
개요
현재 프로젝트에서 쿠팡 사이트의 카테고리별 제품 목록을 크롤링하는 작업에 있다. 84개의 카테고리, 약 4만건이다. 크롤링시 고려할 문제점은 뭐가 있는지, 사이트 차단을 방지하면서 시간을 어떻게 하면 단축 시킬 수 있을 지를 고려하고자 한다.
크롤링 전 고려할 사항
1. robots.txt
크롤링 하고자 하는 사이트 링크 뒤에 /robots.txt 를 붙혀본다면 아래와 같은 화면이 보일 것이다.
e.g. https://www.coupang.com/robots.txt
쿠팡 사이트는 다음과 같은 상황에만 크롤링할 수 있다.
Allow: /vp/products/
Allow: /np/categories/- Googlebot: 이 부분은 Google 검색 엔진의 일반적인 크롤러를 대상으로 한다.
- Allow:
/vp/products/와/np/categories/경로는 Googlebot이 크롤링할 수 있도록 허용한다.
User-agent: Googlebot-Mobile
Allow: /vp/products/
Allow: /np/categories/- Googlebot-Mobile: Google의 모바일 검색 엔진 크롤러를 대상으로 한다.
- Allow: 모바일 버전의
/vp/products/와/np/categories/경로를 허용한다.
User-agent: Googlebot-image
Allow: /vp/products/
Allow: /np/categories/- Googlebot-image: Google의 이미지 검색 엔진 크롤러를 대상으로 한다.
- Allow: 이미지 검색을 위한
/vp/products/와/np/categories/경로를 허용한다.
User-agent: NaverBot
Allow: /vp/products/
Allow: /np/categories/- NaverBot: 네이버 검색 엔진의 크롤러를 대상으로 한다.
- Allow:
/vp/products/와/np/categories/경로를 허용한다.
User-agent: Yeti
Allow: /vp/products/
Allow: /np/categories/- Yeti: 네이버의 Yeti 크롤러를 대상으로 한다.
- Allow: Yeti 크롤러에게
/vp/products/와/np/categories/경로를 허용한다.
User-agent: *
Disallow: /- 모든 봇에 대한 기본 설정: 모든 다른 크롤러(User-agent: *)에게는 모든 경로를 금지한다. (Disallow: /). 따라서 이 설정은 모든 다른 봇들이 해당 웹 사이트의 모든 페이지를 크롤링하지 못하도록 제한한다.
결국, 모든 경로에 대해 크롤링을 허용하지 않겠다는 것이다. 그래서 개인 목적으로 웹 서버에 과도한 부하를 주지 않는 선에서 진행하기로 결정했다.
2. Bot으로 오인할 수 있지 않을까?
실제 크롤링 코드를 작성하면서 쿠팡 사이트 측에서 Bot으로 오인하는 오류를 마주했다. 이를 해결하기 위해서 HTTP 요청 헤더에 User-Agent 값을 넣어주었다. (User-Agent은 웹 브라우저 혹은 HTTP 클라이언트의 종류와 버전을 나타내는 문자열)
예를 들어, Chrome 브라우저에서 접속한 사용자라면 다음과 같은 User-Agent를 사용한다.
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}이를 그대로 활용해서 크롤링해도 되지만, 혹시 모를 상황에 대비해서 헤더를 랜덤하게 지정해주었다.
import random
from fake_useragent import UserAgent
def set_header() -> dict[str, str]:
return {
"User-Agent": UserAgent().random,
"Accept-Language": "ko-KR,ko;q=0.8,en-US;q=0.5,en;q=0.3"
}fake_useragent 를 사용하여 요청을 보낼 때마다 set_header() 를 통해 User-Agent를 무작위로 생성하였다.
3. 요청을 자주 보내지 않는가?
반복문으로 요청을 한번에 계속 보내게 된다면, 분명 쿠팡 측에서 악의적인 공격으로 받아드릴 것이다. 그렇게 된다면 더이상 내 IP로 쿠팡 사이트를 접속할 수 없을 것이다. 그렇기 때문에 time.sleep() 함수를 통해 크롤링 하는 시간을 지연하기로 결정했다.
단순하게 time.sleep(1) 처럼 1초를 그냥 줄 수도 있지만 규칙적으로 요청을 하기 때문에 이또한 공격으로 오인할 수도 있다는 생각을 하게 되었다.
import time
import random
def crawling_waiting_time() -> None:
return time.sleep(random.randint(1, 3))그렇기에 다음과 같이 random.randint(1, 3) 함수를 통해서 시간 자체를 무작위로 생성하도록 구현하였다.
Selenium
동적으로 웹 크롤링 하기 위해서 가장 많이 사용하는 라이브러리일 것이다. ChromeDriver 등을 통해 직접 웹사이트를 사람처럼 제어하면서 크롤링할 수 있다. 그렇기에 이를 사용하려 크롤링하고자 한다.
class CoupangCrawler:
def __init__(self, categories_id, max_pages=10):
self.categories_id = categories_id
self.max_pages = max_pages
self.chrome_options = Options()
self.chrome_options.add_argument("--no-sandbox")
self.chrome_options.add_argument("--disable-dev-shm-usage")
self.chrome_options.add_argument('--disable-blink-features=AutomationControlled')
self.chrome_options.add_argument(f"user-agent={UserAgent().random}")
self.driver = None
def start_driver(self):
self.driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=self.chrome_options)Selenium을 사용하면서 ChromeDriver를 필연적으로 사용할 수 밖에 없다. 만약 서버 배포나 기타 상황 등을 대비하여 ChromeDriverManager().install() 을 통해 환경에 맞춰 동적으로 다운로드 하도록 구현하였다. 만약, 이미 다운 받았던 이력이 있다면 캐싱 처리로 인해 재다운을 받지않고 캐시에서 바로 가져와 사용하도록 되어있다. 그렇기에 동적으로 다운받는다고 생각하면 크롤링을 할 때마다 다운을 받는다고 생각할 수 있지만 캐싱 처리가 되기에 그렇지 않다.
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from fake_useragent import UserAgent
class CoupangCrawler:
def __init__(self, categories_id, max_pages=10):
self.categories_id = categories_id
self.max_pages = max_pages
self.chrome_options = Options()
self.chrome_options.add_argument("--no-sandbox")
self.chrome_options.add_argument("--disable-dev-shm-usage")
self.chrome_options.add_argument('--disable-blink-features=AutomationControlled')
self.chrome_options.add_argument(f"user-agent={UserAgent().random}")
self.driver = None
def start_driver(self):
self.driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=self.chrome_options)
def crawl_category(self, category_id):
self.start_driver()
baseurl = (f'https://www.coupang.com/np/categories/{category_id}'
f'?listSize=120&brand=&offerCondition=&filterType='
f'&isPriceRange=false&minPrice=&maxPrice=&channel=user'
f'&fromComponent=N&selectedPlpKeepFilter=&sorter=bestAsc&filter=&component=194186&rating=0')
self.driver.get(baseurl)
page = 1
while page <= self.max_pages:
try:
WebDriverWait(self.driver, 20).until(
EC.presence_of_element_located((By.CLASS_NAME, 'baby-product-link'))
)
except Exception as e:
print(f"페이지 로드 오류: 카테고리 {category_id}, 페이지 {page}")
print(f"Error: {e}")
break
items = self.driver.find_elements(By.CLASS_NAME, 'baby-product-link')
if not items:
print(f"더 이상 항목이 없습니다: 카테고리 {category_id}, 페이지 {page}")
break
for item in items:
try:
number = item.get_attribute('data-product-id')
title = item.find_element(By.CLASS_NAME, 'name').text.strip()
price = item.find_element(By.CLASS_NAME, 'price-value').text.strip()
per_price = item.find_element(By.CLASS_NAME, 'unit-price').text.strip()
star = item.find_element(By.CLASS_NAME, 'rating').text.strip()
review_cnt = item.find_element(By.CLASS_NAME, 'rating-total-count').text.strip()
print(number, title, price, per_price, star, review_cnt)
except Exception as e:
# print(f"상품 정보 추출 오류: {e}")
continue
try:
next_page_button = WebDriverWait(self.driver, 10).until(
EC.presence_of_element_located((By.XPATH, f'//*[@id="product-list-paging"]/div/a[{page+2}]'))
)
self.driver.execute_script("arguments[0].click();", next_page_button)
WebDriverWait(self.driver, 20).until(
EC.presence_of_element_located((By.CLASS_NAME, 'baby-product-link'))
)
page += 1
except Exception as e:
print(f"다음 페이지로 이동할 수 없습니다: 카테고리 {category_id}, 페이지 {page}")
print(f"Error: {e}")
break
self.driver.quit()
def crawl(self):
for category_id in self.categories_id:
self.crawl_category(category_id)
def close(self):
if self.driver:
self.driver.quit()
if __name__ == '__main__':
categories_id = [
...
]
crawler = CoupangCrawler(categories_id)
crawler.crawl()
crawler.close()일단 코드 가독성보다 단순 구현에 초점을 맞춰서 구현했다.
의문점
여기서 의문이 생겼다. 굳이 Selenium을 써야할까? 현재 코드를 봤을 때, element의 클래스명이 동적으로 할당이 되거나 JS 이벤트 기반으로 로딩되는 데이터가 있지는 않았다. 그렇기 때문에 Selenium와 ChromeDriver를 걷어내고 HTML 구문 파싱으로 대체하는 것이 더 리소스를 아낄 수 있는 방법이라고 생각했다.
BeautifulSoap
그렇게 사용하게 된 것이 BeautifulSoap이다. request.text를 통해 가져온 데이터는 텍스트 형태의 HTML이다. 텍스트 형태의 데이터에서 원하는 HTML 태그를 추출하기 위해서 사용하는 것이 BeautifulSoap이다.
먼저 카테고리 별로 마지막 페이지가 몇 번인지 알아야 하기 때문에 다음과 같이 작성했다.
import requests
from bs4 import BeautifulSoup
def check_last_page(self, category_id):
response = requests.get(construct_url(category_id, 1), headers=set_header())
response.raise_for_status()
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
page = soup.find('div', class_='product-list-paging')
return int(page['data-total'])
return 1status_code가 200인 경우만 데이터를 추출하도록 했다. 하지만, 이미 raise_for_status()를 통해서 요청이 실패하고 응답 상태 코드가 400 이상인 경우 HTTPError를 발생시키기 때문에 굳이 if문으로 체크할 필요는 없을 듯하다.
class CoupangCrawler:
def __init__(self, max_pages=10):
self.categories_id = setup_categories_id()
self.logger = setup_logging()
self.max_pages = max_pages
self.database_manager = DatabaseManager(db_config=db_config)
def check_last_page(self, category_id):
response = requests.get(construct_url(category_id, 1), headers=set_header())
response.raise_for_status()
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
page = soup.find('div', class_='product-list-paging')
return int(page['data-total'])
return 1
def crawl(self):
try:
self.database_manager.connect()
for category_id in self.categories_id:
self.crawl_category(category_id)
finally:
self.database_manager.close()
def crawl_category(self, category_id):
last_page = self.check_last_page(category_id)
time.sleep(random.randint(1, 3))
for page in range(1, min(last_page, self.max_pages) + 1):
self.crawl_page(category_id, page)
logging.info(f"------category_id: {category_id}, page: {page}------")
time.sleep(random.randint(1, 3))
def crawl_page(self, category_id, page):
url = construct_url(category_id, page)
response = requests.get(url, headers=set_header())
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
items = soup.find('ul', id='productList').find_all('li')
self.extract_items(items, category_id)
def extract_items(self, items, category_id):
for item in items:
try:
product_id = item['data-product-id']
title = item.find('div', class_='name').text
price = item.find('strong', class_='price-value').text
star = item.find('em', class_='rating').text
# per_price 괄호와 "100g당", "원" 제거
per_price = item.find('span', class_='unit-price').text
per_price = re.sub(r'\(100g당\s*|\s*원\)|\(|\)', '', per_price).strip()
# review_count 괄호 제거
review_count = item.find('span', class_='rating-total-count').text
review_count = re.sub(r'[\(\)]', '', review_count).strip()
# price와 per_price에서 쉼표 제거
price = int(price.replace(',', ''))
per_price = int(per_price.replace(',', ''))
self.logger.info(
f"category_id: {category_id}, product_id: {product_id}, title: {title}, price: {price}, "
f"per_price: {per_price}, star: {star}, review_cnt: {review_count}")
self.database_manager.insert_product(int(product_id),
title,
price,
per_price,
float(star),
int(review_count),
category_id)
except Exception:
# 리뷰, 별점 등의 정보가 없는 경우
continue(현재 데이터베이스에 원시 데이터를 적재하고자 하기에 database_manager 클래스를 만들어 사용중이다.)
오늘 자 기준으로 각 상품의 데이터는 ul의 id='productList' 안에 모두 담겨져 있다. 그렇기 때문에 find를 통해 find_all로 li 타입을 찾아서 파싱하고 이를 extract_items를 통해 각 상품 별로 쪼개어 파싱한다.
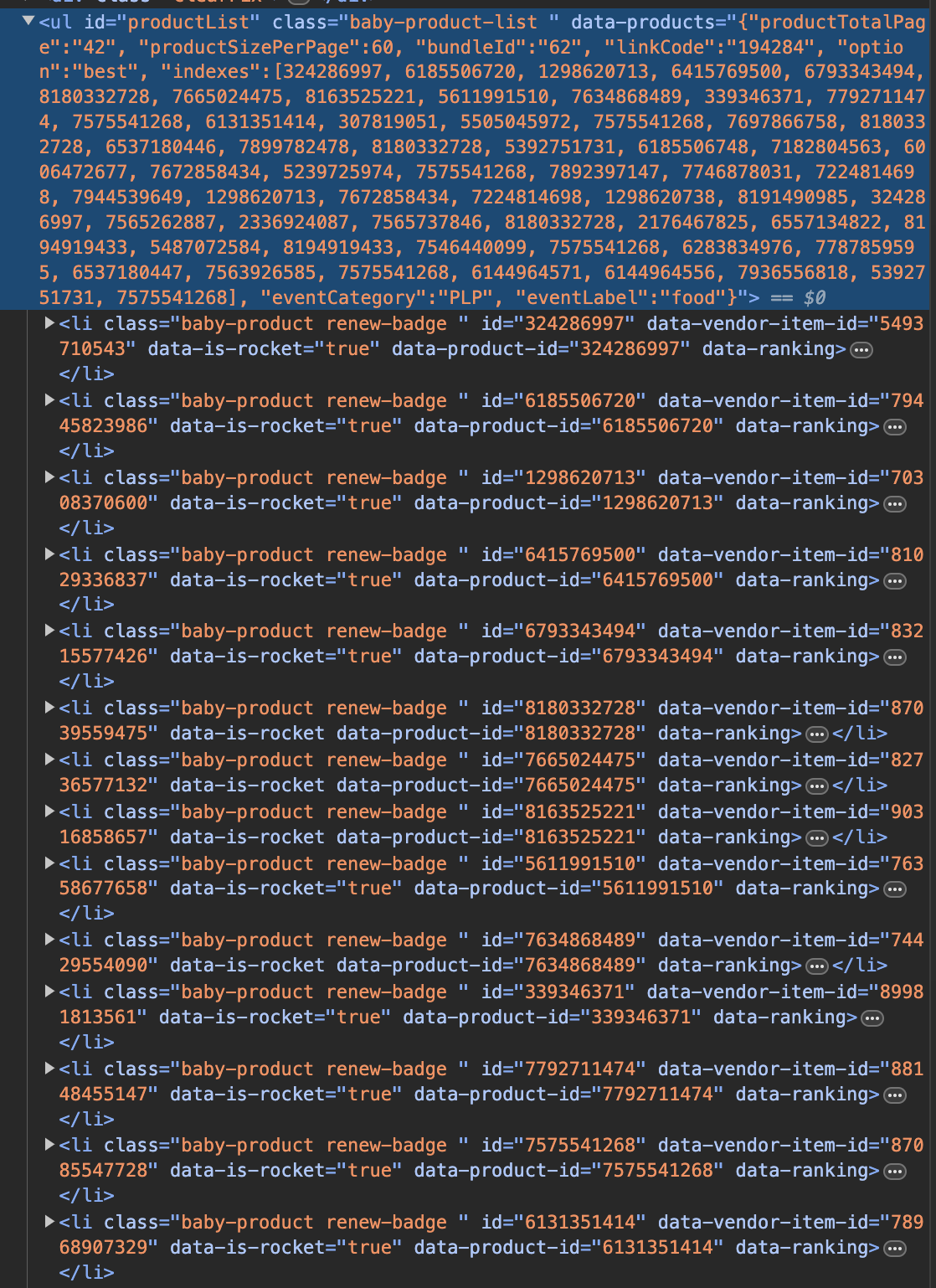
쿠팡 상품페이지의 경우, 클래스명이 동적으로 변하지 않고 JS 이벤트 기반으로 로딩되는 페이지가 없었다. 그렇기에 BeautifulSoap로 구문 분석만 한다면 손쉽게 크롤링을 할 수 있다. 이제 앞으로 Airflow를 활용하여 스케줄링할 계획이다.
Project LINK -> https://github.com/barabobBOB/PriceTracker



감사합니다. 문제 해결에 큰 도움이 됐습니다 ㅎㅎ