블룸필터(Bloom Filter)는 특정 원소가 집합에 속하는지 검사하는데 사용할 수 있는 확률형 자료 구조이다.
블룸필터는 비트코인 언리미티드(Bitcoin Unlimited) 팀이 노드에 알려지지 않은 거래를 식별하는데 도움을 주고 있다.

블룸필터(Bloom Filter)는1970년 Burton Howard Bloom에 의해 고안되었다.
블룸 필터에 의해 어떤 원소가 집합에 속한다고 판단된 경우 실제로는 원소가 집합에 속하지 않는 긍정 오류가 발생하는 것이 가능하지만,
반대로 원소가 집합에 속하지 않는 것으로 판단되었는데 실제로는 원소가 집합에 속하는 부정 오류는 절대로 발생하지 않는다는 특성이 있다.
집합에 원소를 추가하는 것은 가능하나, 집합에서 원소를 삭제하는 것은 불가능하다.
집합 내 원소의 숫자가 증가할수록 긍정 오류 발생 확률도 증가한다.
블룸필터(Bloom Filter)는 1970년도에 Burton H. Bloom이 고안한 것으로 공간 효율적인 Probabilistic Data Structure이며 구성요소가 집합의 구성원인지 점검하는데 사용된다.
블루필터의 특징
블룸필터는 원소가 집합에 속하는지 여부를 검사하는데 사용되는 확률적 자료 구조이다.
1970년 Burton Howard Bloom에 의해 개발되었다.
그 당시 컴퓨터의 저장 공간은 매우 부족하였다.
사용자가 입력하는 암호(Password)의 보안을 올리고자, 영어 사전에 나오는 단어에 해당하는지 검사를 개발하였다.
코딩을 해보자면 Hash-Table이나 Binary-Search-Tree로 구현할 수 있겠으나, 그 당시의 적은 저장 공간과 메모리였다.
그렇다면 어떻게 개발할 수 있었을까?
모든 단어를 집합의 원소로 생각하고 입력으로 들어온 패스워드가 집합에 속해있는지 검색을 하는 방식으로 구현할 수 있다.

여기 Membership Checking(원소가 집합에 속해있는지 확인)에 발생하는 오류에서 FP와 FN을 살펴보자.
FP(False Positive)는 집합에 원소가 속하지 않는데(Member가 아님), 있다고 잘못 판단한 경우이다.
FN(False Negative)는 집합에 원소가 속해 있는데(Member), 아니라고 판단한 경우이다.

모든 단어를 집합(Set)으로 모아놓고, 간결하게 표현한다.
m개의 단어 개수 만큼 m개의 크기를 가지고, 있는지 없는 지 여부를 0과 1의 Bitmap으로 표현한다.
그리고 x라는 원소가 집합(s)에 속하는지(Member) 확인한다.
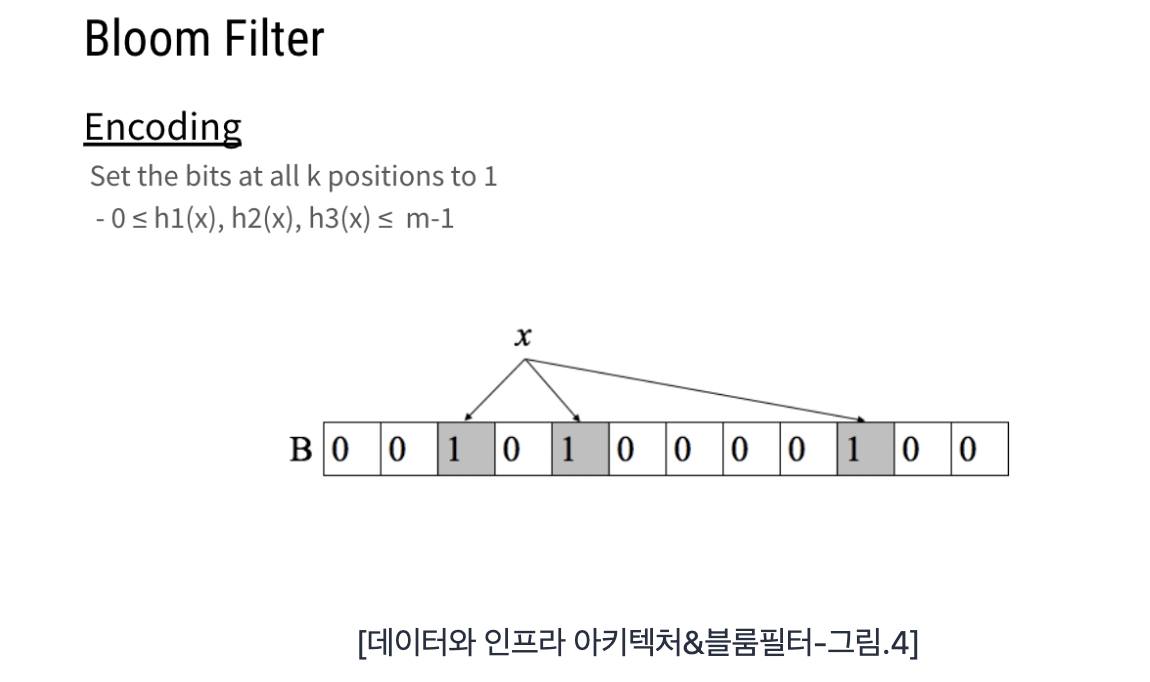
Hash 함수를 k개만큼(h1, h2, …, hk) 사용하여 원소가 있는지 검색한다.
Encoding은 입력으로 들어온 값(x)에 대하여 k개의 hash 함수에서 나온 k개의 위치(Position)에 1을 채워 넣는다.
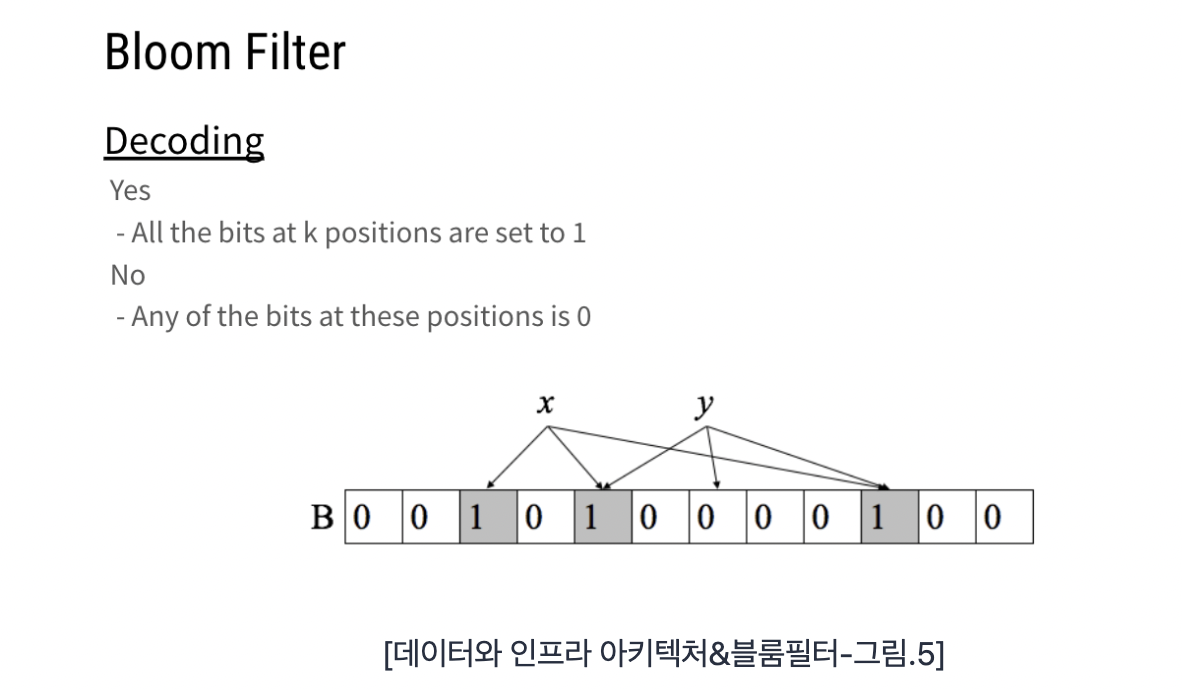
Decoding에서는 있는지 없는지 여부를 판단한다.
Hash 함수 k개의 위치에서 모두 1이 있는 경우에는 Member라고 판단한다.
하나라도 1이 없다면, Non-Member라고 판단한다.
다음의 경우 x는 3개의 Hash 함수에서 1로 되어있기 때문에 Member라고 판단하며, 입력값 y의 경우에는 2번째 Hash 함수에서 0으로 되어 있기 때문에 집합에 포함되어 있지 않다 즉, Non-Member라고 판단한다.
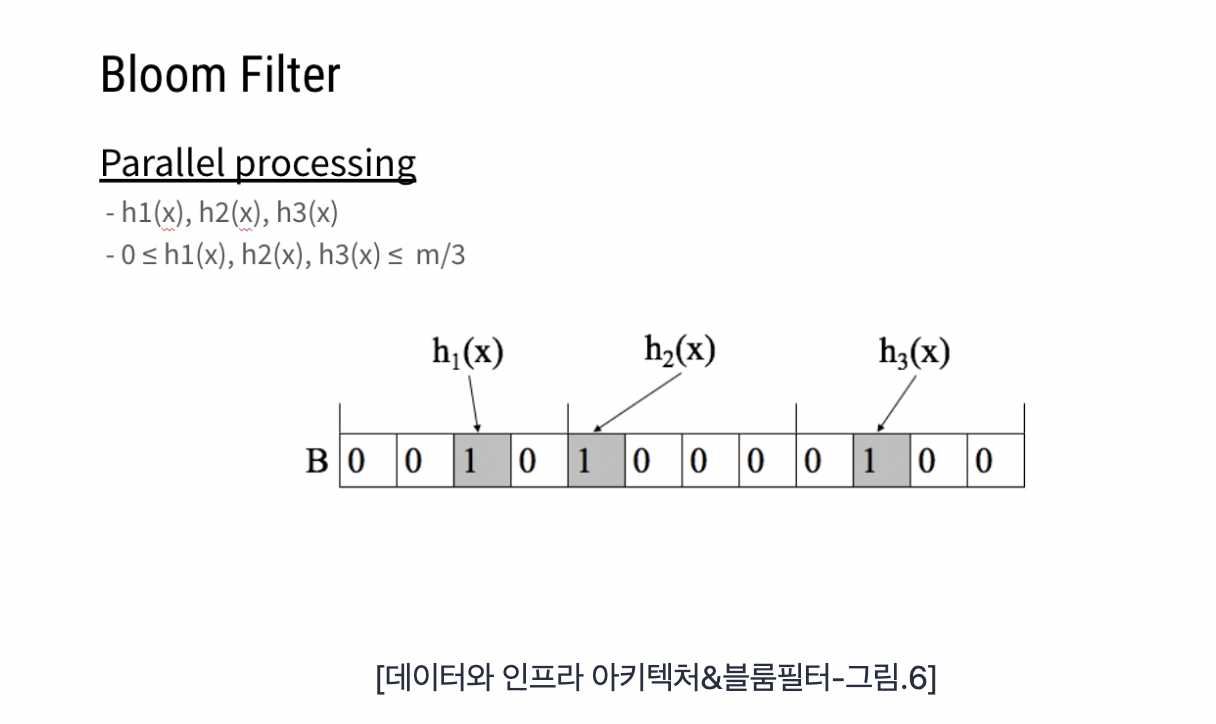
Hash 함수를 여러 개로 두는 것에 따라, 병렬 처리도 가능해진다.
Hash 함수를 인덱스 위치로 지정해서 구간에 따라 처리가 가능해지며, 시간과 공간 복잡도가 향상된다.
공간 절약을 통해 DRAM에 있을 데이터를 SRAM으로 올릴 수 있다.
또한 시간 복잡도는 상수인 O(k)로 처리 시간이 절약된다.
그러나 FP(False Positive)가 용납이 되지 않는 Application에서 사용하면 안된다.

S의 집합 개수는 m개, Hash 함수는 k개, 입력 인자 갯수 n개 가 있다면 nk의 인덱스가 생성된다.
특정 Elements가 선택될 확률은 1/m이며, 선택되지 않은 확률은 1에서 빼면 된다.
이를 통해서 특정 Elements가 0으로 남아 있을 확률은 p의 수식과 같다.
동시 확률에 따라서 선택되지 않은 확률에 nk승 하면 된다.
특정 Elements가 1로 남아 있을 확률은 1-p이다.
이에따라, FP에 대한 확률도 다음의 수식으로 계산할 수 있다.
모두가 1일 확률은 Hash 함수 k개이므로 k승을 하면 된다.
exp(지수)과 ln(자연 로그)로 표현 가능하다.
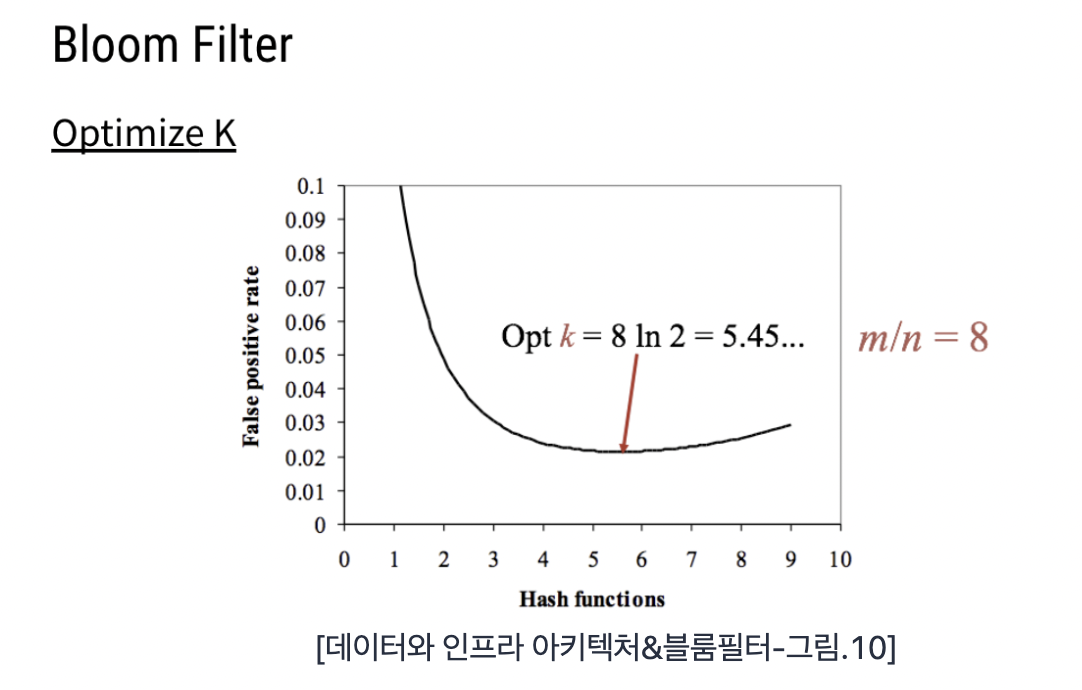
일반적으로 n(입력의 크기), m(집합의 크기 : 영단어장), k 값에 따라 FP에 대한 변화가 생긴다.
n과 m은 일반적으로 고정되어 있으며, k 값을 최적화 하기 위해 최소값을 구해야 한다.
g는 f를 미분한 값이다.
g가 0이 되는 지점을 찾으면 된다.

Hash 함수 개수인 k를 최적화 해보자.
미분에 따라 m과 n으로 k를 구할 수 있다.
FP를 구한 f함수도 m/n에 대해서 정리할 수 있다.

m/n이 8로 고정되었을 때 Hash 함수 k는 5.45로 값이 나오며, 일반적으로 소수점을 버린 값을 취하여 5를 사용하면 적절하다.
Bloom Filter의 사용 예는 다음과 같다.
패스워드 검사, 그리고 Google의 BigTable이나 Apache Hbase, Cassandra에서 존재하지 않는 Row와 Column를 위한 디스크 IO를 줄이기 위해 사용된다.
또한 의심스러운 URL을 검사하기 위해 사용된다.
Bloom Filter는 네트워크에서도 사용된다.
원본 데이터의 길이가 길수록 Bloom Filter를 사용하는 것이 좋다.
IP Address를 확인하는 라우팅 테이블(Routing Table)을 검사하기 위해서도 사용된다.
네트워크를 통한 파일 전송에서는 패킷(Packet)으로 라우터에서 목적지 주소로 전달이 된다.
복잡한 라우팅 테이블에 액세스하지 말고, Bloom Filter로 간단하게 표현한다.
라우터에 대한 Port를 목적지의 주소들을 집합으로 표현한다.
그리고 이 여러 개의 집합에서 값이 있는 지 없는 지 확인한다.
IPv4의 경우 A, B, C, D 클래스 별로 4개의 그룹으로 만들어 Bloom Filter로 검사한다.

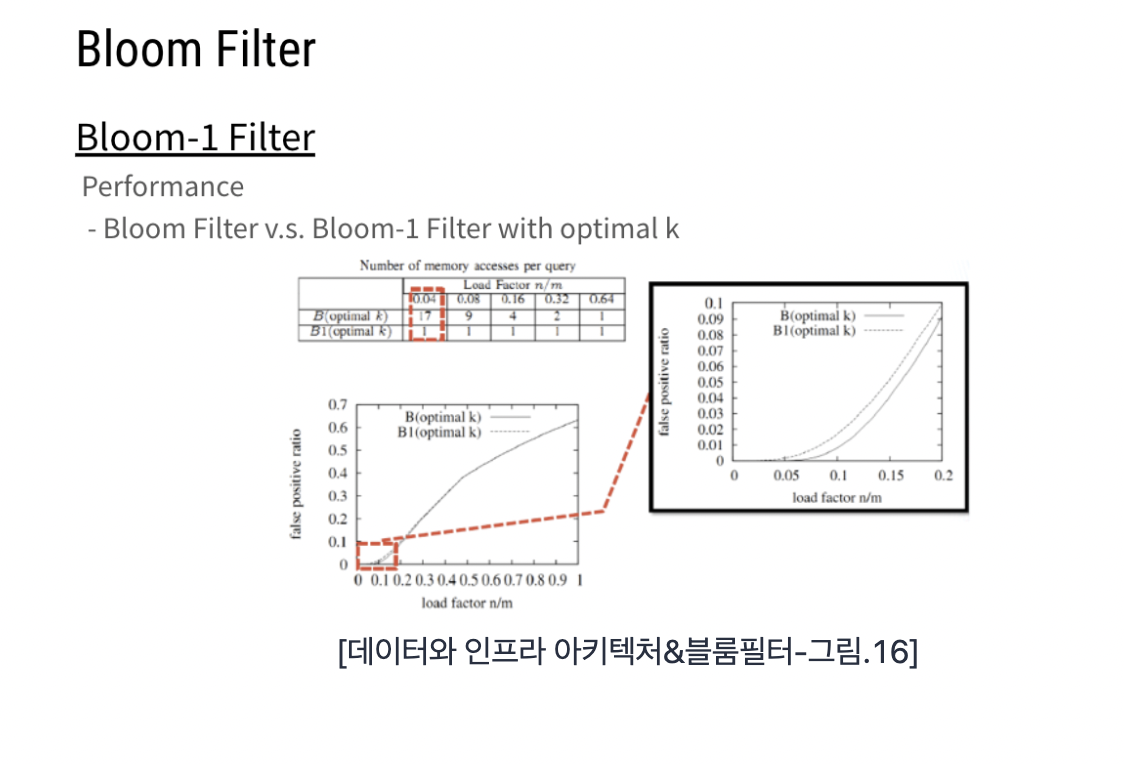
기존의 FP(False Positive)를 낮추고자 Hash 함수의 개수를 늘리면, 메모리 액세스가 많아져 처리하는 시간이 길어지게 된다.
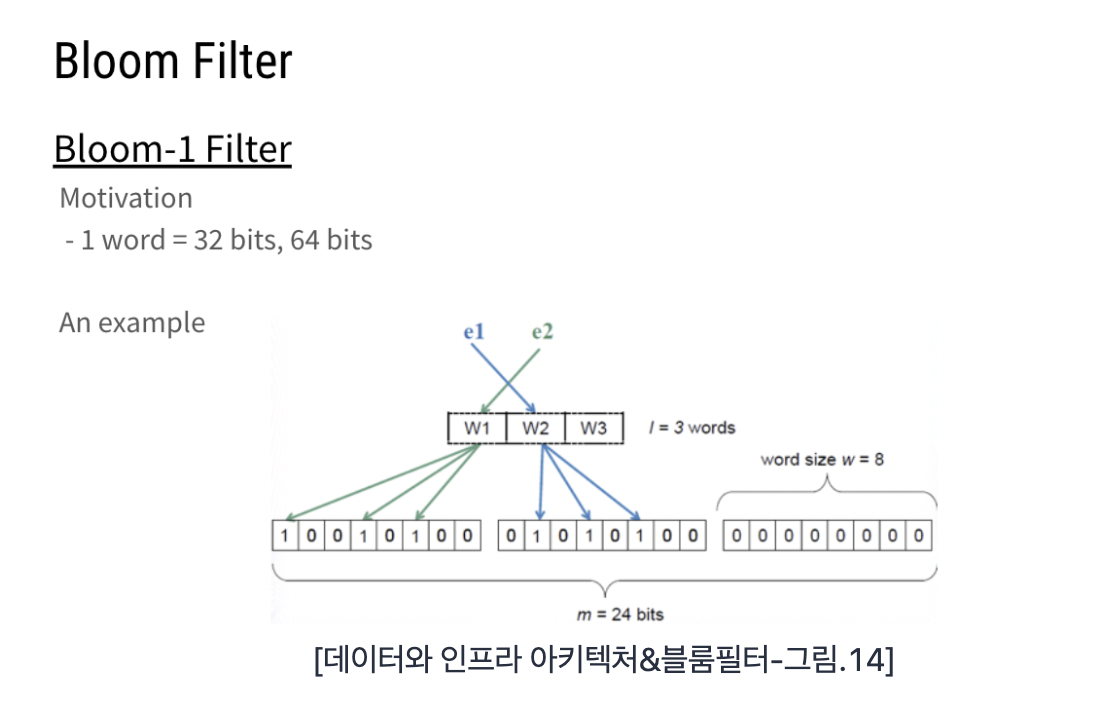
현대로 넘어오면서 운영체제(OS : 32bit/64bit)에 따라 한 번의 메모리 엑세스(Access)로 가져오는 크기가 커졌다.
이에 따라 한번의 메모리 액세스로 Bloom Filter의 응용을 접목하였다.

밑의 예시는 m = 24bit라고 가정했을 경우, Word Size는 8bit로 3개의 Word로 이루어진다.
현대의 컴퓨터인 32/64bit OS에서는 Word Size가 64bit로 메모리에서 CPU로 가져올 때 너무 많은 Bit를 가져오면서 낭비가 발생한다.
그래서 한 번의 메모리 액세스로 Bloom Filter를 구현 하였다.
Word의 크기에 따라 n/m에 따른 FP 비율을 볼 수 있다.
Word에 따른 bit수가 달라져도 일정한 FP의 Ratio를 볼 수 있다.

Bloom-1 Filter를 사용함에 따라 기존의 k의 개수가 1로 바뀌며 비슷한 성능을 보이게 된다.