할 수 있는 타임스탬프가 있어야한다.
테이블 전체 추출 예제 (MySQL)
# 데이터 추출 -> csv -> S3 버킷
import pymysql
import csv
import boto3
import configparser
# DB 기본 설정 및 초기화
parser = configparser.ConfigParser()
parser.read("pipeline.conf")
hostname = parser.get("mysql_config", "hostname")
port = parser.get("mysql_config", "port")
username = parser.get("mysql_config", "username")
dbname = parser.get("mysql_config", "database")
password = parser.get("mysql_config", "password")
conn = pymysql.connect(host=hostname,
user=username,
password=password,
db=dbname,
port=int(port))
if conn is None:
print("Error connecting to the MySQL database")
else:
print("MySQL connection established!")
# 쿼리 실행
m_query = "SELECT * FROM Orders;"
local_filename = "order_extract.csv"
m_cursor = conn.cursor()
m_cursor.execute(m_query)
results = m_cursor.fetchall()
#추출된 데이터 csv 파일로 저장
with open(local_filename, 'w') as fp:
csv_w = csv.writer(fp, delimiter='|')
csv_w.writerows(results)
fp.close()
m_cursor.close()
conn.close()
# S3 업로드
# load the aws_boto_credentials values
parser = configparser.ConfigParser()
parser.read("pipeline.conf")
access_key = parser.get("aws_boto_credentials", "access_key")
secret_key = parser.get("aws_boto_credentials", "secret_key")
bucket_name = parser.get("aws_boto_credentials", "bucket_name")
s3 = boto3.client('s3', aws_access_key_id=access_key, aws_secret_access_key=secret_key)
s3_file = local_filename
s3.upload_file(local_filename, bucket_name, s3_file)테이블 증분 추출 예제 (MySQL)
- 데이터웨어 하우스로 RedShift 이용
- 데이터 웨어하우스에 CSV 파일이 업로드된 상태
import pymysql
import csv
import boto3
import configparser
import psycopg2
# get db Redshift connection info
parser = configparser.ConfigParser()
parser.read("pipeline.conf")
dbname = parser.get("aws_creds", "database")
user = parser.get("aws_creds", "username")
password = parser.get("aws_creds", "password")
host = parser.get("aws_creds", "host")
port = parser.get("aws_creds", "port")
# connect to the redshift cluster
rs_conn = psycopg2.connect(
"dbname=" + dbname
+ " user=" + user
+ " password=" + password
+ " host=" + host
+ " port=" + port)
# 원본테이블에서 추출한 마지막 레코드의 타임스탬프를 찾음
rs_sql = """SELECT COALESCE(MAX(LastUpdated), '1900-01-01')
FROM Orders;"""
rs_cursor = rs_conn.cursor()
rs_cursor.execute(rs_sql)
result = rs_cursor.fetchone()
# 오직 하나의 레코드만 반환됨
last_updated_warehouse = result[0]
rs_cursor.close()
rs_conn.commit()
# get the MySQL connection info and connect
parser = configparser.ConfigParser()
parser.read("pipeline.conf")
hostname = parser.get("mysql_config", "hostname")
port = parser.get("mysql_config", "port")
username = parser.get("mysql_config", "username")
dbname = parser.get("mysql_config", "database")
password = parser.get("mysql_config", "password")
conn = pymysql.connect(host=hostname,
user=username,
password=password,
db=dbname,
port=int(port))
if conn is None:
print("Error connecting to the MySQL database")
else:
print("MySQL connection established!")
# %s 자리 표시자를 이용하여 값이 튜플(데이터 집합을 저장하는 데 사용되는 데이터 유형)으로
#.execute() 함수에 전달된다.
# SQL 주입을 방지하기 위해 SQL 쿼리에 매개변수를 추가해주는 적절하고 안전한 방법
m_query = """SELECT *
FROM Orders
WHERE LastUpdated > %s;"""
local_filename = "order_extract.csv"
m_cursor = conn.cursor()
m_cursor.execute(m_query, (last_updated_warehouse,))
results = m_cursor.fetchall()
with open(local_filename, 'w') as fp:
csv_w = csv.writer(fp, delimiter='|')
csv_w.writerows(results)
fp.close()
m_cursor.close()
conn.close()
# load the aws_boto_credentials values
parser = configparser.ConfigParser()
parser.read("pipeline.conf")
access_key = parser.get(
"aws_boto_credentials",
"access_key")
secret_key = parser.get(
"aws_boto_credentials",
"secret_key")
bucket_name = parser.get(
"aws_boto_credentials",
"bucket_name")
s3 = boto3.client(
's3',
aws_access_key_id=access_key,
aws_secret_access_key=secret_key)
s3_file = local_filename
s3.upload_file(
local_filename,
bucket_name,
s3_file)MySQL 데이터의 이진 로그 복제
대용량 데이터 수집이 필요한 경우 변경 사항을 복제하기 위해 MySQL 이진 로그 내용을 사용하는 것이 더 효과적
- MySQL 이진 로그
- 데이터베이스에서 수행된 모든 작업에 대한 기록을 보관하는 로그
데이터 웨어하우스는 MySQL 데이터베이스가 아닐 가능성이 높으므로
단순하게 내장된 MySQL 복제 기능을 사용할 수 없다.
- MySQL 서버에서 이진 로그를 활성화하고 구성한다.
- 초기 전체 테이블 추출을 실행하고 로드한다.
- 지속적으로 이진 로그를 추출한다.
- 추출된 이진 로그를 데이터 웨어하우스로 변환하여 로드한다.
from pymysqlreplication import BinLogStreamReader
from pymysqlreplication import row_event
import configparser
import pymysqlreplication
import csv
import boto3
# get the MySQL connection info
parser = configparser.ConfigParser()
parser.read("pipeline.conf")
hostname = parser.get("mysql_config", "hostname")
port = parser.get("mysql_config", "port")
username = parser.get("mysql_config", "username")
password = parser.get("mysql_config", "password")
mysql_settings = {
"host": hostname,
"port": int(port),
"user": username,
"passwd": password
}
b_stream = BinLogStreamReader(
connection_settings = mysql_settings,
server_id=100,
only_events=[row_event.DeleteRowsEvent,
row_event.WriteRowsEvent,
row_event.UpdateRowsEvent]
)
order_events = []
for binlogevent in b_stream:
for row in binlogevent.rows:
if binlogevent.table == 'orders':
event = {}
if isinstance(
binlogevent,row_event.DeleteRowsEvent
):
event["action"] = "delete"
event.update(row["values"].items())
elif isinstance(
binlogevent,row_event.UpdateRowsEvent
):
event["action"] = "update"
event.update(row["after_values"].items())
elif isinstance(
binlogevent,row_event.WriteRowsEvent
):
event["action"] = "insert"
event.update(row["values"].items())
order_events.append(event)
b_stream.close()
keys = order_events[0].keys()
local_filename = 'orders_extract.csv'
with open(
local_filename,
'w',
newline='') as output_file:
dict_writer = csv.DictWriter(
output_file, keys,delimiter='|')
dict_writer.writerows(order_events)
# load the aws_boto_credentials values
parser = configparser.ConfigParser()
parser.read("pipeline.conf")
access_key = parser.get(
"aws_boto_credentials",
"access_key")
secret_key = parser.get(
"aws_boto_credentials",
"secret_key")
bucket_name = parser.get(
"aws_boto_credentials",
"bucket_name")
s3 = boto3.client(
's3',
aws_access_key_id=access_key,
aws_secret_access_key=secret_key)
s3_file = local_filename
s3.upload_file(
local_filename,
bucket_name,
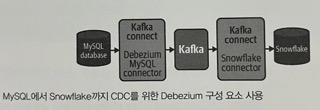
s3_file)카프카 및 Debezium을 통한 스트리밍 데이터 수집
CDC(MySQL 이진 로그 등) 시스템을 통해 데이터를 수집할 경우, 훌륭한 프레임워크의 도움이 필요함.
- Debezium
- 일반적인 CDC 시스템에서 행수준 변경을 캡처한 후 다른 시스템에서 사용할 수 있는 이벤트로 스트리밍해주는 시스템
- 아파치 주키퍼
- 분산 환경을 관리하고 각 서비스의 구성을 처리
- 아파치 카프카
- 확장성이 뛰어난 데이터 파이프라인을 구축하는 데 일반적으로 사용되는 분산 스트리밍 플랫폼
- 아파치 카프카 커넥트
- 데이터를 카프카를 통해 쉽게 스트리밍할 수 있도록 카프카를 다른 시스템과 연결하는 도구

오물쪼물 코딩생활 ๑•‿•๑