컴퓨터는 사람과 어떻게 상호작용할까?
우선 컴퓨터는 전기로 작동한다는 사실을 인지하여야 한다.
랩탑의 경우는 내장 배터리를 통해 전력을 공급하고 데스크탑의 경우는 콘센트에서 나오는 220v 교류전압을 인가받아 작동된다. ( 우리나라의 경우는 220V, 미국은 110V )
( 본체와 콘센트를 연결하는 플러그가 교류 신호를 직류 신호로 변환해서 끊임없는 전력을 공급하여 전원을 유지시켜준다 )
전기로 작동한다는 사실은 무엇을 의미할까? 전기적 신호로 명령을 인식하고 또 수행한다는 뜻이다.
사용자가 키보드나 마우스를 통해 컴퓨터에게 명령을 입력하면
이 명령들은 컴퓨터 내부 장치들의 회로에서 전기 도통, 부통 신호로 변환되며
이를 통해 컴퓨터 내부 장치들은 사용자의 입력을 인식하고 마찬가지의 전기적 신호, 흘렀다 안흘렀다를 반복하며 명령을 수행하고 연산한 결과값을 모니터에 표시한다.
이렇게 컴퓨터는 전기가 흘렀다 ( 1 ), 안 흘렀다 ( 0 ) 두 가지로 정보를 인식하고 또 표현한다.
이렇게 0과 1, 2가지의 정보로만 수를 표현하는 것을 2진수라고 하며, 영어로는 binary 라고 한다.
그리고 0 또는 1을 담아낼 수 있는 정보 칸을 1 bit라고 한다. 1 bit는 데이터 표현의 최소 단위이다.
그런데 이 하나의 비트는 0과 1만 표현할 수 있기 때문에 우리가 사용하는 문자를 표현하기에는 크기가 너무 작다. 그래서 바이트(byte)라는 단위를 사용하게 된다.
1 바이트는 8 비트로 이뤄져 있다.

한 개의 비트는 0과 1, 2개의 정보를 표현할 수 있는데 이것을 8개로 묶으면 2^8개, 즉 256가지의 정보를 표현할 수 있다. 따라서 숫자와 영문자를 모두 표현할 수 있고 남는 공간에 특수문자까지 할당할 수 있다.
비트와 바이트의 개념을 알았으니 이제 본격적으로 아스키코드와 유니코드에 대해서 알아보자.
아스키코드(ASCII)
아스키코드의 등장 이유
컴퓨터는 우리가 말하는 a,b,c를 알지 못한다.
그래서, 'a는 001이고 b는 010고 c는 110이고 d는 111이고...' 같이 글자에 대칭되는 2진수값들을 정리하여 미리 컴퓨터에 세팅해놓아야 한다.
그런데 여기서 문제가 발생한다. 표준이 없기 때문에 컴퓨터 기종에 따라 변환되는 값이 제각각이었다.
어떤 컴퓨터는 a를 001이라고 표현하고 어떤 기기는 a를 100이라고 표현하게 되면서 데이터 표현에 혼란이 생기게 된다.
따라서 숫자와 문자를 매칭시키는 표준을 만들게 된다.
이 표준을 아스키코드라고 한다.
아스키코드의 문자표
숫자와 문자를 1대1로 매칭시킨 표를 말한다.
영어로 CharacterSet이라고 한다. html에서 사용한 그 charset이다.
아스키코드는 1바이트, 즉 8비트의 데이터를 사용한다.
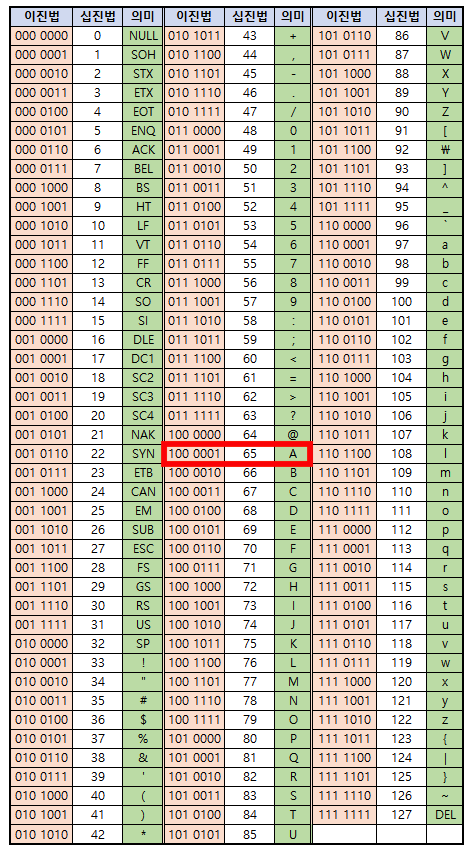
아래 표를 참고해서 A는 어떻게 변환되는지 알아보자.
표를 참고하면 A는 이진수 100 0001로 변환된다. 그런데 이상한 점이 있다. 아스키코드는 8비트의 데이터를 사용한다고 했는데 표의 이진수는 일곱자리다. 한자리는 어디갔을까?
이 한자리는 패리티 비트(parity bit)라고 부르는데, 데이터의 에러를 탐지하기 위해 사용한다.
일곱자리의 이진수에서 '1'이 홀수개라면 끝에 1을, '1'이 짝수개라면 끝에 0을 덧붙인다. 아주 정밀하진 않지만 패리티 비트를 이용해 어느 정도의 에러를 탐지할 수 있다.
따라서, 패리티 비트를 제외하면 아스키 코드는 총 7자리의 이진수를 문자로 내타낼 수 있기 때문에 총 2^7개인 128개의 문자를 나타낼 수 있다.
아스키코드의 문제점
아스키코드(ASCII : American Standard Code for Information Interchange)가 만들어질 당시 컴퓨터는 영미권에서만 주로 사용되었기에 알파벳 위주로만 표현 가능했다.
하지만 시간이 흐르면서 세계 각국에서 컴퓨터를 사용하게 되었고 다양한 표준들이 생겨나기 시작한다.
이렇게 다양한 표준들이 충돌하고 문자가 깨지면서 '걁궬뷀뒐' 같은 문자가 표현됐다.
따라서, 이 많은 표준들을 하나로 합칠 새로운 기준이 필요해졌다.
유니코드(Unicode)
아스키코드로는 모든 언어를 표현하는데 한계가 있었고 전 세계 언어의 문자를 정의하기 위한 국제 표준 코드가 등장하였다.
바로 유니코드이다.
1바이트로는 부족했으니 용량을 크게 확장한 2바이트(2^16 = 65,536)를 사용하게 된다.
처음에는 65,536개에 온 세상 문자를 모두 담을 수 있을 것이라 생각했지만 쓰지 않는 고어, 토속어 같은 모든 문자를 담으려다 보니 이마저도 부족했다. 이를 해결하기 위해 약 백만자가 넘는 문자를 추가로 정의했다.
유니코드의 문제점
그런데 이 유니코드에서 문제점이 발생한다.
유니코드가 영어를 표현할 땐 1바이트로, 한글을 표현할 땐 2바이트로, 다른 특수문자를 표현할 땐 3바이트로 표현하는 가변적인 표현의 문제가 생긴다.
어쩔 땐 1바이트를 읽고 어쩔 떈 2바이트를 읽으니 이는 컴퓨터에게 매우 큰 혼란은 준다. 따라서 어떤 글자는 1바이트로, 어떤 글자는 2바이트로 읽을지 정해줘야한다.
유니코드 인코딩 방식
앞서 나온 문제점을 보완하기 위해 유니코드에는 다양한 인코딩 방식이 존재한다.
인코딩 방식이란, 컴퓨터가 어떤 글자를 만났을 때 얼만큼씩 읽어야 하는지 미리 말해주는 것이다.
유니코드의 인코딩 방식으로는 코드 포인트를 코드화한 UCS-2와 UCS-4, 변환 인코딩 형식인 UTF-7, UTF-8, UTF-16, UTF-32 인코딩 등이 있다.
UTF-8(8-bit Unicode Transformation Format)
다양한 유니코드 인코딩 방식 중 우리에게 익숙한 UTF-8 방식을 살펴보자.
UTF-8은 문자열 집합과 인코딩 형태를 8비트 단위로 한다는 의미를 가지고 있다.
유니코드 한 문자를 나타내기 위해서 1바이트에서 4바이트까지 사용한다. 이를 가변 길이 인코딩 방식이라고 한다.
왜 가변적으로 인코딩할까? 그냥 일정하게 4바이트씩 읽어들이면 더 편하지 않을까?
아스키문자들은 1바이트로 하나의 문자를 표현할 수 있는데 모든 문자를 4바이트를 사용한다면 메모리가 낭비 된다.
따라서 아스키코드로 표현 가능한 것들은 1바이트로 표현하고 그것이 불가하면 2바이트 이상을 사용하는 방식이 UTF-8 방식이다.
그렇다면 어떻게 1바이트로 읽을지 4바이트로 읽을지 알 수 있는걸까 ?
첫번째 바이트를 시작하는 비트가 어떤 것이냐를 보면 알 수 있다.
1바이트의 문자였다면 첫 번째 바이트의 앞 비트가 0,
2바이트였다면 110,
3바이트였다면 1110,
4바이트였다면 11110이 될 것이다.
0xxxxxxx : 첫 번째 바이트가 0으로 시작한다면 0이외의 7 비트를 아스키로 인식한다.
110xxxxx 10xxxxxx : 두번째 바이트까지 읽어서 하나의 문자로 표현
1110xxxx 10xxxxxx 10xxxxxx : 세번째 바이트까지 읽어서 하나의 문자로 표현
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx : 네번째 바이트까지 읽어서 하나의 문자로 표현
여기서 UTF-8의 강점은 아스키방식과 완벽하게 호환된다는 것이다.
최근에 표준으로 가장 많이 사용되고 있는 인코딩 방식이다.
왜 한글이 깨질까?
여기서부터는 추가적인 개념이다.
우리가 겪는 한글이 깨지는 현상의 이유가 뭘까? 다양한 이유가 있겠지만 거의 대부분 이것의 문제이다.
EUC-KR로 인코딩이 된 것을 UTF-8로 읽거나, UTF-8로 인코딩 된것을 EUC-KR로 읽어들일 때 한글이 꺠지는 경우가 가장 많다.
charset이 유니코드도 있지만 유니코드 이전에 한글을 표현하기 위한 KS X 1001이라는 문자표가 존재했다.
이 문자표를 택한 곳이 바로 마이크로소프트이다. 마이크로소프트사에서 윈도우를 개발할 때 이 문자표를 표준으로 선택했고 이 문자표를 인코딩한게 바로 EUC-KR이다.
그렇기 때문에 애초에 EUC-KR과 UTF-8은 문자표도 다르지만 인코딩 방식도 달라 당연히 깨질 수 밖에 없는 것이다.
우리는 한글 윈도우를 사용하고 웹에서는 UTF-8을 사용하기 때문에 웹 프로그래머는 UTF-8로 인코딩을 별도로 해줘야 한다.
