1. apply()
: apply는 series에 일괄적으로 함수를 적용시킬때 쓸 수 있다.
2. drop()
df2 = df2.drop("상품군별(2)", axis = 'columns')
==
df2.drop("상품군별(2)", axis = 'columns', inplace = True) 3. lambda, replace()
df2['date'] = df2['date'].apply(lambda x : x.replace(" p)", ""))
# apply : 컬럼에 함수 적용
# lambda : 함수를 def를 이용해 작성하지 않아도 변경 가능
# replace : string 타입 변경 4. 파일 저장
df2.to_csv("preprocess.csv", encoding = 'cp949', index = False)
#저장할때도 encoding이 필요합니다
#index = False 옵션을 주면 저장시 인덱스 빼고 저장, 옵션 안주면 unnamed 라는 불필요한 컬럼이 파일에 추가됨!!!5. 절대경로, 상대경로

6. os 파이썬 라이브러리
import os
os.getcwd() #현재 파이썬이 실행되는 폴더경로
os.listdir('path') # 해당 경로에 있는 파일들을 리스트로 가져옴
os.mkdir() #폴더생성
os.path.join(src, file_ls[0]) #경로만들기
7. pivot vs pivot_table
- pivot -> 배치O, 집계X
- pivot_table -> 배치O, 집계O
8. concat()
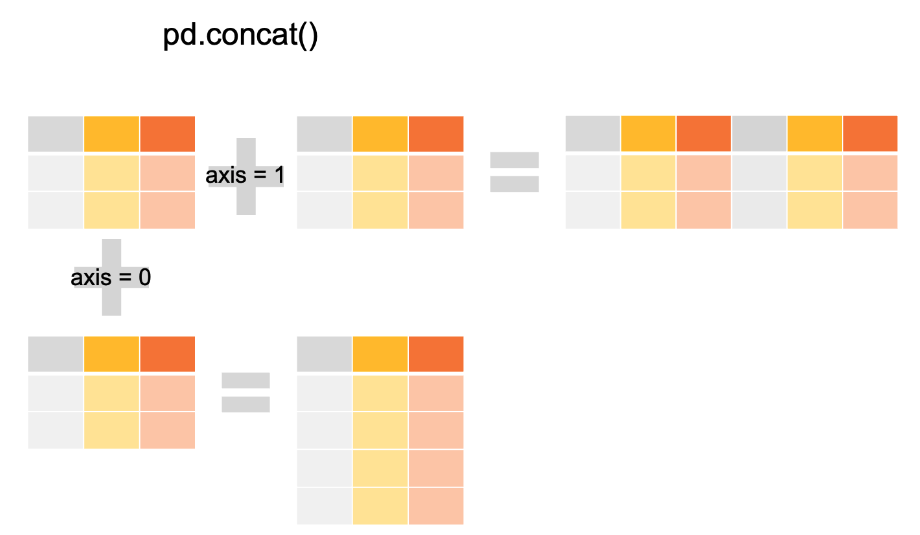
pd.concat([Dataframe1, Dataframe2])
# 같은 형식인데 파일 여러개 일때 합치기 좋음 
도전적인 개발자