1.1 왜 통계학을 알아야 할까?
- 일반적인 데이터 과학의 전체 프로세스

가공한 데이터를 통해 탐색적 데이터 분석(Exploratory Data Analysis)을 하면서 데이터를 이해하고 해석한다.
데이터의 분포, 연관성, 확률 등을 통계적으로 깊이 있게 분석한다.
(효과적인 머신러닝 모델 기획, 적용)
모델 적용 시에는 수많은 테스트와 수정을 반복한다.
결과값을 통해 문제점을 찾아내고, 개선 방향을 도출하는 것도 통계학에 대한 이해가 뒷받침돼야 한다.
현상의 원인 도출 및 미래 예측을 위해서는 가설 설정 및 통계적인 분석을 통해 가설을 검정해 나가야 한다. -> 확률분포, 신뢰구간 추정
이항분포, 정규 분포, t 분포 등을 이해할 수 있어야 데이터 과학의 전체 프로세스를 수행할 수 있다.
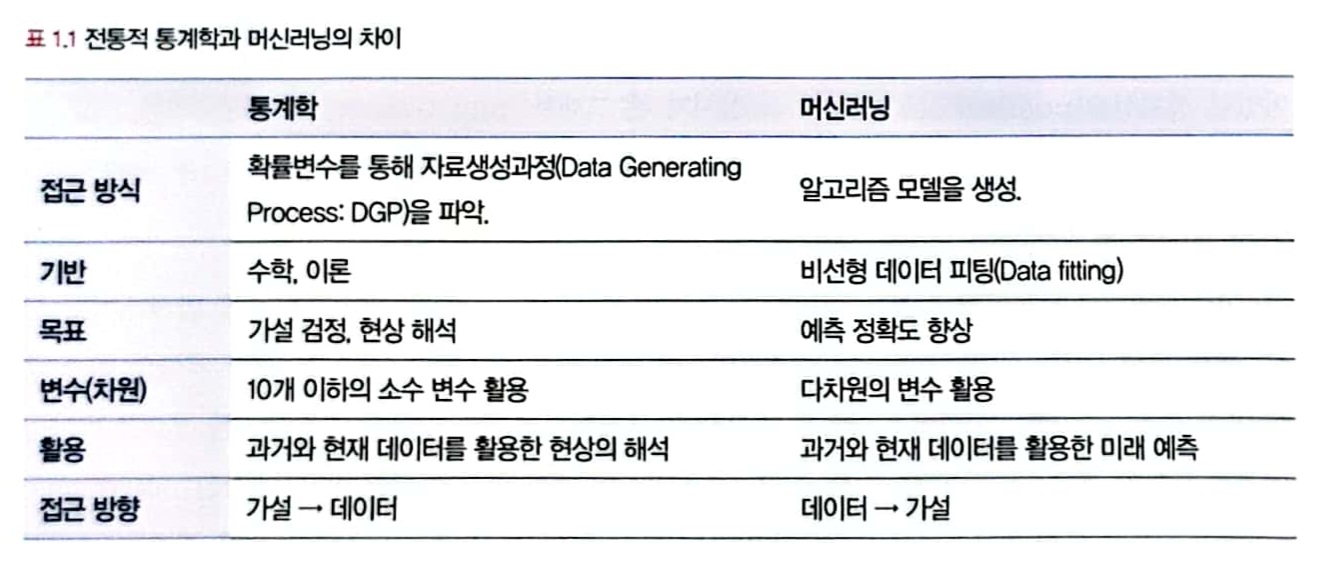
1.2 머신러닝과 전통적 통계학의 차이
머신러닝의 주된 목적은 예측이고
통계학의 주된 목적은 해석이다.
머신러닝은 예측력이 얼마나 높은가에 집중한다.
머신러닝은 통계학의 일부 특성을 활용한 응용과학 분야이다.
통계학은 모델의 신뢰도를 중시하며 복잡성보다는 단순성을 추구한다.
1.3 기술 통계와 추론 통계
이 둘은 데이터를 통해 얻고자 하는 목적이 무엇인가에 따라 구분된다.
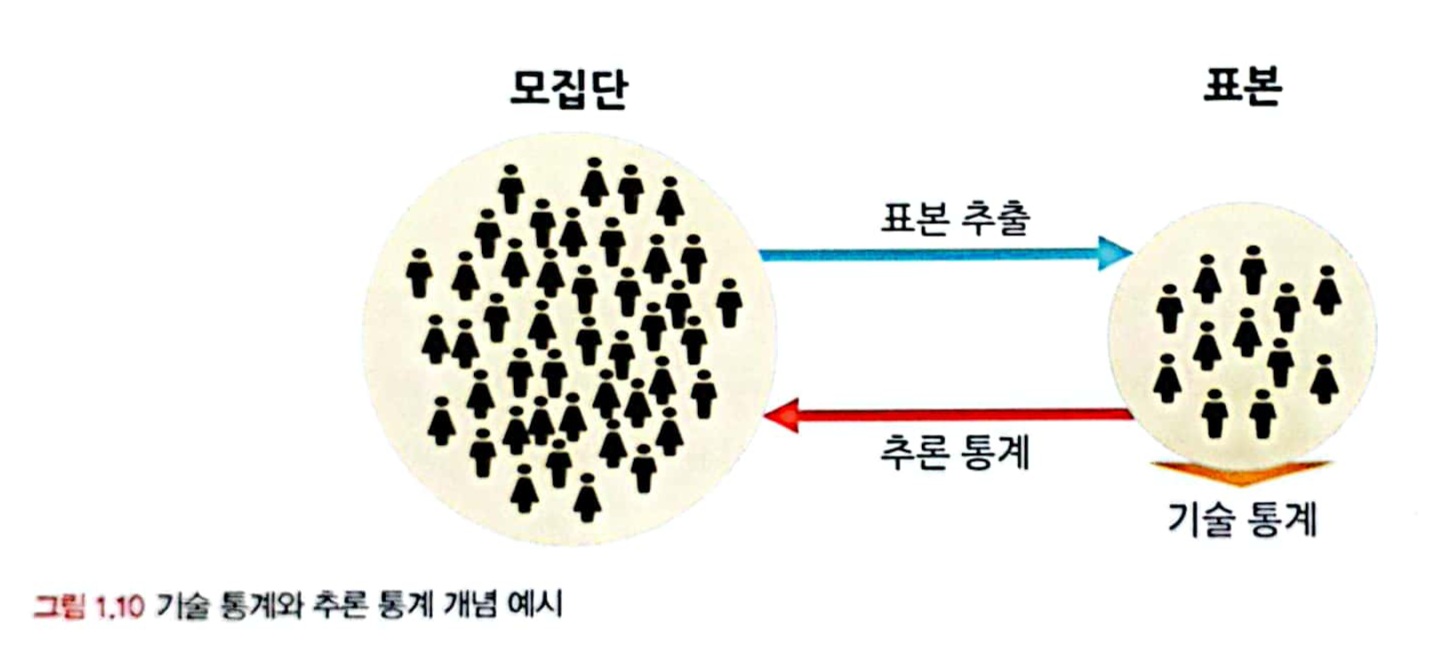
1.3.1 기술 통계
-
주어진 데이터의 특성을 사실에 근거하여 설명, 묘사
-
데이터 설명의 가장 기본적인 방법이 데이터의 대표값을 설명하는 것이다.
(ex. 남자 학생의 평균 키는 173cm, 여자 학생의 평균 키는 163cm) -
전체 데이터를 쉽고 직관적으로 파악할 수 있도록 설명해 주는 것
-
여러 가지 기준을 활용하여 데이터를 설명하는 것
(ex. 평균 키가 같으나, 대부분이 160~170cm 대인 A 학급과, 150~190cm 대로 넓게 분포한 B 학급의 다른 요소를 수치적으로 설명)
이러한 기술 통계를 내는 것을 탐색적 데이터 분석(EDA)라고 한다.
- 보통 시각화를 많이 사용
1.3.2 추론 통계
- 표본 집단으로부터 모집단의 특성을 추론하는 것이 목적
(ex. A 학습의 평균 키가 170cm. 따라서, 학교 전체 학생의 평균 키가 167~173cm 구간 내에 존재할 확률이 00정도)
모집단 : 연구자가 관심 있어 하는 대상 전체 집합
표본 : 연구자가 모집단에서 일부를 추출한 부분집합
-
표본의 통계값을 통해 모집단의 모수 값, 모수 값의 특정 구간 내 존재 확률 추정에 사용
(ex. "이번 투표는 000 후보의 지지율이 00%로 신뢰 구간 00%입니다."에서 신뢰 구간를 구하는 부분) -
기술 통계와 추론 통계의 통합적인 프로세스
「표본 특성 분석 → 특성의 일반화 여부 판단 → 모집단 특성 추정」
