Database란 뭘까?
간단히 말하면 데이터들의 집합이라고 할 수 있지만, 일반적인 의미로는 단순히 데이터들의 집합을 넘어 대용량의 데이터를 저장하는 프로그램을 지칭한다.
그렇다면 이 database는 어디에 사용되는걸까?
서버를 구축할 때 사용된다.
우리가 사용하는 웹 기반 서비스는 클라이언트단 그리고 서버단만 존재하는 2 tier 구조, 서버 & DB & 클라이언트가 존재하는 3 tier 구조가 있는데 이 둘의 차이점으로 장단점을 파악할 수 있다.
2 tier vs 3 tier
2 tier 구조에선 데이터들이 in-memory 방식으로 저장된다. 즉, 서버 컴퓨터의 주기억장치 메모리 ( RAM ) 에 데이터를 저장하는 구조로 데이터 접근 속도가 매우 빠르기 때문에 빠른 데이터 처리가 가능하다.
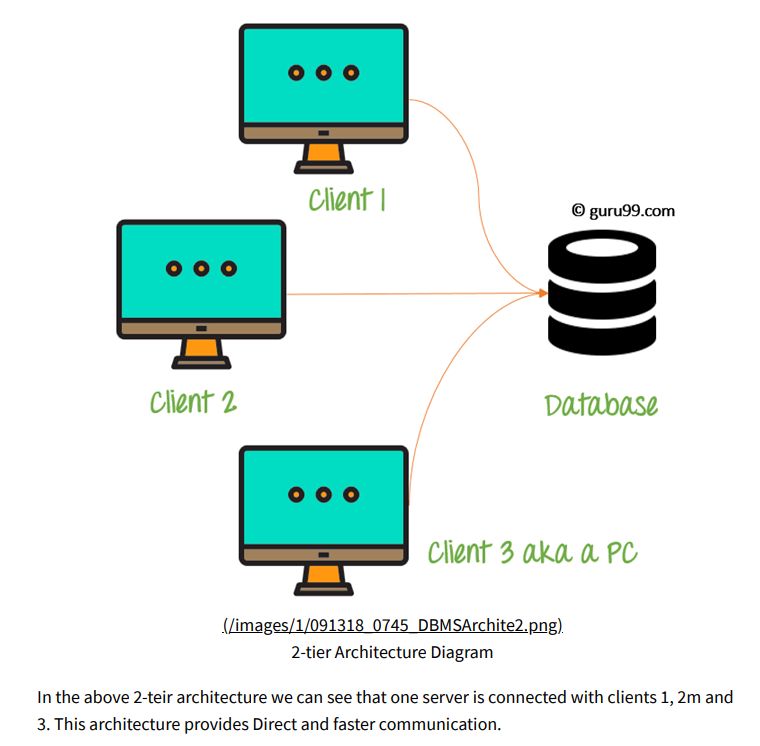
하지만 대용량의 데이터를 보관하기에는 비용이 너무 커진다. ( RAM의 가격이 비싸기에 )
또한 RAM은 휘발성 소자이기에 전력이 끊기면 데이터가 다 날아가기 때문에 정전이나 서버측에 예기치 못한 에러가 생기면 데이터 소실의 위험이 있다.
반면 3 tier 구조에선 데이터를 SSD, HDD 즉, 보조기억 장치에 저장하기 때문에 접근속도는 느리지만 대용량을 저장할 수 있고 비용도 전자의 경우보다 저렴한 편이다. 데이터 소실 위험도 줄일 수 있다.
DB 종류
데이터 베이스 종류로는 관계형 ( SQL : Structured Query Language ), 비관계형 ( NoSQL : Not only SQL ) 으로 나눌 수 있다.
SQL의 대표적인 예시로는 오라클의 DBMS, MS의 SQL Server, Mysql사의 Mysql 등이 있다.
NoSQL의 대표적인 예시로는 MongoDB가 있다.
그렇다면 한 가지 의문이 들 것이다. MS의 엑셀로는 DB 구축하면 안되나?
물론 엑셀이 더 직관적이고 사용하기 편리하다. 하지만 엑셀은 파일 단위로 데이터를 로딩할 수 있기 때문에 부분만 필요하다해도 매번 전체 파일을 로드해야 한다. 이 작업은 파일이 커질수록 느려지기 때문에 비효율적인 반면
SQL, 혹은 NoSQL은 테이블 단위 혹은 원하는 조건 필터링으로 데이터를 로드할 수 있기 때문에 효율적인 접근이 가능한 편이다.
돌아와서 SQL과 NoSQL의 차이는 무엇인가 알아보자.
SQL은 데이터가 구조화된(structured) 테이블을 사용하는 DB이고 NoSQL은 데이터를 구조화하지 않고 즉, 테이블을 사용하지 않고 데이터를 다른 형태로 저장한다.
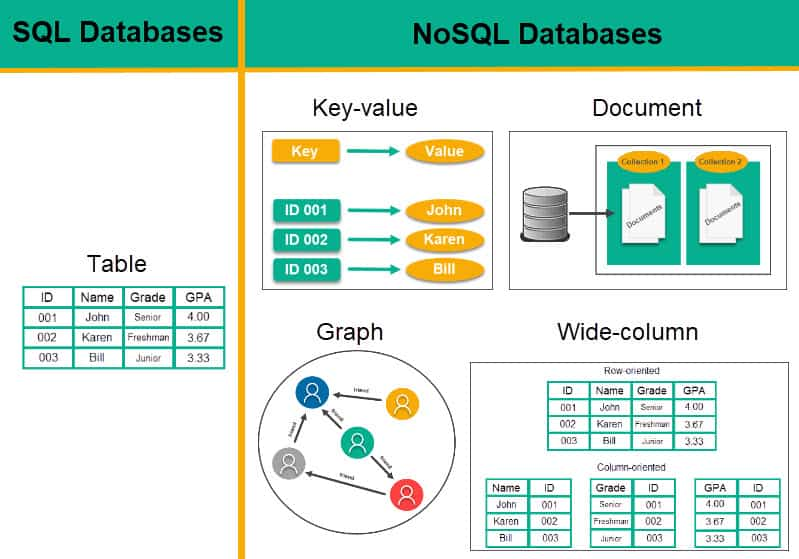
보다시피 SQL은 테이블을 통한 데이터 형태인데 반해 NoSQL은 다양한 형태로 데이터를 저장할 수 있다.
하단의 이미지는 Json화된 문서 형식으로 저장한 데이터와 column 기반으로 데이터를 표현한 NoSQL의 예시이다.
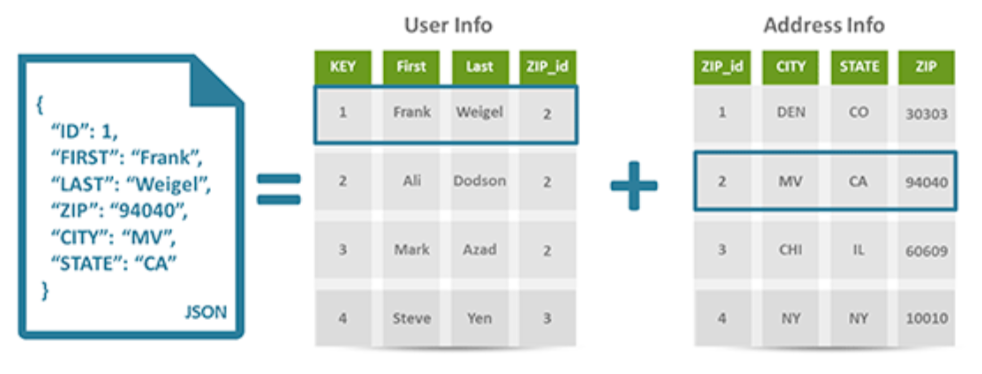
링크텍스트 --- noSql 종류
ACID
위처럼 데이터베이스는 sql, nosql 여러가지 형태로 구현할 수 있으면서 다양한 작업들을 수행할 수 있다. 그 중 대표적인 것이 트랜잭션 ( transaction ) 이다. 한국말로 직역하면 거래를 뜻하는 이 단어는 우리가 흔히 사용하는 계좌 송금 등에 적용되는 작업이다. 트랜잭션을 수행하는 데이터베이스가 가지고 있는 성질이 있다.
그 성질을 ACID라고 일컫는데 다음의 4가지이다.
-
Atomicity ( 원자성 )
-
Consistency ( 일관성 )
-
Isolation ( 격리성 )
-
Durability ( 지속성 )
1. Atomicity ( 원자성 )
원자성은 하나의 트랜잭션에 속해있는 모든 작업이 전부 성공하거나 전부 실패해서 결과를 예측할 수 있어야 한다는 성질이다.
계좌이체의 상황을 살펴보자. 다음의 2단계로 이뤄진다
ㄱ. A 계좌에서 출금
ㄴ. B 계좌에 입금
계좌이체를 하려는데 A 계좌에서는 출금이 이뤄지고, B 계좌에 입금되지 않았다고 가정해보자. 어디서 문제가 발생했는지 파악할 수 없다면, A 계좌에서 출금된 돈은 세상에서 사라지는 돈이 된다.
만약 은행에서 이런 일이 발생한다면, 은행은 더이상 제 기능을 할 수 없을것이다. A 계좌에서 출금하는 일에 성공했지만, B 계좌에 입금하는 작업에 실패한다면 계좌 A에서 출금하는 작업을 포함하여 모든 작업이 실패로 돌아가야 한다는 것이 Atomicity(원자성)이다.
원자성을 지켰다면 1번과 2번, 두 작업이 모두 성공적으로 완료되어야 한다. 그렇지 않으면(둘 중 하나의 작업이라도 실패한다면), 하나의 단위로 묶여있는 모든 작업이 실패하게 만들어 기존 데이터를 보호해야 한다.
SQL에서도 마찬가지이다. 특정 쿼리를 실행했는데 부분적으로 실패하는 부분이 있다면, 전부 실패하도록 구현되어 있다.
2. Consistency ( 일관성 )
두 번째는 데이터베이스의 상태가 일관되어야 한다는 성질이다. 하나의 트랜잭션 이전과 이후, 데이터베이스의 상태는 이전과 같이 유효해야 한다. 다시 말해, 트랜잭션이 일어난 이후의 데이터베이스는 데이터베이스의 제약이나 규칙을 만족해야 한다는 뜻이다.
예를 들어 '모든 고객은 반드시 이름을 가지고 있어야 한다'는 데이터베이스의 제약이 있다고 가정하자.
다음과 같은 트랜잭션은 Consistency(일관성)를 위반한다:
이름 없는 새로운 고객을 추가하는 쿼리
기존 고객의 이름을 삭제하는 쿼리
이 예시는 '이름이 있어야 한다' 라는 제약을 위반한다. 따라서 예시 트랜잭션이 일어난 이후의 데이터베이스는 일관되지 않는 상태를 가지게 되므로 제약에 맞는 쿼리로 수정해야 한다.
3. Isolation(격리성)
격리성은 모든 트랜잭션은 다른 트랜잭션으로부터 독립되어야 한다는 성질이다.
실제로 동시에 여러 개의 트랜잭션들이 수행될 때, 각 트랜젝션은 고립(격리)되어 있어 연속으로 실행된 것과 동일한 결과를 나타내야 한다.
예를 들어 계좌에 만 원이 있다고 가정하자.
이 계좌로부터 계좌 B로 6천 원을, 계좌 C로 6천 원을 동시에 계좌 송금하는 거래가 발생한경우,
계좌 B와 C에 각각 6천 원씩 송금하여 마이너스 통장이 되는 것이 아니고 첫번째 트랜잭션에서 6천원을 송금해서 4천원이 남은 셈이니 남은 거래는 취소가 되는 것이 맞다.
( 동시라고 했지만 소숫점 이하의 자릿수를 측정 비교하면 우선 거래가 결정될 것이다. 거의 동시에 송금 거래가 발생한 경우 시스템상에서 우선 거래를 식별할 수 있어야 한다 )
즉, 각각의 송금 작업을 연속으로 실행하는 것과 동일한 결과가 나타나야 한다. 격리성을 지키는 각 트랜젝션은 철저히 독립적이기 때문에, 다른 트랜젝션의 작업 내용을 알 수 없다.
4. Durability ( 지속성 )
Durability(지속성)는 하나의 트랜잭션이 성공적으로 수행되었다면, 해당 트랜잭션에 대한 로그가 남아야 한다는 성질이다. 만약 런타임 오류나 시스템 오류가 발생하더라도, 해당 기록은 영구적이어야 한다는 뜻이다.
예를 들어 은행에서 계좌이체를 성공적으로 실행한 뒤에, 해당 은행 데이터베이스에 오류가 발생해 종료되더라도 계좌이체 내역은 기록으로 남아야 한다.
마찬가지로 계좌이체를 로그로 기록하기 전에 시스템 오류 등에 의해 종료가 된다면, 해당 이체 내역은 실패로 돌아가고 각 계좌들은 계좌이체 이전 상태들로 돌아가게 된다.
